

Transformer再胜Diffusion!谷歌发布新一代文本-图像生成模型Muse:生成效率提升十倍

最近谷歌又发布了全新的文本-图像生成Muse模型,没有采用当下大火的扩散(diffusion)模型,而是采用了经典的Transformer模型就实现了最先进的图像生成性能,相比扩散或自回归(autoregressive)模型,Muse模型的效率也提升非常多。

论文链接:https://arxiv.org/pdf/2301.00704.pdf
项目链接:https://muse-model.github.io/
Muse以masked modeling任务在离散token空间上进行训练:给定从预训练的大型语言模型(LLM)中提取的文本嵌入,Muse的训练过程就是预测随机masked掉的图像token。
与像素空间的扩散模型(如Imagen和DALL-E 2)相比,由于Muse使用了离散的token,只需要较少的采样迭代,所以效率得到了明显提高;
与自回归模型(如Parti)相比,由于Muse使用了并行解码,所以效率更高。

使用预训练好的LLM可以实现细粒度的语言理解,从而转化为高保真的图像生成和对视觉概念的理解,如物体、空间关系、姿态、cardinality等。
在实验结果中,只有900M参数的Muse模型在CC3M上实现了新的SOTA性能,FID分数为6.06。
Muse 3B参数模型在zero-shot COCO评估中实现了7.88的FID,同时还有0.32的CLIP得分。

Muse还可以在不对模型进行微调或反转(invert)直接实现一些图像编辑应用:修复(inpainting)、扩展(outpainting)和无遮罩编辑(mask-free editing)。
Muse模型
Muse模型的框架包含多个组件,训练pipeline由T5-XXL预训练文本编码器,基础模型(base model)和超分辨率模型组成。
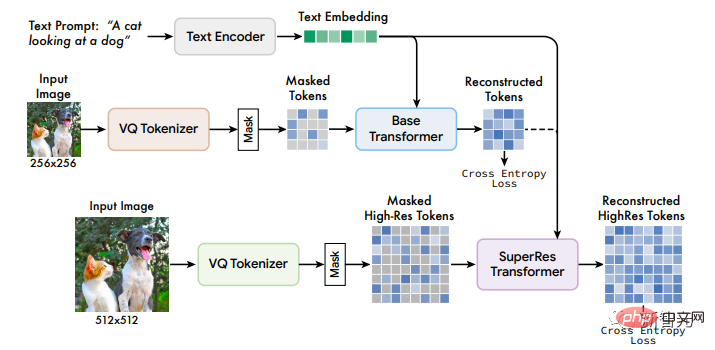
1. 预训练文本编码器
与之前研究中得出的结论类似,研究人员发现利用预训练的大型语言模型(LLM)有利于提升高质量图像的生成结果。
比如从语言模型T5-XXL中提取的嵌入(embedding)带有关于物体(名词)、行动(动词)、视觉属性(形容词)、空间关系(介词)以及其他属性(如卡片性和组成)的丰富信息。
所以研究人员提出假设(hypothesis):Muse模型学会将LLM嵌入中的这些丰富的视觉和语义概念映射到生成的图像上。
最近也有一些工作已经证明了,由LLM学习到的概念表征与由视觉任务训练的模型学习的概念表征大致上是可以「线性映射」的。
给定一个输入的文本标题,将其传递给冻结参数的T5-XXL编码器,可以得到一个4096维的语言嵌入向量,然后将这些向量线性地投射到Transformer模型(base和超分辨率)的hidden size维度上。
2. 使用VQGAN进行Semantic Tokenization
VQGAN模型由一个编码器和一个解码器组成,其中的量化层(quantization layer)将输入图像映射成来自一个学习过的codebook的token序列。
然后完全用卷积层建立编码器和解码器,以支持对不同分辨率的图像进行编码。
编码器中包括几个下采样块来减少输入的空间维度,而解码器中则是有相应数量的上采样块来将latents映射回原始图像大小。
研究人员训练了两个VQGAN模型:一个是下采样率f=16,模型在256×256像素的图像上获得基本模型的标记,从而得到空间尺寸为16×16的标记;另一个是下采样率f=8,在512×512的图像上获得超分辨率模型的token,相应的的空间尺寸为64×64。
编码后得到的离散token可以捕捉图像的高层次语义,同时也可以消除低层次的噪声,并且根据token的离散性可以在输出端使用交叉熵损失来预测下一阶段的masked token
3. Base Model
Muse的基础模型是一个masked Transformer,其中输入是映射的T5嵌入和图像token.
研究人员将所有的文本嵌入设置为unmasked,随机mask掉一部分不同的图像token后,用一个特殊的[MASK]标记来代替原token.
然后将图像token线性地映射到所需的Transformer输入或hidden size维度的图像输入embedding中,并同时学习2D position embedding
和原始的Transformer架构一样,包括几个transformer层,使用自注意块、交叉注意力块和MLP块来提取特征。
在输出层,使用一个MLP将每个masked图像嵌入转换为一组logits(对应于VQGAN codebook的大小),并以ground truth的token为目标使用交叉熵损失。
在训练阶段,基础模型的训练目标为预测每一步的所有msked tokens;但在推理阶段,mask预测是以迭代的方式进行的,这种方式可以极大提高质量。
4. 超分辨率模型
研究人员发现,直接预测512×512分辨率的图像会导致模型专注于低层次的细节而非高层次的语义。
使用级联模型(cascade of models)则可以改善这种情况:
首先使用一个生成16×16 latent map(对应256×256的图像)的基础模型;然后是一个超分辨率模型,将基础latent map上采样为64×64(对应512×512的图像)。其中超分辨率模型是在基础模型训练完成后再进行训练的。
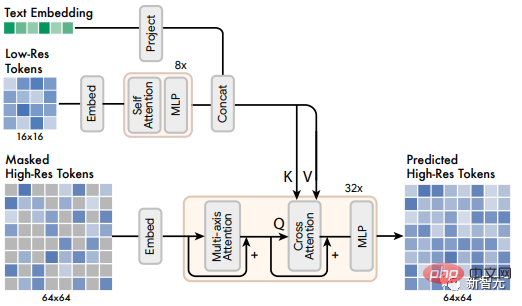
如前所述,研究人员总共训练了两个VQGAN模型,一个是16×16潜分辨率和256×256空间分辨率,另一个是64×64潜伏分辨率和512×512空间分辨率。
由于基础模型输出对应于16×16 latent map的token,所以超分辨率模块学会了将低分辨率的latent map 「翻译」成高分辨率的latent map,然后通过高分辨率的VQGAN解码,得到最终的高分辨率图像;该翻译模型也是以类似于基础模型的方式进行text conditioning和交叉注意力的训练。
5. 解码器微调
为了进一步提高模型生成细节的能力,研究人员选择通过增加VQGAN解码器的容量,添加更多的残差层(residual layer)和通道的同时保持编码器的容量不变。
然后对新的解码器进行微调,同时保持VQGAN编码器的权重、codebook和Transformers(即基础模型和超分辨率模型)不变。这种方式能够提高生成图像的视觉质量,而不需要重新训练任何其他的模型组件(因为视觉token保持固定)。

可以看到,经过微调的解码器以重建更多更清晰的细节。
6. 可变掩码率(Masking Rate)
研究人员使用基于Csoine scheduling的可变掩码率来训练模型:对于每个训练例子,从截断的arccos分布中抽出一个掩码率r∈[0,1],其密度函数如下.
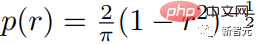
掩码率的期望值为0.64,也就是说更偏向于选择更高的掩码率,使得预测问题更加困难。
随机的掩码率不仅对并行采样方案至关重要,而且还能实现一些零散的、开箱即用的编辑功能。
7. Classifier Free Guidance(CFG)
研究人员采用无分类指导(CFG)来提高图像的生成质量和文本-图像对齐。
在训练时,在随机选择的10%的样本上去除文本条件,注意力机制降为图像token本身的自注意力。
在推理阶段,为每个被mask的token计算一个条件logit lc和一个无条件logit lu,然后通过从无条件logit中移出一个量t作为指导尺度,形成最终的logit lg:
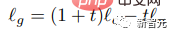
直观来看,CFG是以多样性换取保真度,但与以前方法不同的是,Muse通过采样过程线性地增加指导尺度t来减少多样性的损失,使得early token可以在低引导或无引导的情况下更自由地被取样,不过也增加了对later tokens条件提示的影响。
研究人员还利用这一机制,通过将无条件的logit lu替换为以negative prompt为条件的logit,促进了生成图像具有与postive prompt相关的特征。
8. 推理时迭代并行解码
在提升模型推理时间效率的一个关键部分是使用并行解码来预测单个前向通道中的多个输出token,其中一个关键假设是马尔科夫属性,即许多token是有条件地独立于给定的其他token的。
其中解码是根据cosine schedule进行的,选择固定比例中最高置信度的掩码进行预测,其中token在剩余的步中被设定为unmasked,并且适当减少masked tokens。
根据上述过程,就可以在基本模型中只用24个解码步(step)实现对256个token的推理,在超分辨率模型中用8个解码步对4096个token进行推理,相比之下,自回归模型需要256或4096步,扩散模型需要数百步。
虽然最近的一些研究包括progressive distillation、better ODE solver大大减少了扩散模型的采样步骤,但这些方法还没有在大规模的文本到图像生成中得到广泛验证。
实验结果
研究人员以不同的参数量(从600M到3B),基于T5-XXL训练了一系列基础Transformer模型。
生成图像的质量
实验中测试了Muse模型对于不同属性的文本提示的能力,包括对cardinality的基本理解,对于非单数的物体,Muse并没有多次生成相同的物体像素,而是增加了上下文的变化,使整个图像更加真实。

例如,大象的大小和方向、酒瓶包装纸的颜色以及网球的旋转等等。
定量比较
研究人员在CC3M和COCO数据集上与其他研究方法进行了实验对比,指标包括衡量样本质量和多样性的Frechet Inception Distance(FID),以及衡量图像/文本对齐的CLIP得分。
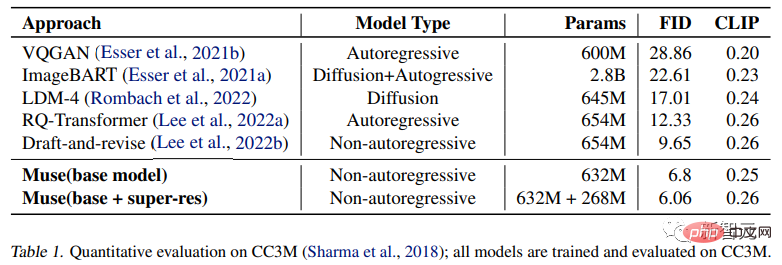
实验结果证明了632M的Muse模型在CC3M上取得了SOTA结果,在FID得分方面得到了改善,同时也取得了最先进的CLIP得分。
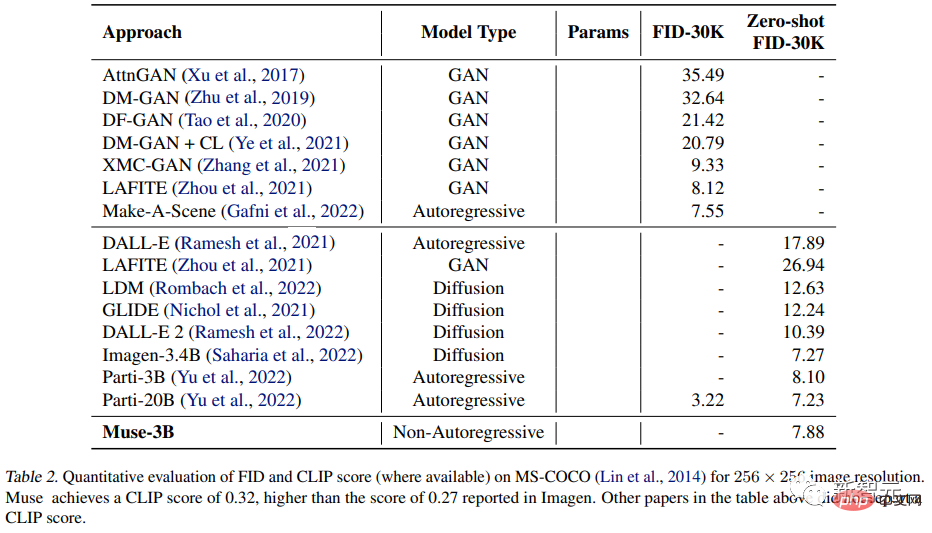
在MS-COCO数据集上,3B模型取得了7.88分的FID得分,略好于相似参数量的Parti-3B模型取得的8.1分。
以上是Transformer再胜Diffusion!谷歌发布新一代文本-图像生成模型Muse:生成效率提升十倍的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 deepseek怎么评论
Feb 19, 2025 pm 05:42 PM
deepseek怎么评论
Feb 19, 2025 pm 05:42 PM
DeepSeek是一款功能强大的信息检索工具,其优势在于能够深入挖掘信息,但缺点是速度较慢、结果呈现方式较简单且数据库覆盖范围有限,需要根据具体需求权衡其利弊。
 deepseek怎么搜索
Feb 19, 2025 pm 05:39 PM
deepseek怎么搜索
Feb 19, 2025 pm 05:39 PM
DeepSeek是一个专有搜索引擎,仅在特定数据库或系统中搜索,速度更快,准确性更高。使用时,建议用户阅读文档、尝试不同的搜索策略、寻求帮助和反馈使用体验,以便充分利用其优势。
 芝麻开门交易所网页注册链接 gate交易app注册网址最新
Feb 28, 2025 am 11:06 AM
芝麻开门交易所网页注册链接 gate交易app注册网址最新
Feb 28, 2025 am 11:06 AM
本文详细介绍了芝麻开门交易所(Gate.io)网页版和Gate交易App的注册流程。 无论是网页注册还是App注册,都需要访问官方网站或应用商店下载正版App,然后填写用户名、密码、邮箱和手机号等信息,并完成邮箱或手机验证。
 Bybit交易所链接为什么不能直接下载安装?
Feb 21, 2025 pm 10:57 PM
Bybit交易所链接为什么不能直接下载安装?
Feb 21, 2025 pm 10:57 PM
为什么Bybit交易所链接无法直接下载安装?Bybit是一个加密货币交易所,为用户提供交易服务。该交易所的移动应用程序不能直接通过AppStore或GooglePlay下载,原因如下:1.应用商店政策限制苹果公司和谷歌公司对应用商店中允许的应用程序类型有严格的要求。加密货币交易所应用程序通常不符合这些要求,因为它们涉及金融服务,需要遵循特定的法规和安全标准。2.法律法规合规在许多国家/地区,与加密货币交易相关的活动都受到监管或限制。为了遵守这些规定,Bybit应用程序只能通过官方网站或其他授权渠

 加密数字资产交易APP推荐top10(2025全球排名)
Mar 18, 2025 pm 12:15 PM
加密数字资产交易APP推荐top10(2025全球排名)
Mar 18, 2025 pm 12:15 PM
本文推荐十大值得关注的加密货币交易平台,涵盖币安(Binance)、OKX、Gate.io、BitFlyer、KuCoin、Bybit、Coinbase Pro、Kraken、BYDFi和XBIT去中心化交易所。这些平台在交易币种数量、交易类型、安全性、合规性、特色功能等方面各有千秋,例如币安以其全球最大的交易量和丰富的功能着称,而BitFlyer则凭借其日本金融厅牌照和高安全性吸引亚洲用户。选择合适的平台需要根据自身交易经验、风险承受能力和投资偏好进行综合考量。 希望本文能帮助您找到最适合自
 芝麻开门交易所网页版登入口 最新版gateio官网入口
Mar 04, 2025 pm 11:48 PM
芝麻开门交易所网页版登入口 最新版gateio官网入口
Mar 04, 2025 pm 11:48 PM
详细介绍芝麻开门交易所网页版登入口操作,含登录步骤、找回密码流程,还针对登录失败、无法打开页面、收不到验证码等常见问题提供解决方法,助你顺利登录平台。
 币安binance官网最新版登录入口
Feb 21, 2025 pm 05:42 PM
币安binance官网最新版登录入口
Feb 21, 2025 pm 05:42 PM
访问币安官方网站最新版登录入口,只需遵循这些简单步骤。前往官方网址,点击右上角的“登录”按钮。选择您现有的登录方式,如果是新用户,请“注册”。输入您的注册手机号或邮箱和密码,并完成身份验证(例如手机验证码或谷歌身份验证器)。成功验证后,即可访问币安官方网站的最新版登录入口。
