

AI考公考编指日可待!微软华人团队发布全新基准AGIEval,专为人类考试而生

随着语言模型的能力越来越强,现有的这些评估基准实在有点小儿科了,有些任务的性能都甩了人类一截。
通用人工智能(AGI)的一个重要特点是模型具有处理人类水平任务的泛化能力,而依赖于人工数据集的传统基准测试并不能准确表示人类的能力。
最近,微软的研究人员发布了一个全新基准AGIEval,专门用于评估基础模型在「以人为本」(human-centric)的标准化考试中,如高考、公务员考试、法学院入学考试、数学竞赛和律师资格考试中的表现。

论文链接:https://arxiv.org/pdf/2304.06364.pdf
数据链接:https://github.com/microsoft/AGIEval
研究人员使用AGIEval基准评估了三个最先进的基础模型,包括GPT-4、 ChatGPT和Text-Davinci-003,实验结果发现GPT-4在SAT、 LSAT和数学竞赛中的成绩超过了人类平均水平,SAT数学考试的准确率达到了95% ,中国高考英语考试的准确率达到了92.5% ,表明了目前基础模型的非凡表现。
但GPT-4在需要复杂推理或特定领域知识的任务中不太熟练,文中对模型能力(理解、知识、推理和计算)的全面分析揭示了这些模型的优势和局限性。
AGIEval数据集
近年来,大型基础模型如GPT-4在各个领域已经表现出非常强大的能力,可以辅助人类处理日常事件,甚至还能在法律、医学和金融等专业领域提供决策建议。
也就是说,人工智能系统正逐步接近并实现通用人工智能(AGI)。
但随着AI逐步融入日常生活,如何评估模型以人为本的泛化能力,识别潜在的缺陷,并确保它们能够有效地处理复杂的、以人为本的任务,以及评估推理能力确保在不同环境下的可靠性和可信度是至关重要的。
研究人员构造AGIEval数据集主要遵循两个设计原则:
1. 强调人脑级别的认知任务
设计「以人为本」的主要目标是以与人类认知和解决问题密切相关的任务为中心,并以一种更有意义和全面的方式评估基础模型的泛化能力。
为了实现这一目标,研究人员选择了各种官方的、公开的、高标准的招生和资格考试,以满足一般人类应试者的需要,包括大学入学考试、法学院入学考试、数学考试、律师资格考试和国家公务员考试,每年都有数百万寻求进入高等教育或新职业道路的人参加这些考试。
通过遵守这些官方认可的评估人类水平能力的标准,AGIEval可以确保对模型性能的评估与人类决策和认知能力直接相关。
2. 与现实世界场景的相关性
通过选择来自高标准的入学考试和资格考试的任务,可以确保评估结果能够反映个人在不同领域和背景下经常遇到的挑战的复杂性和实用性。
这种方法不仅可以衡量模型在人类认知能力方面的表现,而且可以更好地了解在现实生活中的适用性和有效性,即有助于开发出更可靠、更实用、更适合于解决广泛的现实世界问题的人工智能系统。
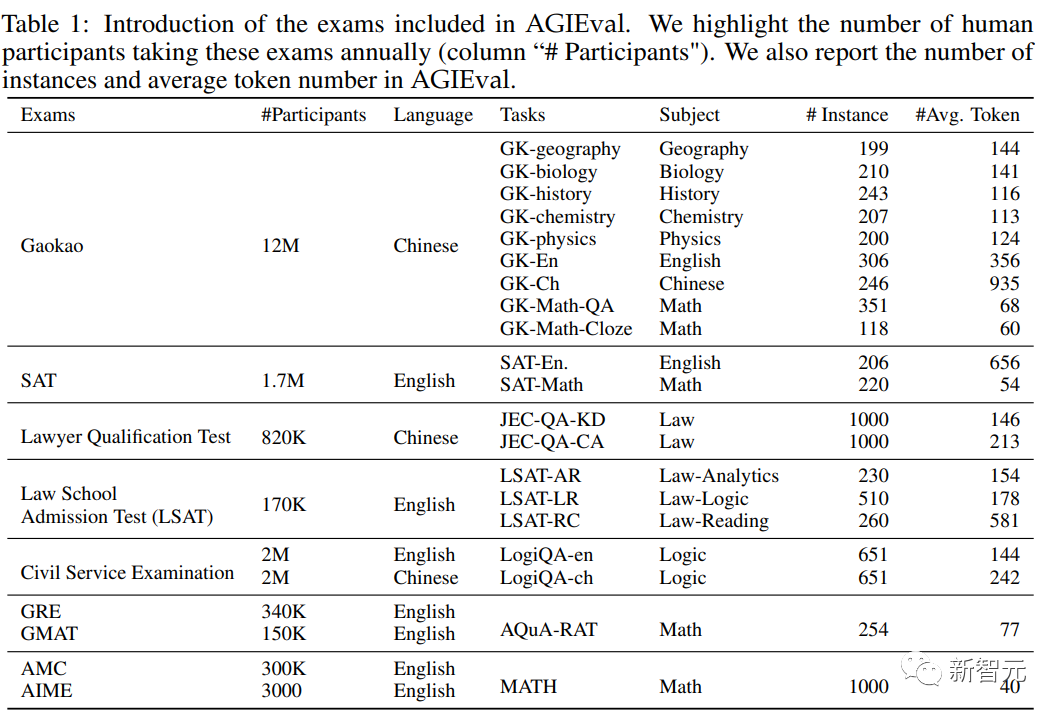
根据上述设计原则,研究人员选择了多种标准化的高质量考试,强调人类水平的推理和现实世界的相关性,具体包括:
1. 普通高校入学考试
大学入学考试包含各种科目,需要批判性思维、解决问题和分析能力,是评估大型语言模型与人类认知相关性能的理想选择。
具体包括研究生入学考试(GRE),学术评估考试(SAT)和中国高考(Gaokao),可以评估寻求进入高等教育机构的学生的一般能力和特定学科知识。
数据集中收集了与中国高考8个科目对应的考试:历史、数学、英语、中文、地理、生物、化学和物理;从GRE中选择数学题;从SAT中选择英语和数学科目来构建基准数据集。
2. 法学院入学考试
法学院入学考试,如LSAT,旨在衡量未来的法律学生的推理和分析能力,考试内容包括逻辑推理、阅读理解和分析推理等部分,需要应试者分析复杂信息和得出准确结论的能力,这些任务可以评估语言模型在法律推理和分析方面的能力。
3. 律师资格考试
可以评估追求法律职业的个人的法律知识、分析能力和道德理解,考试内容涵盖了广泛的法律主题,包括宪法、合同法、刑法和财产法,并要求考生展示他们有效应用法律原则和推理的能力,可以在专业法律知识和道德判断的背景下评估语言模型的表现。
4. 研究生管理入学考试(GMAT)
GMAT是一个标准化的考试,可以评估未来商学院研究生的分析、定量、言语和综合推理能力,由分析性写作评估、综合推理、定量推理和言语推理等部分组成,评估应试者的批判性思考、分析数据和有效沟通的能力。
5. 高中数学竞赛
这些比赛涵盖了广泛的数学主题,包括数论、代数、几何和组合学,并且经常出现一些非常规的问题,需要用创造性的方法来解决。
具体包括美国数学竞赛(AMC)和美国数学邀请考试(AIME),可以测试学生的数学能力、创造力和解决问题的能力,能够进一步评估语言模型处理复杂和创造性数学问题的能力,以及模型生成新颖解决方案的能力。
6. 国内公务员考试
可以评估寻求进入公务员队伍的个人的能力和技能,考试内容包括评估一般知识、推理能力、语言技能,以及与中国各种公务员职位的角色和职责有关的特定科目的专业知识,可以衡量语言模型在公共管理背景下的表现,以及他们对政策制定、决策和公共服务提供过程的潜力。
评估结果
选择的模型包括:
ChatGPT,由OpenAI开发的对话式人工智能模型,可以参与用户互动和动态对话,使用庞大的指令数据集进行训练,并通过强化学习与人类反馈(RLHF)进一步调整,使其能够提供与人类期望相一致的上下文相关和连贯的回复。
GPT-4,作为第四代GPT模型,包含范围更广的知识库,在许多应用场景中都表现出人类水平的性能。GPT-4利用对抗性测试和ChatGPT进行了反复调整,从而在事实性、可引导性和对规则的遵守方面有了明显的改进。
Text-Davinci-003是GPT-3和GPT-4之间的一个中间版本,通过指令微调后比GPT-3的性能更好。
除此之外,实验中还报告了人类应试者的平均成绩和最高成绩,作为每个任务的人类水平界限,但并不能完全代表人类可能拥有的技能和知识范围。
Zero-shot/Few-shot评估
在零样本的设置下,模型直接对问题进行评估;在少样本任务中,在对测试样本进行评估之前,先输入同一任务中的少量例子(如5个)。
为了进一步测试模型的推理能力,实验中还引入思维链(CoT)提示,即先输入提示「Let’s think step by step」为给定的问题生成解释,然后输入提示「Explanation is」根据解释生成最终的答案。
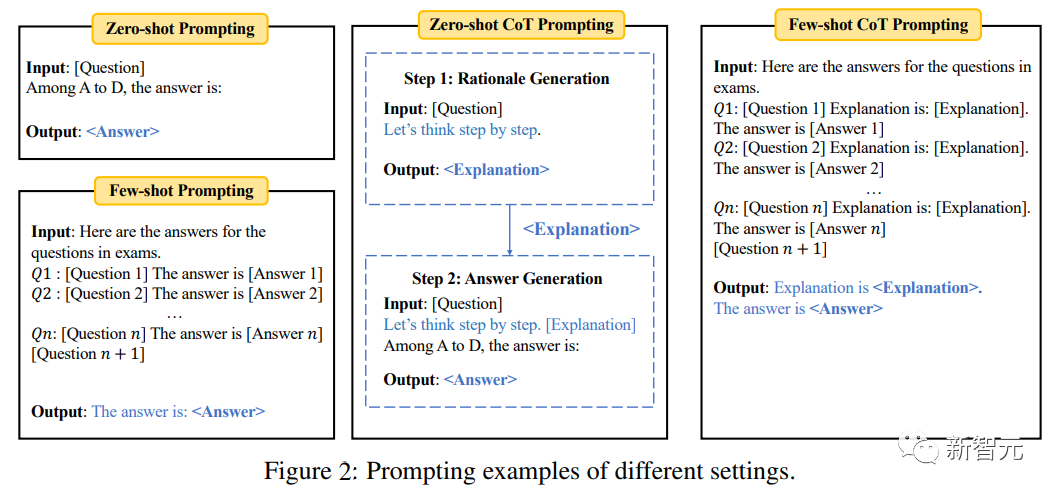
基准中的「多选题」使用标准分类准确率;「填空题」使用精确匹配(EM)和F1指标。
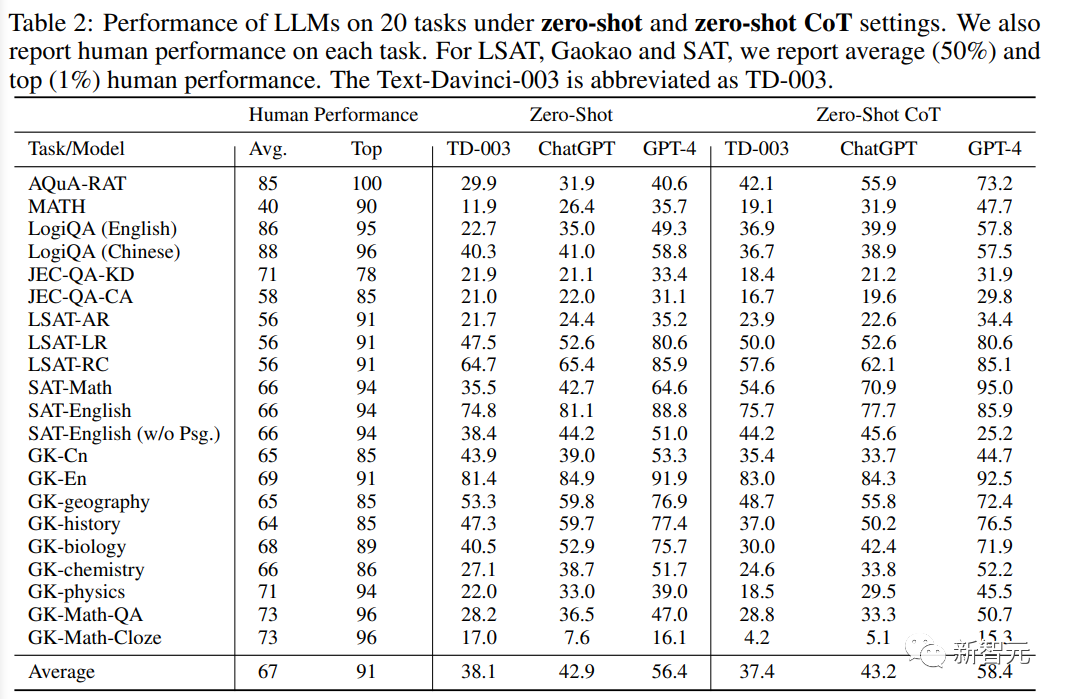
从实验结果中可以发现:
1. GPT-4在所有任务设置下都明显优于其同类产品,其中在Gaokao-English上更是取得了93.8%的准确率,在SAT-MATH上取得了95%的准确率,表明GPT-4在处理以人为本的任务方面具有卓越的通用能力。
2. ChatGPT在需要外部知识的任务中明显优于Text-Davinci-003,例如涉及地理、生物、化学、物理和数学的任务,表明ChatGPT拥有更强大的知识基础,能够更好地处理那些需要对特定领域有深刻理解的任务。
另一方面,ChatGPT在所有评估设置中,在需要纯粹理解和不严重依赖外部知识的任务中,如英语和LSAT任务,略微优于Text-Davinci-003,或取得相当的结果。这一观察结果意味着,这两个模型都能够处理以语言理解和逻辑推理为中心的任务,而不需要专门的领域知识。
3. 尽管这些模型的总体表现不错,但所有的语言模型都在复杂的推理任务中表现不佳,比如MATH、LSAT-AR、GK-physics和GK-Math,突出了这些模型在处理需要高级推理和解决问题技能的任务方面的局限性。
观察到的处理复杂推理问题的困难为未来的研究和开发提供了机会,目的是提高模型的一般推理能力。
4. 与zero-shot学习相比,few-shot学习通常只能带来有限的性能改善,表明目前大型语言模型的zero-shot学习能力正在接近few-shot学习能力,也标志着与最初的GPT-3模型相比有了很大的进步,当时few-shot性能要比zero-shot好得多。
对这一发展的一个合理解释是,在目前的语言模型中加强了人类的调整和指令的调整,这些改进使模型能够提前更好地理解任务的含义和背景,从而使它们即使在zero-shot的情况下也能有良好的表现,证明了指令的有效性。
以上是AI考公考编指日可待!微软华人团队发布全新基准AGIEval,专为人类考试而生的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 centos关机命令行
Apr 14, 2025 pm 09:12 PM
centos关机命令行
Apr 14, 2025 pm 09:12 PM
CentOS 关机命令为 shutdown,语法为 shutdown [选项] 时间 [信息]。选项包括:-h 立即停止系统;-P 关机后关电源;-r 重新启动;-t 等待时间。时间可指定为立即 (now)、分钟数 ( minutes) 或特定时间 (hh:mm)。可添加信息在系统消息中显示。
 CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系统下GitLab的备份与恢复策略为了保障数据安全和可恢复性,CentOS上的GitLab提供了多种备份方法。本文将详细介绍几种常见的备份方法、配置参数以及恢复流程,帮助您建立完善的GitLab备份与恢复策略。一、手动备份利用gitlab-rakegitlab:backup:create命令即可执行手动备份。此命令会备份GitLab仓库、数据库、用户、用户组、密钥和权限等关键信息。默认备份文件存储于/var/opt/gitlab/backups目录,您可通过修改/etc/gitlab
 如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
检查CentOS系统中HDFS配置的完整指南本文将指导您如何有效地检查CentOS系统上HDFS的配置和运行状态。以下步骤将帮助您全面了解HDFS的设置和运行情况。验证Hadoop环境变量:首先,确认Hadoop环境变量已正确设置。在终端执行以下命令,验证Hadoop是否已正确安装并配置:hadoopversion检查HDFS配置文件:HDFS的核心配置文件位于/etc/hadoop/conf/目录下,其中core-site.xml和hdfs-site.xml至关重要。使用
 CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
在CentOS系统上启用PyTorchGPU加速,需要安装CUDA、cuDNN以及PyTorch的GPU版本。以下步骤将引导您完成这一过程:CUDA和cuDNN安装确定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA显卡支持的CUDA版本。例如,您的MX450显卡可能支持CUDA11.1或更高版本。下载并安装CUDAToolkit:访问NVIDIACUDAToolkit官网,根据您显卡支持的最高CUDA版本下载并安装相应的版本。安装cuDNN库:前
 centos安装mysql
Apr 14, 2025 pm 08:09 PM
centos安装mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安装 MySQL 涉及以下步骤:添加合适的 MySQL yum 源。执行 yum install mysql-server 命令以安装 MySQL 服务器。使用 mysql_secure_installation 命令进行安全设置,例如设置 root 用户密码。根据需要自定义 MySQL 配置文件。调整 MySQL 参数和优化数据库以提升性能。
 docker原理详解
Apr 14, 2025 pm 11:57 PM
docker原理详解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux内核特性,提供高效、隔离的应用运行环境。其工作原理如下:1. 镜像作为只读模板,包含运行应用所需的一切;2. 联合文件系统(UnionFS)层叠多个文件系统,只存储差异部分,节省空间并加快速度;3. 守护进程管理镜像和容器,客户端用于交互;4. Namespaces和cgroups实现容器隔离和资源限制;5. 多种网络模式支持容器互联。理解这些核心概念,才能更好地利用Docker。
 centos8重启ssh
Apr 14, 2025 pm 09:00 PM
centos8重启ssh
Apr 14, 2025 pm 09:00 PM
重启 SSH 服务的命令为:systemctl restart sshd。步骤详解:1. 访问终端并连接到服务器;2. 输入命令:systemctl restart sshd;3. 验证服务状态:systemctl status sshd。
 CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系统上进行PyTorch分布式训练,需要按照以下步骤操作:PyTorch安装:前提是CentOS系统已安装Python和pip。根据您的CUDA版本,从PyTorch官网获取合适的安装命令。对于仅需CPU的训练,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,请确保已安装对应版本的CUDA和cuDNN,并使用相应的PyTorch版本进行安装。分布式环境配置:分布式训练通常需要多台机器或单机多GPU。所
