

MySQL使用ReplicationConnection导致连接失效怎么解决

引言
MySQL数据库读写分离,是提高服务质量的常用手段之一,而对于技术方案,有很多成熟开源框架或方案,例如:sharding-jdbc、spring中的AbstractRoutingDatasource、MySQL-Router等,而mysql-jdbc中的ReplicationConnection亦可支持。
本文暂不对读写分离的技术选型做过多的分析,只是探索在使用druid作为数据源、结合ReplicationConnection做读写分离时,连接失效的原因,并找到一个简单有效的解决方案。
问题背景
由于历史原因,某几个服务出现连接失效异常,关键报错如下:

根据日志可以推断出,这是因为该连接长时间未与MySQL服务端进行交互,导致服务端关闭了连接,典型的连接失效情况。
涉及的主要配置
jdbc配置
jdbc:mysql:replication://master_host:port,slave_host:port/database_name
druid配置
testWhileIdle=true(即,开启了空闲连接检查);
timeBetweenEvictionRunsMillis=6000L(即,对于获取连接的场景,如果某连接空闲时间超过1分钟,将会进行检查,如果连接无效,将抛弃后重新获取)。
附:DruidDataSource.getConnectionDirect中
处理逻辑如下:
if (testWhileIdle) {
final DruidConnectionHolder holder = poolableConnection.holder;
long currentTimeMillis = System.currentTimeMillis();
long lastActiveTimeMillis = holder.lastActiveTimeMillis;
long lastExecTimeMillis = holder.lastExecTimeMillis;
long lastKeepTimeMillis = holder.lastKeepTimeMillis;
if (checkExecuteTime
&& lastExecTimeMillis != lastActiveTimeMillis) {
lastActiveTimeMillis = lastExecTimeMillis;
}
if (lastKeepTimeMillis > lastActiveTimeMillis) {
lastActiveTimeMillis = lastKeepTimeMillis;
}
long idleMillis = currentTimeMillis - lastActiveTimeMillis;
long timeBetweenEvictionRunsMillis = this.timeBetweenEvictionRunsMillis;
if (timeBetweenEvictionRunsMillis <= 0) {
timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS;
}
if (idleMillis >= timeBetweenEvictionRunsMillis
|| idleMillis < 0 // unexcepted branch
) {
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validate) {
if (LOG.isDebugEnabled()) {
LOG.debug("skip not validate connection.");
}
discardConnection(poolableConnection.holder);
continue;
}
}
}mysql超时参数配置wait_timeout=3600(3600秒,即:如果某连接超过一个小时和服务端没有交互,该连接将会被服务端kill)。 显而易见,基于如上配置,按照常规理解,不应该出现“The last packet successfully received from server was xxx,xxx,xxx milliseconds ago”的问题。(当然,当时也排除了人工介入kill掉数据库连接的可能)。
当“理所应当”的经验解释不了问题所在,往往需要跳出可能浮于表面经验束缚,来一次追根究底。那么,该问题的真正原因是什么呢?
本质原因
当使用druid管理数据源,结合mysql-jdbc中原生的ReplicationConnection做读写分离时,ReplicationConnection代理对象中实际存在master和slaves两套连接,druid在做连接检测时候,只能检测到其中的master连接,如果某个slave连接长时间未使用,会导致连接失效问题。
原因分析
mysql-jdbc中,数据库驱动对连接的处理过程
结合com.mysql.jdbc.Driver源码,不难看出mysql-jdbc中获取连接的主体流程如下:

对于以“jdbc:mysql:replication://”开头配置的jdbc-url,通过mysql-jdbc获取到的连接,其实是一个ReplicationConnection的代理对象,默认情况下,“jdbc:mysql:replication://”后的第一个host和port对应master连接,其后的host和port对应slaves连接,而对于存在多个slave配置的场景,默认使用随机策略进行负载均衡。
ReplicationConnection代理对象,使用JDK动态代理生成的,其中InvocationHandler的具体实现,是ReplicationConnectionProxy,关键代码如下:
public static ReplicationConnection createProxyInstance(List<String> masterHostList, Properties masterProperties, List<String> slaveHostList,
Properties slaveProperties) throws SQLException {
ReplicationConnectionProxy connProxy = new ReplicationConnectionProxy(masterHostList, masterProperties, slaveHostList, slaveProperties);
return (ReplicationConnection) java.lang.reflect.Proxy.newProxyInstance(ReplicationConnection.class.getClassLoader(), INTERFACES_TO_PROXY, connProxy);
}ReplicationConnectionProxy的重要组成
关于数据库连接代理,ReplicationConnectionProxy中的主要组成如下图:
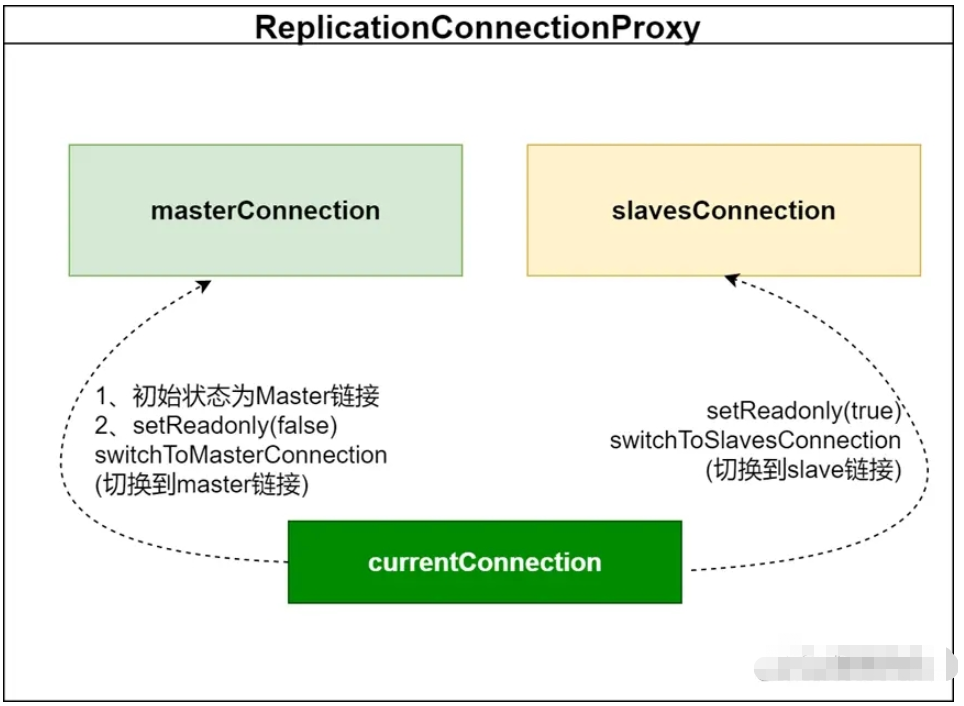
ReplicationConnectionProxy存在masterConnection和slavesConnection两个实际连接对象,currentConnetion(当前连接)可以切换成mastetConnection或者slavesConnection,切换方式可以通过设置readOnly实现。
业务逻辑中,实现读写分离的核心也在于此,简单来说:使用ReplicationConnection做读写分离时,只要做一个“设置connection的readOnly属性的”aop即可。
基于ReplicationConnectionProxy,业务逻辑中获取到的Connection代理对象,数据库访问时的主要逻辑是什么样的呢?
ReplicationConnection代理对象处理过程
对于业务逻辑而言,获取到的Connection实例,是ReplicationConnection代理对象,该代理对象通过ReplicationConnectionProxy和ReplicationMySQLConnection相互协同完成对数据库访问的处理,其中ReplicationConnectionProxy在实现 InvocationHandler的同时,还充当对连接管理的角色,核心逻辑如下图:
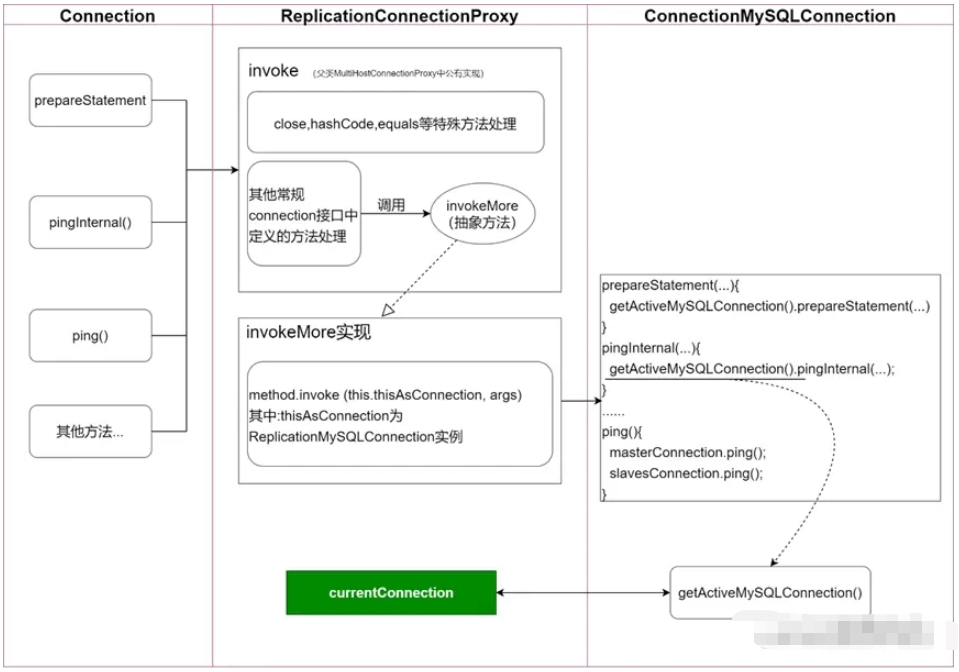
对于prepareStatement等常规逻辑,ConnectionMySQConnection获取到当前连接进行处理(普通的读写分离的处理的重点正是在此);此时,重点提及pingInternal方法,其处理方式也是获取当前连接,然后执行pingInternal逻辑。
对于ping()这个特殊逻辑,图中描述相对简单,但主体含义不变,即:对master连接和sleves连接都要进行ping()的处理。
图中,pingInternal流程和druid的MySQ连接检查有关,而ping的特殊处理,也正是解决问题的关键。
druid数据源对MySQ连接的检查
druid中对MySQL连接检查的默认实现类是MySqlValidConnectionChecker,其中核心逻辑如下:
public boolean isValidConnection(Connection conn, String validateQuery, int validationQueryTimeout) throws Exception {
if (conn.isClosed()) {
return false;
}
if (usePingMethod) {
if (conn instanceof DruidPooledConnection) {
conn = ((DruidPooledConnection) conn).getConnection();
}
if (conn instanceof ConnectionProxy) {
conn = ((ConnectionProxy) conn).getRawObject();
}
if (clazz.isAssignableFrom(conn.getClass())) {
if (validationQueryTimeout <= 0) {
validationQueryTimeout = DEFAULT_VALIDATION_QUERY_TIMEOUT;
}
try {
ping.invoke(conn, true, validationQueryTimeout * 1000);
} catch (InvocationTargetException e) {
Throwable cause = e.getCause();
if (cause instanceof SQLException) {
throw (SQLException) cause;
}
throw e;
}
return true;
}
}
String query = validateQuery;
if (validateQuery == null || validateQuery.isEmpty()) {
query = DEFAULT_VALIDATION_QUERY;
}
Statement stmt = null;
ResultSet rs = null;
try {
stmt = conn.createStatement();
if (validationQueryTimeout > 0) {
stmt.setQueryTimeout(validationQueryTimeout);
}
rs = stmt.executeQuery(query);
return true;
} finally {
JdbcUtils.close(rs);
JdbcUtils.close(stmt);
}
}对应服务中使用的mysql-jdbc(5.1.45版),在未设置“druid.mysql.usePingMethod”系统属性的情况下,默认usePingMethod为true,如下:
public MySqlValidConnectionChecker(){
try {
clazz = Utils.loadClass("com.mysql.jdbc.MySQLConnection");
if (clazz == null) {
clazz = Utils.loadClass("com.mysql.cj.jdbc.ConnectionImpl");
}
if (clazz != null) {
ping = clazz.getMethod("pingInternal", boolean.class, int.class);
}
if (ping != null) {
usePingMethod = true;
}
} catch (Exception e) {
LOG.warn("Cannot resolve com.mysql.jdbc.Connection.ping method. Will use 'SELECT 1' instead.", e);
}
configFromProperties(System.getProperties());
}
@Override
public void configFromProperties(Properties properties) {
String property = properties.getProperty("druid.mysql.usePingMethod");
if ("true".equals(property)) {
setUsePingMethod(true);
} else if ("false".equals(property)) {
setUsePingMethod(false);
}
}同时,可以看出MySqlValidConnectionChecker中的ping方法使用的是MySQLConnection中的pingInternal方法,而该方法,结合上面对ReplicationConnection的分析,当调用pingInternal时,只是对当前连接进行检验。执行检验连接的时机是通过DrduiDatasource获取连接时,此时未设置readOnly属性,检查的连接,其实只是ReplicationConnectionProxy中的master连接。
此外,如果通过“druid.mysql.usePingMethod”属性设置usePingMeghod为false,其实也会导致连接失效的问题,因为:当通过valideQuery(例如“select 1”)进行连接校验时,会走到ReplicationConnection中的普通查询逻辑,此时对应的连接依然是master连接。
题外一问:ping方法为什么使用“pingInternal”,而不是常规的ping?
原因:pingInternal预留了超时时间等控制参数。
解决方式
调整依赖版本
在服务中,使用的MySQL JDBC版本是5.1.45,并且使用的Druid版本是1.1.20。经过对其他高版本依赖的了解,依然存在该问题。
修改读写分离实现
修改的工作量主要在于数据源配置和aop调整,但需要一定的整体回归验证成本,鉴于涉及该问题的服务重要性一般,暂不做大调整。
拓展mysql-jdbc驱动
基于原有ReplicationConnection的功能,拓展pingInternal调整为普通的ping,集成原有Driver拓展新的Driver。方案可行,但修改成本不算小。
基于druid,拓展MySQL连接检查
为简单高效解决问题,选择拓展MySqlValidConnectionChecker,并在druid数据源中加上对应配置即可。拓展如下:
public class MySqlReplicationCompatibleValidConnectionChecker extends MySqlValidConnectionChecker {
private static final Log LOG = LogFactory.getLog(MySqlValidConnectionChecker.class);
/**
*
*/
private static final long serialVersionUID = 1L;
@Override
public boolean isValidConnection(Connection conn, String validateQuery, int validationQueryTimeout) throws Exception {
if (conn.isClosed()) {
return false;
}
if (conn instanceof DruidPooledConnection) {
conn = ((DruidPooledConnection) conn).getConnection();
}
if (conn instanceof ConnectionProxy) {
conn = ((ConnectionProxy) conn).getRawObject();
}
if (conn instanceof ReplicationConnection) {
try {
((ReplicationConnection) conn).ping();
LOG.info("validate connection success: connection=" + conn.toString());
return true;
} catch (SQLException e) {
LOG.error("validate connection error: connection=" + conn.toString(), e);
throw e;
}
}
return super.isValidConnection(conn, validateQuery, validationQueryTimeout);
}
}ReplicatoinConnection.ping()的实现逻辑中,会对所有master和slaves连接进行ping操作,最终每个ping操作都会调用到LoadBalancedConnectionProxy.doPing进行处理,而此处,可在数据库配置url中设置loadBalancePingTimeout属性设置超时时间。
以上是MySQL使用ReplicationConnection导致连接失效怎么解决的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 MySQL:世界上最受欢迎的数据库的简介
Apr 12, 2025 am 12:18 AM
MySQL:世界上最受欢迎的数据库的简介
Apr 12, 2025 am 12:18 AM
MySQL是一种开源的关系型数据库管理系统,主要用于快速、可靠地存储和检索数据。其工作原理包括客户端请求、查询解析、执行查询和返回结果。使用示例包括创建表、插入和查询数据,以及高级功能如JOIN操作。常见错误涉及SQL语法、数据类型和权限问题,优化建议包括使用索引、优化查询和分表分区。
 MySQL的位置:数据库和编程
Apr 13, 2025 am 12:18 AM
MySQL的位置:数据库和编程
Apr 13, 2025 am 12:18 AM
MySQL在数据库和编程中的地位非常重要,它是一个开源的关系型数据库管理系统,广泛应用于各种应用场景。1)MySQL提供高效的数据存储、组织和检索功能,支持Web、移动和企业级系统。2)它使用客户端-服务器架构,支持多种存储引擎和索引优化。3)基本用法包括创建表和插入数据,高级用法涉及多表JOIN和复杂查询。4)常见问题如SQL语法错误和性能问题可以通过EXPLAIN命令和慢查询日志调试。5)性能优化方法包括合理使用索引、优化查询和使用缓存,最佳实践包括使用事务和PreparedStatemen
 为什么要使用mysql?利益和优势
Apr 12, 2025 am 12:17 AM
为什么要使用mysql?利益和优势
Apr 12, 2025 am 12:17 AM
选择MySQL的原因是其性能、可靠性、易用性和社区支持。1.MySQL提供高效的数据存储和检索功能,支持多种数据类型和高级查询操作。2.采用客户端-服务器架构和多种存储引擎,支持事务和查询优化。3.易于使用,支持多种操作系统和编程语言。4.拥有强大的社区支持,提供丰富的资源和解决方案。
 apache怎么连接数据库
Apr 13, 2025 pm 01:03 PM
apache怎么连接数据库
Apr 13, 2025 pm 01:03 PM
Apache 连接数据库需要以下步骤:安装数据库驱动程序。配置 web.xml 文件以创建连接池。创建 JDBC 数据源,指定连接设置。从 Java 代码中使用 JDBC API 访问数据库,包括获取连接、创建语句、绑定参数、执行查询或更新以及处理结果。
 docker怎么启动mysql
Apr 15, 2025 pm 12:09 PM
docker怎么启动mysql
Apr 15, 2025 pm 12:09 PM
在 Docker 中启动 MySQL 的过程包含以下步骤:拉取 MySQL 镜像创建并启动容器,设置根用户密码并映射端口验证连接创建数据库和用户授予对数据库的所有权限
 MySQL的角色:Web应用程序中的数据库
Apr 17, 2025 am 12:23 AM
MySQL的角色:Web应用程序中的数据库
Apr 17, 2025 am 12:23 AM
MySQL在Web应用中的主要作用是存储和管理数据。1.MySQL高效处理用户信息、产品目录和交易记录等数据。2.通过SQL查询,开发者能从数据库提取信息生成动态内容。3.MySQL基于客户端-服务器模型工作,确保查询速度可接受。
 laravel入门实例
Apr 18, 2025 pm 12:45 PM
laravel入门实例
Apr 18, 2025 pm 12:45 PM
Laravel 是一款 PHP 框架,用于轻松构建 Web 应用程序。它提供一系列强大的功能,包括:安装: 使用 Composer 全局安装 Laravel CLI,并在项目目录中创建应用程序。路由: 在 routes/web.php 中定义 URL 和处理函数之间的关系。视图: 在 resources/views 中创建视图以呈现应用程序的界面。数据库集成: 提供与 MySQL 等数据库的开箱即用集成,并使用迁移来创建和修改表。模型和控制器: 模型表示数据库实体,控制器处理 HTTP 请求。
 centos7如何安装mysql
Apr 14, 2025 pm 08:30 PM
centos7如何安装mysql
Apr 14, 2025 pm 08:30 PM
优雅安装 MySQL 的关键在于添加 MySQL 官方仓库。具体步骤如下:下载 MySQL 官方 GPG 密钥,防止钓鱼攻击。添加 MySQL 仓库文件:rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm更新 yum 仓库缓存:yum update安装 MySQL:yum install mysql-server启动 MySQL 服务:systemctl start mysqld设置开机自启动
