
现在的数据科学比赛提供的数据量越来越大,动不动几十个G,甚至上百G,这就要考验机器性能和数据处理能力。
Python中的pandas是大家常用的数据处理工具,能应付较大数据集(千万行级别),但当数据量达到十亿百亿行级别,pandas处理起来就有点力不从心了,可以说非常的慢。
这里面会有电脑内存等性能的因素,但pandas本身的数据处理机制(依赖内存)也限制了它处理大数据的能力。
当然pandas可以通过chunk分批读取数据,但是这样的劣势在于数据处理较复杂,而且每一步分析都会消耗内存和时间。
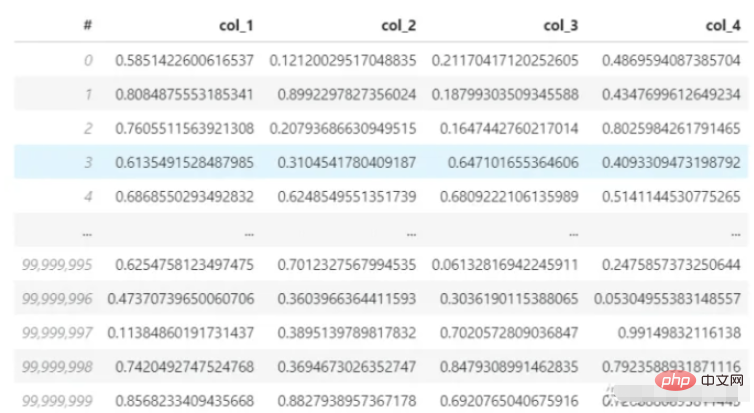
下面用pandas读取3.7个G的数据集(hdf5格式),该数据集共有4列、1亿行,并且计算第一行的平均值。我的电脑CPU是i7-8550U,内存8G,看看这个加载和计算过程需要花费多少时间。
数据集:
使用pandas读取并计算:
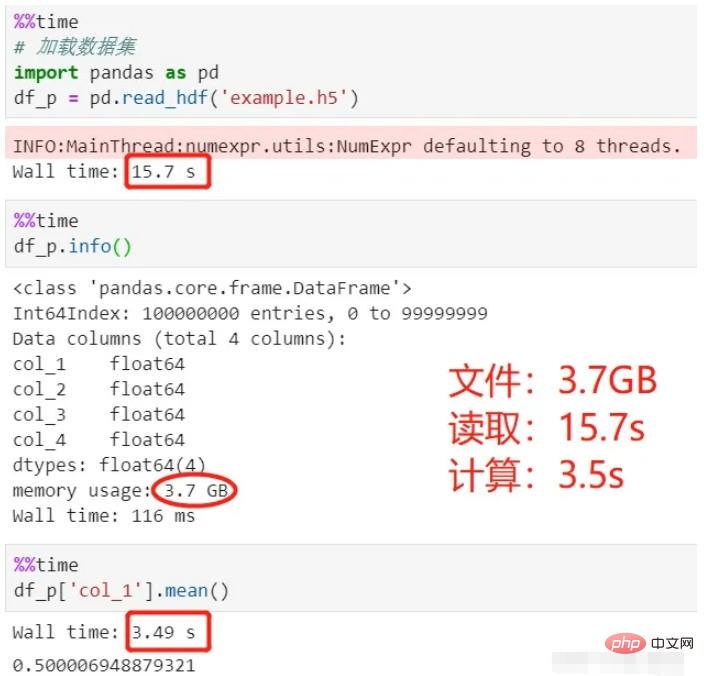
看上面的过程,加载数据用了15秒,平均值计算用了3.5秒,总共18.5秒。
这里用的是hdf5文件,hdf5是一种文件存储格式,相比较csv更适合存储大数据量,压缩程度高,而且读取、写入也更快。
换上今天的主角vaex,读取同样的数据,做同样的平均值计算,需要多少时间呢?
使用vaex读取并计算:
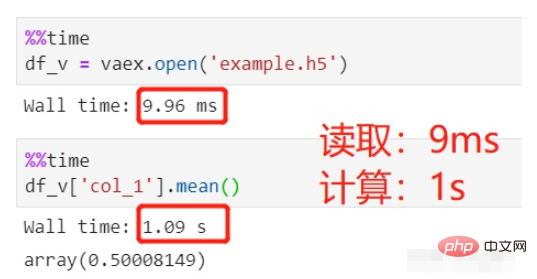
文件读取用了9ms,可以忽略不计,平均值计算用了1s,总共1s。
同样是读取1亿行的hdfs数据集,为什么pandas需要十几秒,而vaex耗费时间接近于0呢?
这里主要是因为pandas把数据读取到了内存中,然后用于处理和计算。而vaex只会对数据进行内存映射,而不是真的读取数据到内存中,这个和spark的懒加载是一样的,在使用的时候 才会去加载,声明的时候不加载。
所以说不管加载多大的数据,10GB、100GB...对vaex来说都是瞬间搞定。美中不足的是,vaex的懒加载只支持HDF5, Apache Arrow,Parquet, FITS等文件,不支持csv等文本文件,因为文本文件没办法进行内存映射。
可能有的小伙伴不太理解内存映射,下面放一段解释,具体要弄清楚还得自行摸索:
内存映射是指硬盘上文件的位置与进程逻辑地址空间中一块大小相同的区域之间的一一对应。这种对应关系纯属是逻辑上的概念,物理上是不存在的,原因是进程的逻辑地址空间本身就是不存在的。在内存映射的过程中,并没有实际的数据拷贝,文件没有被载入内存,只是逻辑上被放入了内存,具体到代码,就是建立并初始化了相关的数据结构(struct address_space)。
前面对比了vaex和pandas处理大数据的速度,vaex优势明显。虽然能力出众,不比pandas家喻户晓,vaex还是个刚出圈的新人。
vaex同样是基于python的数据处理第三方库,使用pip就可以安装。
官网对vaex的介绍可以总结为三点:
vaex是一个用处理、展示数据的数据表工具,类似pandas;
vaex采取内存映射、惰性计算,不占用内存,适合处理大数据;
vaex可以在百亿级数据集上进行秒级的统计分析和可视化展示;
vaex的优势在于:
性能:处理海量数据,109 行/秒;
惰性:快速计算,不占用内存;
零内存复制:在进行过滤/转换/计算时,不复制内存,在需要时进行流式传输;
可视化:内含可视化组件;
API:类似pandas,拥有丰富的数据处理和计算函数;
可交互:配合Jupyter notebook使用,灵活的交互可视化;
使用pip或者conda进行安装:

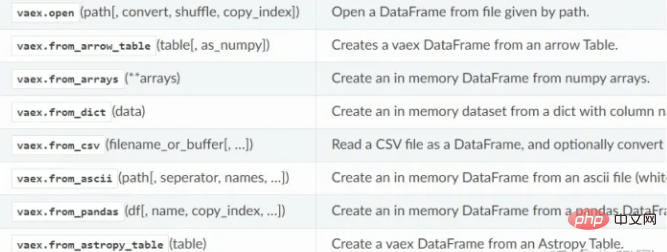
vaex支持读取hdf5、csv、parquet等文件,使用read方法。hdf5可以惰性读取,而csv只能读到内存中。
vaex数据读取函数:
有时候我们需要对数据进行各种各样的转换、筛选、计算等,pandas的每一步处理都会消耗内存,而且时间成本高。除非说使用链式处理,但那样过程就很不清晰。
vaex则全过程都是零内存。因为它的处理过程仅仅产生expression(表达式),表达式是逻辑表示,不会执行,只有到了最后的生成结果阶段才会执行。而且整个过程数据是流式传输,不会产生内存积压。
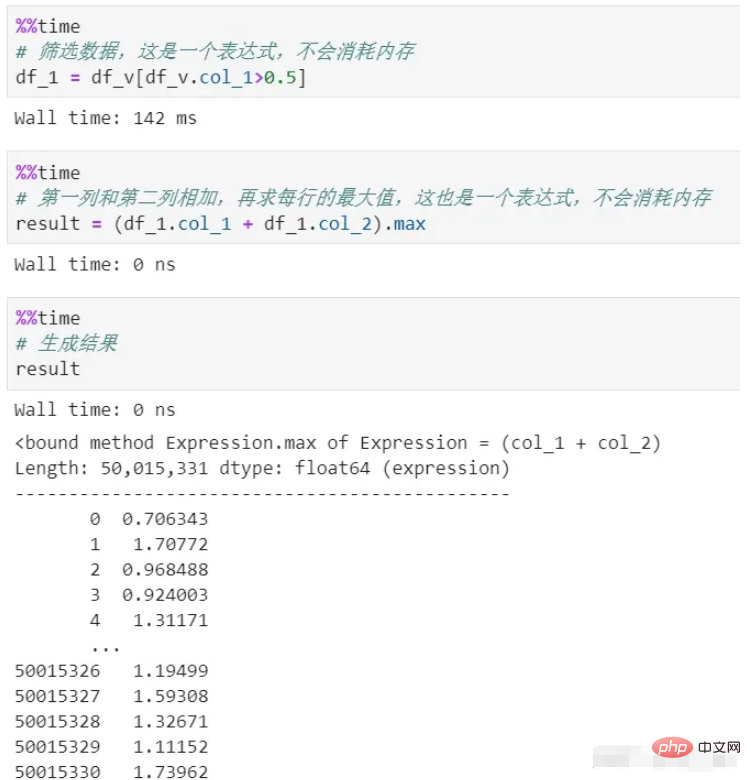
可以看到上面有筛选和计算两个过程,都没有复制内存,这里采用了延迟计算,也就是惰性机制。如果每个过程都真实计算,消耗内存不说,单是时间成本就很大。
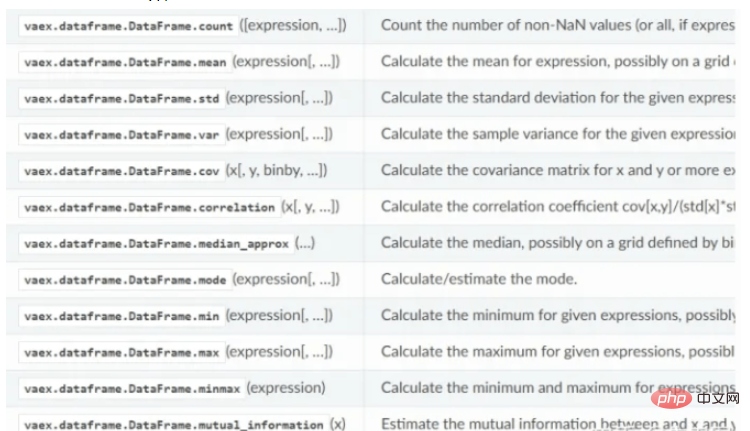
vaex的统计计算函数:
vaex还可以进行快速可视化展示,即便是上百亿的数据集,依然能秒出图。
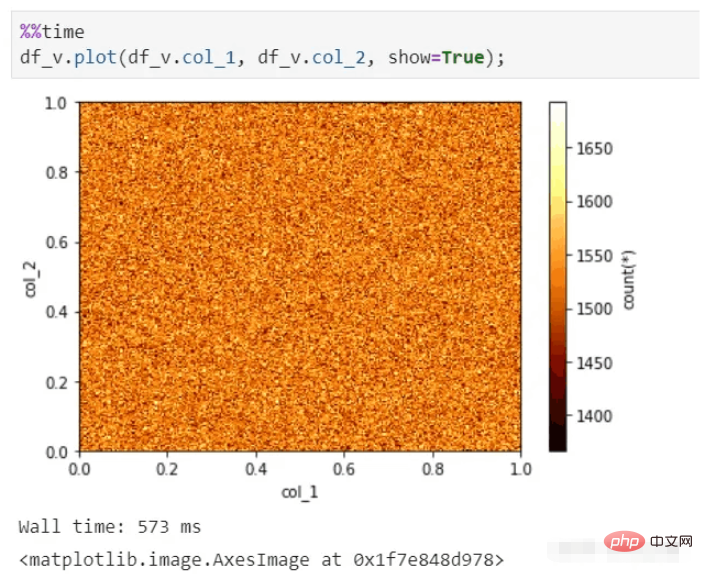
vaex可视化函数:

vaex有点类似spark和pandas的结合体,数据量越大越能体现它的优势。只要你的硬盘能装下多大数据,它就能快速分析这些数据。
vaex还在快速发展中,集成了越来越多pandas的功能,它在github上的star数是5k,成长潜力巨大。
附:hdf5数据集生成代码(4列1亿行数据)
import pandas as pd import vaex df = pd.DataFrame(np.random.rand(100000000,4),columns=['col_1','col_2','col_3','col_4']) df.to_csv('example.csv',index=False) vaex.read('example.csv',convert='example1.hdf5')
注意这里不要用pandas直接生成hdf5,其格式会与vaex不兼容。
以上是Python Vaex如何实现快速分析100G大数据量的详细内容。更多信息请关注PHP中文网其他相关文章!





















