

多路径多领域通吃!谷歌AI发布多领域学习通用模型MDL

面向视觉任务(如图像分类)的深度学习模型,通常用来自单一视觉域(如自然图像或计算机生成的图像)的数据进行端到端的训练。
一般情况下,一个为多个领域完成视觉任务的应用程序需要为每个单独的领域建立多个模型,分别独立训练,不同领域之间不共享数据,在推理时,每个模型将处理特定领域的输入数据。
即使是面向不同领域,这些模型之间的早期层的有些特征都是相似的,所以,对这些模型进行联合训练的效率更高。这能减少延迟和功耗,降低存储每个模型参数的内存成本,这种方法被称为多领域学习(MDL)。
此外,MDL模型也可以优于单领域模型,在一个域上的额外训练,可以提高模型在另一个域上的性能,这称为「正向知识迁移」,但也可能产生负向知识转移,这取决于训练方法和具体的领域组合。 虽然以前关于MDL的工作已经证明了跨领域联合学习任务的有效性,但它涉及到一个手工制作的模型架构,应用于其他工作的效率很低。

论文链接:https://arxiv.org/pdf/2010.04904.pdf
为了解决这个问题,在「Multi-path Neural Networks for On-device Multi-domain Visual Classification」一文中,谷歌研究人员提出了一个通用MDL模型。
文章表示,该模型既可以有效地实现高精确度,减少负向知识迁移的同时,学习增强正向的知识迁移,在处理各种特定领域的困难时,可以有效地优化联合模型。
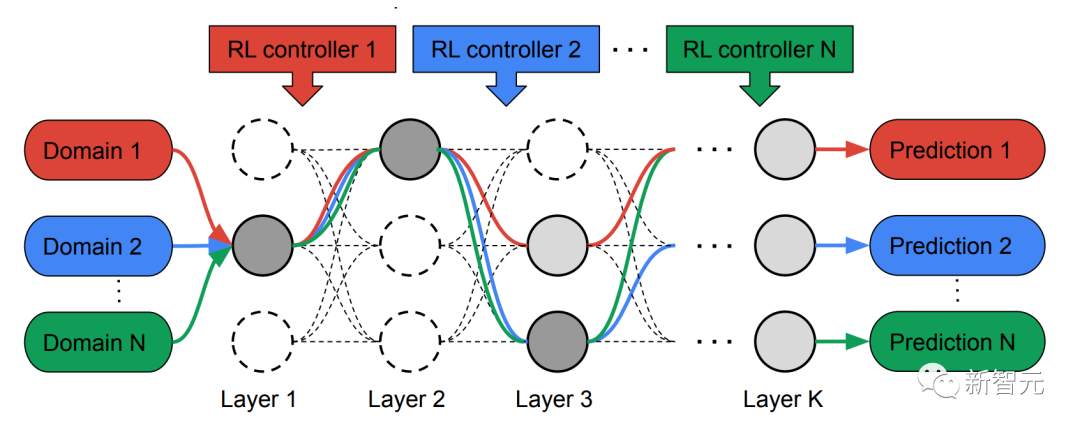
为此,研究人员提出了一种多路径神经架构搜索(MPNAS)方法,为多领域建立一个具有异质网络架构的统一模型。
该方法将高效的神经结构搜索(NAS)方法从单路径搜索扩展到多路径搜索,为每个领域联合寻找一条最优路径。同时引入一个新的损失函数,称为自适应平衡域优先化(ABDP),它适应特定领域的困难,以帮助有效地训练模型。由此产生的MPNAS方法是高效和可扩展的。
新模型在保持性能不下降的同时,与单领域方法相比,模型大小和FLOPS分别减少了78%和32%。
多路径神经结构搜索
为了促进正向知识迁移,避免负向迁移,传统的解决方案是,建立一个MDL模型,使各域共享大部分的层,学习各域的共享特征(称为特征提取),然后在上面建一些特定域的层。 然而,这种特征提取方法无法处理具有明显不同特征的域(如自然图像中的物体和艺术绘画)。另一方面,为每个MDL模型建立统一的异质结构是很耗时的,而且需要特定领域的知识。
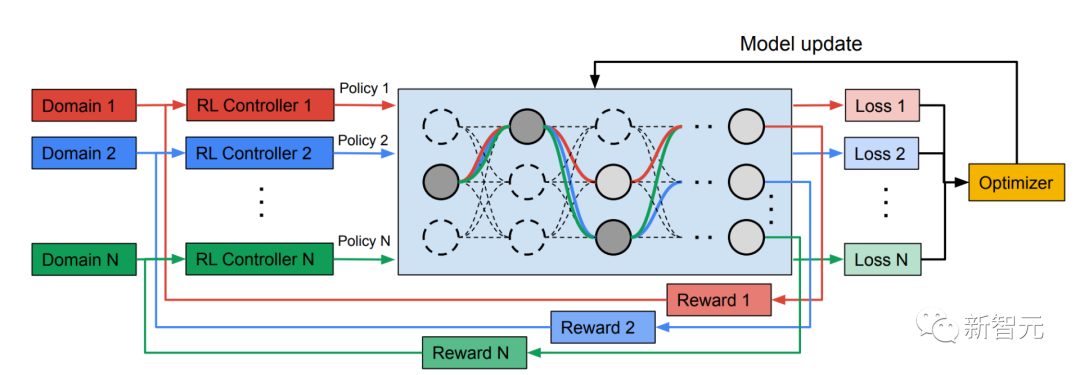
多路径神经搜索架构框架 NAS是一个自动设计深度学习架构的强大范式。它定义了一个搜索空间,由可能成为最终模型一部分的各种潜在构建块组成。
搜索算法从搜索空间中找到最佳的候选架构,以优化模型目标,例如分类精度。最近的NAS方法(如TuNAS)通过使用端到端的路径采样,提高了搜索效率。
受TuNAS的启发,MPNAS在两个阶段建立了MDL模型架构:搜索和训练。
在搜索阶段,为了给每个领域共同找到一条最佳路径,MPNAS为每个领域创建了一个单独的强化学习(RL)控制器,它从超级网络(即由搜索空间定义的候选节点之间所有可能的子网络的超集)中采样端到端的路径(从输入层到输出层)。
在多次迭代中,所有RL控制器更新路径,以优化所有领域的RL奖励。在搜索阶段结束时,我们为每个领域获得一个子网络。 最后,所有的子网络被结合起来,为MDL模型建立一个异质结构,如下图所示。
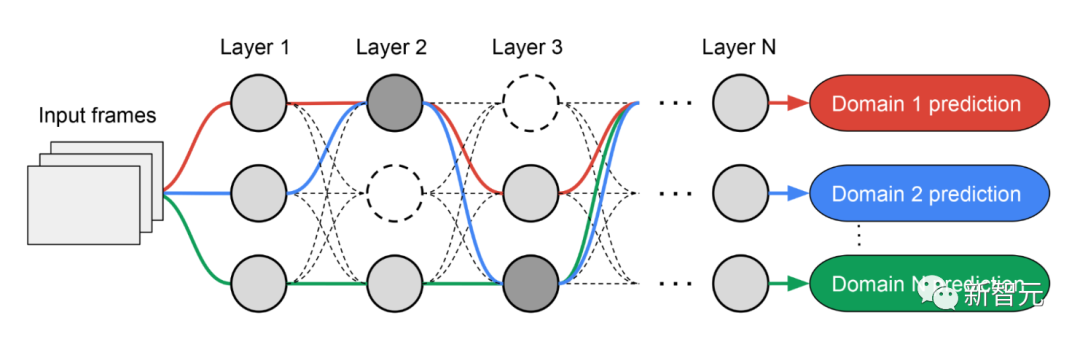
由于每个域的子网络是独立搜索的,所以每一层的构件可以被多个域共享(即深灰色节点),被单个域使用(即浅灰色节点),或者不被任何子网络使用(即点状节点)。
每个域的路径在搜索过程中也可以跳过任何一层。鉴于子网络可以以优化性能的方式自由选择沿路使用的区块,输出网络既是异质的又是高效的。
下图展示了Visual Domain Decathlon的其中两个领域的搜索架构。
Visual Domain Decathlon是CVPR 2017中的PASCAL in Detail Workshop Challenge的一部分,测试了视觉识别算法处理(或利用)许多不同视觉领域的能力。 可以看出,这两个高度相关的域(一个红色,另一个绿色)的子网,从它们的重叠路径中共享了大部分构建块,但它们之间仍然存在差异。
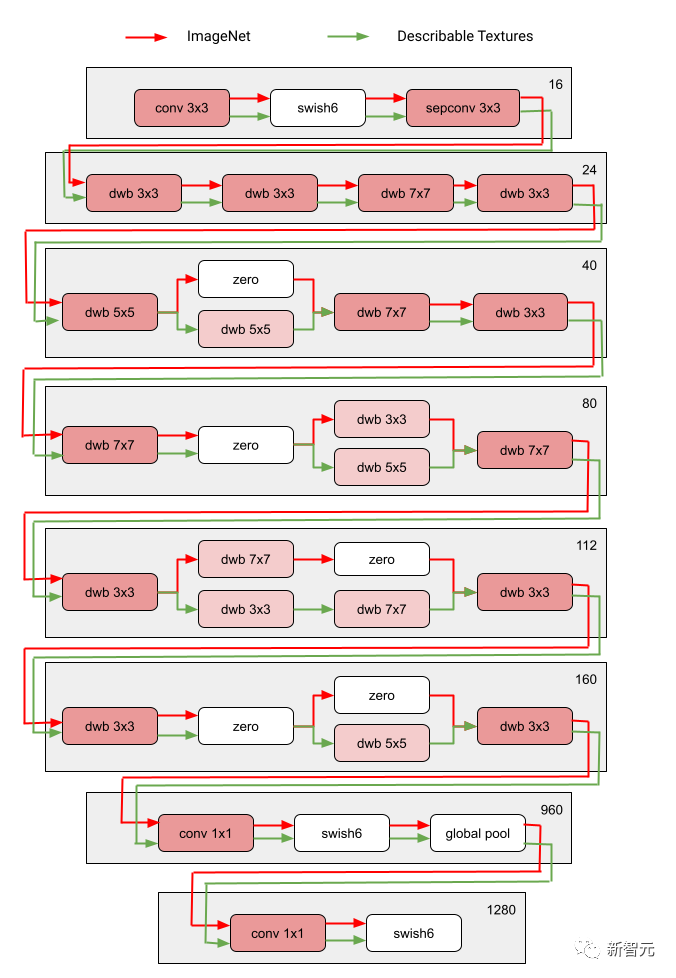
图中红色和绿色路径分别代表 ImageNet 和Describable Textures的子网络,深粉色节点代表多个域共享的块,浅粉色节点代表每条路径使用的块。图中的“dwb”块代表 dwbottleneck 块。图中的Zero块表示子网跳过该块 下图展示了上文提到的两个领域的路径相似性。 相似度通过每个域的子网之间的Jaccard相似度得分来衡量,其中越高意味着路径越相似。

图为十个域的路径之间的Jaccard相似度得分的混淆矩阵。分值范围为0到1,分值越大表示两条路径共享的节点越多。
训练异构多域模型
在第二阶段,MPNAS 产生的模型将针对所有领域从头开始训练。 为此,有必要为所有领域定义一个统一的目标函数。 为了成功处理各种各样的领域,研究人员设计了一种算法,该算法在整个学习过程中进行调整,以便在各个领域之间平衡损失,称为自适应平衡领域优先级 (ABDP)。 下面展示了在不同设置下训练的模型的准确率、模型大小和FLOPS。我们将MPNAS与其他三种方法进行比较:
独立于域的 NAS:分别为每个域搜索和训练模型。
单路径多头:使用预训练模型作为所有域的共享主干,每个域都有单独的分类头。
多头 NAS:为所有域搜索统一的骨干架构,每个域都有单独的分类头。
从结果中,我们可以观察到NAS需要为每个域构建一组模型,从而导致模型很大。 尽管单路径多头和多头NAS可以显着降低模型大小和FLOPS,但强制域共享相同的主干会引入负面的知识转移,从而降低整体准确性。

相比之下,MPNAS可以构建小而高效的模型,同时仍保持较高的整体精度。 MPNAS的平均准确率甚至比领域独立的NAS方法高1.9%,因为该模型能够实现积极的知识转移。 下图比较了这些方法的每个域top-1准确度。
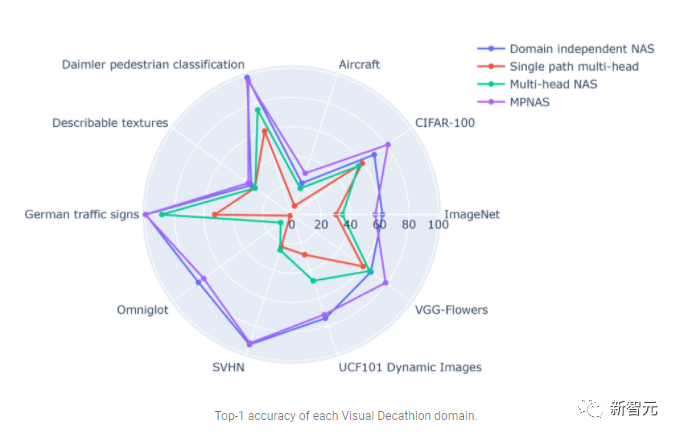
评估表明,通过使用 ABDP 作为搜索和训练阶段的一部分,top-1 的准确率从 69.96% 提高到 71.78%(增量: 1.81%)。
未来方向
MPNAS是构建异构网络以解决MDL中可能的参数共享策略的数据不平衡、域多样性、负迁移、域可扩展性和大搜索空间的有效解决方案。 通过使用类似MobileNet的搜索空间,生成的模型也对移动设备友好。 对于与现有搜索算法不兼容的任务,研究人员正继续扩展MPNAS用于多任务学习,并希望用MPNAS来构建统一的多域模型。
以上是多路径多领域通吃!谷歌AI发布多领域学习通用模型MDL的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 YOLO不死!YOLOv9出炉:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
YOLO不死!YOLOv9出炉:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
如今的深度学习方法专注于设计最适合的目标函数,以使模型的预测结果与实际情况最接近。同时,必须设计一个合适的架构,以便为预测获取足够的信息。现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。本文将深入探讨数据通过深度网络传输时的重要问题,即信息瓶颈和可逆函数。基于此提出了可编程梯度信息(PGI)的概念,以应对深度网络实现多目标所需的各种变化。PGI可以为目标任务提供完整的输入信息,以计算目标函数,从而获得可靠的梯度信息以更新网络权重。此外设计了一种新的轻量级网络架
 此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
Jun 14, 2023 pm 01:43 PM
此「错」并非真的错:从四篇经典论文入手,理解Transformer架构图「错」在何处
Jun 14, 2023 pm 01:43 PM
前段时间,一条指出谷歌大脑团队论文《AttentionIsAllYouNeed》中Transformer构架图与代码不一致的推文引发了大量的讨论。对于Sebastian的这一发现,有人认为属于无心之过,但同时也会令人感到奇怪。毕竟,考虑到Transformer论文的流行程度,这个不一致问题早就应该被提及1000次。SebastianRaschka在回答网友评论时说,「最最原始」的代码确实与架构图一致,但2017年提交的代码版本进行了修改,但同时没有更新架构图。这也是造成「不一致」讨论的根本原因。
 多路径多领域通吃!谷歌AI发布多领域学习通用模型MDL
May 28, 2023 pm 02:12 PM
多路径多领域通吃!谷歌AI发布多领域学习通用模型MDL
May 28, 2023 pm 02:12 PM
面向视觉任务(如图像分类)的深度学习模型,通常用来自单一视觉域(如自然图像或计算机生成的图像)的数据进行端到端的训练。一般情况下,一个为多个领域完成视觉任务的应用程序需要为每个单独的领域建立多个模型,分别独立训练,不同领域之间不共享数据,在推理时,每个模型将处理特定领域的输入数据。即使是面向不同领域,这些模型之间的早期层的有些特征都是相似的,所以,对这些模型进行联合训练的效率更高。这能减少延迟和功耗,降低存储每个模型参数的内存成本,这种方法被称为多领域学习(MDL)。此外,MDL模型也可以优于单
 Spring Data JPA 的架构和工作原理是什么?
Apr 17, 2024 pm 02:48 PM
Spring Data JPA 的架构和工作原理是什么?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA基于JPA架构,通过映射、ORM和事务管理与数据库交互。其存储库提供CRUD操作,派生查询简化了数据库访问。此外,它使用延迟加载,仅在必要时检索数据,从而提高了性能。
 1.3ms耗时!清华最新开源移动端神经网络架构 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗时!清华最新开源移动端神经网络架构 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显着的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
 golang框架架构的学习曲线有多陡峭?
Jun 05, 2024 pm 06:59 PM
golang框架架构的学习曲线有多陡峭?
Jun 05, 2024 pm 06:59 PM
Go框架架构的学习曲线取决于对Go语言和后端开发的熟悉程度以及所选框架的复杂性:对Go语言的基础知识有较好的理解。具有后端开发经验会有所帮助。复杂性不同的框架导致学习曲线差异。
 你知道程序员再过几年会没落?
Nov 08, 2023 am 11:17 AM
你知道程序员再过几年会没落?
Nov 08, 2023 am 11:17 AM
《ComputerWorld》杂志曾经写过一篇文章,说“编程到1960年就会消失”,因为IBM开发了一种新语言FORTRAN,这种新语言可以让工程师写出他们所需的数学公式,然后提交给计算机运行,所以编程就会终结。图片又过了几年,我们听到了一种新说法:任何业务人员都可以使用业务术语来描述自己的问题,告诉计算机要做什么,使用这种叫做COBOL的编程语言,公司不再需要程序员了。后来,据说IBM开发出了一门名为RPG的新编程语言,可以让员工填写表格并生成报告,因此大部分企业的编程需求都可以通过它来完成图
 探索使用对比损失的孪生网络进行图像相似性比较
Apr 02, 2024 am 11:37 AM
探索使用对比损失的孪生网络进行图像相似性比较
Apr 02, 2024 am 11:37 AM
简介在计算机视觉领域,准确地测量图像相似性是一项关键任务,具有广泛的实际应用。从图像搜索引擎到人脸识别系统和基于内容的推荐系统,有效比较和查找相似图像的能力非常重要。Siamese网络与对比损失结合,为数据驱动方式学习图像相似性提供了强大的框架。在这篇博文中,我们将深入了解Siamese网络的细节,探讨对比损失的概念,并探讨这两个组件如何共同工作以创建一个有效的图像相似性模型。首先,Siamese网络由两个相同的子网络组成,这两个子网络共享相同的权重和参数。每个子网络将输入图像编码为特征向量,这
