
1 2 3 4 |
|
1 2 3 4 5 6 7 8 9 |
|
1 2 3 4 5 6 7 |
|
配置logback-spring.xml日志,非必要配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
|
1 2 3 4 5 6 7 8 9 10 |
|
创建UserRepository ,继承MongoRepository,并指定实体类型和主键类型
在MongoRepository中定义了很多现成的方法,可以更方便的使用。
Spring Data mongodb也提供了自定义方法的规则,按照findByXXX,findByXXXAndYYY、countByXXXAndYYY等规则定义方法,实现查询操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 |
|
GridFS是MongoDB提供的用于持久化存储文件的模块。
工作原理:
GridFS存储文件是将文件分块存储,文件会按照256KB的大小分割成多个块进行存储,GridFS使用两个集合(collection)存储文件,一个集合是chunks, 用于存储文件的二进制数据;一个集合是files,用于存储文件的元数据信息(文件名称、块大小、上传时间等信息)。
特点:
用于存储和恢复超过16M(BSON文件限制)的文件(如:图片、音频、视频等)
是文件存储的一种方式,但它是存储在MonoDB的集合中
可以更好的存储大于16M的文件
会将大文件对象分割成多个小的chunk(文件片段),一般为256k/个,每个chunk将作为MongoDB的一个文档(document)被存储在chunks集合中
用两个集合来存储一个文件:fs.files与fs.chunks
每个文件的实际内容被存在chunks(二进制数据)中,和文件有关的meta数据(filename,content_type,还有用户自定义的属性)将会被存在files集合中。
详细参考:官网文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
文件存储成功得到一个文件id,该文件id是fs.files集合中的主键
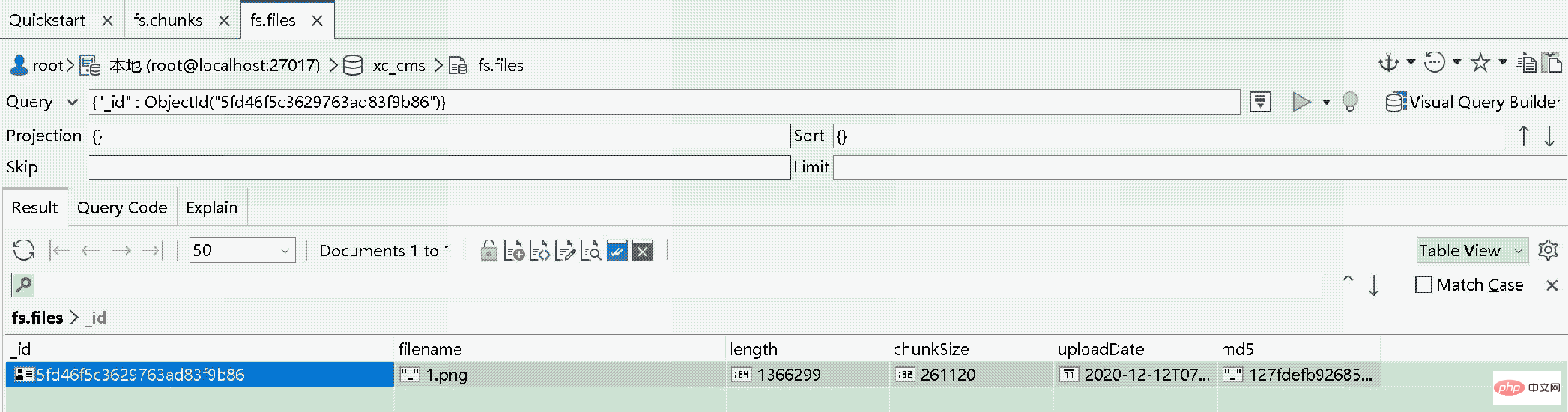
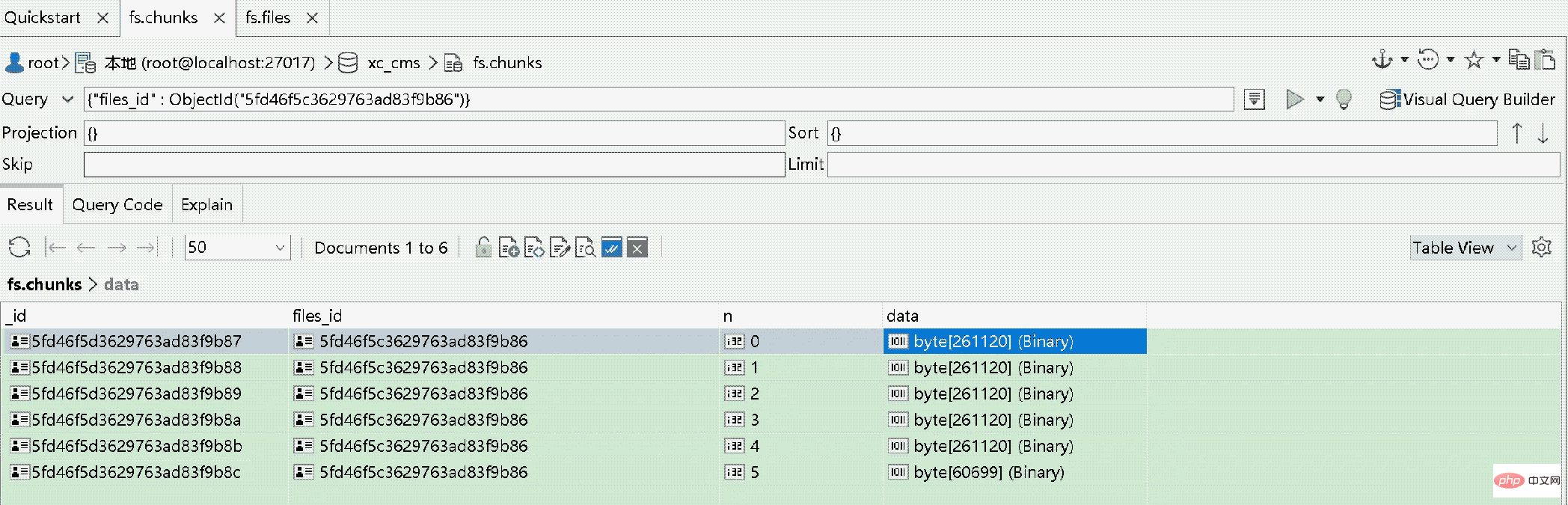
可以通过文件id查询fs.chunks表中的记录,得到文件的内容。
当GridFS中读取文件时,若文件分成多块,需要对文件的各分块进行组装、合并
定义一个Mongodb的配置类,初始化项目时创建一个GridFSBucket对象,用于打开下载流对象。
1 2 3 4 5 6 7 8 9 10 11 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|

1 2 3 4 5 6 7 |
|
以上是SpringBoot MongoDB与MongoDB GridFS怎么使用的详细内容。更多信息请关注PHP中文网其他相关文章!





















