

视频分割大结局!浙大最新发布SAM-Track:通用智能视频分割一键直达

近期,浙江大学ReLER实验室将SAM与视频分割进行深度结合,发布Segment-and-Track Anything (SAM-Track)。
SAM-Track赋予了SAM对视频目标进行跟踪的能力,并支持多种方式(点、画笔、文字)进行交互。
在此基础上,SAM-Track统一了多个传统视频分割任务,达成了一键分割追踪任意视频中的任意目标,将传统视频分割外推至通用视频分割。
SAM-Track具有卓越的性能,在复杂场景下仅需单卡就能高质量地稳定跟踪数百个目标。

项目地址:https://github.com/z-x-yang/Segment-and-Track-Anything
论文地址:https://arxiv.org/abs/2305.06558
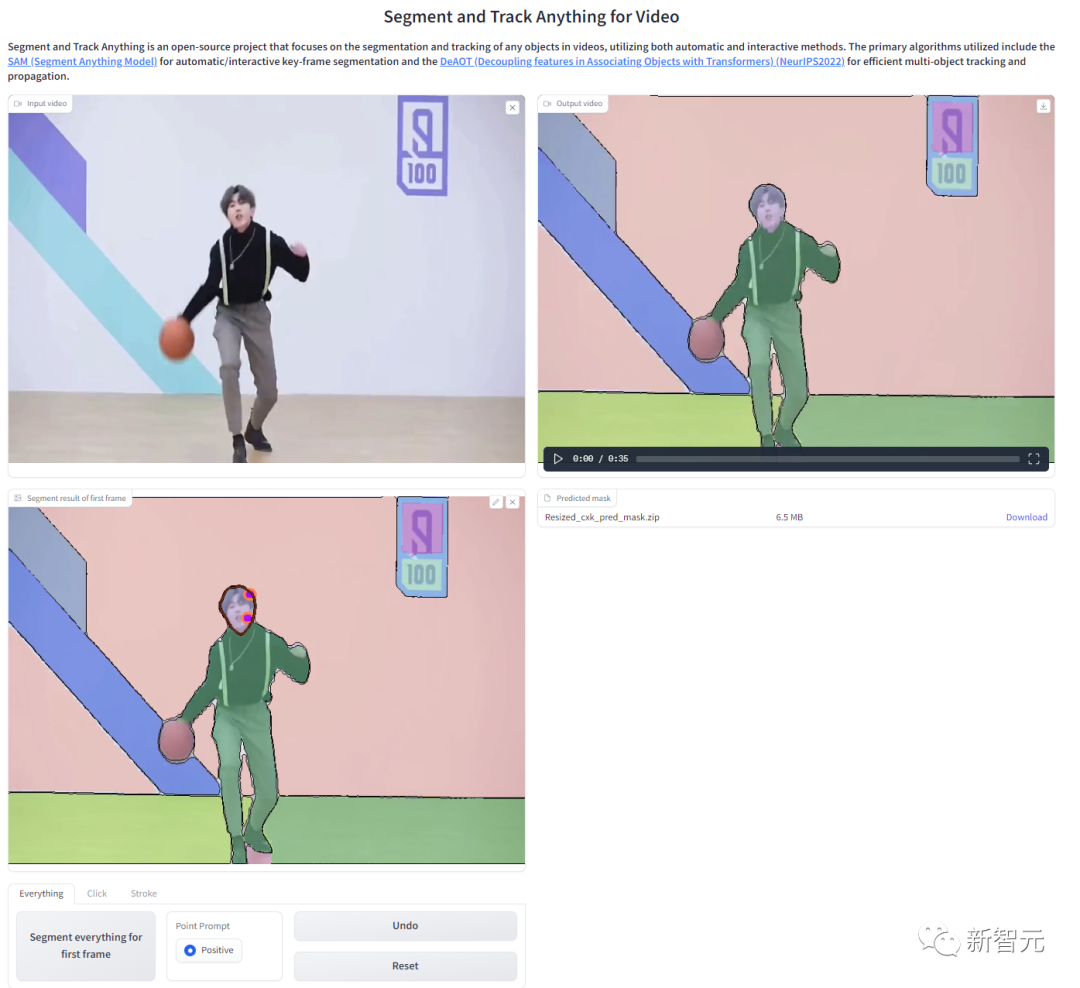
效果展示
SAM-Track支持语言输入作为Prompt。比如,给定类别文本「熊猫」,便可一键实例级分割追踪所有属于「熊猫」这一类别的目标。

也可进一步给出更详细的描述,比如输入文字「最左边的熊猫」,SAM-Track可以定位至特定目标进行分割追踪。

相较于传统视频追踪算法,SAM-Track的另一个强大之处在于可对大量目标同时进行跟踪分割,并自动检测新出现的物体。

SAM-Track还支持多种交互方式组合使用,用户可根据实际需求搭配。比如使用画笔来框定与人体紧密连接的滑板,防止分割多余物体,而后使用点击选择人体。
全自动视频目标分割与追踪自然也不在话下,各种应用场景包括街景、航拍、AR、动画、医学图像等,均可一键分割追踪并自动检测新出现的物体。

如果对自动分割结果不满意,用户可在此基础上进行编辑修正,例如使用点击来修正过分割的电车。

同时最新版本的SAM-Track支持对追踪结果进行在线浏览,可选择中间任意一帧的分割结果进行修改和新增目标,并再次追踪。

为了方便用户线上体验,项目提供了WebUI,可通过Colab一键部署:
模型组成
SAM-Track模型基于ECCV'22 VOT Workshop四个赛道的冠军方案DeAOT。
DeAOT是一个高效的多目标VOS模型,在给定首帧物体标注的情况下,可以对视频其余帧中的物体进行追踪分割。
DeAOT采用一种识别机制,将一个视频中的多个目标嵌入到同一高维空间中,从而实现了同时对多个物体进行追踪。
DeAOT在多物体追踪方面的速度表现能够与其他针对单个物体追踪的VOS方法相媲美。
此外,通过基于分层的Transformer的传播机制,DeAOT更好地聚合了长时序和短时序信息,表现出了优异的追踪性能。
由于DeAOT需要参考帧的标注来初始化,为了提高便捷性,SAM-Track使用了最近在图像分割领域大放异彩的Segment Anything Model(SAM)模型来获取标注信息。
利用SAM出色的零样本迁移能力,以及多种交互方式,SAM-Track能高效地为DeAOT获取高质量的参考帧标注信息。
虽然SAM模型在图像分割领域表现出色,但它无法输出语义标签,且文本提示也不能很好地支持Referring Object Segmentation及其他依赖深层语义理解的任务。
因此,SAM-Track模型进一步集成了Grounding-DINO,实现了高精度的语言引导的视频分割。Grounding DINO是一个开放集合目标检测模型,具有很好的语言理解能力。
根据输入的类别或目标对象的详细描述,Grounding-DINO可以检测到目标并返回位置框。
SAM-Track模型架构
如下图所示,SAM-Track模型支持了三种物体跟踪模式,分别为交互跟踪模式、自动跟踪模式以及融合模式。
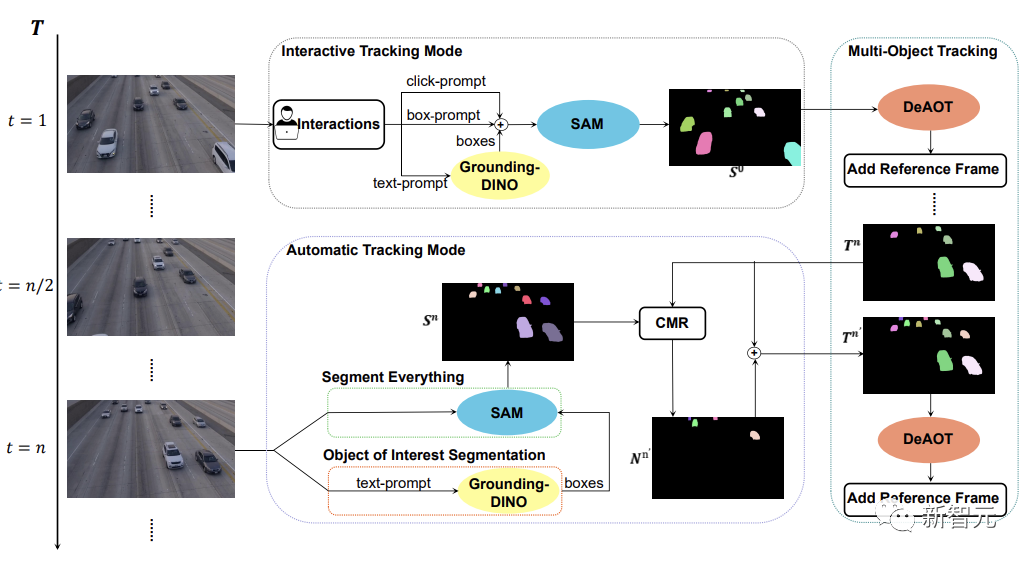
对于交互跟踪模式,SAM-Track模型首先会应用SAM,在参考帧中利用点击或画框的方式选中目标,直到得到用户满意的交互分割结果。
如果想要实现语言引导的视频物体分割,SAM-Track则会调用Grounding-DINO根据输入的文本,先得到目标物体的位置框,并在此基础上通过SAM得到感兴趣物体的分割结果。
最后DeAOT将交互分割结果作为参考帧,对选中的目标进行追踪。在追踪的过程中,DeAOT会将过去帧中的视觉嵌入和高维ID嵌入分层传播到当前帧中,实现逐帧追踪分割多个目标对象。因此,SAM-Track能过支持多模态的交互方式来追踪分割视频中的感兴趣物体。
然而,交互跟踪模式无法处理视频中出现的新出现的物体。限制了SAM-Track在特定领域的应用,例如,自动驾驶,智慧城市等。
为了进一步拓展SAM-Track的应用范围和性能,SAM-Track实现了自动跟踪模式,对视频中出现的新物体进行追踪。
自动跟踪模式通过Segment Everything和Object of Interest Segmentation两种方式来获得每n帧中新出现的物体的注释。对于新出现的物体的ID分配问题,SAM-Track采用了比较掩码模块(CMR)来确定新的对象的ID。
融合模式则是把交互跟踪模式和自动跟踪模式相结合。通过交互式跟踪模式用户可以很方便地获取视频中第一帧的注释,而自动跟踪模式则可以处理视频后续帧中出现的未被选中的新对象。追踪方法的组合扩大了SAM-Track的应用范围,增加了SAM-Track的实用性。
以上是视频分割大结局!浙大最新发布SAM-Track:通用智能视频分割一键直达的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 视频文件存储在浏览器缓存中的位置在哪里?
Feb 19, 2024 pm 05:09 PM
视频文件存储在浏览器缓存中的位置在哪里?
Feb 19, 2024 pm 05:09 PM
浏览器缓存视频在哪个文件夹在日常使用互联网浏览器时,我们经常会观看各种在线视频,比如在YouTube上看音乐视频或在Netflix上观看电影等。而这些视频在加载过程中会被浏览器缓存下来,以便日后再次播放时能够快速加载。那么问题来了,这些缓存的视频实际上存储在哪个文件夹中呢?不同浏览器的缓存视频文件夹保存位置是不同的。下面我们将分别介绍几种常见的浏览器以及它们
 抖音发布他人视频侵权吗?它怎样剪辑视频不算侵权?
Mar 21, 2024 pm 05:57 PM
抖音发布他人视频侵权吗?它怎样剪辑视频不算侵权?
Mar 21, 2024 pm 05:57 PM
随着短视频平台的兴起,抖音成为了大家日常生活中不可或缺的一部分。在抖音上,我们可以看到来自世界各地的有趣视频。有些人喜欢发布他人的视频,这就引发了一个问题:抖音发布他人视频侵权吗?本文将围绕这个问题展开讨论,告诉大家怎样剪辑视频不算侵权,以及如何避免侵权问题。一、抖音发布他人视频侵权吗?根据我国《著作权法》的规定,未经著作权人许可,擅自使用其作品,属于侵权行为。因此,在抖音上发布他人视频,如果未经原作者或著作权人许可,就属于侵权行为。二、怎样剪辑视频不算侵权?1.使用公共领域或已授权的内容:公共
 Wink如何去视频水印
Feb 23, 2024 pm 07:22 PM
Wink如何去视频水印
Feb 23, 2024 pm 07:22 PM
Wink如何去视频水印?winkAPP中是有去除掉视频水印的工具,但是多数的小伙伴不知道wink中如何去除掉视频中的水印,接下来就是小编为玩家带来的Wink视频去水印方法图文教程,感兴趣的用户快来一起看看吧!Wink如何去视频水印1、首先打开winkAPP,在首页面专区中选择【去水印】功能;2、然后在相册中选择你需要去除水印的视频;3、接着选择视频之后,剪辑视频之后点击右上角【√】;4、最后点击如下图所示的【一键去印】之后点击【处理】即可。
 抖音发布视频如何赚收益?新手小白怎么在抖音上赚钱啊?
Mar 21, 2024 pm 08:17 PM
抖音发布视频如何赚收益?新手小白怎么在抖音上赚钱啊?
Mar 21, 2024 pm 08:17 PM
抖音,这个全民短视频平台,不仅让我们在闲暇时间享受到各种有趣、新奇的短视频,同时也给了我们一个展示自我、实现价值的舞台。那么,如何在抖音发布视频赚取收益呢?本文将详细解答这个问题,帮助你在抖音上赚取更多的收益。一、抖音发布视频如何赚收益?发布视频在抖音上获得一定的播放量后,可以有机会参与广告分成计划。这一收益方式是抖音用户最为熟悉的之一,也是许多创作者主要的收入来源。抖音根据账号权重、视频内容以及观众反馈等多种因素来决定是否提供广告分成的机会。抖音平台允许观众通过发送礼物来支持自己喜欢的创作者,
 MobileSAM:为移动设备提供高性能的轻量级图像分割模型
Jan 05, 2024 pm 02:50 PM
MobileSAM:为移动设备提供高性能的轻量级图像分割模型
Jan 05, 2024 pm 02:50 PM
一、引言随着移动设备的普及和计算能力的提升,图像分割技术成为了研究的热点。MobileSAM(MobileSegmentAnythingModel)是一种针对移动设备优化的图像分割模型,旨在在保持高质量分割结果的同时,降低计算复杂度和内存占用,以便在资源有限的移动设备上高效运行。本文将详细介绍MobileSAM的原理、优势和应用场景。二、MobileSAM模型的设计思路MobileSAM模型的设计思路主要包括以下几个方面:轻量级模型:为了适应移动设备的资源限制,MobileSAM模型采用了轻量级
 从 iPhone 上的视频中删除慢动作的 2 种方法
Mar 04, 2024 am 10:46 AM
从 iPhone 上的视频中删除慢动作的 2 种方法
Mar 04, 2024 am 10:46 AM
在iOS设备上,“相机”应用程序允许您拍摄慢动作视频,如果您使用的是最新款的iPhone,甚至可以以每秒240帧的速度录制视频。这种功能让您能够捕捉到丰富细节的高速动作。但有时候,您可能希望将慢动作视频以正常速度播放,这样可以更好地欣赏视频中的细节和动作。在这篇文章中,我们将解释从iPhone上的现有视频中删除慢动作的所有方法。如何从iPhone上的视频中删除慢动作[2种方法]您可以使用“照片”App或iMovie剪辑App从设备上的视频中删除慢动作。方法1:使用“照片”应用在iPhone上打开
 微博发视频怎么不压缩画质_微博发视频不压缩画质方法
Mar 30, 2024 pm 12:26 PM
微博发视频怎么不压缩画质_微博发视频不压缩画质方法
Mar 30, 2024 pm 12:26 PM
1、首先打开手机微博,点击右下角【我】(如图所示)。2、接着点击右上角【齿轮】打开设置(如图所示)。3、然后找到并打开【通用设置】(如图所示)。4、随后进入【视频随着】选项(如图所示)。5、再打开【视频上传清晰度】设置(如图所示)。6、最后选择【原画质】就能不压缩了(如图所示)。
 如何发布小红书视频作品?发视频要注意什么?
Mar 23, 2024 pm 08:50 PM
如何发布小红书视频作品?发视频要注意什么?
Mar 23, 2024 pm 08:50 PM
随着短视频平台的兴起,小红书成为了许多人分享生活、表达自我、获取流量的平台。在这个平台上,发布视频作品是一种非常受欢迎的互动方式。那么,如何发布小红书视频作品呢?一、如何发布小红书视频作品?首先,确保准备好一段适合分享的视频内容。你可以利用手机或其他摄像设备进行拍摄,需要注意画质和声音的清晰度。2.剪辑视频:为了让作品更具吸引力,可以对视频进行剪辑。可以使用专业的视频剪辑软件,如抖音、快手等,添加滤镜、音乐、字幕等元素。3.选择封面:封面是吸引用户点击的关键,选择一张清晰、有趣的图片作为封面,让
