

GPT-4的32k输入框还是不够用?Unlimiformer把上下文长度拉到无限长

Transformer 是时下最强大的 seq2seq 架构。预训练 transformer 通常具有 512(例如 BERT)或 1024 个(例如 BART)token 的个上下文窗口,这对于目前许多文本摘要数据集(XSum、CNN/DM)来说是足够长的。
但 16384 并不是生成所需上下文长度的上限:涉及长篇叙事的任务,如书籍摘要(Krys-´cinski et al.,2021)或叙事问答(Kociskýet al.,2018),通常输入超过 10 万个 token。维基百科文章生成的挑战集(Liu*et al.,2018)包含超过 50 万个 token 的输入。生成式问答中的开放域任务可以从更大的输入中综合信息,例如回答关于维基百科上所有健在作者的文章的聚合属性的问题。图 1 根据常见的上下文窗口长度绘制了几个流行的摘要和问答数据集的大小;最长的输入比 Longformer 的上下文窗口长 34 倍以上。
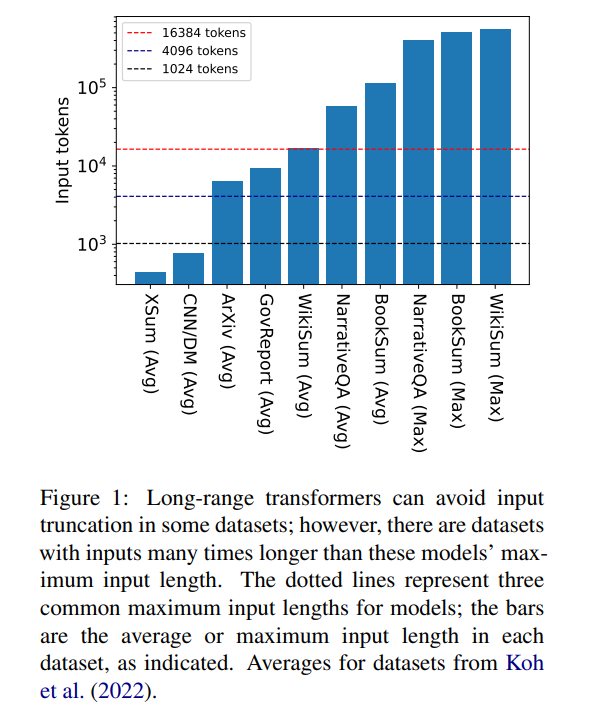
在这些超长输入的情况下,vanilla transformer 无法进行缩放,因为原生注意力机制具有平方级的复杂度。长输入 transformer 虽然比标准 transformer 更高效,但仍需要大量的计算资源,这些资源随着上下文窗口大小的增加而增加。此外,增加上下文窗口需要用新的上下文窗口大小从头开始重新训练模型,计算上和环境上的代价都不小。
在「Unlimiformer: Long-Range Transformers with Unlimited Length Input」一文中,来自卡内基梅隆大学的研究者引入了 Unlimiformer。这是一种基于检索的方法,这种方法增强了预训练的语言模型,以在测试时接受无限长度的输入。

论文链接:https://arxiv.org/pdf/2305.01625v1.pdf
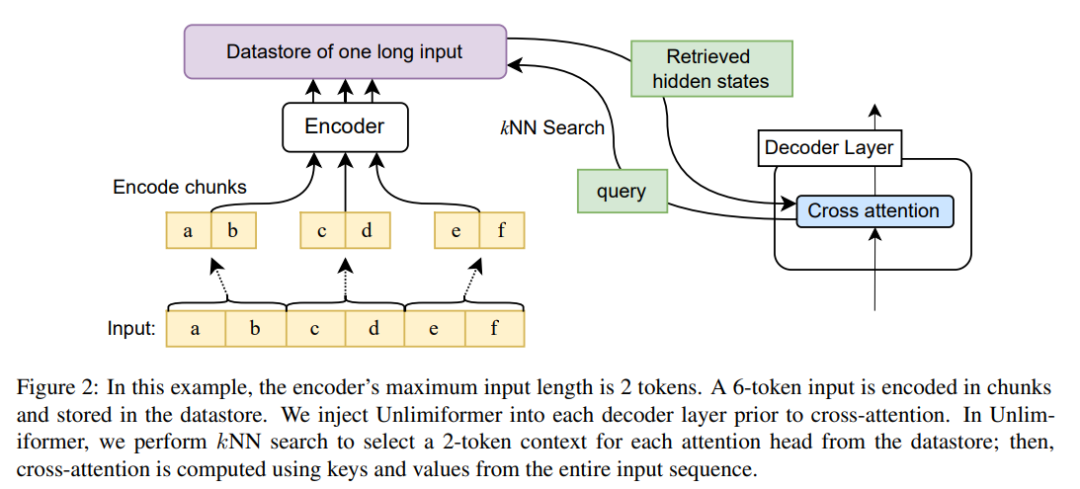
Unlimiformer 可以被注入到任何现有的编码器 - 解码器 transformer 中,能够处理长度不限的输入。给定一个长的输入序列,Unlimiformer 可以在所有输入 token 的隐藏状态上构建一个数据存储。然后,解码器的标准交叉注意力机制能够查询数据存储,并关注前 k 个输入 token。数据存储可以存储在 GPU 或 CPU 内存中,能够次线性查询。
Unlimiformer 可以直接应用于经过训练的模型,并且可以在没有任何进一步训练的情况下改进现有的 checkpoint。Unlimiformer 经过微调后,性能会得到进一步提高。本文证明,Unlimiformer 可以应用于多个基础模型,如 BART(Lewis et al.,2020a)或 PRIMERA(Xiao et al.,2022),且无需添加权重和重新训练。在各种长程 seq2seq 数据集中,Unlimiformer 不仅在这些数据集上比 Longformer(Beltagy et al.,2020b)、SLED(Ivgi et al.,2022)和 Memorizing transformers(Wu et al.,2021)等强长程 Transformer 表现更好,而且本文还发现 Unlimiform 可以应用于 Longformer 编码器模型之上,以进行进一步改进。
Unlimiformer 技术原理
由于编码器上下文窗口的大小是固定的,Transformer 的最大输入长度受到限制。然而,在解码过程中,不同的信息可能是相关的;此外,不同的注意力头可能会关注不同类型的信息(Clark et al.,2019)。因此,固定的上下文窗口可能会在注意力不那么关注的 token 上浪费精力。
在每个解码步骤中,Unlimiformer 中每个注意力头都会从全部输入中选择一个单独的上下文窗口。通过将 Unlimiformer 查找注入解码器来实现:在进入交叉注意力模块之前,该模型在外部数据存储中执行 k 最近邻 (kNN) 搜索,在每个解码器层中的每个注意力头中选一组 token 来参与。
编码
为了将比模型的上下文窗口长度更长的输入序列进行编码,本文按照 Ivgi et al. (2022) 的方法对输入的重叠块进行编码 (Ivgi et al. ,2022),只保留每个 chunk 的输出的中间一半,以确保编码过程前后都有足够的上下文。最后,本文使用 Faiss (Johnson et al., 2019) 等库对数据存储中的编码输入进行索引(Johnson et al.,2019)。
检索增强的交叉注意力机制
在标准的交叉注意力机制中,transformer 的解码器关注编码器的最终隐状态,编码器通常截断输入,并仅对输入序列中的前 k 个 token 进行编码。
本文不是只关注输入的这前 k 个 token,对于每个交叉注意头,都检索更长的输入系列的前 k 个隐状态,并只关注这前 k 个。这样就能从整个输入序列中检索关键字,而不是截断关键字。在计算和 GPU 内存方面,本文的方法也比处理所有输入 token 更便宜,同时通常还能保留 99% 以上的注意力性能。
图 2 显示了本文对 seq2seq transformer 架构的更改。使用编码器对完整输入进行块编码,并将其存储在数据存储中;然后,解码时查询编码的隐状态数据存储。kNN 搜索是非参数的,并且可以被注入到任何预训练的 seq2seq transformer 中,详情如下。
实验结果
长文档摘要
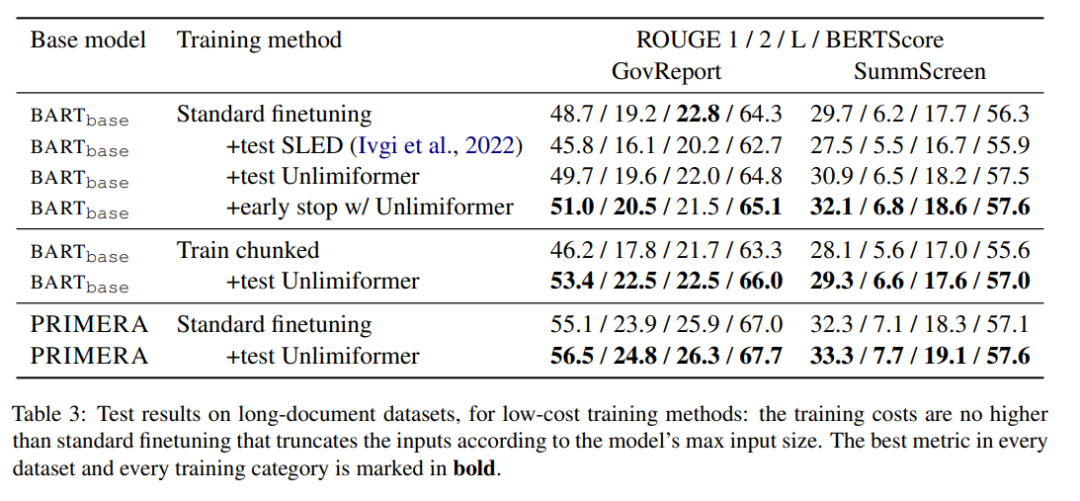
表 3 显示了长文本(4k 及 16k 的 token 输入)摘要数据集中的结果。
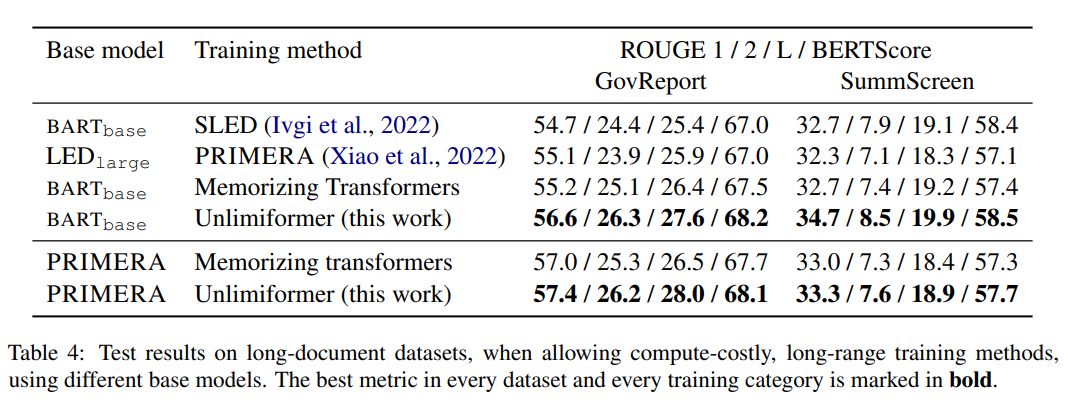
在表 4 的训练方法中,Unlimiformer 能够在各项指标上达到最优。
书籍摘要
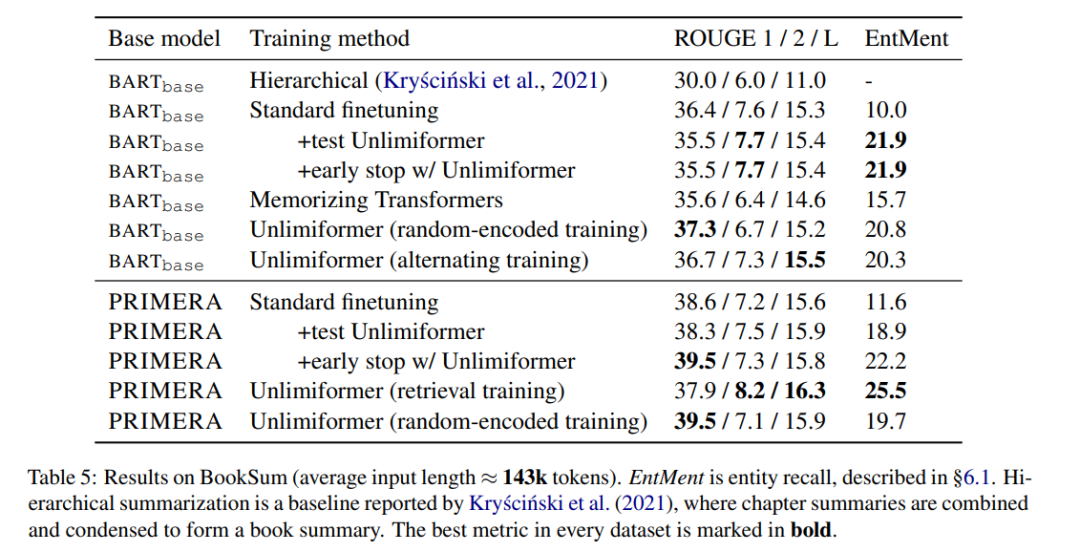
表 5 显示了在书籍摘要上的结果。可以看到,基于 BARTbase 和 PRIMERA,应用 Unlimiformer 都能取得一定的改进效果。
以上是GPT-4的32k输入框还是不够用?Unlimiformer把上下文长度拉到无限长的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 如何添加新列
Apr 09, 2025 pm 02:09 PM
SQL 中通过使用 ALTER TABLE 语句为现有表添加新列。具体步骤包括:确定表名称和列信息、编写 ALTER TABLE 语句、执行语句。例如,为 Customers 表添加 email 列(VARCHAR(50)):ALTER TABLE Customers ADD email VARCHAR(50);
 SQL 添加列的语法是什么
Apr 09, 2025 pm 02:51 PM
SQL 添加列的语法是什么
Apr 09, 2025 pm 02:51 PM
SQL 中添加列的语法为 ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value]; 其中,table_name 是表名,column_name 是新列名,data_type 是数据类型,NOT NULL 指定是否允许空值,DEFAULT default_value 指定默认值。
 SQL 清空表:性能优化技巧
Apr 09, 2025 pm 02:54 PM
SQL 清空表:性能优化技巧
Apr 09, 2025 pm 02:54 PM
提高 SQL 清空表性能的技巧:使用 TRUNCATE TABLE 代替 DELETE,释放空间并重置标识列。禁用外键约束,防止级联删除。使用事务封装操作,保证数据一致性。批量删除大数据,通过 LIMIT 限制行数。清空后重建索引,提高查询效率。
 SQL 添加列时如何设置默认值
Apr 09, 2025 pm 02:45 PM
SQL 添加列时如何设置默认值
Apr 09, 2025 pm 02:45 PM
为新添加的列设置默认值,使用 ALTER TABLE 语句:指定添加列并设置默认值:ALTER TABLE table_name ADD column_name data_type DEFAULT default_value;使用 CONSTRAINT 子句指定默认值:ALTER TABLE table_name ADD COLUMN column_name data_type CONSTRAINT default_constraint DEFAULT default_value;
 使用 DELETE 语句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
使用 DELETE 语句清空 SQL 表
Apr 09, 2025 pm 03:00 PM
是的,DELETE 语句可用于清空 SQL 表,步骤如下:使用 DELETE 语句:DELETE FROM table_name;替换 table_name 为要清空的表的名称。
 Redis内存碎片如何处理?
Apr 10, 2025 pm 02:24 PM
Redis内存碎片如何处理?
Apr 10, 2025 pm 02:24 PM
Redis内存碎片是指分配的内存中存在无法再分配的小块空闲区域。应对策略包括:重启Redis:彻底清空内存,但会中断服务。优化数据结构:使用更适合Redis的结构,减少内存分配和释放次数。调整配置参数:使用策略淘汰最近最少使用的键值对。使用持久化机制:定期备份数据,重启Redis清理碎片。监控内存使用情况:及时发现问题并采取措施。
 phpmyadmin建立数据表
Apr 10, 2025 pm 11:00 PM
phpmyadmin建立数据表
Apr 10, 2025 pm 11:00 PM
要使用 phpMyAdmin 创建数据表,以下步骤必不可少:连接到数据库并单击“新建”标签。为表命名并选择存储引擎(推荐 InnoDB)。通过单击“添加列”按钮添加列详细信息,包括列名、数据类型、是否允许空值以及其他属性。选择一个或多个列作为主键。单击“保存”按钮创建表和列。
 怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
创建Oracle数据库并非易事,需理解底层机制。1. 需了解数据库和Oracle DBMS的概念;2. 掌握SID、CDB(容器数据库)、PDB(可插拔数据库)等核心概念;3. 使用SQL*Plus创建CDB,再创建PDB,需指定大小、数据文件数、路径等参数;4. 高级应用需调整字符集、内存等参数,并进行性能调优;5. 需注意磁盘空间、权限和参数设置,并持续监控和优化数据库性能。 熟练掌握需不断实践,才能真正理解Oracle数据库的创建和管理。
