

经过前面两节内容的铺垫,我们可以开始讲一讲机器学习的动力之源:梯度下降。
梯度下降并不是一个很复杂的数学工具,其历史已经有200多年了,但是人们可能不曾料到,这样一个相对简单的数学工具会成为诸多机器学习算法的基础,而且还配合着神经网络点燃了深度学习革命。
对多元函数的各参数求偏导数,然后把所求得的各个参数的偏导数以向量的形式写出来,就是梯度。
具体来说,两个自变量的函数f(x1,x2),对应着机器学习数据集中的两个特征,如果分别对x1,x2求偏导数,那么求得的梯度向量就是(∂f/∂x1,∂f/∂x2)T,在数学上可以表示成Δf(x1,x2)。那么计算梯度向量的意义何在呢?其几何意义,就是函数变化的方向,而且是变化最快的方向。对于函数f(x),在点(x0,y0),梯度向量的方向也就是y值增加最快的方向。也就是说,沿着梯度向量的方向Δf(x0),能找到函数的最大值。反过来说,沿着梯度向量相反的方向,也就是 -Δf(x0)的方向,梯度减少最快,能找到函数的最小值。如果某一个点的梯度向量的值为0,那么也就是来到了导数为0的函数最低点(或局部最低点)了。
在机器学习中用下山来比喻梯度下降是很常见的。想象你们站在一座大山上某个地方,看着远处的地形,一望无际,只知道远处的位置比此处低很多。你们想知道如何下山,但是只能一步一步往下走,那也就是在每走到一个位置的时候,求解当前位置的梯度。然后,沿着梯度的负方向,也就是往最陡峭的地方向下走一步,继续求解新位置的梯度,并在新位置继续沿着最陡峭的地方向下走一步。就这样一步步地走,直到山脚,如下图所示。
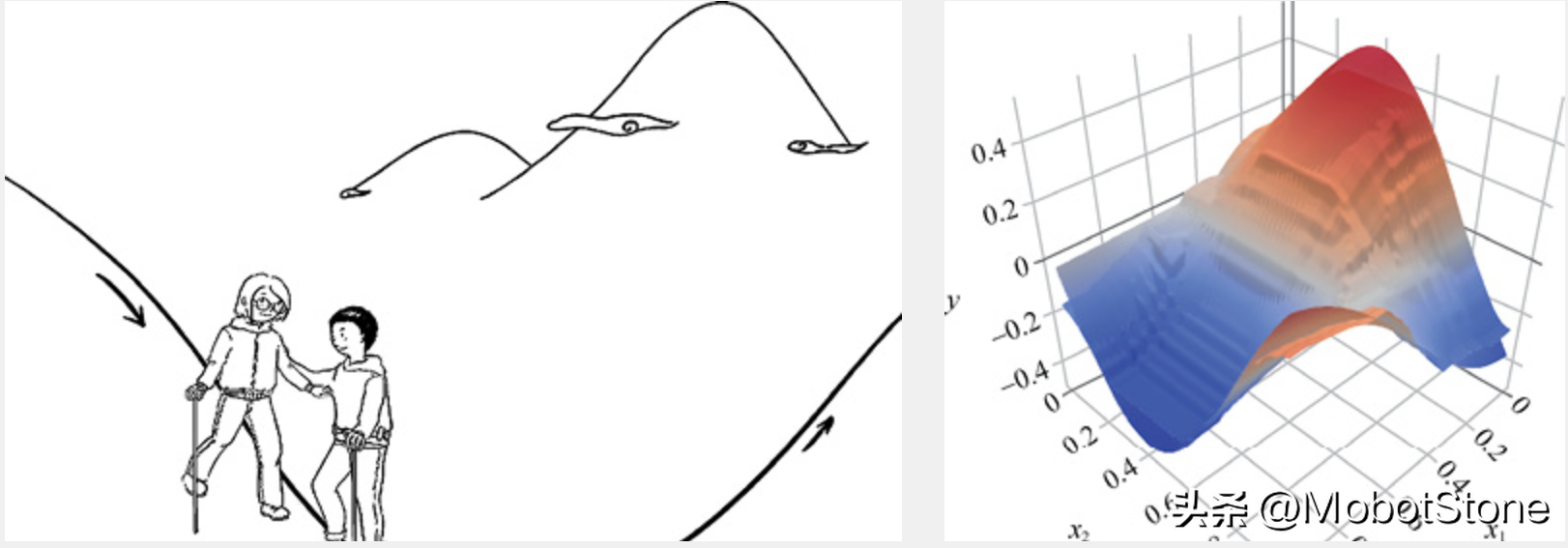
从上面的解释中,就不难理解为何刚才我们要提到函数的凹凸性了。因为,在非凸函数中,有可能还没走到山脚,而是到了某一个山谷就停住了。也就是说,对应非凸函数梯度下降不一定总能够找到全局最优解,有可能得到的只是一个局部最优解。然而,如果函数是凸函数,那么梯度下降法理论上就能得到全局最优解。
梯度下降在机器学习中非常有用。简单地说,可以注意以下几点。
机器学习的本质是找到最优的函数。
如何衡量函数是否最优?其方法是尽量减小预测值和真值间的误差(在机器学习中也叫损失值)。
可以建立误差和模型参数之间的函数(最好是凸函数)。
梯度下降能够引导我们走到凸函数的全局最低点,也就是找到误差最小时的参数。
以上是一文带你了解什么是梯度下降的详细内容。更多信息请关注PHP中文网其他相关文章!






















