

Python多线程是什么及怎么用

什么是线程?你为什么想要它?
从本质上讲,Python是一种线性语言,但当你需要更多的处理能力时,线程模块非常方便。虽然Python中的线程不能用于并行CPU计算,但它非常适合I/O操作,如web抓取,因为处理器处于空闲状态,等待数据。
线程正在改变游戏规则,因为许多与网络/数据I/O相关的脚本将大部分时间用于等待来自远程源的数据。由于下载可能没有链接(即,抓取单独的网站),处理器可以并行地从不同的数据源下载,并在最后合并结果。对于CPU密集型进程,使用线程模块没有什么好处。
幸运的是,线程包含在标准库中:
import threading from queue import Queue import time
你可以使用target作为可调用对象,使用args将参数传递给函数,并start启动线程。
def testThread(num): print num if __name__ == '__main__': for i in range(5): t = threading.Thread(target=testThread, arg=(i,)) t.start()
如果你以前从未见过if __name__ == '__main__':,这基本上是一种确保嵌套在其中的代码仅在脚本直接运行(而不是导入)时运行的方法。
锁
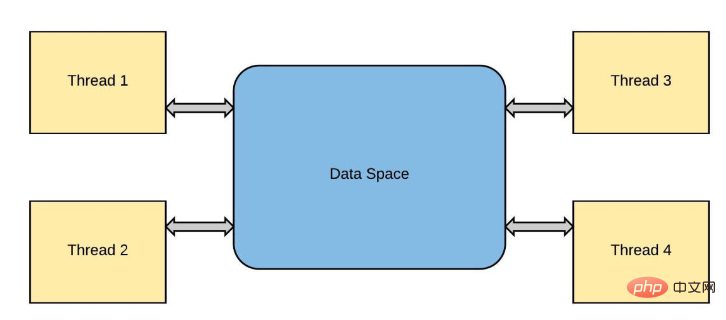
同一操作系统进程的线程将计算工作负载分布到多个内核中,如C++和Java等编程语言所示。通常,python只使用一个进程,从该进程生成一个主线程来执行运行时。由于一种称为全局解释器锁(global interpreter lock)的锁定机制,它保持在单个核上,而不管计算机有多少核,也不管产生了多少新线程,这种机制是为了防止所谓的竞争条件。
提到竞争,我想到了想到 NASCAR 和一级方程式赛车。让我们用这个类比,想象所有一级方程式赛车手都试图同时在一辆赛车上比赛。听起来很荒谬,对吧?,这只有在每个司机都可以使用自己的车的情况下才有可能,或者最好还是一次跑一圈,每次把车交给下一个司机。
这与线程中发生的情况非常相似。线程是从“主”线程“派生”的,每个后续线程都是前一个线程的副本。这些线程都存在于同一进程“上下文”(事件或竞争)中,因此分配给该进程的所有资源(如内存)都是共享的。例如,在典型的python解释器会话中:
>>> a = 8
在这里,a 通过让内存中的某个任意位置暂时保持值 8 来消耗很少的内存 (RAM)。
到目前为止一切顺利,让我们启动一些线程并观察它们的行为,当添加两个数字x时y:
import time
import threading
from threading import Thread
a = 8
def threaded_add(x, y):
# simulation of a more complex task by asking
# python to sleep, since adding happens so quick!
for i in range(2):
global a
print("computing task in a different thread!")
time.sleep(1)
#this is not okay! but python will force sync, more on that later!
a = 10
print(a)
# the current thread will be a subset fork!
if __name__ != "__main__":
current_thread = threading.current_thread()
# here we tell python from the main
# thread of execution make others
if __name__ == "__main__":
thread = Thread(target = threaded_add, args = (1, 2))
thread.start()
thread.join()
print(a)
print("main thread finished...exiting")>>> computing task in a different thread! >>> 10 >>> computing task in a different thread! >>> 10 >>> 10 >>> main thread finished...exiting
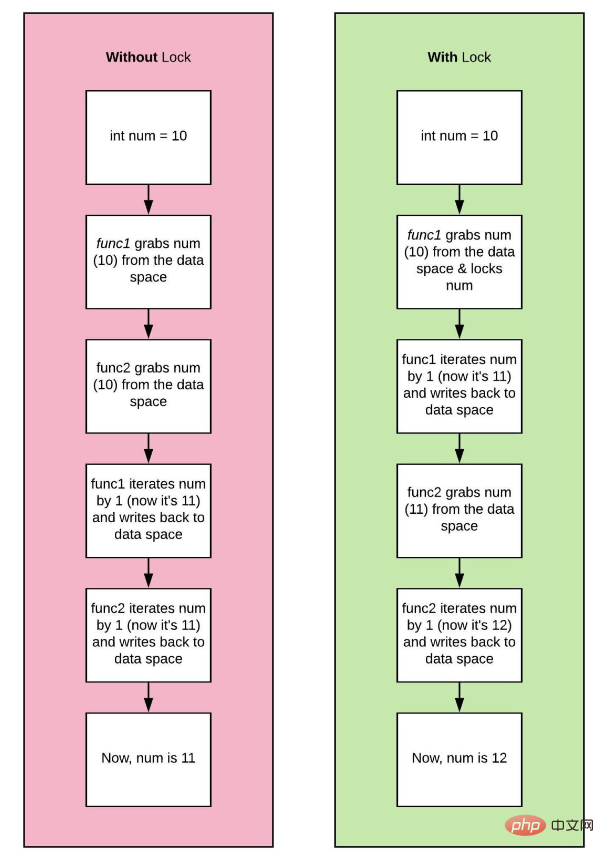
两个线程当前正在运行。让我们把它们称为thread_one和thread_two。如果thread_one想要用值10修改a,而thread_two同时尝试更新同一变量,我们就有问题了!将出现称为数据竞争的情况,并且a的结果值将不一致。
一场你没有看的赛车比赛,但从你的两个朋友那里听到了两个相互矛盾的结果!thread_one告诉你一件事,thread two反驳了这一点!这里有一个伪代码片段说明:
a = 8 # spawns two different threads 1 and 2 # thread_one updates the value of a to 10 if (a == 10): # a check #thread_two updates the value of a to 15 a = 15 b = a * 2 # if thread_one finished first the result will be 20 # if thread_two finished first the result will be 30 # who is right?
到底是怎么回事?
Python是一种解释语言,这意味着它带有一个解释器——一个从另一种语言解析其源代码的程序!python中的一些此类解释器包括cpython、pypypy、Jpython和IronPython,其中,cpython是python的原始实现。
CPython是一个解释器,它提供与C以及其他编程语言的外部函数接口,它将python源代码编译成中间字节码,由CPython虚拟机进行解释。迄今为止和未来的讨论都是关于CPython和理解环境中的行为。
内存模型和锁定机制
编程语言使用程序中的对象来执行操作。这些对象由基本数据类型组成,如string、integer或boolean。它们还包括更复杂的数据结构,如list或classes/objects。程序对象的值存储在内存中,以便快速访问。在程序中使用变量时,进程将从内存中读取值并对其进行操作。在早期的编程语言中,大多数开发人员负责他们程序中的所有内存管理。这意味着在创建列表或对象之前,首先必须为变量分配内存。在这样做时,你可以继续释放以“释放”内存。
在python中,对象通过引用存储在内存中。引用是对象的一种标签,因此一个对象可以有许多名称,比如你如何拥有给定的名称和昵称。引用是对象的精确内存位置。引用计数器用于python中的垃圾收集,这是一种自动内存管理过程。
在引用计数器的帮助下,python通过在创建或引用对象时递增引用计数器和在取消引用对象时递减来跟踪每个对象。当引用计数为0时,对象的内存将被释放。
import sys import gc hello = "world" #reference to 'world' is 2 print (sys.getrefcount(hello)) bye = "world" other_bye = bye print(sys.getrefcount(bye)) print(gc.get_referrers(other_bye))
>>> 4
>>> 6
>>> [['sys', 'gc', 'hello', 'world', 'print', 'sys', 'getrefcount', 'hello', 'bye', 'world', 'other_bye', 'bye', 'print', 'sys', 'getrefcount', 'bye', 'print', 'gc', 'get_referrers', 'other_bye'], (0, None, 'world'), {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0138ADF0>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'test.py', '__cached__': None, 'sys': <module 'sys' (built-in)>, 'gc': <module 'gc' (built-in)>, 'hello': 'world', 'bye': 'world', 'other_bye': 'world'}]需要保护这些参考计数器变量,防止竞争条件或内存泄漏。以保护这些变量;可以将锁添加到跨线程共享的所有数据结构中。
CPython 的 GIL 通过一次允许一个线程控制解释器来控制 Python 解释器。它为单线程程序提供了性能提升,因为只需要管理一个锁,但代价是它阻止了多线程 CPython 程序在某些情况下充分利用多处理器系统。
当用户编写python程序时,性能受CPU限制的程序和受I/O限制的程序之间存在差异。CPU通过同时执行许多操作将程序推到极限,而I/O程序必须花费时间等待I/O。
因此,只有多线程程序在GIL中花费大量时间来解释CPython字节码;GIL成为瓶颈。即使没有严格必要,GIL也会降低性能。例如,一个用python编写的同时处理IO和CPU任务的程序:
import time, os
from threading import Thread, current_thread
from multiprocessing import current_process
COUNT = 200000000
SLEEP = 10
def io_bound(sec):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start sleeping...")
time.sleep(sec)
print(f"{pid} * {processName} * {threadName} \
---> Finished sleeping...")
def cpu_bound(n):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start counting...")
while n>0:
n -= 1
print(f"{pid} * {processName} * {threadName} \
---> Finished counting...")
def timeit(function,args,threaded=False):
start = time.time()
if threaded:
t1 = Thread(target = function, args =(args, ))
t2 = Thread(target = function, args =(args, ))
t1.start()
t2.start()
t1.join()
t2.join()
else:
function(args)
end = time.time()
print('Time taken in seconds for running {} on Argument {} is {}s -{}'.format(function,args,end - start,"Threaded" if threaded else "None Threaded"))
if __name__=="__main__":
#Running io_bound task
print("IO BOUND TASK NON THREADED")
timeit(io_bound,SLEEP)
print("IO BOUND TASK THREADED")
#Running io_bound task in Thread
timeit(io_bound,SLEEP,threaded=True)
print("CPU BOUND TASK NON THREADED")
#Running cpu_bound task
timeit(cpu_bound,COUNT)
print("CPU BOUND TASK THREADED")
#Running cpu_bound task in Thread
timeit(cpu_bound,COUNT,threaded=True)>>> IO BOUND TASK NON THREADED >>> 17244 * MainProcess * MainThread ---> Start sleeping... >>> 17244 * MainProcess * MainThread ---> Finished sleeping... >>> 17244 * MainProcess * MainThread ---> Start sleeping... >>> 17244 * MainProcess * MainThread ---> Finished sleeping... >>> Time taken in seconds for running <function io_bound at 0x00C50810> on Argument 10 is 20.036664724349976s -None Threaded >>> IO BOUND TASK THREADED >>> 10180 * MainProcess * Thread-1 ---> Start sleeping... >>> 10180 * MainProcess * Thread-2 ---> Start sleeping... >>> 10180 * MainProcess * Thread-1 ---> Finished sleeping... >>> 10180 * MainProcess * Thread-2 ---> Finished sleeping... >>> Time taken in seconds for running <function io_bound at 0x01B90810> on Argument 10 is 10.01464056968689s -Threaded >>> CPU BOUND TASK NON THREADED >>> 14172 * MainProcess * MainThread ---> Start counting... >>> 14172 * MainProcess * MainThread ---> Finished counting... >>> 14172 * MainProcess * MainThread ---> Start counting... >>> 14172 * MainProcess * MainThread ---> Finished counting... >>> Time taken in seconds for running <function cpu_bound at 0x018F4468> on Argument 200000000 is 44.90199875831604s -None Threaded >>> CPU BOUND TASK THEADED >>> 15616 * MainProcess * Thread-1 ---> Start counting... >>> 15616 * MainProcess * Thread-2 ---> Start counting... >>> 15616 * MainProcess * Thread-1 ---> Finished counting... >>> 15616 * MainProcess * Thread-2 ---> Finished counting... >>> Time taken in seconds for running <function cpu_bound at 0x01E44468> on Argument 200000000 is 106.09711360931396s -Threaded
从结果中我们注意到,multithreading在多个IO绑定任务中表现出色,执行时间为10秒,而非线程方法执行时间为20秒。我们使用相同的方法执行CPU密集型任务。好吧,最初它确实同时启动了我们的线程,但最后,我们看到整个程序的执行需要大约106秒!然后发生了什么?这是因为当Thread-1启动时,它获取全局解释器锁(GIL),这防止Thread-2使用CPU。因此,Thread-2必须等待Thread-1完成其任务并释放锁,以便它可以获取锁并执行其任务。锁的获取和释放增加了总执行时间的开销。因此,可以肯定地说,线程不是依赖CPU执行任务的理想解决方案。
这种特性使并发编程变得困难。如果GIL在并发性方面阻碍了我们,我们是不是应该摆脱它,还是能够关闭它?。嗯,这并不容易。其他功能、库和包都依赖于GIL,因此必须有一些东西来取代它,否则整个生态系统将崩溃。这是一个很难解决的问题。
多进程
我们已经证实,CPython使用锁来保护数据不受竞速的影响,尽管这种锁存在,但程序员已经找到了一种显式实现并发的方法。当涉及到GIL时,我们可以使用multiprocessing库来绕过全局锁。多处理实现了真正意义上的并发,因为它在不同CPU核上跨不同进程执行代码。它创建了一个新的Python解释器实例,在每个内核上运行。不同的进程位于不同的内存位置,因此它们之间的对象共享并不容易。在这个实现中,python为每个要运行的进程提供了不同的解释器;因此在这种情况下,为多处理中的每个进程提供单个线程。
import os
import time
from multiprocessing import Process, current_process
SLEEP = 10
COUNT = 200000000
def count_down(cnt):
pid = os.getpid()
processName = current_process().name
print(f"{pid} * {processName} \
---> Start counting...")
while cnt > 0:
cnt -= 1
def io_bound(sec):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start sleeping...")
time.sleep(sec)
print(f"{pid} * {processName} * {threadName} \
---> Finished sleeping...")
if __name__ == '__main__':
# creating processes
start = time.time()
#CPU BOUND
p1 = Process(target=count_down, args=(COUNT, ))
p2 = Process(target=count_down, args=(COUNT, ))
#IO BOUND
#p1 = Process(target=, args=(SLEEP, ))
#p2 = Process(target=count_down, args=(SLEEP, ))
# starting process_thread
p1.start()
p2.start()
# wait until finished
p1.join()
p2.join()
stop = time.time()
elapsed = stop - start
print ("The time taken in seconds is :", elapsed)>>> 1660 * Process-2 ---> Start counting... >>> 10184 * Process-1 ---> Start counting... >>> The time taken in seconds is : 12.815475225448608
可以看出,对于cpu和io绑定任务,multiprocessing性能异常出色。MainProcess启动了两个子进程,Process-1和Process-2,它们具有不同的PIDs,每个都执行将COUNT减少到零的任务。每个进程并行运行,使用单独的CPU内核和自己的Python解释器实例,因此整个程序执行只需12秒。
请注意,输出可能以无序的方式打印,因为过程彼此独立。这是因为每个进程都在自己的默认主线程中执行函数。
我们还可以使用asyncio库(上一节我已经讲过了,没看的可以返回到上一节去学习)绕过GIL锁。asyncio的基本概念是,一个称为事件循环的python对象控制每个任务的运行方式和时间。事件循环知道每个任务及其状态。就绪状态表示任务已准备好运行,等待阶段表示任务正在等待某个外部任务完成。在异步IO中,任务永远不会放弃控制,也不会在执行过程中被中断,因此对象共享是线程安全的。
import time
import asyncio
COUNT = 200000000
# asynchronous function defination
async def func_name(cnt):
while cnt > 0:
cnt -= 1
#asynchronous main function defination
async def main ():
# Creating 2 tasks.....You could create as many tasks (n tasks)
task1 = loop.create_task(func_name(COUNT))
task2 = loop.create_task(func_name(COUNT))
# await each task to execute before handing control back to the program
await asyncio.wait([task1, task2])
if __name__ =='__main__':
# get the event loop
start_time = time.time()
loop = asyncio.get_event_loop()
# run all tasks in the event loop until completion
loop.run_until_complete(main())
loop.close()
print("--- %s seconds ---" % (time.time() - start_time))>>> --- 41.74118399620056 seconds ---
我们可以看到,asyncio需要41秒来完成倒计时,这比multithreading的106秒要好,但对于cpu受限的任务,不如multiprocessing的12秒。Asyncio创建一个eventloop和两个任务task1和task2,然后将这些任务放在eventloop上。然后,程序await任务的执行,因为事件循环执行所有任务直至完成。
为了充分利用python中并发的全部功能,我们还可以使用不同的解释器。JPython和IronPython没有GIL,这意味着用户可以充分利用多处理器系统。
与线程一样,多进程仍然存在缺点:
数据在进程之间混洗会产生 I/O 开销
整个内存被复制到每个子进程中,这对于更重要的程序来说可能是很多开销
以上是Python多线程是什么及怎么用的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题
 7654
7654
 15
1393
52
91
11
73
19
37
110
15
1393
52
91
11
73
19
37
110

 PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP和Python:解释了不同的范例
Apr 18, 2025 am 12:26 AM
PHP主要是过程式编程,但也支持面向对象编程(OOP);Python支持多种范式,包括OOP、函数式和过程式编程。PHP适合web开发,Python适用于多种应用,如数据分析和机器学习。
 在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
在PHP和Python之间进行选择:指南
Apr 18, 2025 am 12:24 AM
PHP适合网页开发和快速原型开发,Python适用于数据科学和机器学习。1.PHP用于动态网页开发,语法简单,适合快速开发。2.Python语法简洁,适用于多领域,库生态系统强大。
 visual studio code 可以用于 python 吗
Apr 15, 2025 pm 08:18 PM
visual studio code 可以用于 python 吗
Apr 15, 2025 pm 08:18 PM
VS Code 可用于编写 Python,并提供许多功能,使其成为开发 Python 应用程序的理想工具。它允许用户:安装 Python 扩展,以获得代码补全、语法高亮和调试等功能。使用调试器逐步跟踪代码,查找和修复错误。集成 Git,进行版本控制。使用代码格式化工具,保持代码一致性。使用 Linting 工具,提前发现潜在问题。
 vs code 可以在 Windows 8 中运行吗
Apr 15, 2025 pm 07:24 PM
vs code 可以在 Windows 8 中运行吗
Apr 15, 2025 pm 07:24 PM
VS Code可以在Windows 8上运行,但体验可能不佳。首先确保系统已更新到最新补丁,然后下载与系统架构匹配的VS Code安装包,按照提示安装。安装后,注意某些扩展程序可能与Windows 8不兼容,需要寻找替代扩展或在虚拟机中使用更新的Windows系统。安装必要的扩展,检查是否正常工作。尽管VS Code在Windows 8上可行,但建议升级到更新的Windows系统以获得更好的开发体验和安全保障。
 vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
vscode 扩展是否是恶意的
Apr 15, 2025 pm 07:57 PM
VS Code 扩展存在恶意风险,例如隐藏恶意代码、利用漏洞、伪装成合法扩展。识别恶意扩展的方法包括:检查发布者、阅读评论、检查代码、谨慎安装。安全措施还包括:安全意识、良好习惯、定期更新和杀毒软件。
 Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript:学习曲线和易用性
Apr 16, 2025 am 12:12 AM
Python更适合初学者,学习曲线平缓,语法简洁;JavaScript适合前端开发,学习曲线较陡,语法灵活。1.Python语法直观,适用于数据科学和后端开发。2.JavaScript灵活,广泛用于前端和服务器端编程。
 PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP和Python:深入了解他们的历史
Apr 18, 2025 am 12:25 AM
PHP起源于1994年,由RasmusLerdorf开发,最初用于跟踪网站访问者,逐渐演变为服务器端脚本语言,广泛应用于网页开发。Python由GuidovanRossum于1980年代末开发,1991年首次发布,强调代码可读性和简洁性,适用于科学计算、数据分析等领域。
 vscode怎么在终端运行程序
Apr 15, 2025 pm 06:42 PM
vscode怎么在终端运行程序
Apr 15, 2025 pm 06:42 PM
在 VS Code 中,可以通过以下步骤在终端运行程序:准备代码和打开集成终端确保代码目录与终端工作目录一致根据编程语言选择运行命令(如 Python 的 python your_file_name.py)检查是否成功运行并解决错误利用调试器提升调试效率
