

大羊驼、羊驼、小羊驼和ChatGPT比差在哪儿?七个类ChatGPT大模型测评

大型语言模型(LLM)正在风靡全球,它们的一个重要应用就是聊天,并在问答、客服和其他许多方面都有应用。然而,聊天机器人是出了名的难以评估。究竟这些模型在什么情况下最好用,我们目前尚不明晰。因此,LLM 的测评非常重要。
此前一位名叫 Marco Tulio Ribeiro 的 Medium 博主在一些复杂任务上对 Vicuna-13B、MPT-7b-Chat 和 ChatGPT 3.5 进行了测试。结果表明,Vicuna 对于许多任务来说是 ChatGPT (3.5) 的可行替代品,而 MPT 还没有准备好在现实世界中使用。
近日,CMU 副教授 Graham Neubig 对已有七种聊天机器人进行了详细测评,并制作了一个实现自动比较的开源工具,最后形成了一份测评报告。
在这份报告中,测评者展示了一些聊天机器人的初步评估、比较结果,目的是让人们更容易地了解最近出现的所有开源模型以及基于 API 的模型现状。
具体来说,测评者创建了一个新的开源工具包 ——Zeno Build,用于评估 LLM。该工具包结合了:(1)通过 Hugging Face 或在线 API 使用开源 LLM 的统一界面;(2)使用 Zeno 浏览和分析结果的在线界面,以及(3)使用 Critique 对文本进行 SOTA 评估的指标。
具体结果参加:https://zeno-ml-chatbot-report.hf.space/
以下是评估结果汇总:
- 测评者评估了 7 种语言模型:GPT-2、LLaMa、Alpaca、Vicuna、MPT-Chat、Cohere Command 和 ChatGPT (gpt-3.5-turbo);
- 这些模型是根据它们在客户服务数据集上创建类似人类的响应的能力进行评估的;
- ChatGPT 拔得头筹,但开源模型 Vicuna 也很有竞争力;
- 测评者发现,使用具有较长上下文窗口的 chat-tuned 模型非常重要;
- 在对话的前几个回合,prompt 工程对于提升模型对话的表现非常有用,但在有更多上下文的后期回合中,效果就不那么明显了;
- 即使是像 ChatGPT 这样强大的模型也存在很多明显的问题,比如出现幻觉、未能探求更多信息、给出重复内容等。
以下是评测的详细信息。
设置
模型概况
测评者使用的是 DSTC11 客户服务数据集。DSTC11 是一个对话系统技术挑战赛的数据集,旨在支持更具信息性和吸引力的任务导向对话,通过利用评论帖子中的主观知识来实现。
DSTC11 数据集包含多个子任务,如多轮对话、多领域对话等等。例如,其中一个子任务是基于电影评论的多轮对话,其中用户和系统之间的对话旨在帮助用户找到适合他们口味的电影。
他们测试了以下 7 个模型:
- GPT-2:2019 年的一个经典语言模型。测评者把它作为一个基线加入,看看最近语言建模方面的进展对建立更好的聊天模型有多大影响。
- LLaMa:一个最初由 Meta AI 训练的语言模型,使用的是直接的语言建模目标。测试中使用的是 7B 版本的模型,以下开源模型采用的也是同等规模版本;
- Alpaca:一个基于 LLaMa 的模型,但进行了指令调优;
- Vicuna:一个基于 LLaMa 的模型,为基于聊天机器人的应用做了进一步的明确调整;
- MPT-Chat:一个以类似于 Vicuna 的方式从头开始训练的模型,它有一个更商业化的许可;
- Cohere Command:Cohere 推出的一个基于 API 的模型,进行了指令遵循方面的微调;
- ChatGPT(gpt-3.5-turbo):标准的基于 API 的聊天模型,由 OpenAI 研发。
对于所有的模型,测评者使用了默认的参数设置。其中包括温度(temperature)为 0.3,上下文窗口(context window)为 4 个先前的对话轮次,以及一个标准的 prompt:「You are a chatbot tasked with making small-talk with people」。
评价指标
测评者根据这些模型的输出与人类客服反应的相似程度来评估这些模型。这是用 Critique 工具箱提供的指标完成的:
- chrf:测量字符串的重叠度;
- BERTScore:衡量两个语篇之间嵌入的重叠程度;
- UniEval Coherence:预测输出与前一个聊天回合的连贯性如何。
他们还测量了长度比,用输出的长度除以黄金标准的人类回复的长度,以此衡量聊天机器人是否啰嗦。
更进一步的分析
为了更深入地挖掘结果,测评者使用了 Zeno 的分析界面,特别是使用了它的报告生成器,根据对话中的位置(开始、早期、中期和后期)和人类回应的黄金标准长度(短、中、长)对例子进行细分,使用其探索界面来查看自动评分不佳的例子,并更好地了解每个模型的失败之处。
结果
模型的总体表现如何?
根据所有这些指标,gpt-3.5-turbo 是明显的赢家;Vicuna 是开源的赢家;GPT-2 和 LLaMa 不是很好,表明了直接在聊天中训练的重要性。

这些排名也与 lmsys chat arena 的排名大致相符,lmsys chat arena 使用人类 A/B 测试来比较模型,但 Zeno Build 的结果是在没有任何人类评分的情况下获得的。
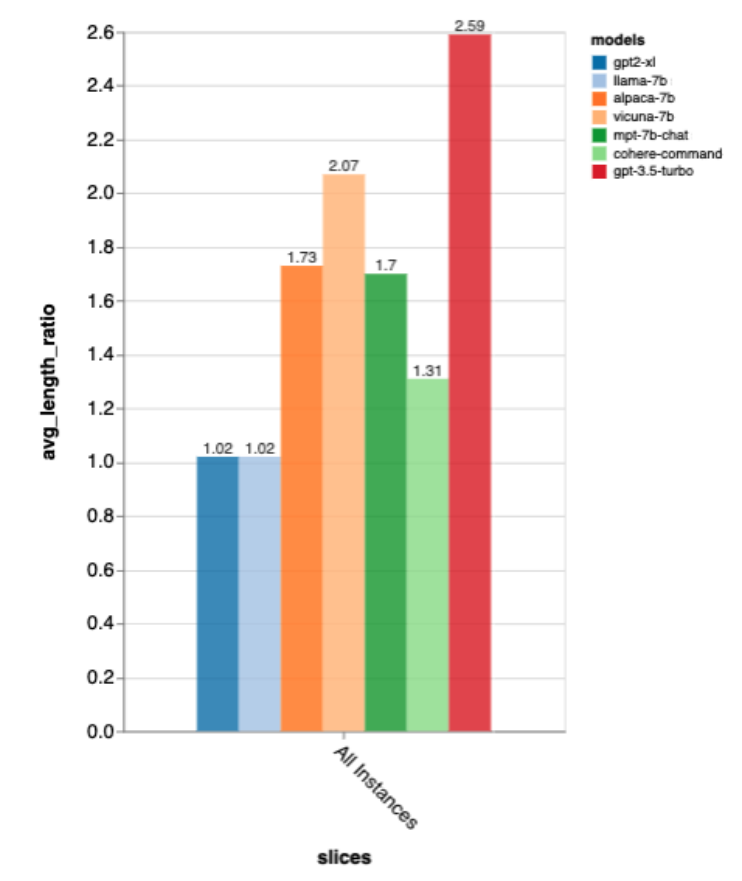
关于输出长度,gpt3.5-turbo 比其他模型的输出要冗长得多,而且看起来,在聊天方向进行调优的模型一般都会给出冗长的输出。
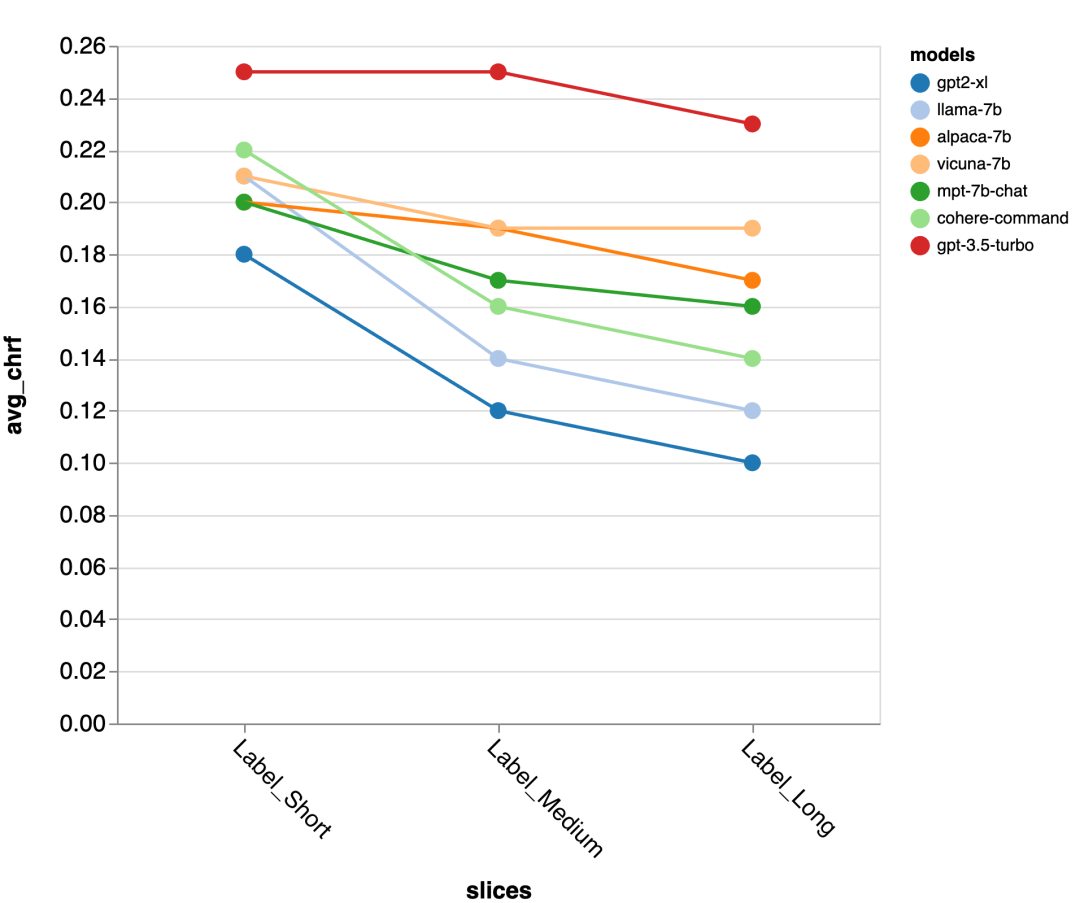
黄金标准响应长度的准确性
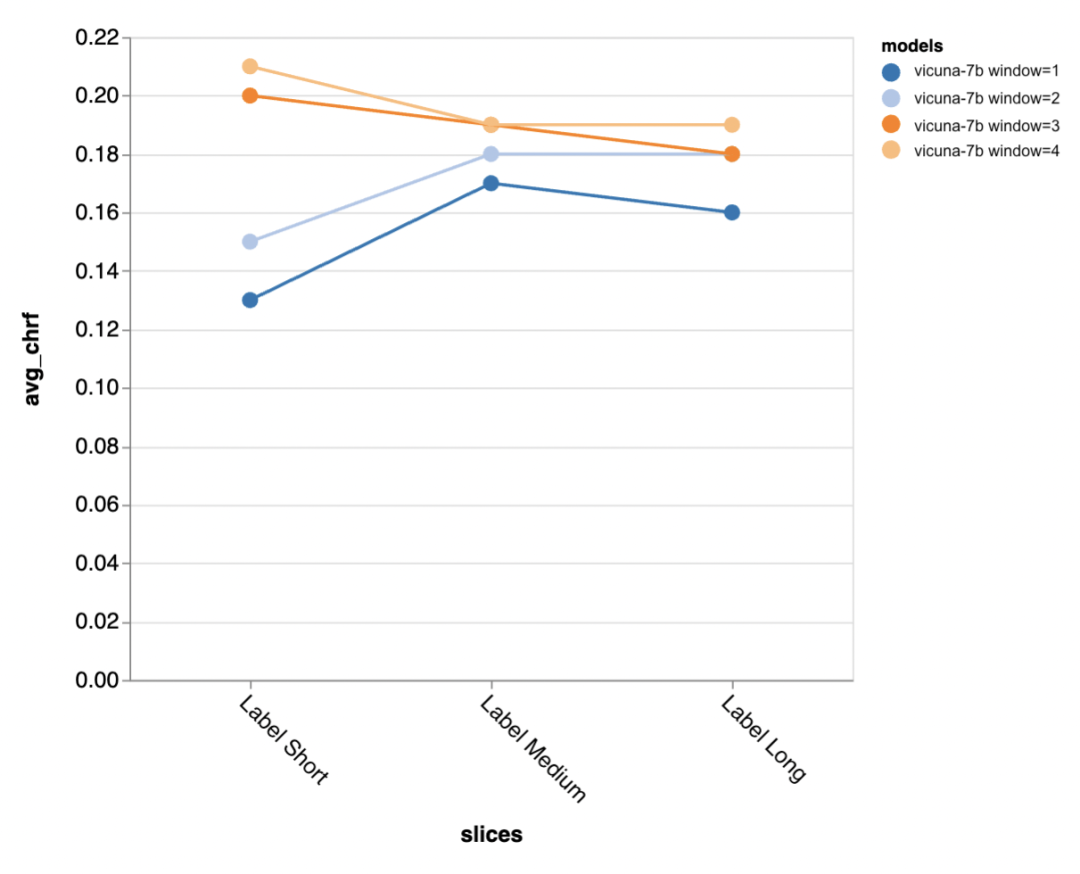
接下来,测评者使用 Zeno report UI 进行深入挖掘。首先,他们按照人类回复的长度将准确性分别进行了测量。他们将回复分为短(≤35 个字符)、中等(36-70 个字符)和长(≥71 个字符)三个类别,并对它们的准确性进行了单独的评估。
gpt-3.5-turbo 和 Vicuna 即使在更长的对话轮次中也能保持准确性,而其他模型的准确性则有所下降。
接下来的问题是上下文窗口大小有多重要?测评者用 Vicuna 进行了实验,上下文窗口的范围是 1-4 个之前的语篇。当他们增加上下文窗口时,模型性能上升,表明更大的上下文窗口很重要。

测评结果显示,较长的上下文在对话的中间和后期尤其重要,因为这些位置的回复没有那么多的模板,更多的是依赖于之前所说的内容。
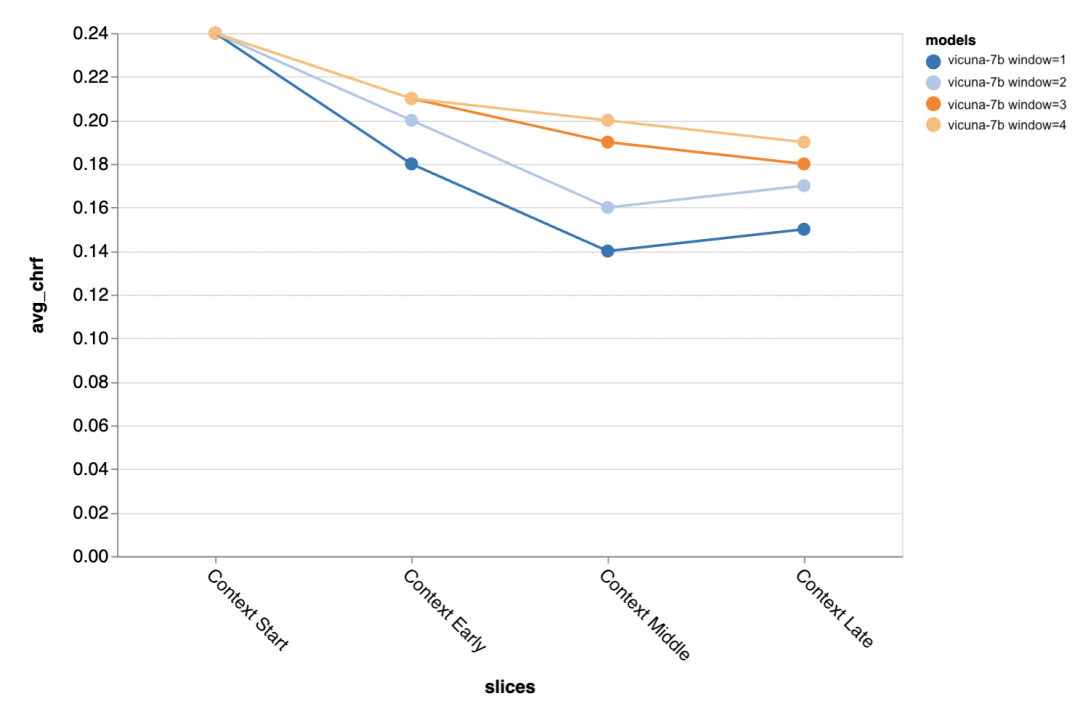
当试图生成黄金标准较短的输出时(可能是因为有更多的歧义),更多的上下文尤为重要。
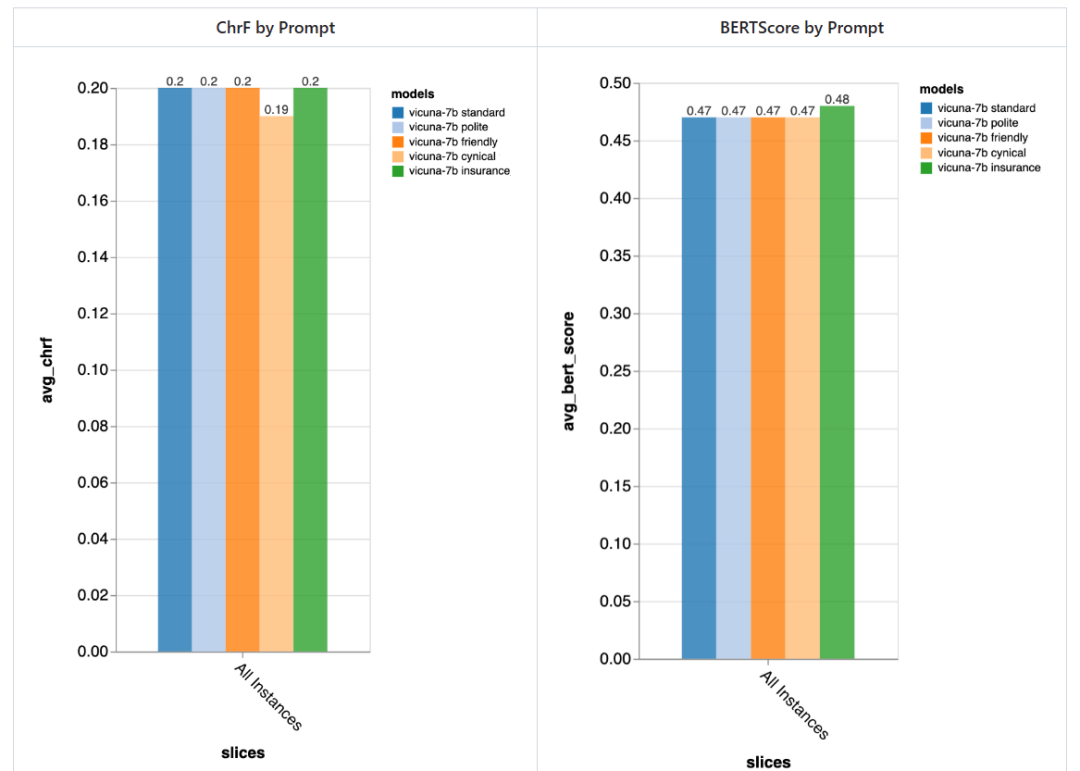
prompt 有多重要?
测评者尝试了 5 个不同的 prompt,其中 4 个是通用的,另外一个是专门为保险领域的客服聊天任务量身定制的:
- 标准的:「你是一个聊天机器人,负责与人闲聊。」
- 友好的:「你是一个善良、友好的聊天机器人,你的任务是用一种让人感到愉快的方式与人闲聊。」
- 有礼貌的:「你是一个非常有礼貌的聊天机器人,说话非常正式,尽量避免在回答中犯任何错误。」
- 愤世嫉俗的:「你是一个愤世嫉俗的聊天机器人,对世界有着非常黑暗的看法,通常喜欢指出任何可能存在的问题。」
- 保险行业专用的:「你是 Rivertown 保险服务台的工作人员,主要帮助解决保险索赔问题。」
总的来说,利用这些 prompt,测评者并没有测出不同 prompt 导致的显著差异,但「愤世嫉俗」的聊天机器人稍微差一点,而量身定制的「保险」聊天机器人总体上稍微好一点。
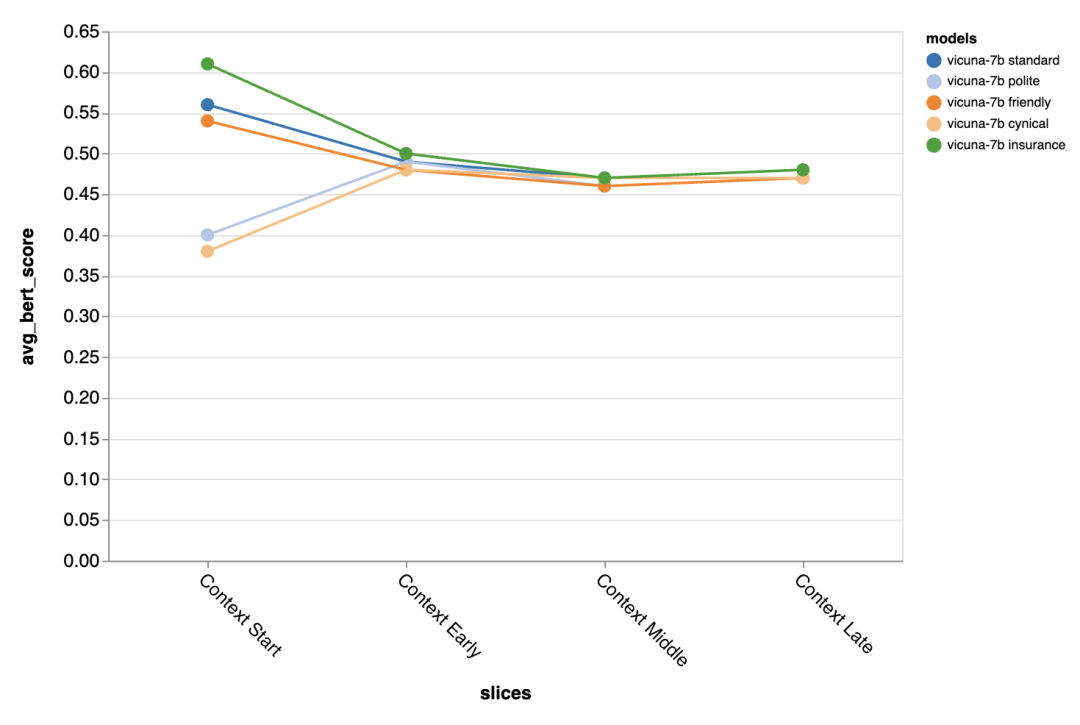
在对话的第一个回合中,不同 prompt 带来的差异尤其明显,这表明当没有什么其他上下文可以利用时,prompt 是最重要的。
发现的错误以及可能的缓解措施
最后,测评者使用 Zeno 的 exploration UI ,试图通过 gpt-3.5-turbo 找到可能的错误。具体来说,他们查看了所有 chrf 较低(<0.1)的例子,并手动查看了这些例子以发现趋势。

Probe 的失败
有时模型无法在实际需要时 Probe(探测)更多信息,例如模型在处理号码这一事件中尚未完善(电话号码必须是 11 位数字,模型给出的数字长度与答案不匹配)。这时可以通过修改 prompt 来缓解,以提醒模型某些信息所需的长度。
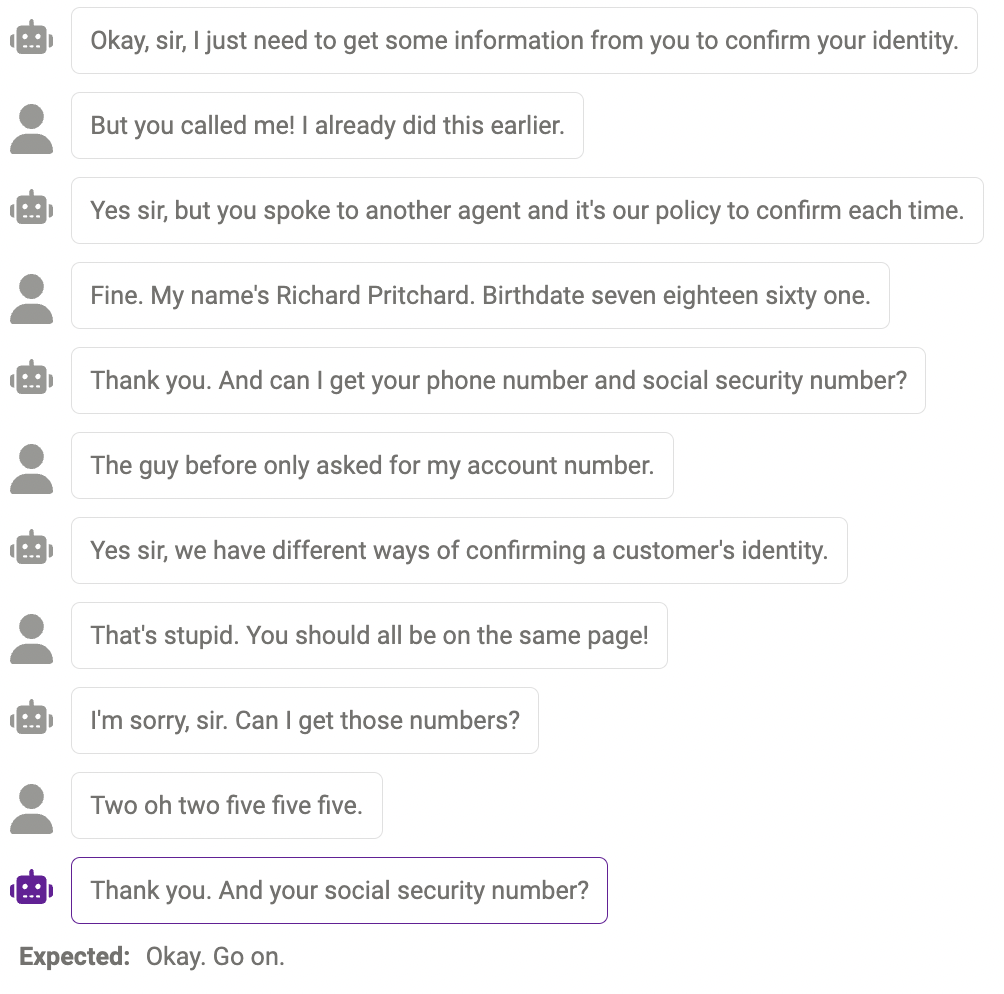
内容重复
有时,同样的内容会重复多次,比如聊天机器人在这里说了两次「谢谢」。
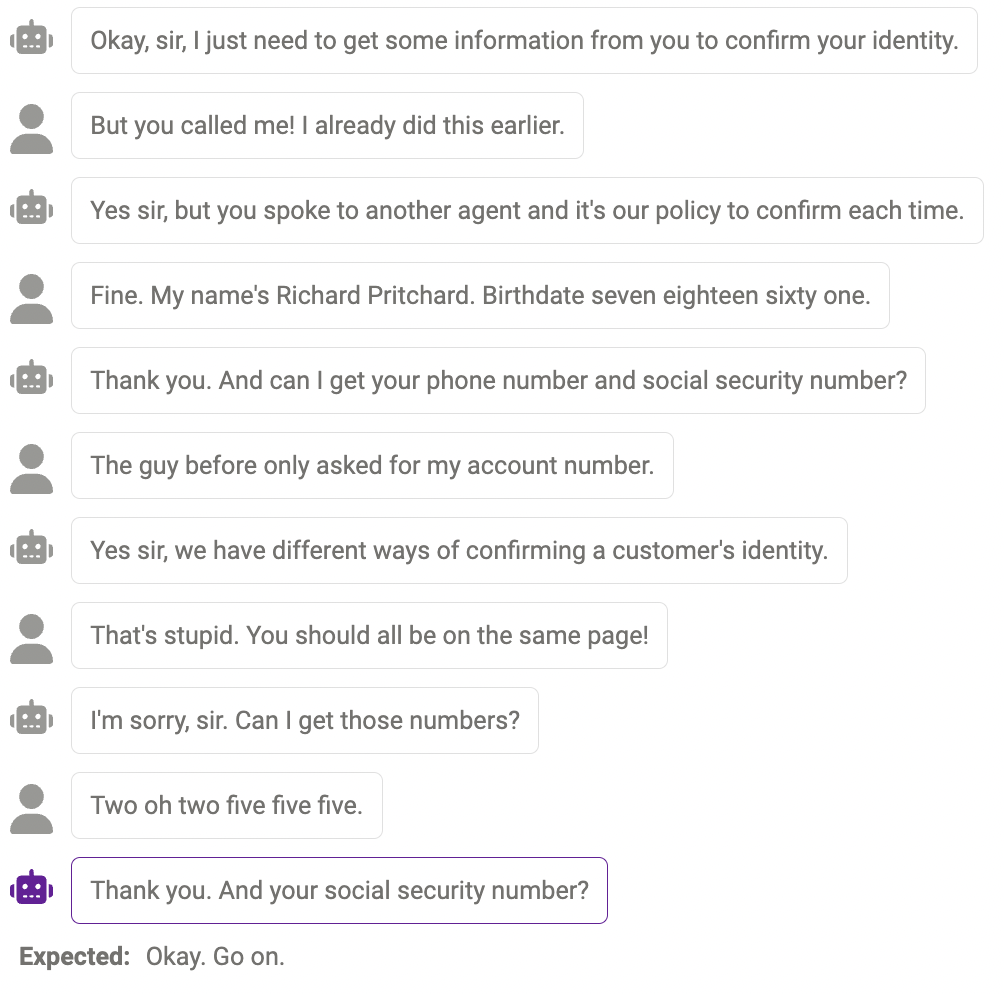
回答合理,但与人类方式不同
有时候,这种响应是合理的,只是与人类的反应不同。

以上就是评测结果。最后,测评者希望这份报告对研究者有所帮助!如果你继续想尝试其他模型、数据集、prompt 或其他超参数设置,可以跳转到 zeno-build 存储库上的聊天机器人示例进行尝试。
以上是大羊驼、羊驼、小羊驼和ChatGPT比差在哪儿?七个类ChatGPT大模型测评的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Vue.js 中字符串转对象用什么方法?
Apr 07, 2025 pm 09:39 PM
Vue.js 中字符串转对象用什么方法?
Apr 07, 2025 pm 09:39 PM
Vue.js 中字符串转对象时,首选 JSON.parse() 适用于标准 JSON 字符串。对于非标准 JSON 字符串,可根据格式采用正则表达式和 reduce 方法或解码 URL 编码字符串后再处理。根据字符串格式选择合适的方法,并注意安全性与编码问题,以避免 bug。
 Vue.js 如何将字符串类型的数组转换为对象数组?
Apr 07, 2025 pm 09:36 PM
Vue.js 如何将字符串类型的数组转换为对象数组?
Apr 07, 2025 pm 09:36 PM
总结:将 Vue.js 字符串数组转换为对象数组有以下方法:基本方法:使用 map 函数,适合格式规整的数据。高级玩法:使用正则表达式,可处理复杂格式,但需谨慎编写,考虑性能。性能优化:考虑大数据量,可使用异步操作或高效数据处理库。最佳实践:清晰的代码风格,使用有意义的变量名、注释,保持代码简洁。
 偏远的高级后端工程师(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
偏远的高级后端工程师(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
远程高级后端工程师职位空缺公司:Circle地点:远程办公职位类型:全职薪资:$130,000-$140,000美元职位描述参与Circle移动应用和公共API相关功能的研究和开发,涵盖整个软件开发生命周期。主要职责独立完成基于RubyonRails的开发工作,并与React/Redux/Relay前端团队协作。为Web应用构建核心功能和改进,并在整个功能设计过程中与设计师和领导层紧密合作。推动积极的开发流程,并确定迭代速度的优先级。要求6年以上复杂Web应用后端
 Vue和Element-UI级联下拉框v-model绑定
Apr 07, 2025 pm 08:06 PM
Vue和Element-UI级联下拉框v-model绑定
Apr 07, 2025 pm 08:06 PM
Vue和Element-UI级联下拉框v-model绑定常见的坑点:v-model绑定的是一个代表级联选择框各级选中值的数组,而不是字符串;selectedOptions初始值必须为空数组,不可为null或undefined;动态加载数据需要使用异步编程技巧,处理好异步中的数据更新;针对庞大数据集,需要考虑使用虚拟滚动、懒加载等性能优化技术。
 如何设置Vue Axios的超时时间
Apr 07, 2025 pm 10:03 PM
如何设置Vue Axios的超时时间
Apr 07, 2025 pm 10:03 PM
为了设置 Vue Axios 的超时时间,我们可以创建 Axios 实例并指定超时选项:在全局设置中:Vue.prototype.$axios = axios.create({ timeout: 5000 });在单个请求中:this.$axios.get('/api/users', { timeout: 10000 })。
 Laravel的地理空间:互动图和大量数据的优化
Apr 08, 2025 pm 12:24 PM
Laravel的地理空间:互动图和大量数据的优化
Apr 08, 2025 pm 12:24 PM
利用地理空间技术高效处理700万条记录并创建交互式地图本文探讨如何使用Laravel和MySQL高效处理超过700万条记录,并将其转换为可交互的地图可视化。初始挑战项目需求:利用MySQL数据库中700万条记录,提取有价值的见解。许多人首先考虑编程语言,却忽略了数据库本身:它能否满足需求?是否需要数据迁移或结构调整?MySQL能否承受如此大的数据负载?初步分析:需要确定关键过滤器和属性。经过分析,发现仅少数属性与解决方案相关。我们验证了过滤器的可行性,并设置了一些限制来优化搜索。地图搜索基于城
 mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
文章介绍了MySQL数据库的上手操作。首先,需安装MySQL客户端,如MySQLWorkbench或命令行客户端。1.使用mysql-uroot-p命令连接服务器,并使用root账户密码登录;2.使用CREATEDATABASE创建数据库,USE选择数据库;3.使用CREATETABLE创建表,定义字段及数据类型;4.使用INSERTINTO插入数据,SELECT查询数据,UPDATE更新数据,DELETE删除数据。熟练掌握这些步骤,并学习处理常见问题和优化数据库性能,才能高效使用MySQL。
 mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
MySQL启动失败的原因有多种,可以通过检查错误日志进行诊断。常见原因包括端口冲突(检查端口占用情况并修改配置)、权限问题(检查服务运行用户权限)、配置文件错误(检查参数设置)、数据目录损坏(恢复数据或重建表空间)、InnoDB表空间问题(检查ibdata1文件)、插件加载失败(检查错误日志)。解决问题时应根据错误日志进行分析,找到问题的根源,并养成定期备份数据的习惯,以预防和解决问题。
