

连百年梗图都整明白了!微软多模态「宇宙」搞定IQ测试,仅16亿参数

大模型的卷,已经不睡觉都赶不上进度了......
这不,微软亚研院刚刚发布了一个多模态大型语言模型(MLLM)—— KOSMOS-1。

论文地址:https://arxiv.org/pdf/2302.14045.pdf
论文题目Language Is Not All You Need,还得源于一句名言。
文中有这么一句话,「我语言的局限,就是我世界的局限。——奥地利哲学家Ludwig Wittgenstein」

那么问题来了......
拿着图问KOSMOS-1「是鸭还是兔」能搞明白吗?这张有100多年历史的梗图硬是把谷歌AI整不会了。
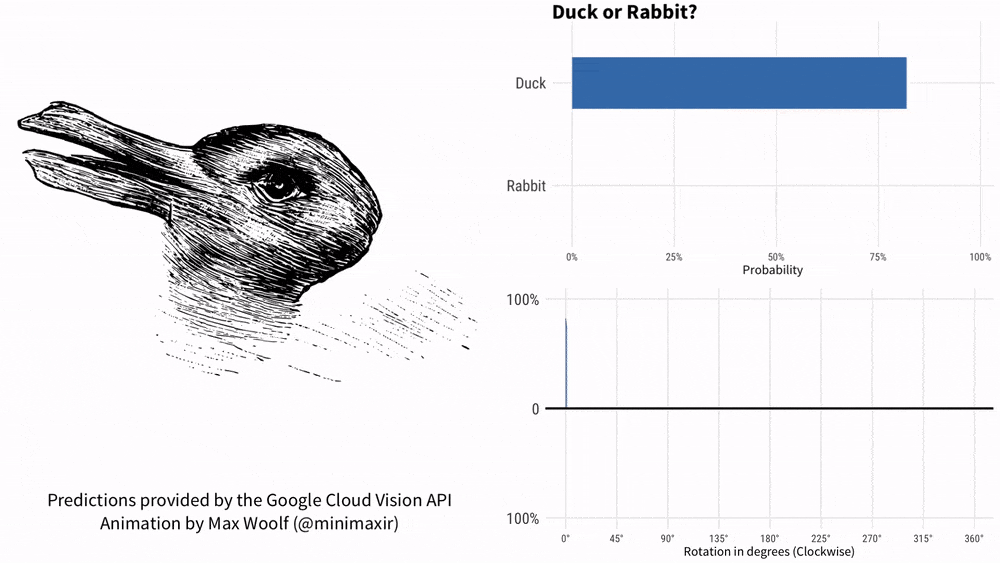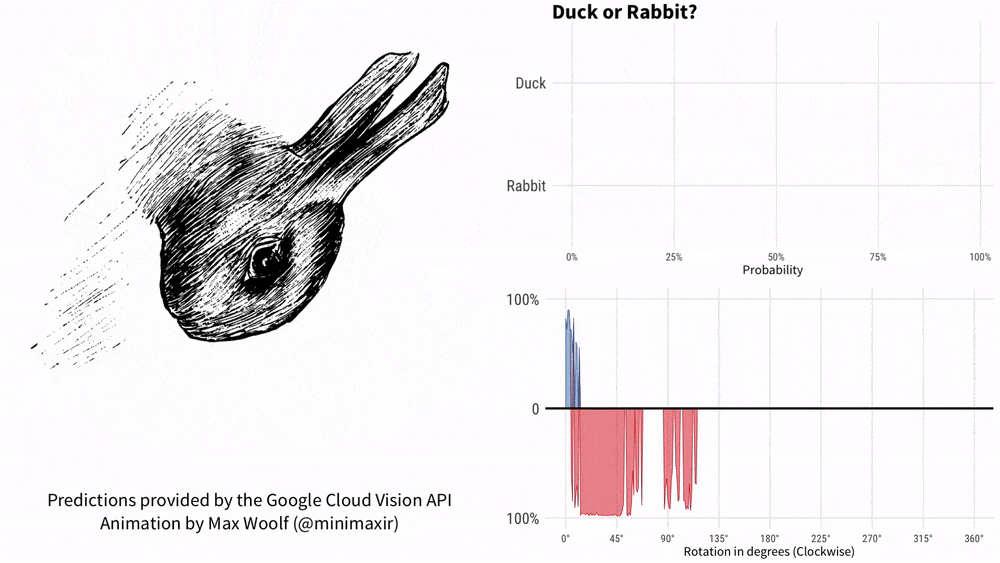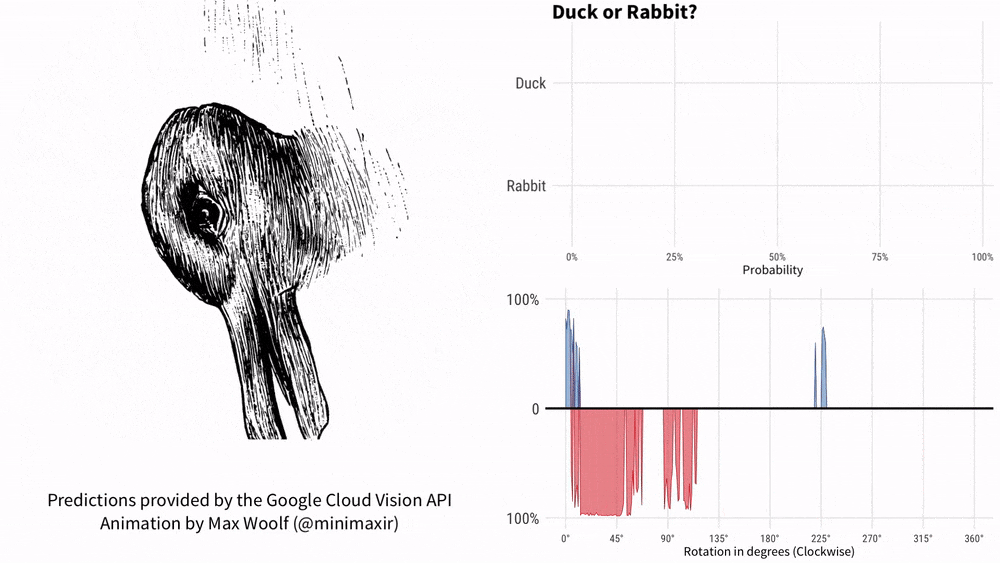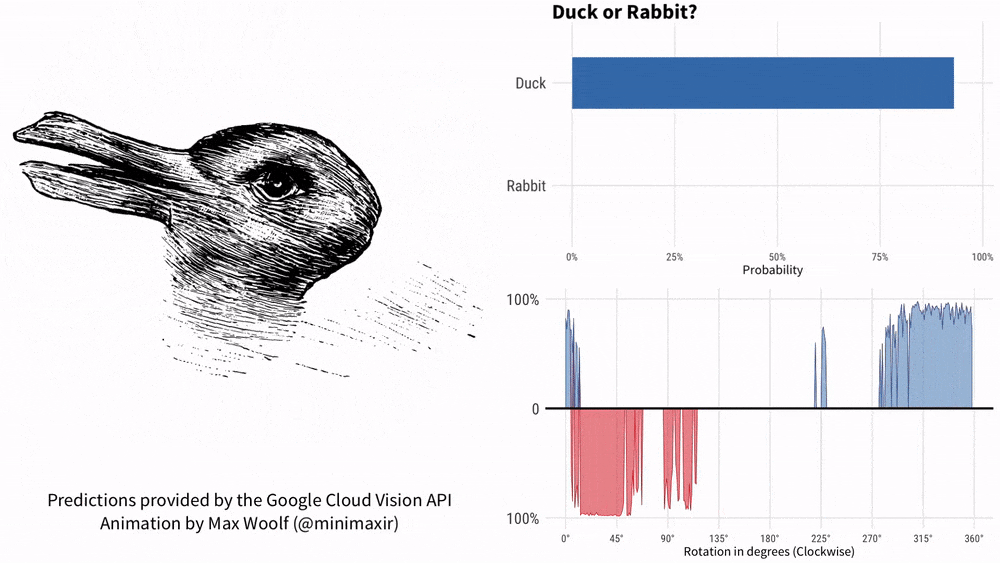
1899年,美国心理学家Joseph Jastrow首次使用「鸭兔图」来表明感知不仅是人们所看到的,而且是一种心理活动。
现在,KOSMOS-1便能将这种感知和语言模型相结合。
-图中是什么?
-像一只鸭子。
-如果不是鸭子,那是什么?
-看起来更像兔子。
-为什么?
-它有兔子的耳朵。
这么一问,KOSMOS-1真有点像微软版的ChatGPT了。

不仅如此,Kosmos-1还能理解图像、文本、带有文本的图像、OCR、图像说明、视觉QA。
甚至IQ测试也不在话下。
「宇宙」无所不能
Kosmos来源希腊一词cosmos,有「宇宙」之意。
据论文介绍,最新Kosmos-1模型是一个多模态大型语言模型。
其主干是一个基于Transformer的因果语言模型,除了文本之外,其他模态,如视觉、音频都可以嵌入模型。
Transformer解码器用作多模态输入的通用接口,因此它能感知一般模态,进行上下文学习,并遵循指令。
Kosmos-1在语言和多模态任务上取得了令人印象深刻的表现,无需进行微调,其中包括带有文字指示的图像识别、视觉问答和多模态对话。
如下是Kosmos-1生成一些例子式样。
图片解释、图片问答、网页问题回答,简单数字公式,以及数字识别。

那么,Kosmos-1是在哪些数据集上进行预训练的呢?
训练所用的数据库,包括文本语料库、图像-字幕对、图像和文本交叉数据集。
文本语料库取自The Pile和Common Crawl(CC);
图像-字幕对的来源为English LAION-2B、LAION-400M、COYO-700M和Conceptual Captions;
文本交叉数据集的来源是Common Crawl snapshot。
数据库有了,接下来就是对模型进行预训练了。
MLLM组件有24层、2,048个隐藏维度、8,192个FFN和32个注意力头头,产生了大约1.3B的参数。
为了保证优化的稳定性,采用Magneto初始化;为了更快地收敛,图像表示是从一个预先训练好的具有1024个特征维度的CLIP ViT-L/14模型获取的。在训练过程中,图像被预处理成224×224分辨率,CLIP模型的参数除了最后一层均被冻结。
KOSMOS-1的参数总量约为16亿。
为了使KOSMOS-1更好地与指令保持一致,对其进行了只用语言的指令调整 [LHV+23, HSLS22],即用指令数据继续训练模型,该指令数据是仅有的语言数据,与训练语料库混合。
该调优过程是按照语言建模的方式进行的,选取的指令数据集为Unnatural Instructions [HSLS22]和FLANv2 [LHV+23]。
结果显示,指令跟随能力的提高可以跨模式转移。
总之,MLLM可以从跨模态迁移中获益,将知识从语言迁移到多模态,反之亦然;
5大类10个任务,都拿捏了
一个模型好不好使,拿出来溜溜就知道了。
研究团队从多角度进行实验来评价KOSMOS-1的性能,包括5大类十项任务:
1 语言任务(语言理解、语言生成、无OCR的文本分类)
2 多模态转移(常识推理)
3 非语言推理(IQ测试)
4 感知-语言任务(图像说明、视觉问答、网页问答)
5 视觉任务(零样本图像分类、带描述的零样本图像分类)
无OCR的文本分类
这是一种不依赖于光学字符识别(OCR)的专注于文本和图像的理解任务。
KOSMOS-1对HatefulMemes和对Rendered SST-2测试集的准确率均高于优于其他模型。
而且Flamingo明确提供OCR文本到提示中,KOSMOS-1并没有访问任何外部工具或资源,这展示了KOSMOS-1阅读和理解渲染的图像中的文本的内在能力。
IQ测试
瑞文智力测试是评估非语言的最常用测试之一。
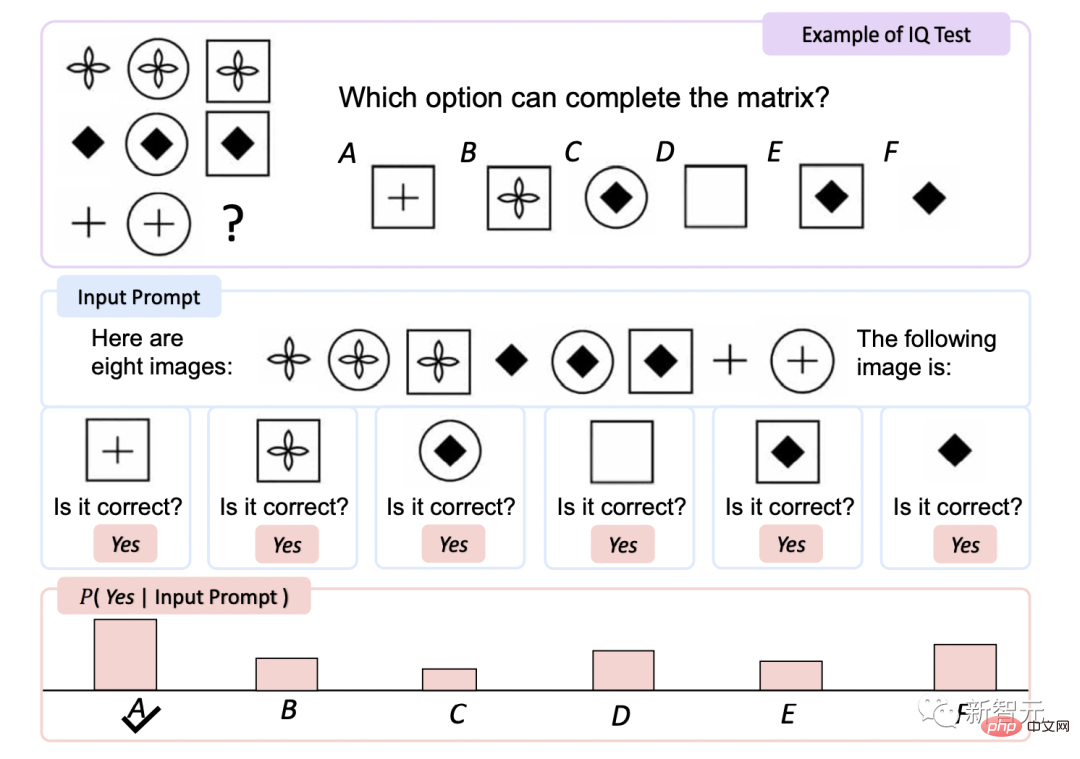
KOSMOS-1在没有进行微调时准确率比随机选择提高了5.3%,经过微调后则提高了9.3%,表明其具有感知非语言环境中的抽象概念模式的能力。
这是首次有模型能够完成零样本Raven测试,证明了MLLMs通过将感知与语言模型结合起来进行零样本非言语推理的潜力。

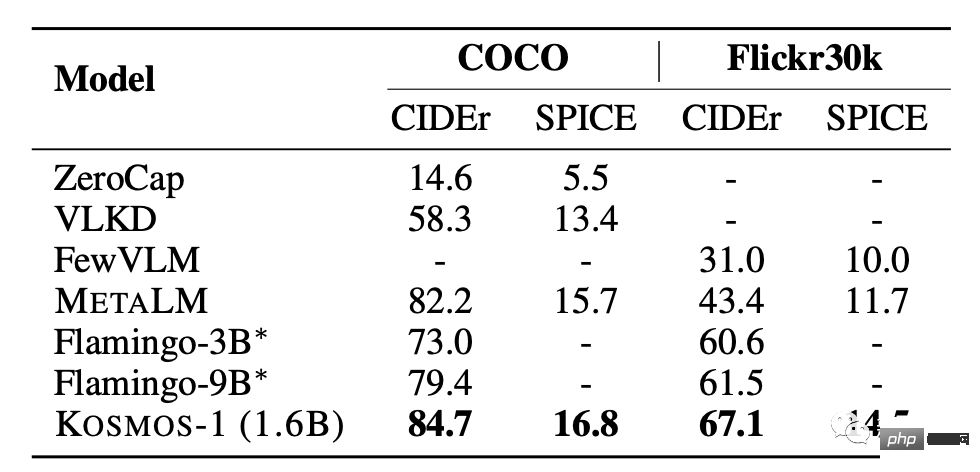
图像说明
KOSMOS-1在COCO和Flickr30k测试中的零样本性能均表现优秀,相比其他模型,其得分更高,但采用的参数量更小。
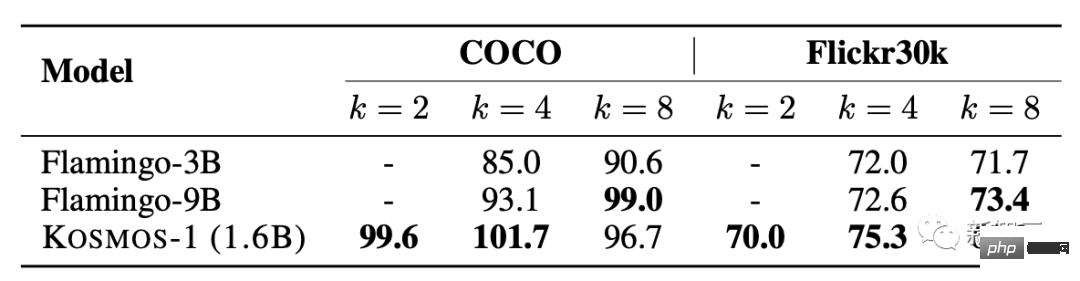
在少样本性能测试中,得分随着k值增大有所增加。
零样本图像分类
给定一个输入图像,并将该图像与提示 「The photo of the」连接起来。然后,输入模型以获得图像的类别名称。

通过在ImageNet[DDS+09]上评估该模型,在有约束和无约束的条件下,KOSMOS-1的图像归类效果都明显优于GIT[WYH+22],展现了完成视觉任务的强大能力。

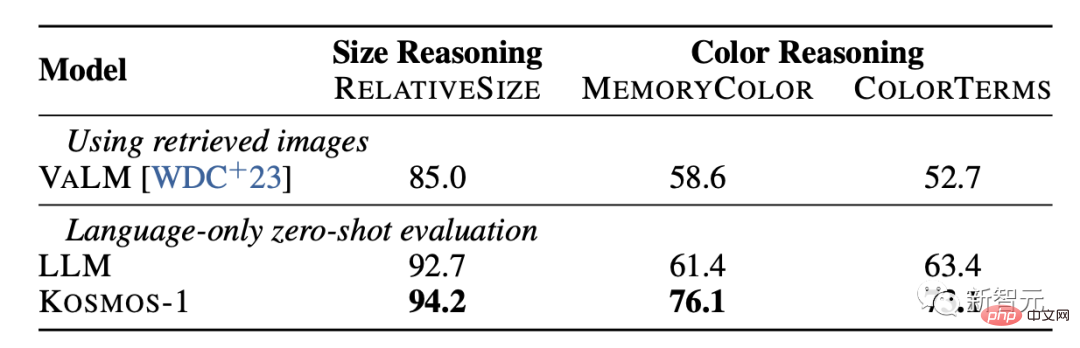
常识推理
视觉常识推理任务要求模型理解现实世界中日常物体的属性,如颜色、大小和形状,这些任务是具有挑战性的,因为它们可能需要比文本中更多的关于物体属性的信息。
结果显示,KOSMOS-1在尺寸和颜色方面的推理能力都明显好于LLM模型。这主要是因为KOSMOS-1具备多模态迁移能力,从而能够将视觉知识运用到语言任务中,而不必像LLM那样必须依靠文本知识和线索来推理。
对于微软Kosmos-1,网友称赞道,未来5年,我可以看到一个高级机器人浏览网络,并仅通过视觉方式基于人类的文本输入来工作。真是有趣的时代。

以上是连百年梗图都整明白了!微软多模态「宇宙」搞定IQ测试,仅16亿参数的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想象一下,一个人工智能模型,不仅拥有超越传统计算的能力,还能以更低的成本实现更高效的性能。这不是科幻,DeepSeek-V2[1],全球最强开源MoE模型来了。DeepSeek-V2是一个强大的专家混合(MoE)语言模型,具有训练经济、推理高效的特点。它由236B个参数组成,其中21B个参数用于激活每个标记。与DeepSeek67B相比,DeepSeek-V2性能更强,同时节省了42.5%的训练成本,减少了93.3%的KV缓存,最大生成吞吐量提高到5.76倍。DeepSeek是一家探索通用人工智
 替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
本月初,来自MIT等机构的研究者提出了一种非常有潜力的MLP替代方法——KAN。KAN在准确性和可解释性方面表现优于MLP。而且它能以非常少的参数量胜过以更大参数量运行的MLP。比如,作者表示,他们用KAN以更小的网络和更高的自动化程度重现了DeepMind的结果。具体来说,DeepMind的MLP有大约300,000个参数,而KAN只有约200个参数。KAN与MLP一样具有强大的数学基础,MLP基于通用逼近定理,而KAN基于Kolmogorov-Arnold表示定理。如下图所示,KAN在边上具
 特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人Optimus最新视频出炉,已经可以在厂子里打工了。正常速度下,它分拣电池(特斯拉的4680电池)是这样的:官方还放出了20倍速下的样子——在小小的“工位”上,拣啊拣啊拣:这次放出的视频亮点之一在于Optimus在厂子里完成这项工作,是完全自主的,全程没有人为的干预。并且在Optimus的视角之下,它还可以把放歪了的电池重新捡起来放置,主打一个自动纠错:对于Optimus的手,英伟达科学家JimFan给出了高度的评价:Optimus的手是全球五指机器人里最灵巧的之一。它的手不仅有触觉
 微软发布 Win11 八月累积更新:提高安全、优化锁屏等
Aug 14, 2024 am 10:39 AM
微软发布 Win11 八月累积更新:提高安全、优化锁屏等
Aug 14, 2024 am 10:39 AM
本站8月14日消息,在今天的8月补丁星期二活动日中,微软发布了适用于Windows11系统的累积更新,包括面向22H2和23H2的KB5041585更新,面向21H2的KB5041592更新。上述设备安装8月累积更新之后,本站附上版本号变化如下:21H2设备安装后版本号升至Build22000.314722H2设备安装后版本号升至Build22621.403723H2设备安装后版本号升至Build22631.4037面向Windows1121H2的KB5041585更新主要内容如下:改进:提高了
 微软全屏弹窗催促:Windows 10用户抓紧时间升级到Windows 11
Jun 06, 2024 am 11:35 AM
微软全屏弹窗催促:Windows 10用户抓紧时间升级到Windows 11
Jun 06, 2024 am 11:35 AM
6月3日消息,微软正在积极向所有Windows10用户发送全屏通知,鼓励他们升级到Windows11操作系统。这一举措涉及了那些硬件配置并不支持新系统的设备。自2015年起,Windows10已经占据了近70%的市场份额,稳坐Windows操作系统的霸主地位。然而,市场占有率远超过82%的市场份额,占有率远超过2021年面世的Windows11。尽管Windows11已经推出已近三年,但其市场渗透率仍显缓慢。微软已宣布,将于2025年10月14日后终止对Windows10的技术支持,以便更专注于
 全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
Jun 01, 2024 pm 04:41 PM
为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐LLM方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管RLHF方法的结果很出色,但其中涉及到了一些优化难题。其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。近段时间已有一些研究者探索了更简单的离线算法,其中之一便是直接偏好优化(DPO)。DPO是通过参数化RLHF中的奖励函数来直接根据偏好数据学习策略模型,这样就无需显示式的奖励模型了。该方法简单稳定
 无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显着突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。 StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
 LLM全搞定!OmniDrive:集3D感知、推理规划于一体(英伟达最新)
May 09, 2024 pm 04:55 PM
LLM全搞定!OmniDrive:集3D感知、推理规划于一体(英伟达最新)
May 09, 2024 pm 04:55 PM
写在前面&笔者的个人理解这篇论文致力于解决当前多模态大语言模型(MLLMs)在自动驾驶应用中存在的关键挑战,即将MLLMs从2D理解扩展到3D空间的问题。由于自动驾驶车辆(AVs)需要针对3D环境做出准确的决策,这一扩展显得尤为重要。3D空间理解对于AV来说至关重要,因为它直接影响车辆做出明智决策、预测未来状态以及与环境安全互动的能力。当前的多模态大语言模型(如LLaVA-1.5)通常仅能处理较低分辨率的图像输入(例如),这是由于视觉编码器的分辨率限制,LLM序列长度的限制。然而,自动驾驶应用需
