

上科大等发布DreamFace:只需文本即可生成「超写实3D数字人」

随着大型语言模型(LLM)、扩散(Diffusion)等技术的发展,ChatGPT、Midjourney等产品的诞生掀起了新一波的AI热潮,生成式AI也成为备受关注的话题。
与文本和图像不同,3D生成仍处于技术探索阶段。
2022年年底,Google、NVIDIA和微软相继推出了自己的3D生成工作,但大多基于先进的神经辐射场(NeRF)隐式表达,与工业界3D软件如Unity、Unreal Engine和Maya等的渲染管线不兼容。
即使通过传统方案将其转换为Mesh表达的几何和颜色贴图,也会造成精度不足和视觉质量下降,不能直接应用于影视制作和游戏生产。

项目网站:https://sites.google.com/view/dreamface
论文地址:https://arxiv.org/abs/2304.03117
Web Demo:https://hyperhuman.top
HuggingFace Space:https://huggingface.co/spaces/DEEMOSTECH/ChatAvatar
为了解决这些问题,来自影眸科技与上海科技大学的研发团队提出了一种文本指导的渐进式3D生成框架。
该框架引入符合CG制作标准的外部数据集(包含几何和PBR材质),可以根据文本直接生成符合该标准的3D资产,是首个支持Production-Ready 3D资产生成的框架。
为了实现文本生成可驱动的3D超写实数字人,该团队将这个框架与产品级3D数字人数据集相结合。这项工作已经被计算机图形领域国际顶级期刊Transactions on Graphics接收,并将在国际计算机图形顶级会议SIGGRAPH 2023上展示。
DreamFace主要包括三个模块,几何体生成,基于物理的材质扩散和动画能力生成。
相比先前的3D生成工作,这项工作的主要贡献包括:
· 提出了DreamFace这一新颖的生成方案,将最近的视觉-语言模型与可动画和物理材质的面部资产相结合,通过渐进式学习来分离几何、外观和动画能力。
· 引入了双通道外观生成的设计,将一种新颖的材质扩散模型与预训练模型相结合,同时在潜在空间和图像空间进行两阶段优化。
· 使用BlendShapes或生成的Personalized BlendShapes的面部资产具备动画能力,并进一步展示了DreamFace在自然人物设计方面的应用。
几何生成
几何体生成模块可以根据文本提示生成与之一致的几何模型。然而,在人脸生成方面,这可能难以监督和收敛。
因此,DreamFace提出了一个基于CLIP(Contrastive Language-Image Pre-Training)的选择框架,首先从对人脸几何参数空间内随机采样的候选项中选择最佳的粗略几何模型,然后雕刻几何细节,使头部模型更符合文本提示。
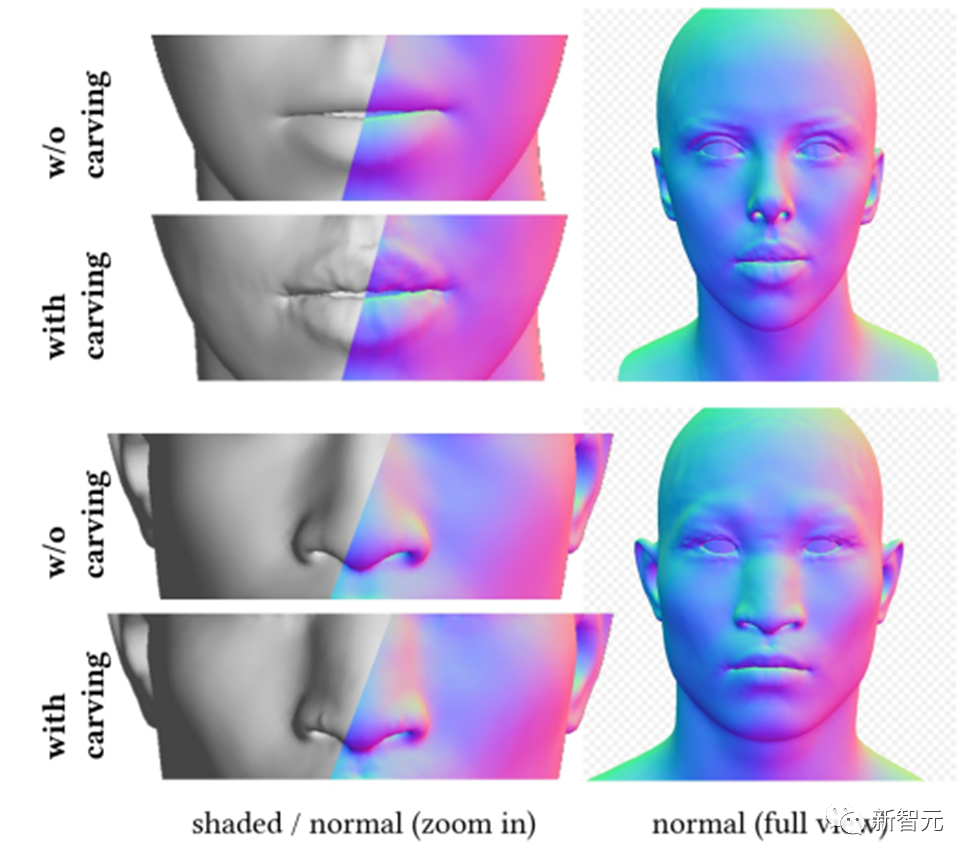
根据输入提示,DreamFace利用CLIP模型选择匹配得分最高的粗略几何候选项。接下来,DreamFace使用隐式扩散模型(LDM)在随机视角和光照条件下对渲染图像进行得分蒸馏采样(SDS)处理。
这使得DreamFace可以通过顶点位移和详细的法线贴图向粗略几何模型添加面部细节,从而得到高度精细的几何体。
与头部模型类似,DreamFace还基于该框架进行发型和颜色的选择。
基于物理的材质扩散生成
基于物理的材质扩散模块旨在预测与预测几何体和文本提示一致的面部纹理。
首先,DreamFace将预先训练的LDM在收集的大规模UV材质数据集上微调,得到两个LDM扩散模型。

DreamFace采用了一种联合训练方案,协调两个扩散过程,一个用于直接去噪UV纹理贴图,另一个用于监督渲染图像,以确保面部UV贴图和渲染图像的正确形成与文本提示一致。
为了减少生成时间,DreamFace采用了一个粗糙纹理潜在扩散阶段,为细节纹理生成提供先验潜在。
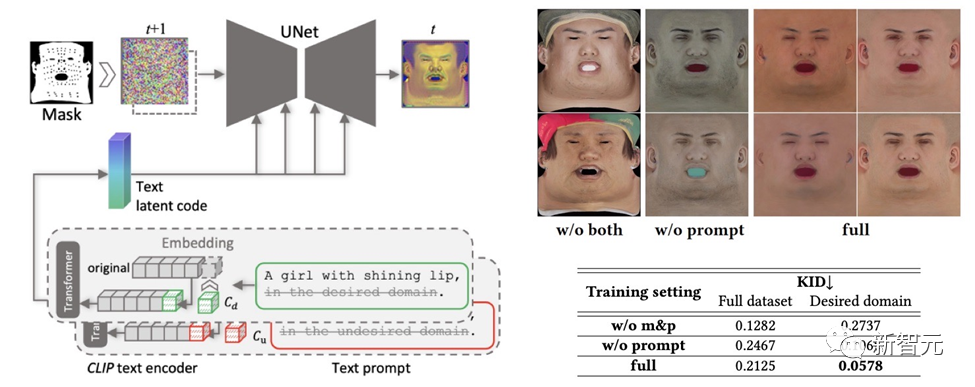
为了确保所创建的纹理地图不含有不良特征或照明情况,同时仍保持多样性,设计了一种提示学习策略。
团队利用两种方法生成高质量的漫反射贴图:
(1)Prompt Tuning。与手工制作的特定领域文本提示不同,DreamFace将两个特定领域的连续文本提示 Cd 和 Cu 与相应的文本提示结合起来,这将在U-Net去噪器训练期间进行优化,以避免不稳定和耗时的手工撰写提示。
(2)非面部区域遮罩。LDM去噪过程将额外地受到非面部区域遮罩的限制,以确保生成的漫反射贴图不含有任何不需要的元素。
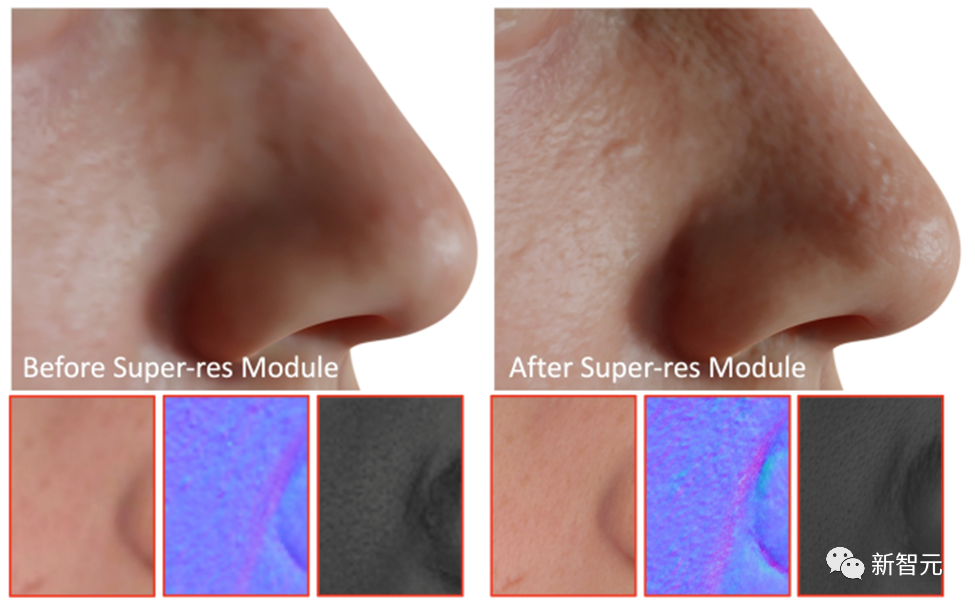
作为最后一步,DreamFace应用超分辨率模块生成4K基于物理的纹理,以进行高质量渲染。

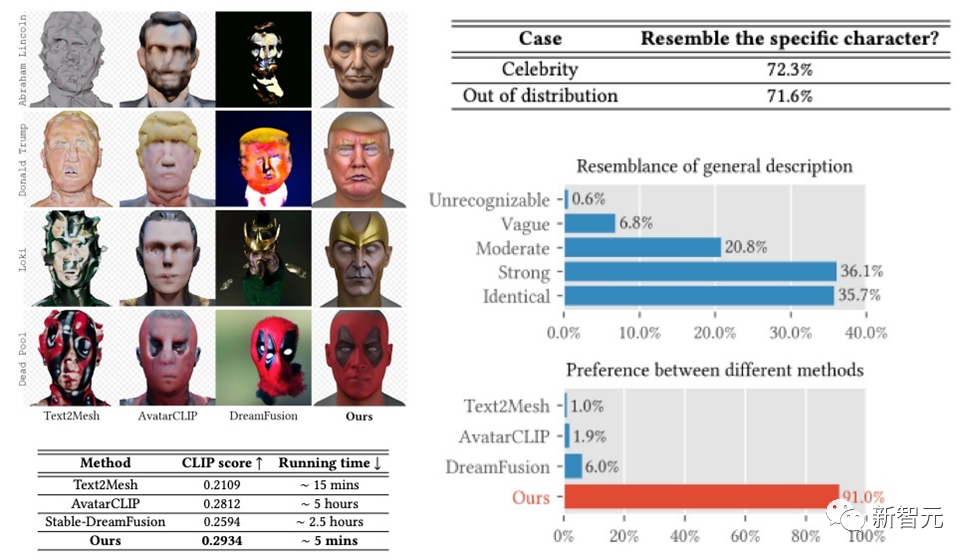
DreamFace框架在名人生成,根据描述生成角色上都取得了相当不错的效果,在User Study中获得了远超先前工作的成绩。相比先前的工作,在运行时间上也具备明显的优势。
除此之外,DreamFace还支持使用提示和草图进行纹理编辑。通过直接使用微调的纹理LDM和提示,可以实现全局的编辑效果,如老化和化妆。通过进一步结合掩模或草图,可以创建各种效果,如纹身、胡须和胎记。

动画能力生成
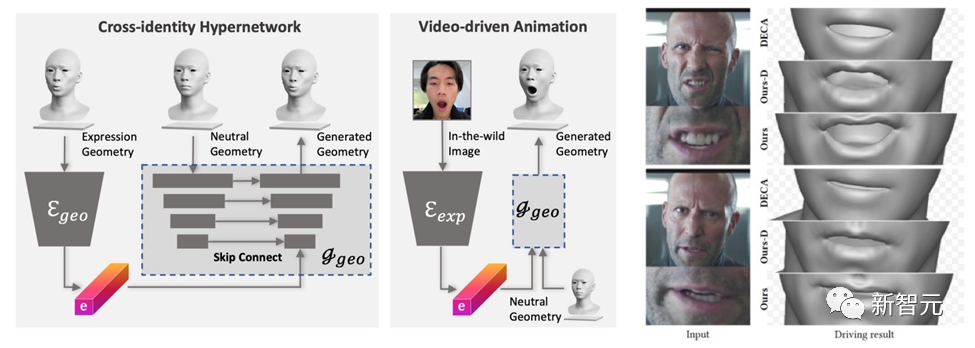
DreamFace生成的模型具备动画能力。与基于BlendShapes的方法不同,DreamFace的神经面部动画方法通过预测独特的变形来为生成的静息(Neutral)模型赋予动画效果,从而产生个性化的动画。
首先,训练一个几何生成器,学习表情的潜在空间,其中解码器被扩展为以中性几何形状为条件。接着,进一步训练表情编码器,从RGB图像中提取表情特征。因此,DreamFace能够通过使用单目RGB图像以中性几何形状为条件来生成个性化的动画。
与使用通用BlendShapes进行表情控制的DECA相比,DreamFace的框架提供了细致的表情细节,并且能够精细地捕捉表演。
结论
本文介绍了DreamFace,一种文本指导的渐进式3D生成框架,它结合了最新的视觉-语言模型、隐式扩散模型,以及基于物理的材质扩散技术。
DreamFace的主要创新包括几何体生成、基于物理的材质扩散生成和动画能力生成。与传统的3D生成方法相比,DreamFace具有更高的准确性、更快的运行速度和较好的CG管线兼容性。
DreamFace的渐进式生成框架为解决复杂的3D生成任务提供了一种有效的解决方案,有望推动更多类似的研究和技术发展。
此外,基于物理的材质扩散生成和动画能力生成将推动3D生成技术在影视制作、游戏开发和其他相关行业的应用。
以上是上科大等发布DreamFace:只需文本即可生成「超写实3D数字人」的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 上科大等发布DreamFace:只需文本即可生成「超写实3D数字人」
May 17, 2023 am 08:02 AM
上科大等发布DreamFace:只需文本即可生成「超写实3D数字人」
May 17, 2023 am 08:02 AM
随着大型语言模型(LLM)、扩散(Diffusion)等技术的发展,ChatGPT、Midjourney等产品的诞生掀起了新一波的AI热潮,生成式AI也成为备受关注的话题。与文本和图像不同,3D生成仍处于技术探索阶段。2022年年底,Google、NVIDIA和微软相继推出了自己的3D生成工作,但大多基于先进的神经辐射场(NeRF)隐式表达,与工业界3D软件如Unity、UnrealEngine和Maya等的渲染管线不兼容。即使通过传统方案将其转换为Mesh表达的几何和颜色贴图,也会造成精度不足
 大模型卷爆数字人:一句话5分钟实现定制,跳舞主持带货都能hold住
May 08, 2024 pm 08:10 PM
大模型卷爆数字人:一句话5分钟实现定制,跳舞主持带货都能hold住
May 08, 2024 pm 08:10 PM
最快5分钟,打造一个直接上岗工作的3D数字人。这是大模型给数字人领域带来的最新震撼。就像这样,一句话描述需求:生成的数字人直接就能进驻直播间当主播。跳起女团舞也不在话下。整个制作过程中,想到什么说什么就行,大模型都能自动拆解需求,瞬间get设计、修改思路。△2倍速再也不怕老板/甲方的想法太新奇。这样的文生数字人技术,来自百度智能云最新发布。该说不说,是要把数字人的使用门槛一口气砍没的节奏了。听闻如此神器,我们照例第一时间争取到了内测资格,更多细节,一起先睹为快~一句话5分钟,3D数字人直接上岗从
 完蛋,我被数字同事包围了!小冰AI数字员工再升级,零样本定制,即时上岗
Jul 19, 2024 pm 05:52 PM
完蛋,我被数字同事包围了!小冰AI数字员工再升级,零样本定制,即时上岗
Jul 19, 2024 pm 05:52 PM
「你好,我在咱们公司刚入职。业务上有什么事儿,就请您多多指教啦!」什么,这些同事竟然都是大模型驱动的“数字人”?只需30秒画面,10秒音频,10分钟就能极速定制一个这样和真人无异的“数字同事”。它可以直接和你实时交互,并且有着通信运营商级别的高质量低延迟的音画传输。就像这样:像这样:这是小冰公司最新上线的“零样本”数字人(Zero-shotXiaoiceNeuralRendering,Zero-XNR)技术,依托超千亿大模型基座,新技
 数字人点燃亚运主火炬,从这篇ICCV论文透视蚂蚁的生成式AI黑科技
Sep 29, 2023 pm 11:57 PM
数字人点燃亚运主火炬,从这篇ICCV论文透视蚂蚁的生成式AI黑科技
Sep 29, 2023 pm 11:57 PM
打开一个数字人,里面全是生成式AI。9月23日晚上,杭州亚运会的开幕式上,点燃主火炬的环节展现了上亿线上数字火炬手的「小火苗」聚集在钱塘江上,形成了一个数字人形象。接着,数字人火炬手和现场的第六棒火炬手一同走到火炬台前,共同点燃了主火炬作为开幕式的核心创意,数实互联的火炬点燃形式冲上了热搜,引发了人们的重点关注。重写后的内容:作为开幕式的核心创意,数实互联的火炬点燃方式引起了热议,吸引了人们的关注数字人点火是一个前所未有的创举,上亿人参与其中,涉及了大量先进且复杂的技术。其中最重要的问题之一是如
 Unity大中华区平台技术总监杨栋:开启元宇宙的数字人之旅
Apr 08, 2023 pm 06:11 PM
Unity大中华区平台技术总监杨栋:开启元宇宙的数字人之旅
Apr 08, 2023 pm 06:11 PM
作为构建元宇宙内容的基石,数字人是最早可落地且可持续发展的元宇宙细分成熟场景,目前,虚拟偶像、电商带货、电视主持、虚拟主播等商业应用已被大众认可。在元宇宙世界中,最核心的内容之一非数字人莫属,因为数字人不光是真实世界人类在元宇宙中的“化身”,也是我们在元宇宙中进行各种交互的重要载具之一。众所周知,创建和渲染逼真的数字人类角色是计算机图形学中最困难的问题之一。近日,在由51CTO主办的MetaCon元宇宙技术大会《游戏与AI交互》分会场中,Unity大中华区平台技术总监杨栋通过一系列的Demo演示
 什么是数字人,未来前景如何?
Oct 16, 2023 pm 02:25 PM
什么是数字人,未来前景如何?
Oct 16, 2023 pm 02:25 PM
在当今技术先进的世界中,栩栩如生的数字人已经成为了一个备受关注的新兴领域。作为一种基于计算机图形(CG)技术与人工智能技术创造出的与人类形象接近的数字化虚拟形象,数字人能够为人们提供更加便捷、高效、个性化的服务。与此同时,数字人的出现也可以促进虚拟经济的发展,为数字内容创新和数字消费提供更多机会。根据国际数据公司(IDC)发布的报告预测,全球虚拟数字人市场规模预计在2025年将达到270亿美元,年复合增长率高达22.5%。由此可见,数字人具有非常广阔的应用前景和市场潜力。什么是数字人?数字人是运
 DreamFace:一句话生成 3D 数字人?
May 16, 2023 pm 09:46 PM
DreamFace:一句话生成 3D 数字人?
May 16, 2023 pm 09:46 PM
在科技迅速发展的今天,生成式人工智能和计算机图形学领域的研究日益引人注目,影视制作、游戏开发等行业正面临着巨大的挑战和机遇。本文将为您介绍一项3D生成领域的研究——DreamFace,它是首个支持Production-Ready3D资产生成的文本指导渐进式3D生成框架,能够实现文本生成可驱动的3D超写实数字人。这项工作已经被计算机图形领域国际顶级期刊TransactionsonGraphics接收,并将在国际计算机图形顶级会议SIGGRAPH2023上展示。项目网站:https://sites.
 AI+数字人实现全新互动 中国电信携AI带来智能生活
May 27, 2023 pm 12:34 PM
AI+数字人实现全新互动 中国电信携AI带来智能生活
May 27, 2023 pm 12:34 PM
(图片来源:摄图网)(记者陈锦锋)近日,2023上海信息消费节拉开帷幕,“数字人”成为当仁不让的主角。业内人士认为,AI技术应用将加快优质内容开发,虚拟数字人或成为新的流量入口。AI数字人走进日常生活随着人工智能、虚拟现实等技术的发展,虚拟数字人走进人们日常生活,在很多领域发挥着独特作用。虚拟美妆达人柳夜熙,抖音出道三天点赞即超百万,一夜之间成为国内虚拟偶像界的顶流;在江苏卫视跨年演唱会上,昔日歌后邓丽君重返舞台,与歌手周深同台对唱,交织几代人的青春记忆;20多位数字人同台亮相冬奥会,担当手语主
