

7nm制程,比GPU效率高,Meta发布第一代AI推理加速器

机器之心报道
机器之心编辑部
近日,Meta 透露了其在人工智能方面取得的最新进展。
人们提起 Meta 时,通常会想到其应用程序,包括 Facebook、Instagram、WhatsApp 或即将推出的元宇宙。但许多人不知道的是这家公司设计和构建了非常复杂的数据中心来运营这些服务。
与 AWS、GCP 或 Azure 等云服务提供商不同,Meta 不需要披露有关其硅芯选择、基础设施或数据中心设计的细节,除了其 OCP 设计用来给买家留下深刻印象。Meta 的用户希望获得更好、更一致的体验,而不关心它是如何实现的。
在 Meta,AI 工作负载无处不在,它们构成了广泛用例的基础,包括内容理解、信息流、生成式 AI 和广告排名。这些工作负载在 PyTorch 上运行,具有一流的 Python 集成、即时模式(eager-mode)开发和 API 简洁性。特别是深度学习推荐模型(DLRMs),对于改善 Meta 的服务和应用体验非常重要。但随着这些模型的大小和复杂性的增加,底层的硬件系统需要在保持高效的同时提供指数级增长的内存和计算能力。
Meta 发现,对于目前规模的 AI 运算和特定的工作负载,GPU 的效率不高,并不是最佳选择。因此,该公司提出了推理加速器 MTIA,帮助更快地训练 AI 系统。
MTIA V1
MTIA v1(推理)芯片(die)
2020 年,Meta 为其内部工作负载设计了第一代 MTIA ASIC 推理加速器。该推理加速器是其全栈解决方案的一部分,整个解决方案包括芯片、PyTorch 和推荐模型。
MTIA 加速器采用 TSMC 7nm 工艺制造,运行频率为 800 MHz,在 INT8 精度下提供 102.4 TOPS,在 FP16 精度下提供 51.2 TFLOPS。它的热设计功耗 (TDP) 为 25 W。
MTIA 加速器由处理元件 (PE)、片上和片外存储器资源以及互连组成。该加速器配备了运行系统固件的专用控制子系统。固件管理可用的计算和内存资源,通过专用主机接口与主机通信,协调加速器上的 job 执行。
内存子系统使用 LPDDR5 作为片外 DRAM 资源,可扩展至 128 GB。该芯片还有 128 MB 的片上 SRAM,由所有 PE 共享,为频繁访问的数据和指令提供更高的带宽和更低的延迟。
MTIA 加速器网格包含以 8x8 配置组织的 64 个 PE,这些 PE 相互连接,并通过网状网络连接到内存块。整个网格可以作为一个整体来运行一个 job,也可以分成多个可以运行独立 job 的子网格。
每个 PE 配备两个处理器内核(其中一个配备矢量扩展)和一些固定功能单元,这些单元经过优化以执行关键操作,例如矩阵乘法、累加、数据移动和非线性函数计算。处理器内核基于 RISC-V 开放指令集架构 (ISA),并经过大量定制以执行必要的计算和控制任务。
每个 PE 还具有 128 KB 的本地 SRAM 内存,用于快速存储和操作数据。该架构最大限度地提高了并行性和数据重用性,这是高效运行工作负载的基础。
该芯片同时提供线程和数据级并行性(TLP 和 DLP),利用指令级并行性 (ILP),并通过允许同时处理大量内存请求来实现大量的内存级并行性 (MLP)。
MTIA v1 系统设计
MTIA 加速器安装在小型双 M.2 板上,可以更轻松地集成到服务器中。这些板使用 PCIe Gen4 x8 链接连接到服务器上的主机 CPU,功耗低至 35 W。

带有 MTIA 的样品测试板
托管这些加速器的服务器使用来自开放计算项目的 Yosemite V3 服务器规范。每台服务器包含 12 个加速器,这些加速器连接到主机 CPU,并使用 PCIe 交换机层级相互连接。因此,不同加速器之间的通信不需要涉及主机 CPU。此拓扑允许将工作负载分布在多个加速器上并并行运行。加速器的数量和服务器配置参数经过精心选择,以最适合执行当前和未来的工作负载。
MTIA 软件栈
MTIA 软件(SW)栈旨在提供给开发者更好的开发效率和高性能体验。它与 PyTorch 完全集成,给用户提供了一种熟悉的开发体验。使用基于 MTIA 的 PyTorch 与使用 CPU 或 GPU 的 PyTorch 一样简单。并且,得益于蓬勃发展的 PyTorch 开发者生态系统和工具,现在 MTIA SW 栈可以使用 PyTorch FX IR 执行模型级转换和优化,并使用 LLVM IR 进行低级优化,同时还支持 MTIA 加速器自定义架构和 ISA。
下图为 MTIA 软件栈框架图:
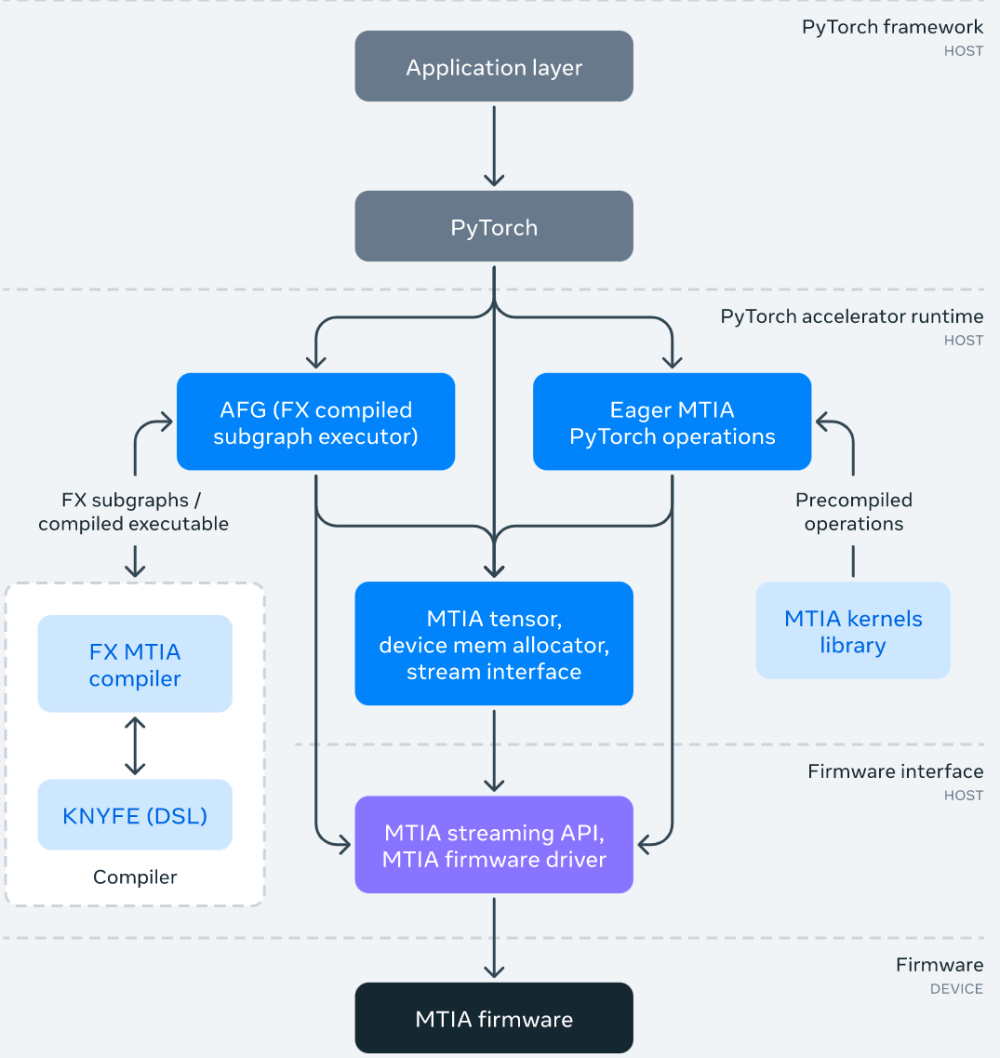
作为 SW 栈的一部分,Meta 还为性能关键型 ML 内核开发了一个手动调整和高度优化的内核库,例如完全连接和嵌入包运算符。在 SW 栈的更高层级可以选择在编译和代码生成过程中实例化和使用这些高度优化的内核。
此外,MTIA SW 栈随着与 PyTorch 2.0 的集成而不断发展,PyTorch 2.0 更快、更 Python 化,但一如既往地动态。这将启用新功能,例如 TorchDynamo 和 TorchInductor。Meta 还在扩展 Triton DSL 以支持 MTIA 加速器,并使用 MLIR 进行内部表示和高级优化。
MTIA 性能
Meta 比较了 MTIA 与其他加速器的性能,结果如下:
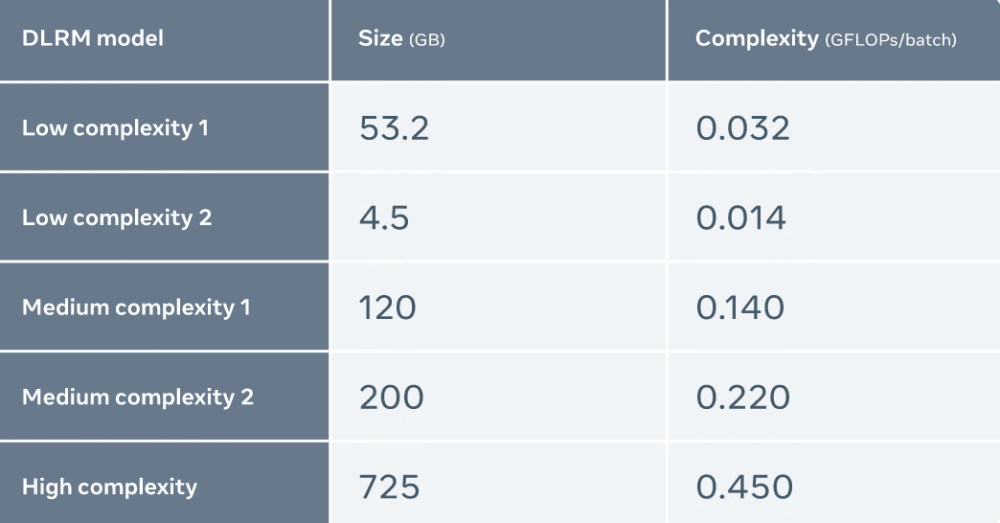
Meta 使用五种不同的 DLRMs(复杂度从低到高)来评估 MTIA
此外,Meta 还将 MTIA 与 NNPI 以及 GPU 进行了比较,结果如下:

评估发现,与 NNPI 和 GPU 相比,MTIA 能够更高效地处理低复杂度(LC1 和 LC2)和中等复杂度(MC1 和 MC2)的模型。此外,Meta 尚未针对高复杂度(HC)模型进行 MTIA 的优化。
参考链接:
https://ai.facebook.com/blog/meta-training-inference-accelerator-AI-MTIA/
以上是7nm制程,比GPU效率高,Meta发布第一代AI推理加速器的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 我尝试了使用光标AI编码的Vibe编码,这太神奇了!
Mar 20, 2025 pm 03:34 PM
我尝试了使用光标AI编码的Vibe编码,这太神奇了!
Mar 20, 2025 pm 03:34 PM
Vibe编码通过让我们使用自然语言而不是无尽的代码行创建应用程序来重塑软件开发的世界。受Andrej Karpathy等有远见的人的启发,这种创新的方法使Dev
 2025年2月的Genai推出前5名:GPT-4.5,Grok-3等!
Mar 22, 2025 am 10:58 AM
2025年2月的Genai推出前5名:GPT-4.5,Grok-3等!
Mar 22, 2025 am 10:58 AM
2025年2月,Generative AI又是一个改变游戏规则的月份,为我们带来了一些最令人期待的模型升级和开创性的新功能。从Xai的Grok 3和Anthropic的Claude 3.7十四行诗到Openai的G
 如何使用Yolo V12进行对象检测?
Mar 22, 2025 am 11:07 AM
如何使用Yolo V12进行对象检测?
Mar 22, 2025 am 11:07 AM
Yolo(您只看一次)一直是领先的实时对象检测框架,每次迭代都在以前的版本上改善。最新版本Yolo V12引入了进步,可显着提高准确性
 Sora vs veo 2:哪个创建更现实的视频?
Mar 10, 2025 pm 12:22 PM
Sora vs veo 2:哪个创建更现实的视频?
Mar 10, 2025 pm 12:22 PM
Google的VEO 2和Openai的Sora:哪个AI视频发电机占据了至尊? 这两个平台都产生了令人印象深刻的AI视频,但它们的优势在于不同的领域。 使用各种提示,这种比较揭示了哪种工具最适合您的需求。 t
 Google的Gencast:Gencast Mini Demo的天气预报
Mar 16, 2025 pm 01:46 PM
Google的Gencast:Gencast Mini Demo的天气预报
Mar 16, 2025 pm 01:46 PM
Google DeepMind的Gencast:天气预报的革命性AI 天气预报经历了巨大的转变,从基本观察到复杂的AI驱动预测。 Google DeepMind的Gencast,开创性
 Chatgpt 4 o可用吗?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o可用吗?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4当前可用并广泛使用,与诸如ChatGpt 3.5(例如ChatGpt 3.5)相比,在理解上下文和产生连贯的响应方面取得了重大改进。未来的发展可能包括更多个性化的间
 哪个AI比Chatgpt更好?
Mar 18, 2025 pm 06:05 PM
哪个AI比Chatgpt更好?
Mar 18, 2025 pm 06:05 PM
本文讨论了AI模型超过Chatgpt,例如Lamda,Llama和Grok,突出了它们在准确性,理解和行业影响方面的优势。(159个字符)
 O1 vs GPT-4O:OpenAI的新型号比GPT-4O好吗?
Mar 16, 2025 am 11:47 AM
O1 vs GPT-4O:OpenAI的新型号比GPT-4O好吗?
Mar 16, 2025 am 11:47 AM
Openai的O1:为期12天的礼物狂欢始于他们迄今为止最强大的模型 12月的到来带来了全球放缓,世界某些地区的雪花放缓,但Openai才刚刚开始。 山姆·奥特曼(Sam Altman)和他的团队正在推出12天的礼物前
