

脑补出新视角,一个统一的NeRF代码库框架已开源

假设一个物体你看了几张照片后,能想象出其它角度看上去的感觉吗?人是可以做到的,我们能自行推测出没见过的部分,或者说没见过的角度是什么样的。模型其实也有办法做到,给定一些场景图片,它也能脑补出一些未见过角度的图像。
渲染新视角,近来最引人瞩目的就是 ECCV 2020 最佳论文荣誉提名的 NeRF (Neural Radiance Field)了,它不需要以前复杂的三维重建过程,只需要几张照片及 拍摄该照片时相机的位置,就能合成新视角下的图像。NeRF 惊艳的效果吸引了很多视觉方面的研究者,后续做出了一系列优秀的工作。
但困难的地方在于,这样的模型构建起来比较复杂,目前也没有一个统一的代码库框架来实现它们,这无疑会阻碍该领域的进一步探索与发展。为此,OpenXRLab 渲染生成平台构建出高度模块化的算法库 XRNeRF,帮助快速实现 NeRF 类模型的构建、训练与推理。
开源地址:https://github.com/openxrlab/xrnerf
什么是 NeRF 类模型
NeRF 类任务,一般指的是在已知视角下捕获场景信息, 包括拍摄到的图像,以及每张图像对应的内参外参,从而合成新视角下的图像。借助 NeRF 论文中的图,我们能很清晰地理解这种任务。
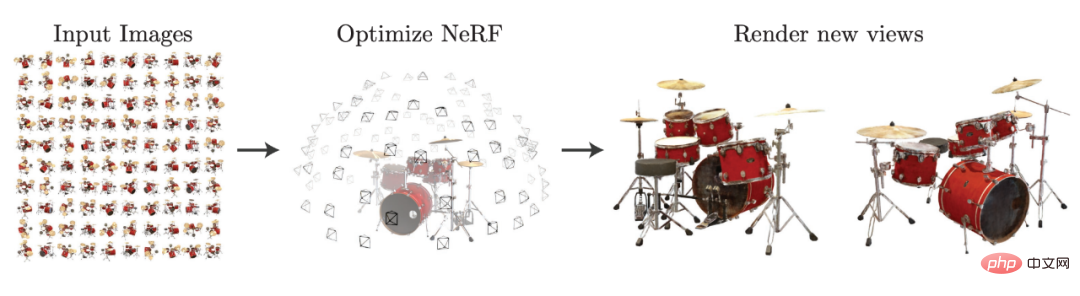
选自 arxiv: 2003.08934。
NeRF 在收集图像时会同时收集 5 维场景信息,即一张图像对应一个三维坐标值及另外两个光线辐射角度。这样的场景会通过多层感知机建模为 Radiance Field,也就是说该多层感知机将输入三维坐标点并映射为该点的 Density 和 RGB 颜色,从而利用体素渲染(Volume Rendering)将 Radiance Field 渲染为照片级的虚拟视角。
如上图所示,通过一些图片构建 Radiance Field 后,就能生成新视角下架子鼓的图像。因为 NeRF 并不需要显式地进行三维重建就能得到想要的新视角,所以它提供了一种基于深度学习的三维隐式表征范式,仅使用 2D 的 posed images 数据就能训练出包含 3D 场景信息的深度神经网络。
自 NeRF 之后,类 NeRF 的模型就层出不穷:Mip-NeRF 利用椎体而不是射线从而优化精细结构的生成效果;KiloNeRF 采用数以千计的微型多层感知机而不是单个大型多层感知机,降低计算量,实现实时渲染能力;此外 AniNeRF 和 Neural Body 等模型从简短视频帧中学习人体视角变换,得到很好的视角合成和驱动效果;此外,GN’R 模型利用稀疏视角图片与几何先验,实现不同 ID 间可泛化的人体渲染。

GN’R 提出的可泛化人体隐式场表征,实现的单模型人体渲染效果
为 NeRF 装上轮子
尽管当前 NeRF 类算法在研究领域具有非常高的热度,但是毕竟属于比较新的方法,所以模型实现上肯定是要麻烦一些的。如果是用 PyTorch 或 TensorFlow 这样常规的框架,那就首先得找个相近的 NeRF 模型,再在其基础上修改。
这样做会带来几个明显的问题,首先即我们得完全读懂一份实现,才能在其基础上改成我们想要的样子,这一部分其实工作量还是不小的;其次因为不同论文的官方实现并不统一,对比不同 NeRF 类模型源码时就会消耗比较大的精力,毕竟谁也不知道某篇论文的训练过程中是不是有一些新颖的 Trick;最后如果没有一套统一的代码,验证新模型的新想法无疑会慢很多。
为了解决众多问题,OpenXRLab 为 NeRF 类模型构造出一种统一的、高度模块化的代码库框架 XRNeRF。

XRNeRF 实现了众多 NeRF 模型,上手更为容易,可轻松复现相应论文的实验结果。XRNeRF 将这些模型分成 datasets、mlp、network、embedder 和 render 这 5 个模块。XRNeRF 的易用性在于,只需要通过 config 机制即能组装不同模块而构成完整模型,极其简单易用,同时也极大地增加了复用性。
在保证易用性的基础上,同时还需要灵活性,XRNeRF 通过另一套注册器机制,能定制化不同模块的具体特性或实现,从而使 XRNeRF 解耦性更强,代码也更易于理解。
此外,XRNeRF 所有实现的算法都是采用 Pipeline 的模式,数据上的 Pipeline 读取原始数据,经过一系列处理后获得模型的输入,模型的 Pipeline 则对输入的数据进行处理,获得对应的输出。这样的 Pipeline 将 config 机制与注册机机制串起来,组成了一个完整的架构。
XRNeRF 实现了众多核心 NeRF 模型,并通过如上三大机制将它们都串起来,构建出既易用又灵活的高度模块化代码框架。
XRNeRF 的核心特性
XRNeRF 是基于 Pytorch 框架的 NeRF 类 算法库,目前已经复现了 scene 和 body 两个方向的 8 篇经典论文。相比直接建模,XRNeRF 在搭模型效率、成本和灵活性上都有显著提升,而且有完善的使用文档、示例和 Issue 反馈机制,概括来说,XRNeRF 的核心特性大概有以下 5 点。
1. 实现了众多主流和核心的算法
例如开山之作 NeRF,CVPR 2021 Best Paper Candidate (NeuralBody)、ICCV 2021 Best Paper Honorable Mention (Mip-NeRF) 和 Siggraph 2022 Best Paper (Instant NGP)。

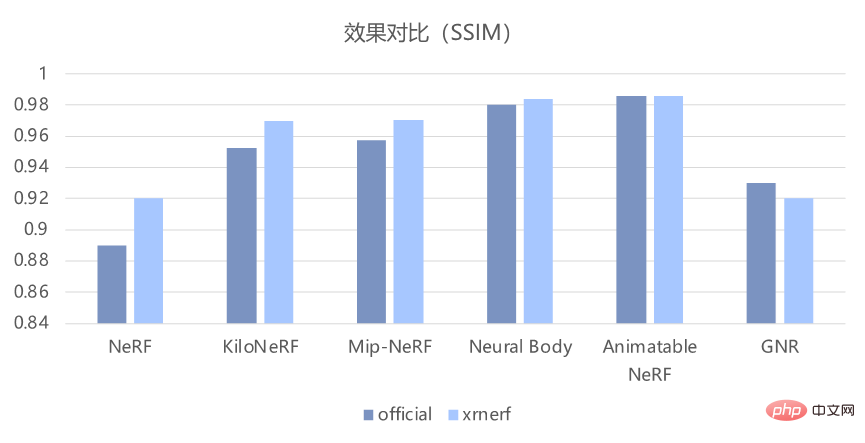
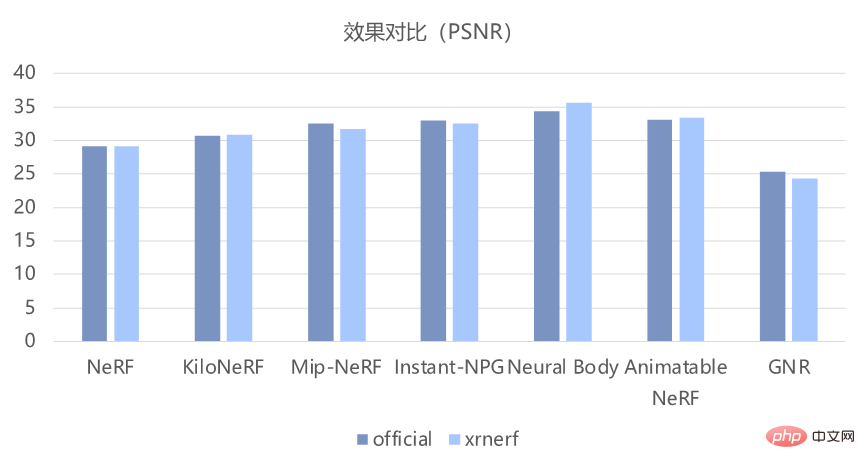
在实现了这些模型的基础上,XRNeRF 还能保证复现效果和论文中的基本一致。如下图所示,从客观的 PSNR 和 SSIM 指标来看,其能很好地复现原版代码的效果。
2. 模块化设计
XRNeRF 将整个代码框架进行了模块化设计,最大程度地提升了代码的可复用性,便于研究者对现有代码进行阅读和修改。通过分析现有的 NeRF 类模型方法,XRNeRF 设计的具体模块流程如下图所示:
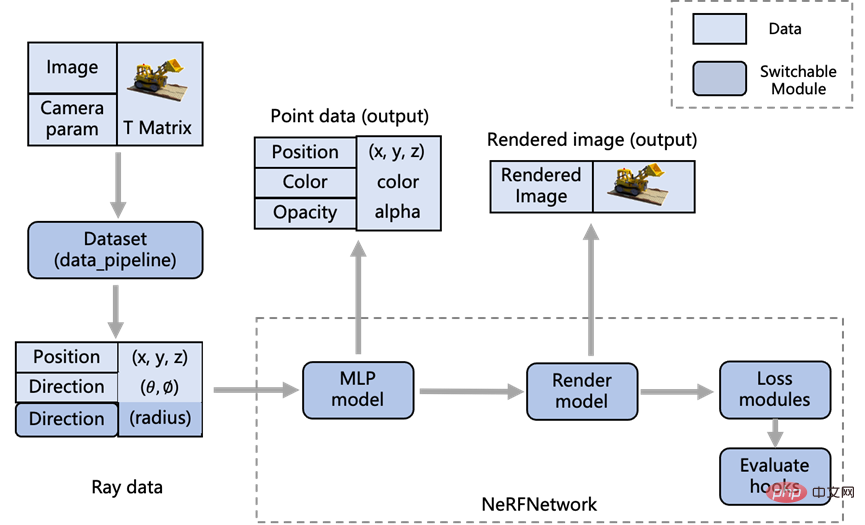
模块化的优势在于,假设我们需要修改数据格式,那只需要修改 Dataset 模块下的逻辑,假设我们需要修改渲染图像的逻辑,那就只需要修改 Render model 模块。
3. 标准数据处理管线
针对 NeRF 类算法数据预处理较为复杂和多样的问题,XRNeRF 提供了一套标准数据处理流程。其由多个数据处理操作串行得到,仅需要修改 config 配置文件中的 data pipeline 部分,即可完成数据处理流畅搭建。
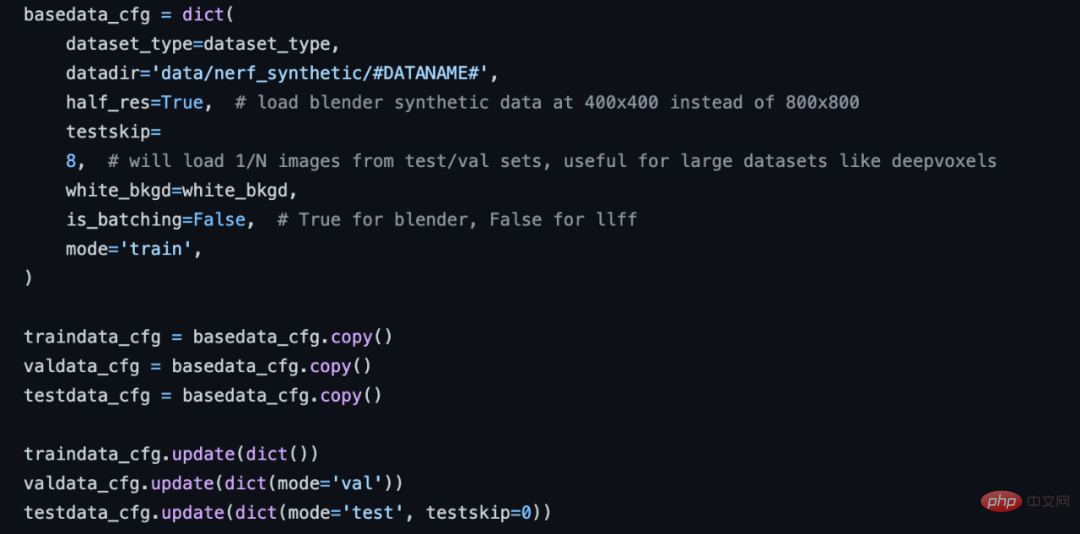
NeRF 配置数据流程部分。
XRNeRF 中已经实现了多个数据集所需要的数据处理 op,只需要将这些 op 在 config 中按照顺序定义好,即可完成数据处理流程的搭建。如果后续有新的 op 需要加入,也只需要在对应文件夹中完成新 op 的实现,即可一行代码加入到整个数据处理流程当中。
4. 模块化网络构建方式
XRNeRF 中的模型主要由 embedder、MLP 和 render model 组成,并通过 network 连接,这几者之间可以互相解耦,由此可以实现不同算法之间不同模块的替换。
其中 embedder 输入点的位置和视角,输出 embedded 特征数据;MLP 使用 embedder 的输出作为输入,输出采样点的 Density 和 RGB 颜色;render model 则输入 MLP 的输出结果,沿着射线上的点进行积分等操作,从而获得图像上一个像素点的 RGB 值。这三大模块再通过标准的 network 模块连接就构成了完整的模型。

自定义 network 模块的代码结构。
5. 良好的复现效果
支持最快 60 秒训练网络,30 帧每秒实时渲染,支持高清晰度、抗锯齿、多尺度场景及人体图像渲染。无论是从客观的 PSNR 和 SSIM 指标还是主观的 demo 展示效果来看,XRNeRF 都能很好地复现原版代码的效果。
XRNeRF 的使用
XRNeRF 框架看起来有非常好的特性,其使用起来也很简单便捷。比如说安装过程,XRNeRF 依赖的开发环境还是比较多的,PyTorch、CUDA 环境、视觉方面的处理库等等。但是 XRNeRF 提供了 Docker 环境,通过 DockerFile 能直接构建镜像文件。
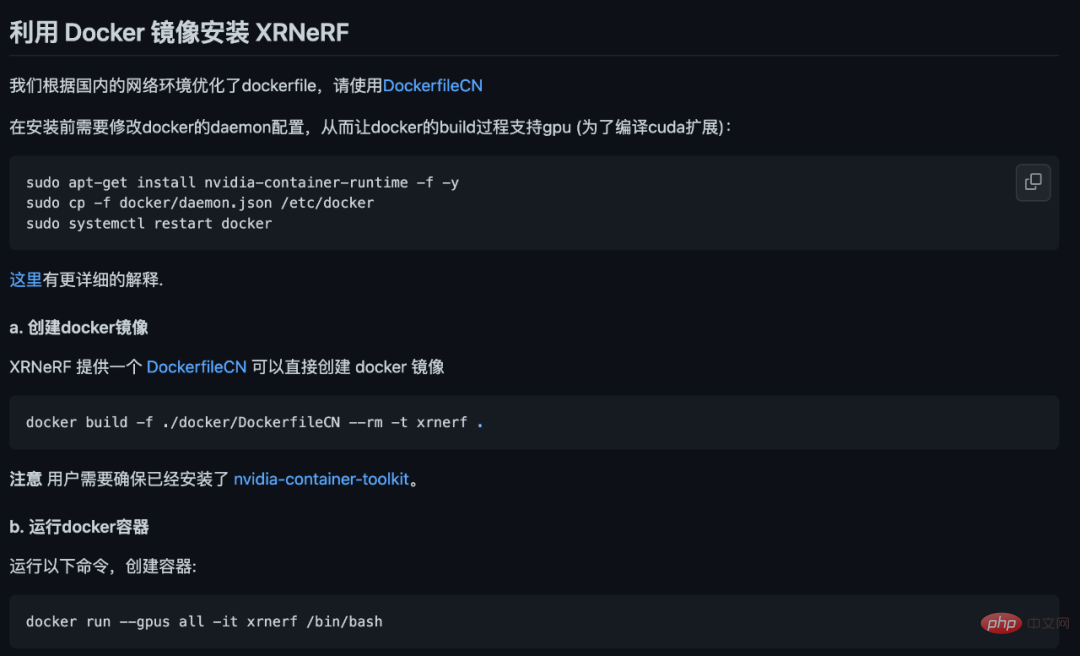
我们试了一下,相比一步步配置各种运行环境与包,只需 docker build 一行命令的配置方式显然要方便太多了。此外构建 Docker 镜像时,DockerFile 里面配置了国内镜像地址,所以速度还是很快的,基本不用担心网络问题。
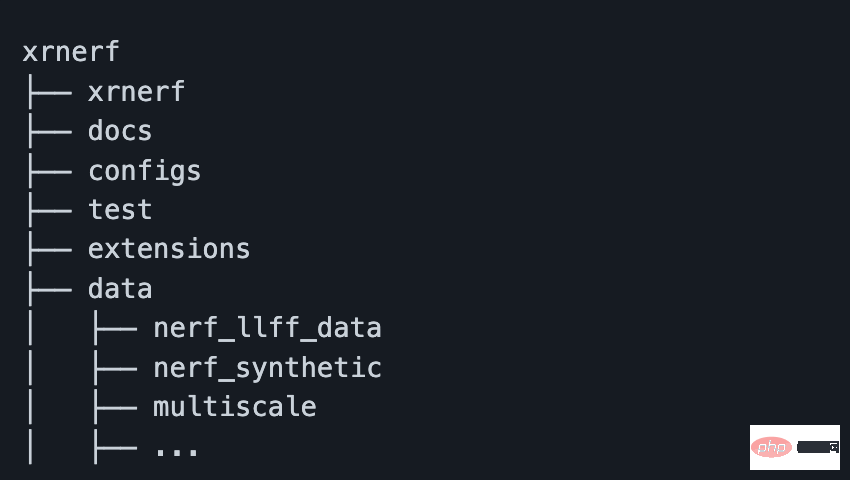
在构建完镜像,并从该镜像启动容器后,我们就能将项目代码,以及数据都通过 docker cp 命令传到容器内。不过也可以直接在创建容器时通过 -v 参数直接将项目地址映射到容器内部。不过这里需要注意的是,数据集是需要放到确定位置的(否则需要改 config 文件),例如 XRNeRF 项目下的 data 文件夹。
一般而言,下载完数据后,大概文件夹结构如下图所示:
现在,环境、数据与代码三者都准备好了,只需简短的一行代码,就能执行 NeFR 模型的训练与验证:
python run_nerf.py --config configs/nerf/nerf_blender_base01.py --dataname lego
其中 dataname 表示数据目录下的具体数据集,config 表示模型的具体配置文件。因为 XRNeRF 采用的是高度模块化的设计,其 config 使用字典来构建,虽然乍一看可能会觉得有一点点繁琐,但实际理解了 XRNeRF 的设计结构之后,阅读起来就非常简单了。
主观看上去,config 配置文件(nerf_blender_base01.py)包含了训练模型所有必要的信息,优化器、分布式策略、模型架构、数据预处理与迭代等等,甚至很多图像处理相关的配置也都包含在内。总结来说,除了具体的代码实现,config 配置文件描述了整个训练、推理过程。
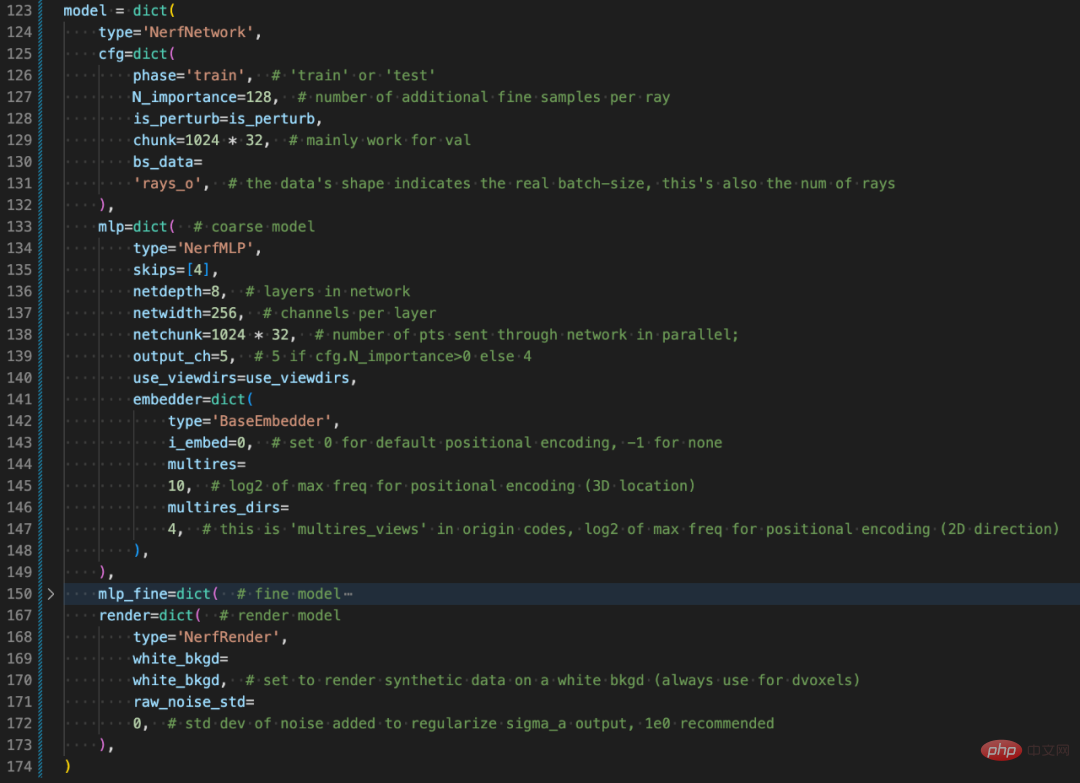
描述模型结构部分的 Config 配置。
总的体验起来,XRNeRF 从基础的运行环境搭建到最终执行训练任务都是比较流畅的。况且通过配置 config 文件,或者实现具体的 OP,同样也能获得非常高的建模灵活性。相比直接使用深度学习框架建模,XRNeRF 无疑将减少大量的开发工作,研究者或者算法工程师也能花更多时间在模型或任务创新上。
NeRF 类模型目前仍然是计算机视觉领域的研究重点,XRNeRF 这样统一的代码库,就像 HuggingFace 的 Transformer 库一样能聚集越来越多的优秀研究工作,聚集越来越多的新代码与新想法。反过来 XRNeRF 同样也将极大地加快研究者对 NeRF 类模型探索的脚步,便于将这一新领域应用到新场景与新任务中,NeRF 的潜力也将由此加速展开。
以上是脑补出新视角,一个统一的NeRF代码库框架已开源的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想象一下,一个人工智能模型,不仅拥有超越传统计算的能力,还能以更低的成本实现更高效的性能。这不是科幻,DeepSeek-V2[1],全球最强开源MoE模型来了。DeepSeek-V2是一个强大的专家混合(MoE)语言模型,具有训练经济、推理高效的特点。它由236B个参数组成,其中21B个参数用于激活每个标记。与DeepSeek67B相比,DeepSeek-V2性能更强,同时节省了42.5%的训练成本,减少了93.3%的KV缓存,最大生成吞吐量提高到5.76倍。DeepSeek是一家探索通用人工智
 AI颠覆数学研究!菲尔兹奖得主、华裔数学家领衔11篇顶刊论文|陶哲轩转赞
Apr 09, 2024 am 11:52 AM
AI颠覆数学研究!菲尔兹奖得主、华裔数学家领衔11篇顶刊论文|陶哲轩转赞
Apr 09, 2024 am 11:52 AM
AI,的确正在改变数学。最近,一直十分关注这个议题的陶哲轩,转发了最近一期的《美国数学学会通报》(BulletinoftheAmericanMathematicalSociety)。围绕「机器会改变数学吗?」这个话题,众多数学家发表了自己的观点,全程火花四射,内容硬核,精彩纷呈。作者阵容强大,包括菲尔兹奖得主AkshayVenkatesh、华裔数学家郑乐隽、纽大计算机科学家ErnestDavis等多位业界知名学者。AI的世界已经发生了天翻地覆的变化,要知道,其中很多文章是在一年前提交的,而在这一
 谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
Apr 01, 2024 pm 07:46 PM
谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
Apr 01, 2024 pm 07:46 PM
谷歌力推的JAX在最近的基准测试中性能已经超过Pytorch和TensorFlow,7项指标排名第一。而且测试并不是在JAX性能表现最好的TPU上完成的。虽然现在在开发者中,Pytorch依然比Tensorflow更受欢迎。但未来,也许有更多的大模型会基于JAX平台进行训练和运行。模型最近,Keras团队为三个后端(TensorFlow、JAX、PyTorch)与原生PyTorch实现以及搭配TensorFlow的Keras2进行了基准测试。首先,他们为生成式和非生成式人工智能任务选择了一组主流
 你好,电动Atlas!波士顿动力机器人复活,180度诡异动作吓坏马斯克
Apr 18, 2024 pm 07:58 PM
你好,电动Atlas!波士顿动力机器人复活,180度诡异动作吓坏马斯克
Apr 18, 2024 pm 07:58 PM
波士顿动力Atlas,正式进入电动机器人时代!昨天,液压Atlas刚刚「含泪」退出历史舞台,今天波士顿动力就宣布:电动Atlas上岗。看来,在商用人形机器人领域,波士顿动力是下定决心要和特斯拉硬刚一把了。新视频放出后,短短十几小时内,就已经有一百多万观看。旧人离去,新角色登场,这是历史的必然。毫无疑问,今年是人形机器人的爆发年。网友锐评:机器人的进步,让今年看起来像人类的开幕式动作、自由度远超人类,但这真不是恐怖片?视频一开始,Atlas平静地躺在地上,看起来应该是仰面朝天。接下来,让人惊掉下巴
 替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
本月初,来自MIT等机构的研究者提出了一种非常有潜力的MLP替代方法——KAN。KAN在准确性和可解释性方面表现优于MLP。而且它能以非常少的参数量胜过以更大参数量运行的MLP。比如,作者表示,他们用KAN以更小的网络和更高的自动化程度重现了DeepMind的结果。具体来说,DeepMind的MLP有大约300,000个参数,而KAN只有约200个参数。KAN与MLP一样具有强大的数学基础,MLP基于通用逼近定理,而KAN基于Kolmogorov-Arnold表示定理。如下图所示,KAN在边上具
 FisheyeDetNet:首个基于鱼眼相机的目标检测算法
Apr 26, 2024 am 11:37 AM
FisheyeDetNet:首个基于鱼眼相机的目标检测算法
Apr 26, 2024 am 11:37 AM
目标检测在自动驾驶系统当中是一个比较成熟的问题,其中行人检测是最早得以部署算法之一。在多数论文当中已经进行了非常全面的研究。然而,利用鱼眼相机进行环视的距离感知相对来说研究较少。由于径向畸变大,标准的边界框表示在鱼眼相机当中很难实施。为了缓解上述描述,我们探索了扩展边界框、椭圆、通用多边形设计为极坐标/角度表示,并定义一个实例分割mIOU度量来分析这些表示。所提出的具有多边形形状的模型fisheyeDetNet优于其他模型,并同时在用于自动驾驶的Valeo鱼眼相机数据集上实现了49.5%的mAP
 特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人Optimus最新视频出炉,已经可以在厂子里打工了。正常速度下,它分拣电池(特斯拉的4680电池)是这样的:官方还放出了20倍速下的样子——在小小的“工位”上,拣啊拣啊拣:这次放出的视频亮点之一在于Optimus在厂子里完成这项工作,是完全自主的,全程没有人为的干预。并且在Optimus的视角之下,它还可以把放歪了的电池重新捡起来放置,主打一个自动纠错:对于Optimus的手,英伟达科学家JimFan给出了高度的评价:Optimus的手是全球五指机器人里最灵巧的之一。它的手不仅有触觉
 牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
写在前面项目链接:https://nianticlabs.github.io/mickey/给定两张图片,可以通过建立图片之间的对应关系来估计它们之间的相机姿态。通常,这些对应关系是二维到二维的,而我们估计的姿态在尺度上是不确定的。一些应用,例如随时随地实现即时增强现实,需要尺度度量的姿态估计,因此它们依赖于外部的深度估计器来恢复尺度。本文提出了MicKey,这是一个关键点匹配流程,能够够预测三维相机空间中的度量对应关系。通过学习跨图像的三维坐标匹配,我们能够在没有深度测试的情况下推断出度量相对
