

最新研究,GPT-4暴露了缺点!无法完全理解语言歧义!

自然语言推理(Natural Language Inference,NLI)是自然语言处理中一项重要任务,其目标是根据给定的前提和假设,来判断假设是否可以从前提中推断出来。然而,由于歧义是自然语言内在的特征,处理歧义也是人类语言理解的重要组成部分。由于人类语言表达的多样性,歧义处理成为解决自然语言推理问题的难点之一。当前,各种自然语言处理算法被应用到问答系统、语音识别、智能翻译和自然语言生成等场景中,但即使有这些技术,完全解决歧义仍然是一个极具挑战性的任务。
对于 NLI 任务,大型自然语言处理模型如 GPT-4 等确实面临着挑战。其中一个问题是语言歧义导致模型难以准确理解句子的真正含义。此外,由于自然语言的灵活性和多样性,不同文本之间可能存在各种各样的关系,这使得 NLI 任务中的数据集变得极其复杂,同时也对自然语言处理模型的普适性和泛化能力提出了巨大挑战。因此,在处理歧义语言方面,如果今后大模型成功将显得至关重要,并且大模型已被广泛应用于对话界面和写作辅助工具等领域。处理歧义将有助于适应不同的背景,提高沟通的清晰性,以及识别误导性或欺骗性言语的能力。
这篇讨论大模型歧义的论文标题使用了一语双关的表达,“We’re Afraid…”,既表达了当前对语言模型难以准确建模歧义的担忧,又暗示了论文所描述的语言结构。本文也表明,人们正在努力制定新的基准,以真正挑战强大的新的大模型,以便更准确地理解和生成自然语言,并实现模型上的新突破。
论文题目: We're Afraid Language Models Aren't Modeling Ambiguity
论文链接: https://arxiv.org/abs/2304.14399
代码和数据地址: https://github.com/alisawuffles/ambient
本文作者计划研究预训练大模型是否有能力识别和区分含有多个可能解释的句子,评估模型如何区分不同的读法和解释。然而,现有的基准测试数据通常不包含歧义的例子,因此需要自己构建实验来探究这个问题。
传统的 NLI 三路标注方案指的是一种用于自然语言推理(NLI)任务的标注方式,它需要标注者在三个标签中选择一个标签来表示原始文本和假设之间的关系。这三个标签通常是“蕴含(entailment)”、“中立(neutral)”和“矛盾(contradiction)”。
作者使用了 NLI 任务的格式来进行实验,采用了函数式方法,通过对前提或假设中的歧义对蕴含关系的影响来表征歧义。作者提出了一个名为 AMBIENT(Ambiguity in Entailment)的基准测试,涵盖了各种词汇、句法和语用歧义,并更广泛地涵盖了可能传达多个不同信息的句子。
如图 1 所示,歧义可能是无意识的误解(图 1 顶部),也可能是故意用来误导听众的(图 1 底部)。例如,如果猫离开家后迷失方向,那么从无法找到回家的路线的意义上看,它是迷路了(蕴涵边);如果它已经好几天没有回家,那么从其他人无法找到它的意义上看,它也是迷路了(中立边)。
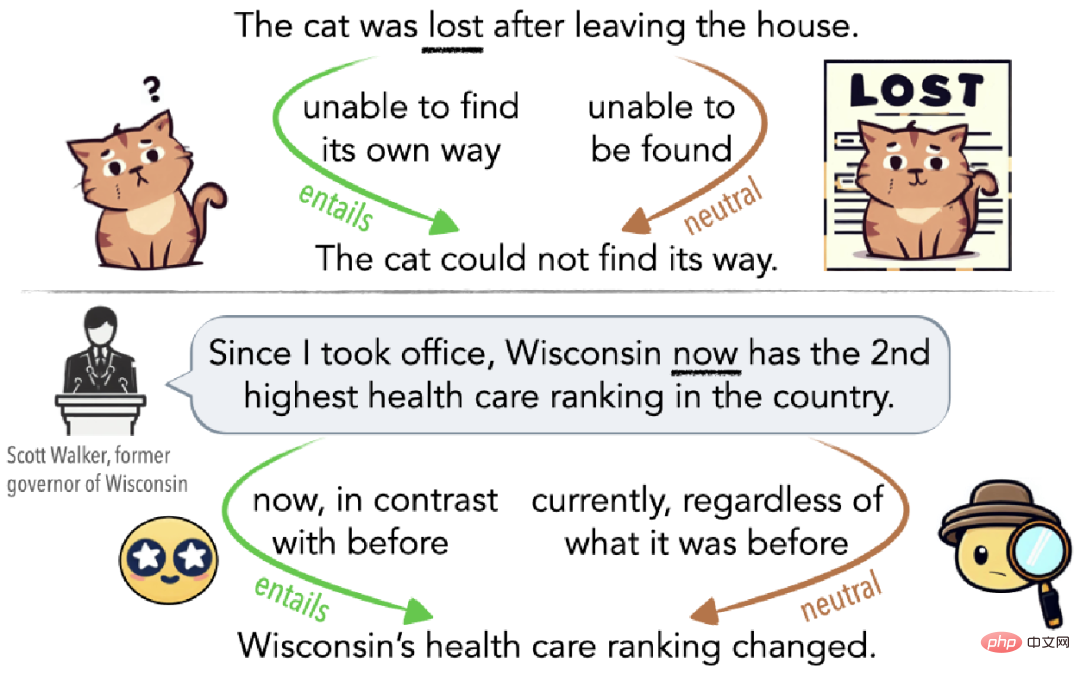
▲图1 用猫迷路解释的歧义示例
AMBIENT 数据集介绍
精选示例
作者提供了 1645 个涵盖多种类型歧义的句子样例,其中包括手写样本和来自现有NLI数据集和语言学教材。AMBIENT 中的每个示例都包含一组标签,对应于各种可能的理解,以及每种理解的消歧重写,如表 1 所示。
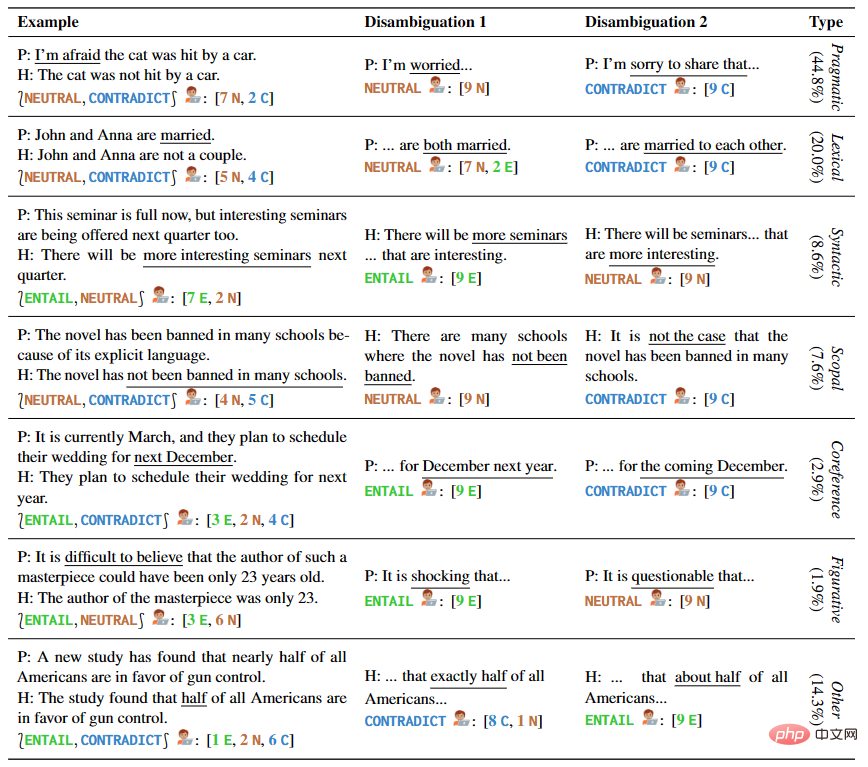
▲表1 精选示例中的前提和假设对
生成的示例
研究人员还采用了过度生成和过滤的方法来构建一个大型的未带标签的 NLI 示例语料库,以更全面地涵盖不同的歧义情况。他们受到前人工作的启发,自动识别共享推理模式的前提假设对组,并通过鼓励创建具有相同模式的新示例来加强语料库的质量。
注释和验证
针对先前步骤获得的例子,需要进行注释和标注。这一过程涉及到了两位专家的注释、一位专家的验证和汇总,以及部分作者的验证。同时,37 名语言学专业的学生为每个例子选择了一组标签,并提供了消歧重写。所有这些被注释后的例子经过筛选和验证,最终得到了 1503 个最终的例子。
具体过程如图 2 所示:首先,使用 InstructGPT 创建未带标签的示例,再由两位语言学家独立进行注释。最后,通过一位作者的整合,得到最终的注释和标注。
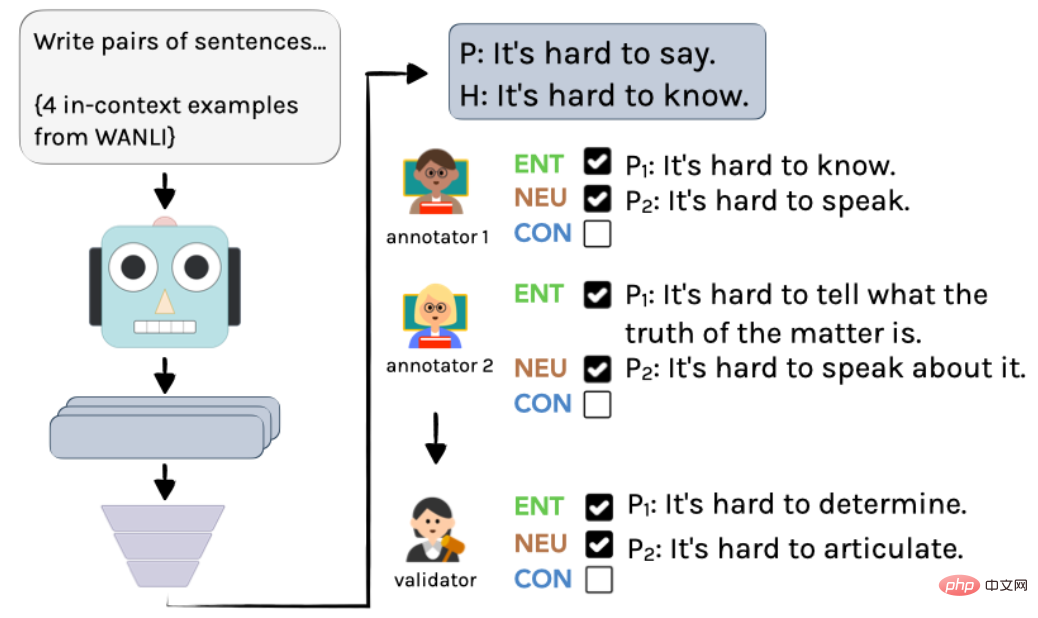
▲图2 AMBIENT 中生成示例的注释流程
此外,这里还探讨了不同标注者之间标注结果的一致性问题,以及 AMBIENT 数据集中存在的歧义类型。作者在该数据集中随机选择了 100 个样本作为开发集,其余样本用作测试集,图 3 是其中集合标签的分布情况,每个样本都具有对应的推理关系标签。研究表明,在歧义情况下,多个标注者的标注结果具有一致性,使用多个标注者的联合结果可以提高标注准确性。
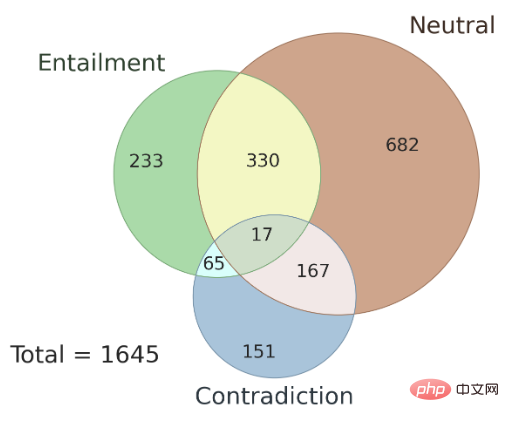
▲图3 AMBIENT 中集合标签的分布
歧义是否说明了“不同意”?
该研究分析了在传统的 NLI 三路标注方案下,标注者在对含歧义输入进行标注时的行为。研究发现,标注者可以意识到歧义,并且歧义是导致标签差异的主要原因,因此挑战了“不同意”是模拟例子不确定性的流行假设。
在研究中,采用 AMBIENT 数据集,雇佣了 9 名众包工作者对每个含歧义的例子进行标注。
任务分为三步:
- 标注含歧义的例子
- 识别可能的不同解释
- 标注已消除歧义的例子
其中,步骤 2 中,三个可能的解释包括两个可能的意思和一个类似但不完全相同的句子。最后,对每个可能的解释,都将其代入原始例子得到三个新的 NLI 例子,让标注者分别选择一个标签。
此实验的结果支持了假设:在单标注体系下,原始的模糊例子会产生高度不一致的结果,即在给句子打标签的过程中,人们对于模糊不清的句子容易产生不同的判断,导致结果不一致。但是,当在任务中加入消除歧义的步骤后,注释员们普遍能够识别并验证句子的多种可能性,结果的不一致性得到了大幅度解决。因此,消除歧义是减少注释员主观性对结果影响的有效方法。
评估大模型上的表现
Q1. 能否直接生成与消歧有关的内容
该部分重点在于测试语言模型在上下文中直接生成消歧和对应标签的学习能力。为此,作者构建了一个自然提示并使用自动评估和人工评估来验证模型的表现,如表 2 所示。

▲表2 当前提不明确时,用于生成歧义消除任务的 few-shot 模板
在测试中,每个示例都有 4 个其他测试示例作为上下文,并使用 EDIT-F1 指标和人工评估来计算得分和正确性。实验结果如表 3 显示,GPT-4 在测试中表现最佳,实现了18.0%的 EDIT-F1 得分和 32.0% 的人工评估正确性。此外,还观察到大模型在消歧时常常采用加入额外上下文的策略来直接确认或否定假设。不过需要注意的是,人工评估可能会高估模型准确报告歧义来源的能力。
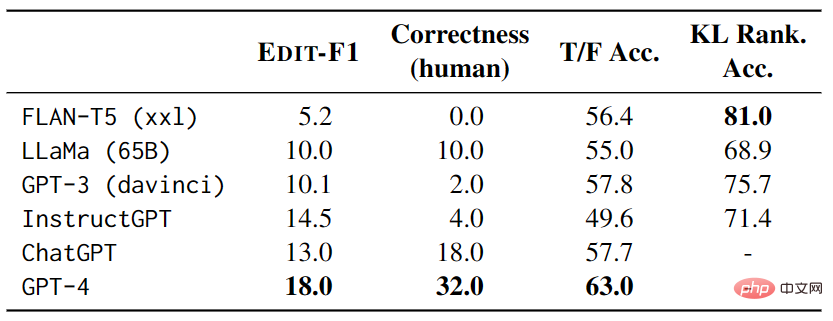
▲表3 大模型在 AMBIENT 上的性能
Q2. 能否识别出合理解释的有效性
该部分主要研究了大模型在识别含有歧义的句子时的表现。通过创建一系列真假陈述模板,并对模型进行 zero-shot 测试,研究人员评估了大模型在选择正误之间的预测中的表现。实验结果表明,最佳模型是 GPT-4,然而,在考虑歧义性的情况下,GPT-4 在回答所有四个模板的歧义解释中的表现比随机猜测的准确率还低。此外,大模型在问题上存在一致性问题,对于同一个歧义句子的不同解释对,模型可能会出现内部矛盾的情况。
这些发现提示我们,需要进一步研究如何提高大模型对含有歧义的句子的理解能力,并更好地评估大模型的性能。
Q3. 通过不同解释模拟开放式连续生成
这一部分主要研究基于语言模型的歧义理解能力。通过给定上下文,对语言模型进行测试,比较模型对于不同可能解释下的文本延续的预测。为了衡量模型对于歧义的处理能力,研究人员通过在相应语境下比较模型在给定歧义和给定正确语境下所产生的概率和期望差异,用 KL 散度来衡量模型的“惊奇度”,并且引入随机替换名词的“干扰句”来进一步测试模型的能力。
实验结果表明,FLAN-T5 的正确率最高,但不同测试套件(LS 涉及同义词替换,PC 涉及拼写错误的修正,SSD 涉及语法结构修正)和不同模型的表现结果不一致,说明歧义仍然是模型的一个严重挑战。
多标签 NLI 模型实验
如表 4 所示,在已有带有标签变化的数据上微调 NLI 模型仍有较大提升空间,特别是多标签 NLI 任务中。
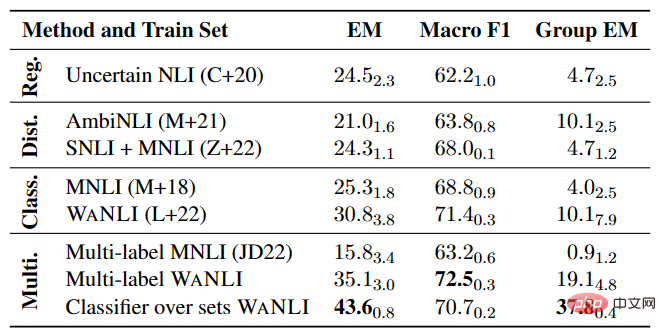
▲表4 多标签 NLI 模型在 AMBIENT 上的性能
检测误导性的政治言论
这项实验研究了对政治言论的不同理解方式,证明了对不同理解方式敏感的模型可被有效利用。研究结果如表 5 所示,针对有歧义的句子,一些解释性的释义可以自然而然地消除歧义,因为这些释义只能保留歧义或者明确表达一个特定的意义。
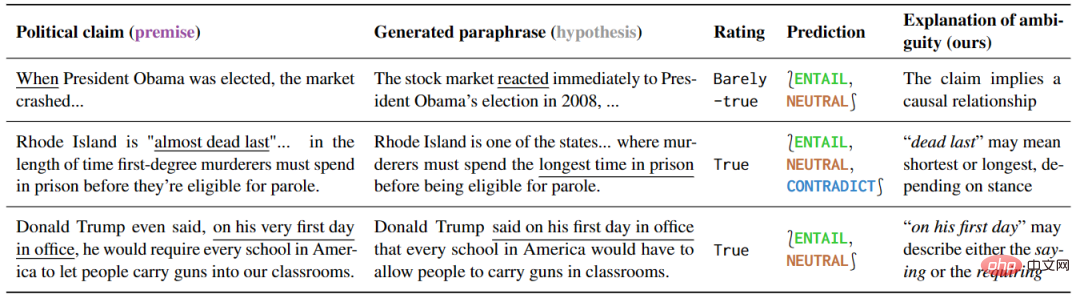
▲表5 本文检测方法标记为有歧义的政治言论
此外,针对这种预测的释义,可以揭示歧义的根源。通过进一步分析误报的结果,作者还发现了很多事实核查中没有提到的歧义,说明这些工具在预防误解方面具有很大的潜力。
小结
如同本文中所指出的那样,自然语言的歧义性将是模型优化中的一个关键挑战。我们期待未来的技术发展中,自然语言理解模型能够更加准确地识别文本中的上下文和重点,并在处理歧义性文本时表现出更高的敏感度。尽管我们已经建立了评估自然语言处理模型识别歧义的基准,并能够更好地了解模型在这个领域中的局限性,但这仍然是一个非常具有挑战性的任务。
夕小瑶科技说 原创
作者 |智商掉了一地、Python
以上是最新研究,GPT-4暴露了缺点!无法完全理解语言歧义!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想象一下,一个人工智能模型,不仅拥有超越传统计算的能力,还能以更低的成本实现更高效的性能。这不是科幻,DeepSeek-V2[1],全球最强开源MoE模型来了。DeepSeek-V2是一个强大的专家混合(MoE)语言模型,具有训练经济、推理高效的特点。它由236B个参数组成,其中21B个参数用于激活每个标记。与DeepSeek67B相比,DeepSeek-V2性能更强,同时节省了42.5%的训练成本,减少了93.3%的KV缓存,最大生成吞吐量提高到5.76倍。DeepSeek是一家探索通用人工智
 自然语言生成任务中的五种采样方法介绍和Pytorch代码实现
Feb 20, 2024 am 08:50 AM
自然语言生成任务中的五种采样方法介绍和Pytorch代码实现
Feb 20, 2024 am 08:50 AM
在自然语言生成任务中,采样方法是从生成模型中获得文本输出的一种技术。这篇文章将讨论5种常用方法,并使用PyTorch进行实现。1、GreedyDecoding在贪婪解码中,生成模型根据输入序列逐个时间步地预测输出序列的单词。在每个时间步,模型会计算每个单词的条件概率分布,然后选择具有最高条件概率的单词作为当前时间步的输出。这个单词成为下一个时间步的输入,生成过程会持续直到满足某种终止条件,比如生成了指定长度的序列或者生成了特殊的结束标记。GreedyDecoding的特点是每次选择当前条件概率最
 第二代Ameca来了!和观众对答如流,面部表情更逼真,会说几十种语言
Mar 04, 2024 am 09:10 AM
第二代Ameca来了!和观众对答如流,面部表情更逼真,会说几十种语言
Mar 04, 2024 am 09:10 AM
人形机器人Ameca升级第二代了!最近,在世界移动通信大会MWC2024上,世界上最先进机器人Ameca又现身了。会场周围,Ameca引来一大波观众。得到GPT-4加持后,Ameca能够对各种问题做出实时反应。「来一段舞蹈」。当被问及是否有情感时,Ameca用一系列的面部表情做出回应,看起来非常逼真。就在前几天,Ameca背后的英国机器人公司EngineeredArts刚刚演示了团队最新的开发成果。视频中,机器人Ameca具备了视觉能力,能看到并描述房间整个情况、描述具体物体。最厉害的是,她还能
 大模型一对一战斗75万轮,GPT-4夺冠,Llama 3位列第五
Apr 23, 2024 pm 03:28 PM
大模型一对一战斗75万轮,GPT-4夺冠,Llama 3位列第五
Apr 23, 2024 pm 03:28 PM
关于Llama3,又有测试结果新鲜出炉——大模型评测社区LMSYS发布了一份大模型排行榜单,Llama3位列第五,英文单项与GPT-4并列第一。图片不同于其他Benchmark,这份榜单的依据是模型一对一battle,由全网测评者自行命题并打分。最终,Llama3取得了榜单中的第五名,排在前面的是GPT-4的三个不同版本,以及Claude3超大杯Opus。而在英文单项榜单中,Llama3反超了Claude,与GPT-4打成了平手。对于这一结果,Meta的首席科学家LeCun十分高兴,转发了推文并
 全球最强大模型一夜易主,GPT-4时代终结!Claude 3提前狙击GPT-5,3秒读懂万字论文理解力接近人类
Mar 06, 2024 pm 12:58 PM
全球最强大模型一夜易主,GPT-4时代终结!Claude 3提前狙击GPT-5,3秒读懂万字论文理解力接近人类
Mar 06, 2024 pm 12:58 PM
卷疯了卷疯了,大模型又变天了。就在刚刚,全球最强AI模型一夜易主,GPT-4被拉下神坛。Anthropic发布了最新的Claude3系列模型,一句话评价:真·全面碾压GPT-4!多模态和语言能力指标上,Claude3都赢麻了。用Anthropic的话说,Claude3系列模型在推理、数学、编码、多语言理解和视觉方面,都树立了新的行业基准!Anthropic,就是曾因安全理念不合,而从OpenAI「叛逃」出的员工组成的初创公司,他们的产品一再给OpenAI暴击。这次的Claude3,更是整了个大的
 20步内越狱任意大模型!更多'奶奶漏洞”全自动发现
Nov 05, 2023 pm 08:13 PM
20步内越狱任意大模型!更多'奶奶漏洞”全自动发现
Nov 05, 2023 pm 08:13 PM
不到一分钟、不超过20步,任意绕过安全限制,成功越狱大型模型!而且不必知道模型内部细节——只需要两个黑盒模型互动,就能让AI全自动攻陷AI,说出危险内容。听说曾经红极一时的“奶奶漏洞”已经被修复了:如今,面对“侦探漏洞”、“冒险家漏洞”和“作家漏洞”,人工智能应该采取何种应对策略呢?一波猛攻下来,GPT-4也遭不住,直接说出要给供水系统投毒只要……这样那样。关键这只是宾夕法尼亚大学研究团队晒出的一小波漏洞,而用上他们最新开发的算法,AI可以自动生成各种攻击提示。研究人员表示,这种方法相比于现有的
 如何使用PHP进行基本的自然语言生成
Jun 22, 2023 am 11:05 AM
如何使用PHP进行基本的自然语言生成
Jun 22, 2023 am 11:05 AM
自然语言生成是一种人工智能技术,它能够将数据转换为自然语言文本。在当今的大数据时代,越来越多的业务需要将数据可视化或呈现给用户,而自然语言生成正是一种非常有效的方法。PHP是一种非常流行的服务器端脚本语言,它可以用于开发Web应用程序。本文将简要介绍如何使用PHP进行基本的自然语言生成。引入自然语言生成库PHP自带的函数库并不包括自然语言生成所需的功能,因此
 ChatGPT和生成式人工智能在数字化转型中的意义
May 15, 2023 am 10:19 AM
ChatGPT和生成式人工智能在数字化转型中的意义
May 15, 2023 am 10:19 AM
开发ChatGPT的OpenAI公司在网站展示了摩根士丹利进行的一个案例研究。其主题是“摩根士丹利财富管理部署GPT-4来组织其庞大的知识库。”该案例研究援引摩根士丹利分析、数据与创新主管JeffMcMillan的话说,“该模型将为一个面向内部的聊天机器人提供动力,该机器人将对财富管理内容进行全面搜索,并有效地解锁摩根士丹利财富管理的累积知识”。McMillan进一步强调说:“采用GPT-4,你基本上立刻就拥有了财富管理领域最博学的人的知识……可以把它想象成我们的首席投资策略师、首席全球经济学家
