

模仿Jeff Dean神总结,前谷歌工程师分享「LLM开发秘籍」:每个开发者都应知道的数字!

最近,一位网友整理了一份「每个LLM开发者都应该知道的数字」,同时解释了这些数字为何重要,以及我们应该如何利用它们。
他在谷歌的时候,就有一份由传奇工程师Jeff Dean整理的文件,叫做「每个工程师都应该知道的数字」。

Jeff Dean:「每个工程师都应该知道的数字」
而对于LLM(Large Language Model)开发者来说,有一组类似的用于粗略估算的数字也是非常有用的。

Prompt
40-90%:在提示中添加「简明扼要」之后节省的成本
要知道,你是按照LLM在输出时用掉的token来付费的。
这意味着,让模型简明扼要(be concise)地进行表述,可以省下很多钱。
与此同时,这个理念还可以扩展到更多地方。
比如,你本来想用GPT-4生成10个备选方案,现在也许可以先要求它提供5个,就可以留下另一半的钱了。
1.3:每个词的平均token数
LLM是以token为单位进行操作的。
而token是单词或单词的子部分,比如「eating」可能被分解成两个token「eat」和「ing」。
一般来说,750个英文单词将产生大约1000个token。
对于英语以外的语言,每个词的token会有所增加,具体数量取决于它们在LLM的嵌入语料库中的通用性。

价格
考虑到LLM的使用成本很高,因此和价格相关的数字就变得尤为重要了。
~50:GPT-4与GPT-3.5 Turbo的成本比
使用GPT-3.5-Turbo大约比GPT-4便宜50倍。说「大约」是因为GPT-4对提示和生成的收费方式不同。
所以在实际应用时,最好确认一下GPT-3.5-Turbo是不是就足够完成你的需求。
例如,对于概括总结这样的任务,GPT-3.5-Turbo绰绰有余。


5:使用GPT-3.5-Turbo与OpenAI嵌入进行文本生成的成本比
这意味着在向量存储系统中查找某个内容比使用用LLM生成要便宜得多。
具体来说,在神经信息检索系统中查找,比向GPT-3.5-Turbo提问要少花约5倍的费用。与GPT-4相比,成本差距更是高达250倍!
10:OpenAI嵌入与自我托管嵌入的成本比
注意:这个数字对负载和嵌入的批大小非常敏感,因此请将其视为近似值。
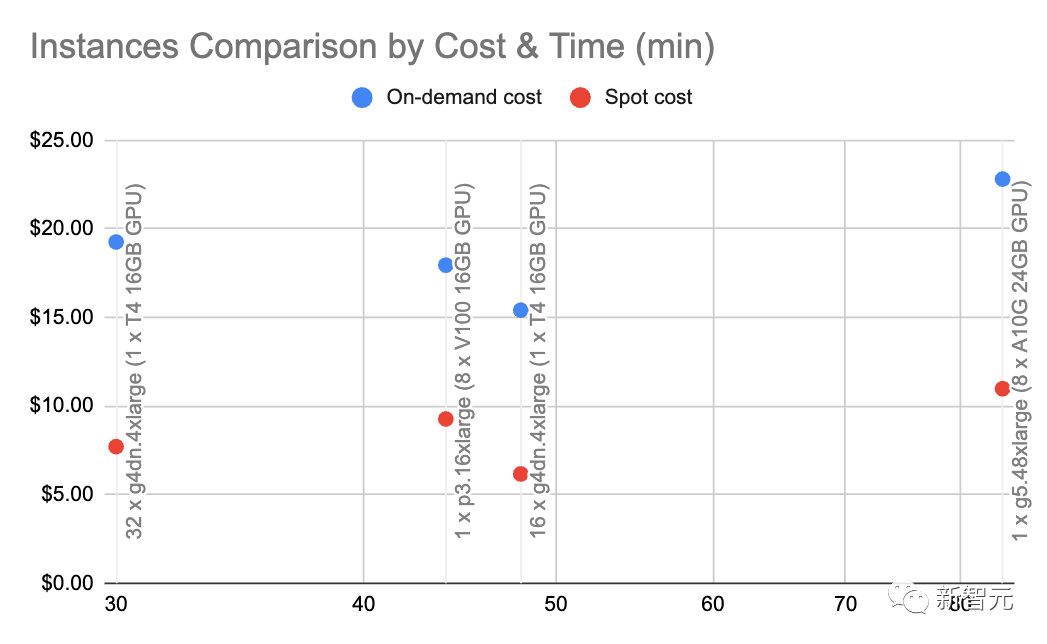
通过g4dn.4xlarge(按需价格:1.20美元/小时),我们可以利用用HuggingFace的SentenceTransformers(与OpenAI的嵌入相当)以每秒约9000个token的速度进行嵌入。
在这种速度和节点类型下进行一些基本的计算,表明自我托管的嵌入可以便宜10倍。
6:OpenAI基础模型与微调模型查询的成本比
在OpenAI上,微调模型的成本是基础模型的6倍。
这也意味着,相比微调定制模型,调整基础模型的提示更具成本效益。
1:自我托管基础模型与微调模型查询的成本比
如果你自己托管模型,那么微调模型和基础模型的成本几乎相同:这两种模型的参数数量是一样的。
训练和微调
~100万美元:在1.4万亿个token上训练130亿参数模型的成本
论文地址:https://arxiv.org/pdf/2302.13971.pdf
LLaMa的论文中提到,他们花了21天的时间,使用了2048个A100 80GB GPU,才训练出了LLaMa模型。
假设我们在Red Pajama训练集上训练自己的模型,假设一切正常,没有任何崩溃,并且第一次就成功,就会得到上述的数字。
此外,这个过程还涉及到2048个GPU之间的协调。
大多数公司,并没有条件做到这些。
不过,最关键的信息是:我们有可能训练出自己的LLM,只是这个过程并不便宜。
并且每次运行,都需要好几天时间。
相比之下,使用预训练模型,会便宜得多。
< 0.001:微调与从头开始训练的成本费率
这个数字有点笼统,总的来说,微调的成本可以忽略不计。
例如,你可以用大约7美元的价格,微调一个6B参数的模型。
即使按照OpenAI对其最昂贵的微调模型Davinci的费率,每1000个token也只要花费3美分。
这意味着,如果要微调莎士比亚的全部作品(大约100万个单词),只需要花费四五十美元。
不过,微调是一回事,从头开始训练,就是另一回事了......
GPU显存
如果您正在自托管模型,了解GPU显存就非常重要,因为LLM正在将GPU的显存推向极限。
以下统计信息专门用于推理。如果要进行训练或微调,就需要相当多的显存。
V100:16GB,A10G:24GB,A100:40/80GB:GPU显存容量
了解不同类型的GPU的显存量是很重要的,因为这将限制你的LLM可以拥有的参数量。
一般来说,我们喜欢使用A10G,因为它们在AWS上的按需价格是每小时1.5到2美元,并且用有24G的GPU显存,而每个A100的价格约为5美元/小时。
2x 参数量:LLM的典型GPU显存要求
举个例子,当你拥有一个70亿参数的模型时,就需要大约14GB的GPU显存。
这是因为大多数情况下,每个参数需要一个16位浮点数(或2个字节)。
通常不需要超过16位精度,但大多数时候,当精度达到8位时,分辨率就开始降低(在某些情况下,这也可以接受)。
当然,也有一些项目改善了这种情况。比如llama.cpp就通过在6GB GPU上量化到4位(8位也可以),跑通了130亿参数的模型,但这并不常见。
~1GB:嵌入模型的典型GPU显存要求
每当你嵌入语句(聚类、语义搜索和分类任务经常要做的事)时,你就需要一个像语句转换器这样的嵌入模型。OpenAI也有自己的商用嵌入模型。
通常不必担心GPU上的显存嵌入占用多少,它们相当小,甚至可以在同一GPU上嵌入LLM。
>10x:通过批处理LLM请求,提高吞吐量
通过GPU运行LLM查询的延迟非常高:吞吐量为每秒0.2个查询的话,延迟可能需要5秒。
有趣的是,如果你运行两个任务,延迟可能只需要5.2秒。
这意味着,如果能将25个查询捆绑在一起,则需要大约10秒的延迟,而吞吐量已提高到每秒2.5个查询。
不过,请接着往下看。
~1 MB:130亿参数模型输出1个token所需的GPU显存
你所需要的显存与你想生成的最大token数量直接成正比。
比如,生成最多512个token(大约380个单词)的输出,就需要512MB的显存。
你可能会说,这没什么大不了的——我有24GB的显存,512MB算什么?然而,如果你想运行更大的batch,这个数值就会开始累加了。
比如,如果你想做16个batch,显存就会直接增加到8GB。
以上是模仿Jeff Dean神总结,前谷歌工程师分享「LLM开发秘籍」:每个开发者都应知道的数字!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 2025年币圈十大虚拟币app交易所最新排行榜
Mar 27, 2025 pm 07:27 PM
2025年币圈十大虚拟币app交易所最新排行榜
Mar 27, 2025 pm 07:27 PM
2025年十大虚拟币交易App排行榜如下:1. OKX,2. Binance,3. Gate.io,4. Bybit,5. Kraken,6. KuCoin,7. Bitget,8. HTX,9. MEXC,10. Coinbase。该排行榜基于安全性、流动性、用户体验和功能丰富度等综合评测得出。
 十大数字虚拟货币交易所app榜单汇总2025年
Mar 27, 2025 pm 07:18 PM
十大数字虚拟货币交易所app榜单汇总2025年
Mar 27, 2025 pm 07:18 PM
2025年十大数字虚拟币交易App排行榜如下:1. OKX,2. Binance,3. Gate.io,4. Bybit,5. Kraken,6. KuCoin,7. Bitget,8. HTX,9. MEXC,10. Coinbase。该排行榜基于安全性、流动性、用户体验和功能丰富度等综合评测得出。
 哪些交易所发布pi消息
Mar 28, 2025 pm 03:33 PM
哪些交易所发布pi消息
Mar 28, 2025 pm 03:33 PM
Pi Network尚未在主流交易所正式上线交易。截至2024年,Pi仍处于封闭主网阶段,仅部分中小型交易所提供IOU交易,官方未授权任何交易,建议通过官方渠道挖矿并等待主网开放后在合规交易所交易。
 安全好用的虚拟币交易所平台top10
Mar 27, 2025 pm 07:06 PM
安全好用的虚拟币交易所平台top10
Mar 27, 2025 pm 07:06 PM
2025年十大虚拟币交易App排行榜如下:1. OKX,2. Binance,3. Gate.io,4. Bybit,5. Kraken,6. KuCoin,7. Bitget,8. HTX,9. MEXC,10. Coinbase。该排行榜基于安全性、流动性、用户体验和功能丰富度等综合评测得出。
 如何在Node.js环境中解决第三方接口返回403的问题?
Mar 31, 2025 pm 11:27 PM
如何在Node.js环境中解决第三方接口返回403的问题?
Mar 31, 2025 pm 11:27 PM
在Node.js环境中解决第三方接口返回403的问题当我们在使用Node.js调用第三方接口时,有时会遇到接口返回403错误�...
 哪些交易所支持heco
Mar 28, 2025 pm 03:36 PM
哪些交易所支持heco
Mar 28, 2025 pm 03:36 PM
截至2024年,仍支持Heco链或Heco代币的主要交易所有:1. HTX(原火币Huobi),官方支持Heco链USDT和代币交易;2. MDEX,基于Heco的DEX,支持Heco链代币交易;3. Gate.io,支持部分Heco链代币的充提;4. KuCoin,部分Heco链代币仍可交易;5. 去中心化交易所如PancakeSwap和Uniswap,需跨链交易,注意Heco链流动性低且项目迁移情况。

 如何在系统重启后自动设置unixsocket的权限?
Mar 31, 2025 pm 11:54 PM
如何在系统重启后自动设置unixsocket的权限?
Mar 31, 2025 pm 11:54 PM
如何在系统重启后自动设置unixsocket的权限每次系统重启后,我们都需要执行以下命令来修改unixsocket的权限:sudo...
