

Redis中使用Pipelining加速查询的问题怎么解决

Request/Response protocols and RTT
Redis是一个client-server模式的TCP服务,也被称为Request/Response协议的实现。

这意味着通常一个请求的完成是遵循下面两个步骤:
Client发送一个操作命令给Server,从TCP的套接字Socket中读取Server的响应值,通常来说这是一种阻塞的方式
Server执行操作命令,然后将响应值返回给Client
举个例子
Client: INCR X Server: 1 Client: INCR X Server: 2 Client: INCR X Server: 3 Client: INCR X Server: 4
Clients和Servers是通过网络进行连接。网络连接速度可能会快得很快(例如本地回环网络)或者慢得很慢(例如跨越多个主机的网络)。不管网络怎么样,一个数据包从Client到Server,然后相应值又从Server返回Client都需要一定的时间。
这个时间被称为RTT(Round Trip Time)。当一个Client需要执行多个连续请求(比如添加许多个元素到一个list中,或者清掉Redis中许多个键值对),那么RTT是怎样影响到性能的呢?这个也是很方便去计算的。比如如果RTT的时间为250ms(假设互联网连接速度非常慢),即使Server可以每秒处理100k个请求,那么最多也只能接受每秒4个请求。
如果是回环网络,RTT将会特别的短(比如作者的127.0.0.1,RTT的响应时间为44ms),但是对于执行连续多次写操作时,也是一笔不小的消耗。
其实我们有其他办法来降低这种场景的消耗,开心不?惊喜不?
Redis Pipelining
在一个Request/Response方式的服务中有一个特性:即使Client没有收到之前的响应值,也可以继续发送新的请求。这种特性意味着我们可以不需要等待Server的响应,可以率先发送许多操作命令给Server,然后在一次性读取Server的所有响应值。
这种方式被称为Pipelining技术,该技术近几十年来被广泛的使用。比如多POP3协议的实现就支持这个特性,大大的提升了从server端下载新的邮件的速度。
Redis在很早的时候就支持该项技术,所以不管你运行的是什么版本,你都可以使用pipelining技术,比如这里有一个使用 netcat 工具的:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379 +PONG +PONG +PONG
现在我们不需要为每一次请求付出RTT的消耗了,而是一次性发送三个操作命令。为了便于直观的理解,还是拿之前的说明,使用pipelining技术该的实现顺序如下:
Client: INCR X Client: INCR X Client: INCR X Client: INCR X Server: 1 Server: 2 Server: 3 Server: 4
划重点(敲黑板):当client使用pipelining发送操作命令时,server端将强制使用内存来排列响应结果。所以在使用pipelining发送大量的操作命令的时候,最好确定一个合理的命令条数,一批一批的发送给Server端,比如发送10k个操作命令,读取响应结果,再发送10k个操作命令,以此类推…虽然说耗时近乎相同,但是额外的内存消耗将是这10k操作命令的排列响应结果所需的最大值。(为防止内存耗尽,选择一个合理的值)
It’s not just a matter of RTT
Pipelining不是减少因为 RTT 造成消耗的唯一方式,但是它确实帮助你极大的提升每秒的执行命令数量。事实的真相是:从访问相应的数据结构并且生成答复结果的角度来看,不使用pipelining确实代价很低;但是从套接字socket I/O的角度来看,恰恰相反。因为这涉及到了read()和write()调用,需要从用户态切换到内核态。这种上下文切换会特别损耗时间的。
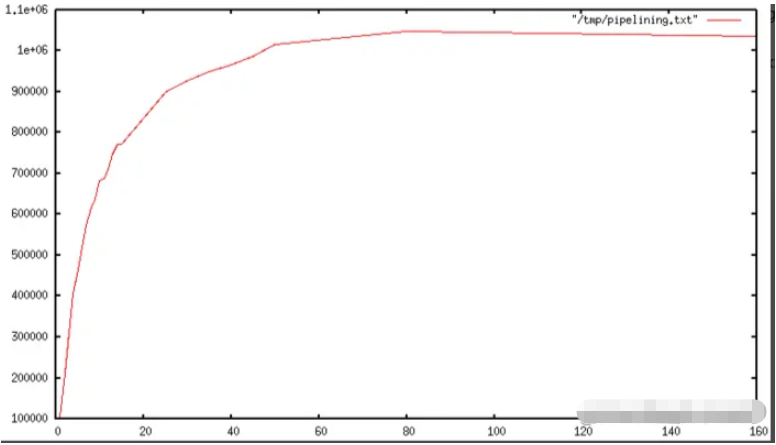
一旦使用了pipelining技术,很多操作命令将会从同一个read()调用中执行读操作,大量的答复结果将会被分发到同一个write()调用中执行写操作。基于此,随着管道的长度增加,每秒执行的查询数量最开始几乎呈直线型增加,直到不使用pipelining技术的基准的10倍,如下图:
Some real world code example
不翻译,基本上就是说使用了pipelining提升了5倍性能。
Pipelining VS Scripting
Redis Scripting(2.6+版本可用),通过使用在Server端完成大量工作的脚本Scripting,可以更加高效的解决大量pipelining用例。使用脚本Scripting的最大好处就是在读和写的时候消耗更少的性能,使得像读、写、计算这样的操作更加快速。(当client需要写操作之前获取读操作的响应结果时,pepelining就显得相形见拙。) 有时候,应用可能需要在使用pipelining时,发送 EVAL 或者 EVALSHA 命令,这是可行的,并且Redis明确支持这么这种SCRIPT LOAD命令。(它保证可可以调用 EVALSHA 而不会有失败的风险)。
Appendix: Why are busy loops slow even on the loopback interface?
读完全文,你可能还会感到疑问:为什么如下的Redis测试基准 benchmark 会执行这么慢,甚至在Client和Server在一个物理机上也是如此:
FOR-ONE-SECOND:
Redis.SET("foo","bar")
END毕竟Redis进程和测试基准benchmark在相同的机器上运行,并且这是没有任何实际的延迟和真实的网络参与,不就是消息通过内存从一个地方拷贝到另一个地方么? 原因是进程在操作系统中并不是一直运行。真实的情景是系统内核调度,调度到进程运行,它才会运行。比如测试基准benchmark被允许运行,从Redis Server中读取响应内容(与最后一次执行的命令相关),并且写了一个新的命令。这时命令将在回环网络的套接字中,但是为了被Redis Server读取,系统内核需要调度Redis Server进程(当前正在系统中挂起),周而复始。所以由于系统内核调度的机制,就算是在回环网络中,仍然会涉及到网络延迟。 简言之,在网络服务器中衡量性能时,使用回环网络测试并不是一个明智的方式。应该避免使用此种方式来测试基准。
以上是Redis中使用Pipelining加速查询的问题怎么解决的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
Redis集群模式通过分片将Redis实例部署到多个服务器,提高可扩展性和可用性。搭建步骤如下:创建奇数个Redis实例,端口不同;创建3个sentinel实例,监控Redis实例并进行故障转移;配置sentinel配置文件,添加监控Redis实例信息和故障转移设置;配置Redis实例配置文件,启用集群模式并指定集群信息文件路径;创建nodes.conf文件,包含各Redis实例的信息;启动集群,执行create命令创建集群并指定副本数量;登录集群执行CLUSTER INFO命令验证集群状态;使
 redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
如何清空 Redis 数据:使用 FLUSHALL 命令清除所有键值。使用 FLUSHDB 命令清除当前选定数据库的键值。使用 SELECT 切换数据库,再使用 FLUSHDB 清除多个数据库。使用 DEL 命令删除特定键。使用 redis-cli 工具清空数据。
 redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
要从 Redis 读取队列,需要获取队列名称、使用 LPOP 命令读取元素,并处理空队列。具体步骤如下:获取队列名称:以 "queue:" 前缀命名,如 "queue:my-queue"。使用 LPOP 命令:从队列头部弹出元素并返回其值,如 LPOP queue:my-queue。处理空队列:如果队列为空,LPOP 返回 nil,可先检查队列是否存在再读取元素。
 redis怎么使用锁
Apr 10, 2025 pm 08:39 PM
redis怎么使用锁
Apr 10, 2025 pm 08:39 PM
使用Redis进行锁操作需要通过SETNX命令获取锁,然后使用EXPIRE命令设置过期时间。具体步骤为:(1) 使用SETNX命令尝试设置一个键值对;(2) 使用EXPIRE命令为锁设置过期时间;(3) 当不再需要锁时,使用DEL命令删除该锁。
 redis指令怎么用
Apr 10, 2025 pm 08:45 PM
redis指令怎么用
Apr 10, 2025 pm 08:45 PM
使用 Redis 指令需要以下步骤:打开 Redis 客户端。输入指令(动词 键 值)。提供所需参数(因指令而异)。按 Enter 执行指令。Redis 返回响应,指示操作结果(通常为 OK 或 -ERR)。
 redis怎么读源码
Apr 10, 2025 pm 08:27 PM
redis怎么读源码
Apr 10, 2025 pm 08:27 PM
理解 Redis 源码的最佳方法是逐步进行:熟悉 Redis 基础知识。选择一个特定的模块或功能作为起点。从模块或功能的入口点开始,逐行查看代码。通过函数调用链查看代码。熟悉 Redis 使用的底层数据结构。识别 Redis 使用的算法。
 redis怎么解决数据丢失
Apr 10, 2025 pm 08:24 PM
redis怎么解决数据丢失
Apr 10, 2025 pm 08:24 PM
Redis 数据丢失的原因包括内存故障、停电、人为错误和硬件故障。解决方案为:1. 通过 RDB 或 AOF 持久化将数据存储到磁盘;2. 复制到多台服务器实现高可用性;3. 使用 Redis Sentinel 或 Redis Cluster 进行 HA;4. 创建快照以备份数据;5. 实施最佳实践,如持久化、复制、快照、监控和安全措施。
 redis命令行怎么用
Apr 10, 2025 pm 10:18 PM
redis命令行怎么用
Apr 10, 2025 pm 10:18 PM
使用 Redis 命令行工具 (redis-cli) 可通过以下步骤管理和操作 Redis:连接到服务器,指定地址和端口。使用命令名称和参数向服务器发送命令。使用 HELP 命令查看特定命令的帮助信息。使用 QUIT 命令退出命令行工具。
