

Python的socket与socketserver怎么使用

一、基于TCP协议的socket套接字编程
1、套接字工作流程
先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束,使用以下Python代码实现:
import socket # socket_family 可以是 AF_UNIX 或 AF_INET。socket_type 可以是 SOCK_STREAM 或 SOCK_DGRAM。protocol 一般不填,默认值为 0 socket.socket(socket_family, socket_type, protocal=0) # 获取tcp/ip套接字 tcpSock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 获取udp/ip套接字 udpSock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
1、 服务端套接字函数
s.bind():绑定(主机,端口号)到套接字
s.listen():开始TCP监听
s.accept():被动接受TCP客户的连接,(阻塞式)等待连接的到来
2、 客户端套接字函数
s.connect():主动初始化TCP服务器连接
s.connect_ex():connect()函数的扩展版本,出错时返回出错码,而不是抛出异常
3、 公共用途的套接字函数
s.recv():接收TCP数据
s.send():发送TCP数据(send在待发送数据量大于己端缓存区剩余空间时,数据丢失,不会发完)
s.sendall():发送完整的TCP数据(本质就是循环调用send,sendall在待发送数据量大于己端缓存区剩余空间时,数据不丢失,循环调用send直到发完)
s.recvfrom():接收UDP数据
s.sendto():发送UDP数据
s.getpeername():连接到当前套接字的远端的地址
s.getsockname():当前套接字的地址
s.getsockopt():返回指定套接字的参数
s.setsockopt():设置指定套接字的参数
s.close():关闭套接字
4、 面向锁的套接字方法
s.setblocking():设置套接字的阻塞与非阻塞模式
s.settimeout():设置阻塞套接字操作的超时时间
s.gettimeout():得到阻塞套接字操作的超时时间
5、 面向文件的套接字的函数
s.fileno():套接字的文件描述符
s.makefile():创建一个与该套接字相关的文件
2、基于TCP协议的套接字编程
可以通过netstat -an | findstr 8080查看套接字状态
1、 服务端
import socket # 1、买手机 phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # tcp称为流式协议,udp称为数据报协议SOCK_DGRAM # print(phone) # 2、插入/绑定手机卡 # phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) phone.bind(('127.0.0.1', 8080)) # 3、开机 phone.listen(5) # 半连接池,限制的是请求数 # 4、等待电话连接 print('start....') while True: # 连接循环 conn, client_addr = phone.accept() # (三次握手建立的双向连接,(客户端的ip,端口)) # print(conn) print('已经有一个连接建立成功', client_addr) # 5、通信:收\发消息 while True: # 通信循环 try: print('服务端正在收数据...') data = conn.recv(1024) # 最大接收的字节数,没有数据会在原地一直等待收,即发送者发送的数据量必须>0bytes # print('===>') if len(data) == 0: break # 在客户端单方面断开连接,服务端才会出现收空数据的情况 print('来自客户端的数据', data) conn.send(data.upper()) except ConnectionResetError: break # 6、挂掉电话连接 conn.close() # 7、关机 phone.close() # start.... # 已经有一个连接建立成功 ('127.0.0.1', 4065) # 服务端正在收数据... # 来自客户端的数据 b'\xad' # 服务端正在收数据...
2、 客户端
import socket # 1、买手机 phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # print(phone) # 2、拨电话 phone.connect(('127.0.0.1', 8080)) # 指定服务端ip和端口 # 3、通信:发\收消息 while True: # 通信循环 msg = input('>>: ').strip() # msg='' if len(msg) == 0: continue phone.send(msg.encode('utf-8')) # print('has send----->') data = phone.recv(1024) # print('has recv----->') print(data) # 4、关闭 phone.close() # >>: 啊 # b'a' # >>: 啊啊 # b'\xb0\xa1\xb0\xa1' # >>:
3、地址占用问题
这个是由于你的服务端仍然存在四次挥手的time_wait状态在占用地址(如果不懂,请深入研究1.tcp三次握手,四次挥手 2.syn洪水攻击 3.服务器高并发情况下会有大量的time_wait状态的优化方法)
1、 方法一:加入一条socket配置,重用ip和端口
# phone=socket(AF_INET,SOCK_STREAM) phone.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) #就是它,在bind前加 phone.bind(('127.0.0.1',8080))
2、 方法二:通过调整linux内核参数
发现系统存在大量TIME_WAIT状态的连接,通过调整linux内核参数解决, vi /etc/sysctl.conf 编辑文件,加入以下内容: net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_fin_timeout = 30 然后执行 /sbin/sysctl -p 让参数生效。 net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭; net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭; net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。 net.ipv4.tcp_fin_timeout 修改系統默认的 TIMEOUT 时间
4、模拟ssh远程执行命令
服务端通过subprocess执行该命令,然后返回命令的结果。
服务端:
from socket import * import subprocess server = socket(AF_INET, SOCK_STREAM) server.bind(('127.0.0.1', 8000)) server.listen(5) print('start...') while True: conn, client_addr = server.accept() while True: print('from client:', client_addr) cmd = conn.recv(1024) if len(cmd) == 0: break print('cmd:', cmd) obj = subprocess.Popen(cmd.decode('utf8'), # 输入的cmd命令 shell=True, # 通过shell运行 stderr=subprocess.PIPE, # 把错误输出放入管道,以便打印 stdout=subprocess.PIPE) # 把正确输出放入管道,以便打印 stdout = obj.stdout.read() # 打印正确输出 stderr = obj.stderr.read() # 打印错误输出 conn.send(stdout) conn.send(stderr) conn.close() server.close()
客户端
import socket client = socket.socket(socket.AF_INET, socket.SOCK_STREAM) client.connect(('127.0.0.1', 8000)) while True: data = input('please enter your data') client.send(data.encode('utf8')) data = client.recv(1024) print('from server:', data) client.close()
输入dir命令,由于服务端发送字节少于1024字节,客户端可以接受。
输入tasklist命令,由于服务端发送字节多于1024字节,客户端只接受部分数据,并且当你再次输入dir命令的时候,客户端会接收dir命令的结果,但是会打印上一次的剩余未发送完的数据,这就是粘包问题。

5、粘包
1、发送端需要等缓冲区满才发送出去,造成粘包
发送数据时间间隔很短,数据量很小,会合到一起,产生粘包。
服务端
# _*_coding:utf-8_*_ from socket import * ip_port = ('127.0.0.1', 8080) TCP_socket_server = socket(AF_INET, SOCK_STREAM) TCP_socket_server.bind(ip_port) TCP_socket_server.listen(5) conn, addr = TCP_socket_server.accept() data1 = conn.recv(10) data2 = conn.recv(10) print('----->', data1.decode('utf-8')) print('----->', data2.decode('utf-8')) conn.close()
客户端
# _*_coding:utf-8_*_ import socket BUFSIZE = 1024 ip_port = ('127.0.0.1', 8080) s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) res = s.connect_ex(ip_port) s.send('hello'.encode('utf-8')) s.send('world'.encode('utf-8')) # 服务端一起收到b'helloworld'
2、接收方不及时接收缓冲区的包,造成多个包接收
客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包。
服务端
# _*_coding:utf-8_*_ from socket import * ip_port = ('127.0.0.1', 8080) TCP_socket_server = socket(AF_INET, SOCK_STREAM) TCP_socket_server.bind(ip_port) TCP_socket_server.listen(5) conn, addr = TCP_socket_server.accept() data1 = conn.recv(2) # 一次没有收完整 data2 = conn.recv(10) # 下次收的时候,会先取旧的数据,然后取新的 print('----->', data1.decode('utf-8')) print('----->', data2.decode('utf-8')) conn.close()
客户端
# _*_coding:utf-8_*_ import socket BUFSIZE = 1024 ip_port = ('127.0.0.1', 8080) s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) res = s.connect_ex(ip_port) s.send('hello feng'.encode('utf-8'))
6、解决粘包问题
1、先发送的字节流总大小(low版)
问题的根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕,如何让发送端在发送数据前,把自己将要发送的字节流总大小让接收端知晓,然后接收端来一个死循环接收完所有数据。
为何low:程序的运行速度远快于网络传输速度,所以在发送一段字节前,先用send去发送该字节流长度,这种方式会放大网络延迟带来的性能损耗。
服务端:
import socket, subprocess server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.bind(('127.0.0.1', 8000)) server.listen(5) while True: conn, addr = server.accept() print('start...') while True: cmd = conn.recv(1024) print('cmd:', cmd) obj = subprocess.Popen(cmd.decode('utf8'), shell=True, stderr=subprocess.PIPE, stdout=subprocess.PIPE) stdout = obj.stdout.read() if stdout: ret = stdout else: stderr = obj.stderr.read() ret = stderr ret_len = len(ret) conn.send(str(ret_len).encode('utf8')) data = conn.recv(1024).decode('utf8') if data == 'recv_ready': conn.sendall(ret) conn.close() server.close()
客户端:
import socket client = socket.socket(socket.AF_INET, socket.SOCK_STREAM) client.connect(('127.0.0.1', 8000)) while True: msg = input('please enter your cmd you want>>>').strip() if len(msg) == 0: continue client.send(msg.encode('utf8')) length = int(client.recv(1024)) client.send('recv_ready'.encode('utf8')) send_size = 0 recv_size = 0 data = b'' while recv_size < length: data = client.recv(1024) recv_size += len(data) print(data.decode('utf8'))
2、自定义固定长度报头(struct模块)
struct模块解析
import struct import json # 'i'是格式 try: obj = struct.pack('i', 1222222222223) except Exception as e: print(e) obj = struct.pack('i', 1222) print(obj, len(obj)) # 'i' format requires -2147483648 <= number <= 2147483647 # b'\xc6\x04\x00\x00' 4 res = struct.unpack('i', obj) print(res[0]) # 1222
解决粘包问题的核心就是:为字节流加上自定义固定长度报头,报头中包含字节流长度,然后一次send到对端,对端在接收时,先从缓存中取出定长的报头,然后再取真实数据。
1、 使用struct模块创建报头:
import json
import struct
header_dic = {
'filename': 'a.txt',
'total_size':111111111111111111111111111111111222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222222223131232,
'hash': 'asdf123123x123213x'
}
header_json = json.dumps(header_dic)
header_bytes = header_json.encode('utf-8')
print(len(header_bytes))# 223
# 'i'是格式
obj = struct.pack('i', len(header_bytes))
print(obj, len(obj))
# b'\xdf\x00\x00\x00' 4
res = struct.unpack('i', obj)
print(res[0])
# 2232、服务端:
from socket import *
import subprocess
import struct
import json
server = socket(AF_INET, SOCK_STREAM)
server.bind(('127.0.0.1', 8000))
server.listen(5)
print('start...')
while True:
conn, client_addr = server.accept()
print(conn, client_addr)
while True:
cmd = conn.recv(1024)
obj = subprocess.Popen(cmd.decode('utf8'),
shell=True,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE)
stderr = obj.stderr.read()
stdout = obj.stdout.read()
# 制作报头
header_dict = {
'filename': 'a.txt',
'total_size': len(stdout) + len(stderr),
'hash': 'xasf123213123'
}
header_json = json.dumps(header_dict)
header_bytes = header_json.encode('utf8')
# 1. 先把报头的长度len(header_bytes)打包成4个bytes,然后发送
conn.send(struct.pack('i', len(header_bytes)))
# 2. 发送报头
conn.send(header_bytes)
# 3. 发送真实的数据
conn.send(stdout)
conn.send(stderr)
conn.close()
server.close()3、 客户端:
from socket import * import json import struct client = socket(AF_INET, SOCK_STREAM) client.connect(('127.0.0.1', 8000)) while True: cmd = input('please enter your cmd you want>>>') if len(cmd) == 0: continue client.send(cmd.encode('utf8')) # 1. 先收4个字节,这4个字节中包含报头的长度 header_len = struct.unpack('i', client.recv(4))[0] # 2. 再接收报头 header_bytes = client.recv(header_len) # 3. 从包头中解析出想要的东西 header_json = header_bytes.decode('utf8') header_dict = json.loads(header_json) total_size = header_dict['total_size'] # 4. 再收真实的数据 recv_size = 0 res = b'' while recv_size < total_size: data = client.recv(1024) res += data recv_size += len(data) print(res.decode('utf8')) client.close()
二、基于UDP协议的socket套接字编程
UDP是无链接的,先启动哪一端都不会报错,并且可以同时多个客户端去跟服务端通信
UDP协议是数据报协议,发空的时候也会自带报头,因此客户端输入空,服务端也能收到。
UPD协议一般不用于传输大数据。
UPD套接字无粘包问题,但是不能替代TCP套接字,因为UPD协议有一个缺陷:如果数据发送的途中,数据丢失,则数据就丢失了,而TCP协议则不会有这种缺陷,因此一般UPD套接字用户无关紧要的数据发送,例如qq聊天。
UDP套接字简单示例
1、服务端
import socket server = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 数据报协议-》UDP server.bind(('127.0.0.1', 8080)) while True: data, client_addr = server.recvfrom(1024) print('===>', data, client_addr) server.sendto(data.upper(), client_addr) server.close()
2、客户端
import socket client = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 数据报协议-》UDP while True: msg = input('>>: ').strip() # msg='' client.sendto(msg.encode('utf-8'), ('127.0.0.1', 8080)) data, server_addr = client.recvfrom(1024) print(data) client.close()
三、基于socketserver实现并发的socket编程
1、基于TCP协议
基于tcp的套接字,关键就是两个循环,一个链接循环,一个通信循环
socketserver模块中分两大类:server类(解决链接问题)和request类(解决通信问题)。
1、 server类
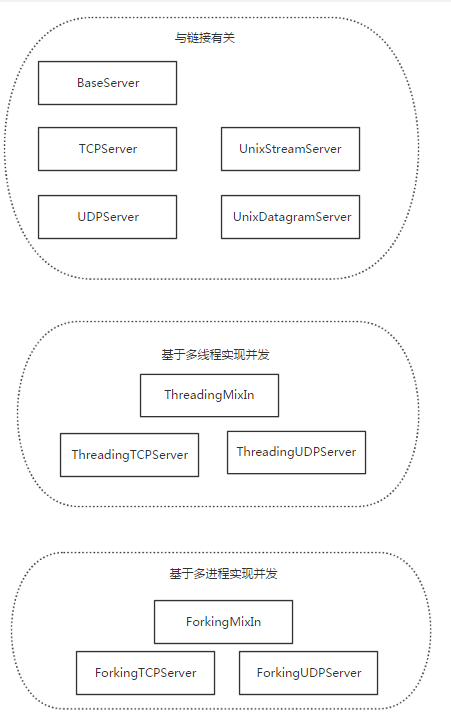
2、 request类
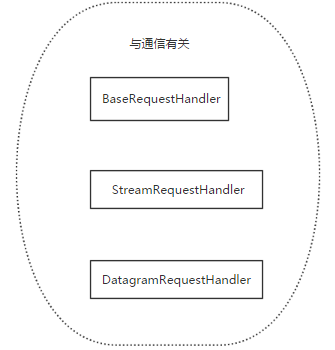
基于tcp的socketserver我们自己定义的类中的。
self.server即套接字对象
self.request即一个链接
self.client_address即客户端地址
3、 服务端
import socketserver class MyHandler(socketserver.BaseRequestHandler): def handle(self): # 通信循环 while True: # print(self.client_address) # print(self.request) #self.request=conn try: data = self.request.recv(1024) if len(data) == 0: break self.request.send(data.upper()) except ConnectionResetError: break if __name__ == '__main__': s = socketserver.ThreadingTCPServer(('127.0.0.1', 8080), MyHandler, bind_and_activate=True) s.serve_forever() # 代表连接循环 # 循环建立连接,每建立一个连接就会启动一个线程(服务员)+调用Myhanlder类产生一个对象,调用该对象下的handle方法,专门与刚刚建立好的连接做通信循环
4、 客户端
import socket phone = socket.socket(socket.AF_INET, socket.SOCK_STREAM) phone.connect(('127.0.0.1', 8080)) # 指定服务端ip和端口 while True: # msg=input('>>: ').strip() #msg='' msg = 'client33333' # msg='' if len(msg) == 0: continue phone.send(msg.encode('utf-8')) data = phone.recv(1024) print(data) phone.close()
2、基于UDP协议
基于udp的socketserver我们自己定义的类中的
self.request是一个元组(第一个元素是客户端发来的数据,第二部分是服务端的udp套接字对象),如(b'adsf', )
self.client_address即客户端地址
1、 服务端
import socketserver class MyHandler(socketserver.BaseRequestHandler): def handle(self): # 通信循环 print(self.client_address) print(self.request) data = self.request[0] print('客户消息', data) self.request[1].sendto(data.upper(), self.client_address) if __name__ == '__main__': s = socketserver.ThreadingUDPServer(('127.0.0.1', 8080), MyHandler) s.serve_forever()
2、 客户端
import socket client = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 数据报协议-》udp while True: # msg=input('>>: ').strip() #msg='' msg = 'client1111' client.sendto(msg.encode('utf-8'), ('127.0.0.1', 8080)) data, server_addr = client.recvfrom(1024) print(data) client.close()
四、Python Internet 模块
以下列出了 Python 网络编程的一些重要模块:
| 协议 | 功能用处 | 端口号 | Python 模块 |
|---|---|---|---|
| HTTP | 网页访问 | 80 | httplib, urllib, xmlrpclib |
| NNTP | 阅读和张贴新闻文章,俗称为"帖子" | 119 | nntplib |
| FTP | 文件传输 | 20 | ftplib, urllib |
| SMTP | 发送邮件 | 25 | smtplib |
| POP3 | 接收邮件 | 110 | poplib |
| IMAP4 | 获取邮件 | 143 | imaplib |
| Telnet | 命令行 | 23 | telnetlib |
| Gopher | 信息查找 | 70 | gopherlib, urllib |
以上是Python的socket与socketserver怎么使用的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Python vs.C:申请和用例
Apr 12, 2025 am 12:01 AM
Python vs.C:申请和用例
Apr 12, 2025 am 12:01 AM
Python适合数据科学、Web开发和自动化任务,而C 适用于系统编程、游戏开发和嵌入式系统。 Python以简洁和强大的生态系统着称,C 则以高性能和底层控制能力闻名。
 oracle数据库有哪些类型的文件组成
Apr 11, 2025 pm 03:03 PM
oracle数据库有哪些类型的文件组成
Apr 11, 2025 pm 03:03 PM
Oracle 数据库文件结构包括:数据文件:存储实际数据。控制文件:记录数据库结构信息。重做日志文件:记录事务操作,确保数据一致性。参数文件:包含数据库运行参数,可优化性能。归档日志文件:备份重做日志文件,用于灾难恢复。
 oracle数据库怎么登陆
Apr 11, 2025 pm 02:39 PM
oracle数据库怎么登陆
Apr 11, 2025 pm 02:39 PM
Oracle 数据库登录不仅涉及用户名和密码,还包括连接字符串(包含服务器信息和凭证)以及身份验证方式。它支持 SQL*Plus 和编程语言连接器,并提供用户名密码、Kerberos 和 LDAP 等身份验证选项。常见错误包括连接字符串错误和无效的用户名/密码,而最佳实践侧重于连接池、参数化查询、索引和安全凭证处理。
 如何利用Debian Apache日志提升网站性能
Apr 12, 2025 pm 11:36 PM
如何利用Debian Apache日志提升网站性能
Apr 12, 2025 pm 11:36 PM
本文将阐述如何通过分析Debian系统下的Apache日志来提升网站性能。一、日志分析基础Apache日志记录了所有HTTP请求的详细信息,包括IP地址、时间戳、请求URL、HTTP方法和响应代码等。在Debian系统中,这些日志通常位于/var/log/apache2/access.log和/var/log/apache2/error.log目录下。理解日志结构是有效分析的第一步。二、日志分析工具您可以使用多种工具分析Apache日志:命令行工具:grep、awk、sed等命令行工具可
 Python:游戏,Guis等
Apr 13, 2025 am 12:14 AM
Python:游戏,Guis等
Apr 13, 2025 am 12:14 AM
Python在游戏和GUI开发中表现出色。1)游戏开发使用Pygame,提供绘图、音频等功能,适合创建2D游戏。2)GUI开发可选择Tkinter或PyQt,Tkinter简单易用,PyQt功能丰富,适合专业开发。
 oracle数据库在c盘安装了哪些东西
Apr 11, 2025 pm 04:21 PM
oracle数据库在c盘安装了哪些东西
Apr 11, 2025 pm 04:21 PM
Oracle数据库在C盘的藏身之处:注册表:使用注册表编辑器搜索"Oracle",可找到包括安装路径、服务名称等信息。文件系统:Oracle文件散布在C盘多个位置,包括主目录、系统文件、临时文件等。环境变量:Oracle设置的环境变量(如ORACLE_HOME、ORACLE_SID)指向安装目录和实例名称。谨慎操作:卸载Oracle时,不仅要删除文件,还需清理注册表和服务,建议使用官方卸载工具或寻求专业帮助。空间管理:优化磁盘空间,避免将Oracle安装在C盘;定期清理临时文
 Laravel(PHP)与Python:开发环境和生态系统
Apr 12, 2025 am 12:10 AM
Laravel(PHP)与Python:开发环境和生态系统
Apr 12, 2025 am 12:10 AM
Laravel和Python在开发环境和生态系统上的对比如下:1.Laravel的开发环境简单,仅需PHP和Composer,提供了丰富的扩展包如LaravelForge,但扩展包维护可能不及时。2.Python的开发环境也简单,仅需Python和pip,生态系统庞大,涵盖多个领域,但版本和依赖管理可能复杂。
 PHP和Python:比较两种流行的编程语言
Apr 14, 2025 am 12:13 AM
PHP和Python:比较两种流行的编程语言
Apr 14, 2025 am 12:13 AM
PHP和Python各有优势,选择依据项目需求。1.PHP适合web开发,尤其快速开发和维护网站。2.Python适用于数据科学、机器学习和人工智能,语法简洁,适合初学者。
