

SpringBoot如何实现过滤敏感词

过滤敏感词

1. 创建一个储存要过滤的敏感词的文本文件
首先创建一个文本文件储存要过滤的敏感词
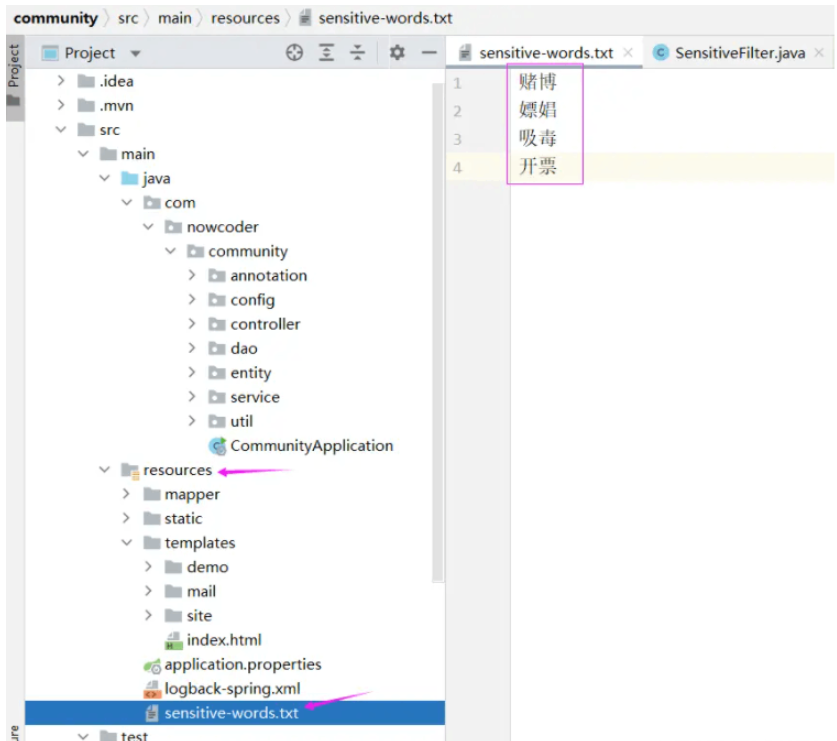
在下面的工具类中我们会读取这个文本文件,这里提前给出
@PostConstruct // 这个注解表示当容器实例化这个bean(服务启动的时候)之后在调用构造器之后这个方法会自动的调用
public void init(){
try(
// 读取写有“敏感词”的文件,getClass表示从程序编译之后的target/classes读配置文件,读之后是字节流
// java7语法,在这里的句子最后会自动执行close语句
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
// 字节流 -> 字符流 -> 缓冲流
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
// 从文件中一行一行读
while ((keyword = reader.readLine()) != null){
// 添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败: " + e.getMessage());
}
}2. 开发过滤敏感词的工具类
开发过滤敏感词组件
为了方便以后复用,我们把过滤敏感词写成一个工具类SensitiveFilter。
@Component
public class SensitiveFilter {
private static final Logger logger = LoggerFactory.getLogger(SensitiveFilter.class);
// 当检测到敏感词后我们要把敏感词替换成什么符号
private static final String REPLACEMENT = "***";
// 根节点
private TrieNode rootNode = new TrieNode();
@PostConstruct // 这个注解表示当容器实例化这个bean(服务启动的时候)之后在调用构造器之后这个方法会自动的调用
public void init(){
try(
// 读取写有“敏感词”的文件,getClass表示从程序编译之后的target/classes读配置文件,读之后是字节流
// java7语法,在这里的句子最后会自动执行close语句
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
// 字节流 -> 字符流 -> 缓冲流
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
// 从文件中一行一行读
while ((keyword = reader.readLine()) != null){
// 添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败: " + e.getMessage());
}
}
// 将一个敏感词添加到前缀树中
private void addKeyword(String keyword){
// 首先默认指向根
TrieNode tempNode = rootNode;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if(subNode == null){
// subNode为空,初始化子节点;subNode不为空,直接用就可以了
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指针指向子节点,进入下一轮循环
tempNode = subNode;
}
// 最后要设置结束标识
tempNode.setKeywordEnd(true);
}
/**
* 过滤敏感词
* @param text 待过滤的文本
* @return 过滤后的文本
*/
public String filter(String text){
if(StringUtils.isBlank(text)){
// 待过滤的文本为空,直接返回null
return null;
}
// 指针1,指向树
TrieNode tempNode = rootNode;
// 指针2,指向正在检测的字符串段的首
int begin = 0;
// 指针3,指向正在检测的字符串段的尾
int position = 0;
// 储存过滤后的文本
StringBuilder sb = new StringBuilder();
while (begin < text.length()){
char c = text.charAt(position);
// 跳过符号,比如 “开票”是敏感词 #开#票# 这个字符串中间的 '#' 应该跳过
if(isSymbol(c)){
// 是特殊字符
// 若指针1处于根节点,将此符号计入结果,指针2、3向右走一步
if(tempNode == rootNode){
sb.append(c);
begin++;
}
// 无论符号在开头或中间,指针3都向下走一步
position++;
// 符号处理完,进入下一轮循环
continue;
}
// 执行到这里说明字符不是特殊符号
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if(tempNode == null){
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = rootNode;
} else if(tempNode.isKeywordEnd()){
// 发现敏感词,将begin~position字符串替换掉,存 REPLACEMENT (里面是***)
sb.append(REPLACEMENT);
// 进入下一个位置
begin = ++position;
// 重新指向根节点
tempNode = rootNode;
} else {
// 检查下一个字符
position++;
}
}
return sb.toString();
}
// 判断是否为特殊符号,是则返回true,不是则返回false
private boolean isSymbol(Character c){
// CharUtils.isAsciiAlphanumeric(c)方法:a、b、1、2···返回true,特殊字符返回false
// 0x2E80 ~ 0x9FFF 是东亚的文字范围,东亚文字范围我们不认为是符号
return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
// 前缀树
private class TrieNode{
// 关键词结束标识
private boolean isKeywordEnd = false;
// 当前节点的子节点(key是下级字符、value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node){
subNodes.put(c, node);
}
// 获取子节点
public TrieNode getSubNode(Character c){
return subNodes.get(c);
}
}
}
上面就是过滤敏感词工具类的全部代码,接下来我们来解释一下开发步骤
开发过滤敏感词组件分为三步:
1.定义前缀树(Tree)
我们将定义前缀树写为SensitiveFilter工具类的内部类
// 前缀树
private class TrieNode{
// 关键词结束标识
private boolean isKeywordEnd = false;
// 当前节点的子节点(key是下级字符、value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node){
subNodes.put(c, node);
}
// 获取子节点
public TrieNode getSubNode(Character c){
return subNodes.get(c);
}
}
2.根据敏感词,初始化前缀树
将敏感词添加到前缀树中
// 将一个敏感词添加到前缀树中
private void addKeyword(String keyword){
// 首先默认指向根
TrieNode tempNode = rootNode;
for (int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tempNode.getSubNode(c);
if(subNode == null){
// subNode为空,初始化子节点;subNode不为空,直接用就可以了
subNode = new TrieNode();
tempNode.addSubNode(c, subNode);
}
// 指针指向子节点,进入下一轮循环
tempNode = subNode;
}
// 最后要设置结束标识
tempNode.setKeywordEnd(true);
}
3.编写过滤敏感词的方法
如何过滤文本中的敏感词:
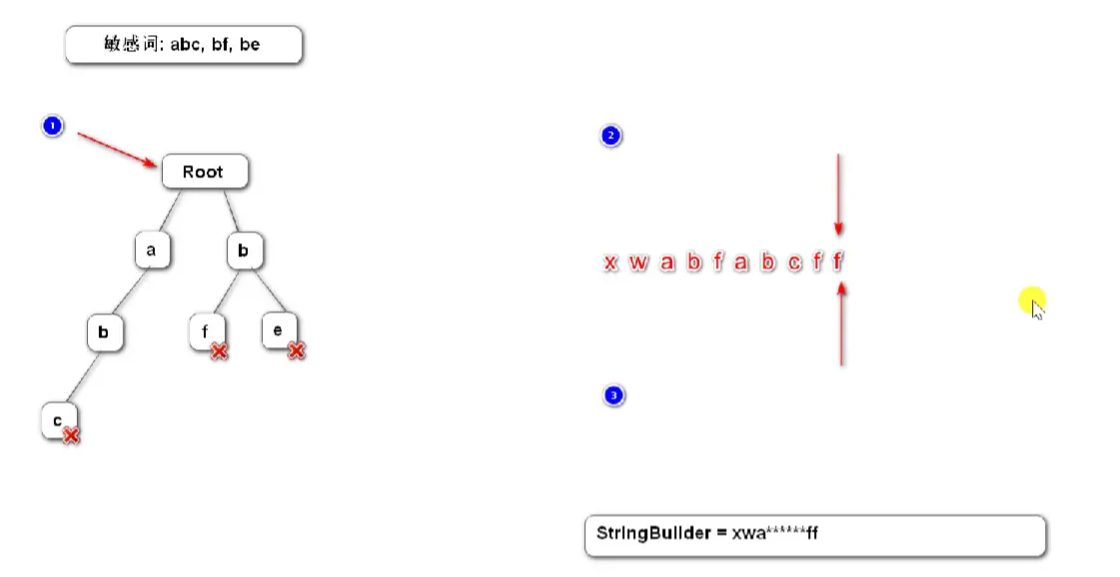
特殊符号怎么处理:

敏感词前缀树初始化完毕之后,过滤文本中的敏感词的算法应该如下:
定义三个指针:
指针1指向Tree树
指针2指向待过滤字符串段的头
指针3指向待过滤字符串段的尾
/**
* 过滤敏感词
* @param text 待过滤的文本
* @return 过滤后的文本
*/
public String filter(String text){
if(StringUtils.isBlank(text)){
// 待过滤的文本为空,直接返回null
return null;
}
// 指针1,指向树
TrieNode tempNode = rootNode;
// 指针2,指向正在检测的字符串段的首
int begin = 0;
// 指针3,指向正在检测的字符串段的尾
int position = 0;
// 储存过滤后的文本
StringBuilder sb = new StringBuilder();
while (begin < text.length()){
char c = text.charAt(position);
// 跳过符号,比如 “开票”是敏感词 #开#票# 这个字符串中间的 '#' 应该跳过
if(isSymbol(c)){
// 是特殊字符
// 若指针1处于根节点,将此符号计入结果,指针2、3向右走一步
if(tempNode == rootNode){
sb.append(c);
begin++;
}
// 无论符号在开头或中间,指针3都向下走一步
position++;
// 符号处理完,进入下一轮循环
continue;
}
// 执行到这里说明字符不是特殊符号
// 检查下级节点
tempNode = tempNode.getSubNode(c);
if(tempNode == null){
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
// 进入下一个位置
position = ++begin;
// 重新指向根节点
tempNode = rootNode;
} else if(tempNode.isKeywordEnd()){
// 发现敏感词,将begin~position字符串替换掉,存 REPLACEMENT (里面是***)
sb.append(REPLACEMENT);
// 进入下一个位置
begin = ++position;
// 重新指向根节点
tempNode = rootNode;
} else {
// 检查下一个字符
position++;
}
}
return sb.toString();
}
// 判断是否为特殊符号,是则返回true,不是则返回false
private boolean isSymbol(Character c){
// CharUtils.isAsciiAlphanumeric(c)方法:a、b、1、2···返回true,特殊字符返回false
// 0x2E80 ~ 0x9FFF 是东亚的文字范围,东亚文字范围我们不认为是符号
return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
最后:建议在测试类中测试一下
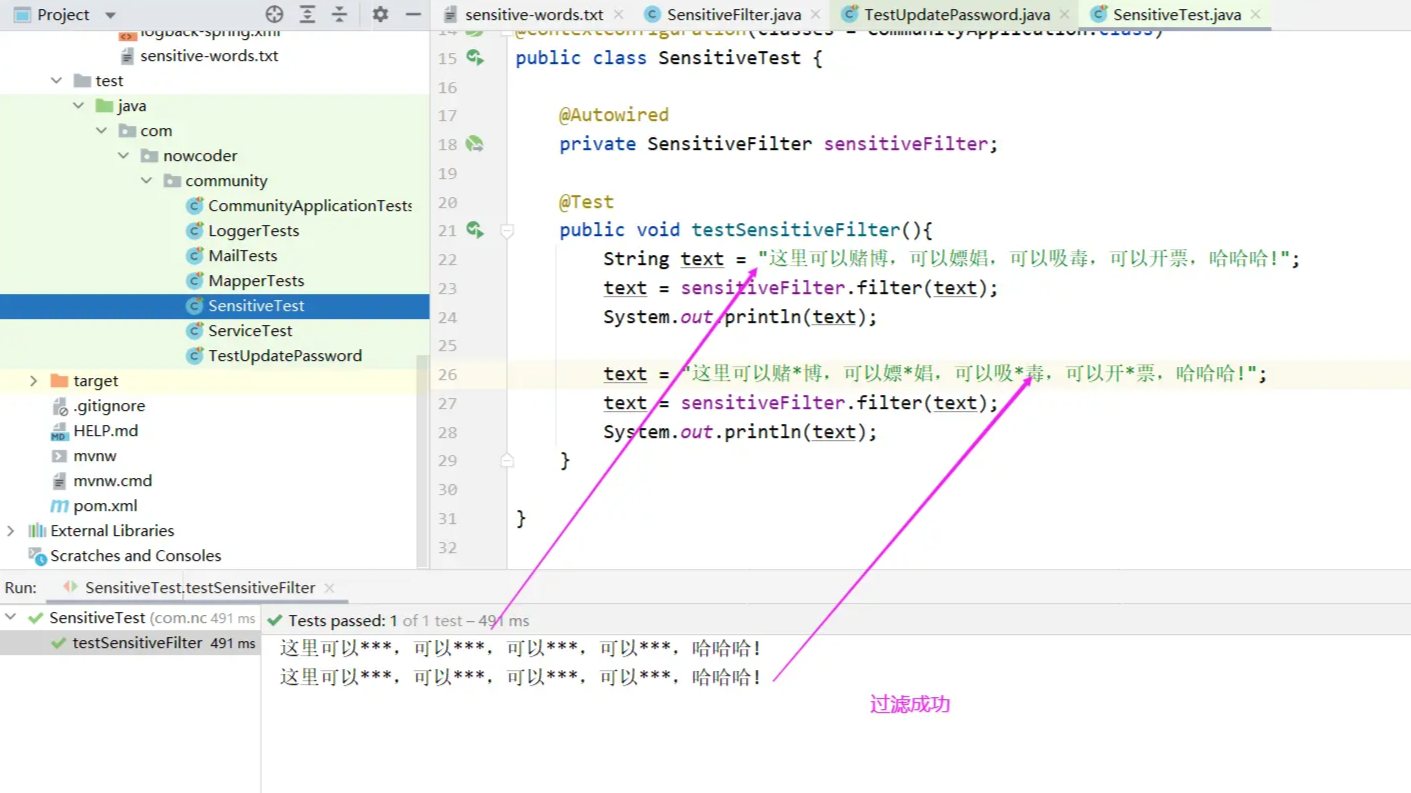
经测试,过滤敏感词的工具类开发完成,这个工具会在接下来的发布帖子的功能中用到。
以上是SpringBoot如何实现过滤敏感词的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Springboot怎么集成Jasypt实现配置文件加密
Jun 01, 2023 am 08:55 AM
Springboot怎么集成Jasypt实现配置文件加密
Jun 01, 2023 am 08:55 AM
Jasypt介绍Jasypt是一个java库,它允许开发员以最少的努力为他/她的项目添加基本的加密功能,并且不需要对加密工作原理有深入的了解用于单向和双向加密的高安全性、基于标准的加密技术。加密密码,文本,数字,二进制文件...适合集成到基于Spring的应用程序中,开放API,用于任何JCE提供程序...添加如下依赖:com.github.ulisesbocchiojasypt-spring-boot-starter2.1.1Jasypt好处保护我们的系统安全,即使代码泄露,也可以保证数据源的
 怎么在SpringBoot中使用Redis实现分布式锁
Jun 03, 2023 am 08:16 AM
怎么在SpringBoot中使用Redis实现分布式锁
Jun 03, 2023 am 08:16 AM
一、Redis实现分布式锁原理为什么需要分布式锁在聊分布式锁之前,有必要先解释一下,为什么需要分布式锁。与分布式锁相对就的是单机锁,我们在写多线程程序时,避免同时操作一个共享变量产生数据问题,通常会使用一把锁来互斥以保证共享变量的正确性,其使用范围是在同一个进程中。如果换做是多个进程,需要同时操作一个共享资源,如何互斥呢?现在的业务应用通常是微服务架构,这也意味着一个应用会部署多个进程,多个进程如果需要修改MySQL中的同一行记录,为了避免操作乱序导致脏数据,此时就需要引入分布式锁了。想要实现分
 SpringBoot怎么集成Redisson实现延迟队列
May 30, 2023 pm 02:40 PM
SpringBoot怎么集成Redisson实现延迟队列
May 30, 2023 pm 02:40 PM
使用场景1、下单成功,30分钟未支付。支付超时,自动取消订单2、订单签收,签收后7天未进行评价。订单超时未评价,系统默认好评3、下单成功,商家5分钟未接单,订单取消4、配送超时,推送短信提醒……对于延时比较长的场景、实时性不高的场景,我们可以采用任务调度的方式定时轮询处理。如:xxl-job今天我们采
 SpringBoot与SpringMVC的比较及差别分析
Dec 29, 2023 am 11:02 AM
SpringBoot与SpringMVC的比较及差别分析
Dec 29, 2023 am 11:02 AM
SpringBoot和SpringMVC都是Java开发中常用的框架,但它们之间有一些明显的差异。本文将探究这两个框架的特点和用途,并对它们的差异进行比较。首先,我们来了解一下SpringBoot。SpringBoot是由Pivotal团队开发的,它旨在简化基于Spring框架的应用程序的创建和部署。它提供了一种快速、轻量级的方式来构建独立的、可执行
 springboot读取文件打成jar包后访问不到怎么解决
Jun 03, 2023 pm 04:38 PM
springboot读取文件打成jar包后访问不到怎么解决
Jun 03, 2023 pm 04:38 PM
springboot读取文件,打成jar包后访问不到最新开发出现一种情况,springboot打成jar包后读取不到文件,原因是打包之后,文件的虚拟路径是无效的,只能通过流去读取。文件在resources下publicvoidtest(){Listnames=newArrayList();InputStreamReaderread=null;try{ClassPathResourceresource=newClassPathResource("name.txt");Input
 SpringBoot怎么自定义Redis实现缓存序列化
Jun 03, 2023 am 11:32 AM
SpringBoot怎么自定义Redis实现缓存序列化
Jun 03, 2023 am 11:32 AM
1、自定义RedisTemplate1.1、RedisAPI默认序列化机制基于API的Redis缓存实现是使用RedisTemplate模板进行数据缓存操作的,这里打开RedisTemplate类,查看该类的源码信息publicclassRedisTemplateextendsRedisAccessorimplementsRedisOperations,BeanClassLoaderAware{//声明了key、value的各种序列化方式,初始值为空@NullableprivateRedisSe
 Springboot+Mybatis-plus不使用SQL语句进行多表添加怎么实现
Jun 02, 2023 am 11:07 AM
Springboot+Mybatis-plus不使用SQL语句进行多表添加怎么实现
Jun 02, 2023 am 11:07 AM
在Springboot+Mybatis-plus不使用SQL语句进行多表添加操作我所遇到的问题准备工作在测试环境下模拟思维分解一下:创建出一个带有参数的BrandDTO对象模拟对后台传递参数我所遇到的问题我们都知道,在我们使用Mybatis-plus中进行多表操作是极其困难的,如果你不使用Mybatis-plus-join这一类的工具,你只能去配置对应的Mapper.xml文件,配置又臭又长的ResultMap,然后再去写对应的sql语句,这种方法虽然看上去很麻烦,但具有很高的灵活性,可以让我们
 springboot怎么获取application.yml里值
Jun 03, 2023 pm 06:43 PM
springboot怎么获取application.yml里值
Jun 03, 2023 pm 06:43 PM
在项目中,很多时候需要用到一些配置信息,这些信息在测试环境和生产环境下可能会有不同的配置,后面根据实际业务情况有可能还需要再做修改。我们不能将这些配置在代码中写死,最好是写到配置文件中,比如可以把这些信息写到application.yml文件中。那么,怎么在代码里获取或者使用这个地址呢?有2个方法。方法一:我们可以通过@Value注解的${key}即可获取配置文件(application.yml)中和key对应的value值,这个方法适用于微服务比较少的情形方法二:在实际项目中,遇到业务繁琐,逻
