

一键控制10万多个AI模型,HuggingFace给类ChatGPT模型们做了个「APP Store」

从聊天到编程再到支持各种插件,强大的 ChatGPT 早就不是一个简单的对话助手,而是朝着 AI 界的「管理层」不断前进。
3 月 23 号,OpenAI 宣布 ChatGPT 开始支持各类第三方插件,比如著名的理工科神器 Wolfram Alpha。借助该神器,原本鸡兔同笼都算不准的 ChatGPT 一跃成为理工科尖子生。Twitter 上许多人评论说,ChatGPT 插件的推出看起来有点像 2008 年 iPhone App Store 的推出。这也意味着 AI 聊天机器人正在进入一个新的进化阶段 ——「meta app」阶段。
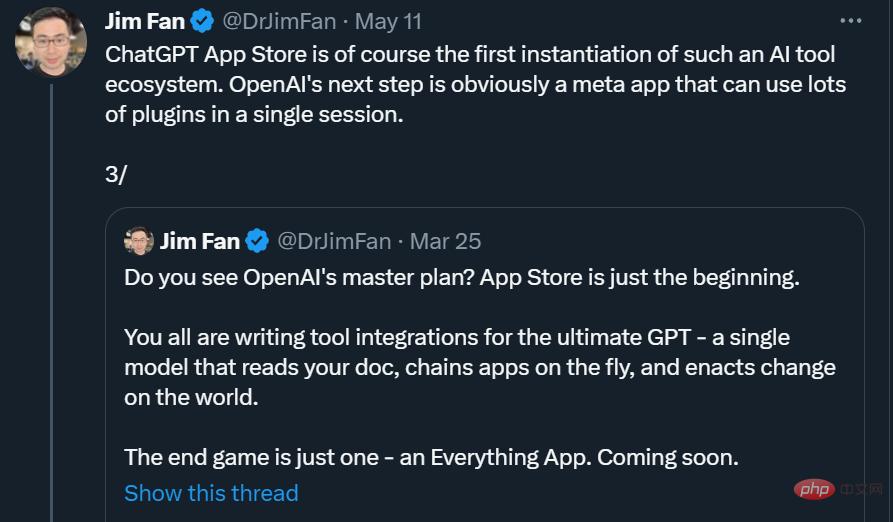
紧接着,4 月初,浙江大学和微软亚研的研究者提出了一种名为「HuggingGPT」的重要方法,可以看做是上述路线的一次大规模演示。HuggingGPT 让 ChatGPT 充当控制器(可以理解为管理层),由它来管理其他的大量 AI 模型,从而解决一些复杂的 AI 任务。具体来说,HuggingGPT 在收到用户请求时使用 ChatGPT 进行任务规划,根据 HuggingFace 中可用的功能描述选择模型,用选定的 AI 模型执行每个子任务,并根据执行结果汇总响应。
这种做法可以弥补当前大模型的很多不足,比如可处理的模态有限,在某些方面比不上专业模型等。
虽然调度的是 HuggingFace 的模型,但 HuggingGPT 毕竟不是 HuggingFace 官方出品。刚刚,HuggingFace 终于出手了。

和 HuggingGPT 理念类似,他们推出了一个新的 API——HuggingFace Transformers Agents。通过 Transformers Agents,你可以控制 10 万多个 Hugging Face 模型完成各种多模态任务。
比如在下面这个例子中,你想让 Transformers Agents 大声解释图片上描绘了什么内容。它会尝试理解你的指令(Read out loud thecontent of the image),然后将其转化为 prompt,并挑选合适的模型、工具来完成你指定的任务。
英伟达 AI 科学家 Jim Fan 评价说:这一天终于来了,这是迈向「Everything APP」(万事通 APP)的重要一步。

不过也有人说,这和 AutoGPT 的自动迭代还不一样,它更像是省掉了写 prompt 并手动指定工具这些步骤,距离万事通 APP 还为时过早。
Transformers Agents 地址:https://huggingface.co/docs/transformers/transformers_agents
Transformers Agents 怎么用?
在发布的同时,HuggingFace 就放出了 Colab 地址,任何人都可以上手一试:
https://huggingface.co/docs/transformers/en/transformers_agents
简而言之,它在 transformers 之上提供了一个自然语言 API:首先定义一套策划的工具,并设计了一个智能体来解释自然语言和使用这些工具。
而且,Transformers Agents 在设计上是可扩展的。
团队已经确定了一组可以授权给智能体的工具,以下是已集成的工具列表:
- 文档问答:给定一个图像格式的文档(例如 PDF),回答关于该文档的问题 (Donut)
- 文本问答:给定一段长文本和一个问题,回答文本中的问题(Flan-T5)
- 无条件的图像说明:为图像添加说明 (BLIP)
- 图片问答:给定一张图片,回答关于这张图片的问题(VILT)
- 图像分割:给定图像和 prompt,输出该 prompt 的分割掩码(CLIPSeg)
- 语音转文本:给定一个人说话的录音,将语音转录成文本 (Whisper)
- 文本到语音:将文本转换为语音(SpeechT5)
- 零样本文本分类:给定文本和标签列表,确定文本与哪个标签最对应 ( BART )
- 文本摘要:用一个或几个句子来概括一个长文本(BART)
- 翻译:将文本翻译成给定的语言(NLLB)
这些工具集成在 transformers 中,也可以手动使用:
<code>from transformers import load_tooltool = load_tool("text-to-speech")audio = tool("This is a text to speech tool")</code>用户还可以将工具的代码推送到 Hugging Face Space 或模型存储库,以便直接通过智能体来利用该工具,比如:
- 文本下载器:从 web URL 下载文本
- Text to image : 根据 prompt 生成图像,利用 Stable Diffusion
- 图像转换:在给定初始图像和 prompt 的情况下修改图像,利用 instruct pix2pix stable diffusion
- Text to video : 根据 prompt 生成小视频,利用 damo-vilab
具体玩法的话,我们先看几个 HuggingFace 的示例:
生成图像描述:
<code>agent.run("Caption the following image", image=image)</code>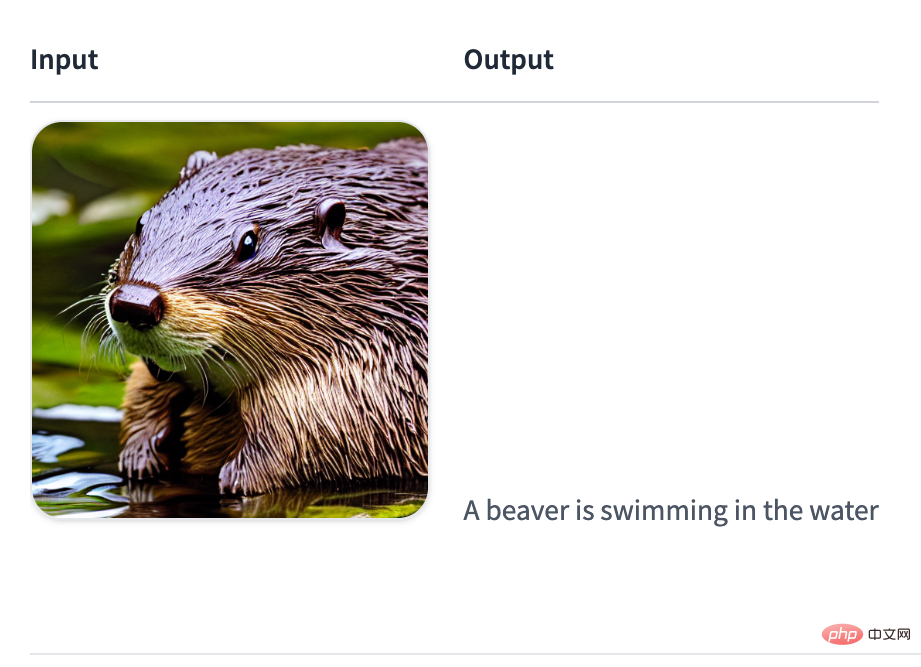
朗读文本:
<code>agent.run("Read the following text out loud", text=text)</code>输入:A beaver is swimming in the water
输出:
tts_example音频:00:0000:01
读取文件:

在运行 agent.run, 之前,需要先实例化一个大语言模型智能体。这里支持 OpenAI 的模型以及 BigCode、OpenAssistant 等开源模型。
首先,请安装 agents 附加组件以安装所有默认依赖项:
<code>pip install transformers[agents]</code>
要使用 openAI 模型,需要在安装依赖项后实例化一个「OpenAiAgent」 openai:
<code>pip install openaifrom transformers import OpenAiAgentagent = OpenAiAgent(model="text-davinci-003", api_key="<your_api_key>")</code>
要使用 BigCode 或 OpenAssistant,首先登录以访问推理 API:
<code>from huggingface_hub import loginlogin("<YOUR_TOKEN>")</code>然后,实例化智能体:
<code>from transformers import HfAgentStarcoderagent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")StarcoderBaseagent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoderbase")OpenAssistantagent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")</code>如果用户对此模型(或另一个模型)有自己的推理端点,可以将上面的 URL 替换为自己的 URL 端点。
接下来,我们了解一下 Transformers Agents 提供的两个 API:
单次执行
单次执行是在使用智能体的 run () 方法时:
<code>agent.run("Draw me a picture of rivers and lakes.")</code>它会自动选择适合要执行的任务的工具并适当地执行,可在同一指令中执行一项或多项任务(不过指令越复杂,智能体失败的可能性就越大)。
<code>agent.run("Draw me a picture of the sea then transform the picture to add an island")</code>每个 run () 操作都是独立的,因此可以针对不同的任务连续运行多次。如果想在执行过程中保持状态或将非文本对象传递给智能体,用户可以通过指定希望智能体使用的变量来实现。例如,用户可以生成第一张河流和湖泊图像,并通过执行以下操作要求模型更新该图片以添加一个岛屿:
<code>picture = agent.run("Generate a picture of rivers and lakes.")updated_picture = agent.run("Transform the image in picture to add an island to it.", picture=picture)</code>当模型无法理解用户的请求并混合使用工具时,这会很有帮助。一个例子是:
<code>agent.run("Draw me the picture of a capybara swimming in the sea")</code>在这里,模型可以用两种方式解释:
- 让 text-to-image 水豚在海里游泳
- 或者,生成 text-to-image 水豚,然后使用 image-transformation 工具让它在海里游泳
如果用户想强制执行第一种情况,可以通过将 prompt 作为参数传递给它来实现:
<code>agent.run("Draw me a picture of the prompt", prompt="a capybara swimming in the sea")</code>基于聊天的执行
智能体还有一种基于聊天的方法:
<code>agent.chat("Generate a picture of rivers and lakes")</code><code>agent.chat ("Transform the picture so that there is a rock in there")</code>这是一种可以跨指令保持状态时。它更适合实验,但在单个指令上表现更好,而 run () 方法更擅长处理复杂指令。如果用户想传递非文本类型或特定 prompt,该方法也可以接受参数。
以上是一键控制10万多个AI模型,HuggingFace给类ChatGPT模型们做了个「APP Store」的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何设置Vue Axios的超时时间
Apr 07, 2025 pm 10:03 PM
如何设置Vue Axios的超时时间
Apr 07, 2025 pm 10:03 PM
为了设置 Vue Axios 的超时时间,我们可以创建 Axios 实例并指定超时选项:在全局设置中:Vue.prototype.$axios = axios.create({ timeout: 5000 });在单个请求中:this.$axios.get('/api/users', { timeout: 10000 })。
 mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
文章介绍了MySQL数据库的上手操作。首先,需安装MySQL客户端,如MySQLWorkbench或命令行客户端。1.使用mysql-uroot-p命令连接服务器,并使用root账户密码登录;2.使用CREATEDATABASE创建数据库,USE选择数据库;3.使用CREATETABLE创建表,定义字段及数据类型;4.使用INSERTINTO插入数据,SELECT查询数据,UPDATE更新数据,DELETE删除数据。熟练掌握这些步骤,并学习处理常见问题和优化数据库性能,才能高效使用MySQL。
 Laravel的地理空间:互动图和大量数据的优化
Apr 08, 2025 pm 12:24 PM
Laravel的地理空间:互动图和大量数据的优化
Apr 08, 2025 pm 12:24 PM
利用地理空间技术高效处理700万条记录并创建交互式地图本文探讨如何使用Laravel和MySQL高效处理超过700万条记录,并将其转换为可交互的地图可视化。初始挑战项目需求:利用MySQL数据库中700万条记录,提取有价值的见解。许多人首先考虑编程语言,却忽略了数据库本身:它能否满足需求?是否需要数据迁移或结构调整?MySQL能否承受如此大的数据负载?初步分析:需要确定关键过滤器和属性。经过分析,发现仅少数属性与解决方案相关。我们验证了过滤器的可行性,并设置了一些限制来优化搜索。地图搜索基于城
 mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
MySQL启动失败的原因有多种,可以通过检查错误日志进行诊断。常见原因包括端口冲突(检查端口占用情况并修改配置)、权限问题(检查服务运行用户权限)、配置文件错误(检查参数设置)、数据目录损坏(恢复数据或重建表空间)、InnoDB表空间问题(检查ibdata1文件)、插件加载失败(检查错误日志)。解决问题时应根据错误日志进行分析,找到问题的根源,并养成定期备份数据的习惯,以预防和解决问题。
 偏远的高级后端工程师(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
偏远的高级后端工程师(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
远程高级后端工程师职位空缺公司:Circle地点:远程办公职位类型:全职薪资:$130,000-$140,000美元职位描述参与Circle移动应用和公共API相关功能的研究和开发,涵盖整个软件开发生命周期。主要职责独立完成基于RubyonRails的开发工作,并与React/Redux/Relay前端团队协作。为Web应用构建核心功能和改进,并在整个功能设计过程中与设计师和领导层紧密合作。推动积极的开发流程,并确定迭代速度的优先级。要求6年以上复杂Web应用后端
 mysql 能返回 json 吗
Apr 08, 2025 pm 03:09 PM
mysql 能返回 json 吗
Apr 08, 2025 pm 03:09 PM
MySQL 可返回 JSON 数据。JSON_EXTRACT 函数可提取字段值。对于复杂查询,可考虑使用 WHERE 子句过滤 JSON 数据,但需注意其性能影响。MySQL 对 JSON 的支持在不断增强,建议关注最新版本及功能。
 mysql安装后怎么优化数据库性能
Apr 08, 2025 am 11:36 AM
mysql安装后怎么优化数据库性能
Apr 08, 2025 am 11:36 AM
MySQL性能优化需从安装配置、索引及查询优化、监控与调优三个方面入手。1.安装后需根据服务器配置调整my.cnf文件,例如innodb_buffer_pool_size参数,并关闭query_cache_size;2.创建合适的索引,避免索引过多,并优化查询语句,例如使用EXPLAIN命令分析执行计划;3.利用MySQL自带监控工具(SHOWPROCESSLIST,SHOWSTATUS)监控数据库运行状况,定期备份和整理数据库。通过这些步骤,持续优化,才能提升MySQL数据库性能。
 如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
如何针对高负载应用程序优化 MySQL 性能?
Apr 08, 2025 pm 06:03 PM
MySQL数据库性能优化指南在资源密集型应用中,MySQL数据库扮演着至关重要的角色,负责管理海量事务。然而,随着应用规模的扩大,数据库性能瓶颈往往成为制约因素。本文将探讨一系列行之有效的MySQL性能优化策略,确保您的应用在高负载下依然保持高效响应。我们将结合实际案例,深入讲解索引、查询优化、数据库设计以及缓存等关键技术。1.数据库架构设计优化合理的数据库架构是MySQL性能优化的基石。以下是一些核心原则:选择合适的数据类型选择最小的、符合需求的数据类型,既能节省存储空间,又能提升数据处理速度
