

人人都懂ChatGPT第一章:ChatGPT 与自然语言处理


ChatGPT(Chat Generative Pre-training Transformer) 是一个 AI 模型,属于自然语言处理( Natural Language Processing , NLP ) 领域,NLP 是人工智能的一个分支。所谓自然语言,就是人们日常生活中
接触和使用的英语、汉语、德语等等。自然语言处理是指,让计算机来理解并正确地操作自然语言,完成人类指定的任务。NLP 中常见的任务包括文本中的关键词抽取、文本分类、机器翻译等等。
NLP 当中还有一个非常难的任务:对话系统,也可被笼统称为聊天机器人,正是 ChatGPT 所完成的工作。
ChatGPT 与图灵测试
自从 1950 年代出现计算机以来,人们就已经开始着手研究让计算机辅助人类理解、处理自然语言,这也是 NLP 这一领域的发展目标,最著名的当属图灵测试。
1950年,计算机之父——艾伦·图灵(Alan Turing)介绍了一项测试,以检查机器是否能像人类一样思考,这项测试称为图灵测试。它具体的测试方法和目前 ChatGPT 的方式一模一样,即构建一个计算机对话系统,一个人和被测试的模型互相进行对话,如果这个人无法辨别对方究竟是机器模型还是另一个人,就说明该模型通过了图灵测试,计算机是智能的。
长久以来,图灵测试都被学界认为是难以攀登的巅峰。正因如此,NLP 也被称为人工智能皇冠上的明珠。而 ChatGPT 所能够做的工作,已经远远超出了聊天机器人这个范畴,它能够根据用户的指令写文章,回答技术问题,做数学题,做外文翻译,玩文字游戏等等。所以,某种程度上,ChatGPT 已经摘下了这颗皇冠上的明珠。
ChatGPT 的建模形式
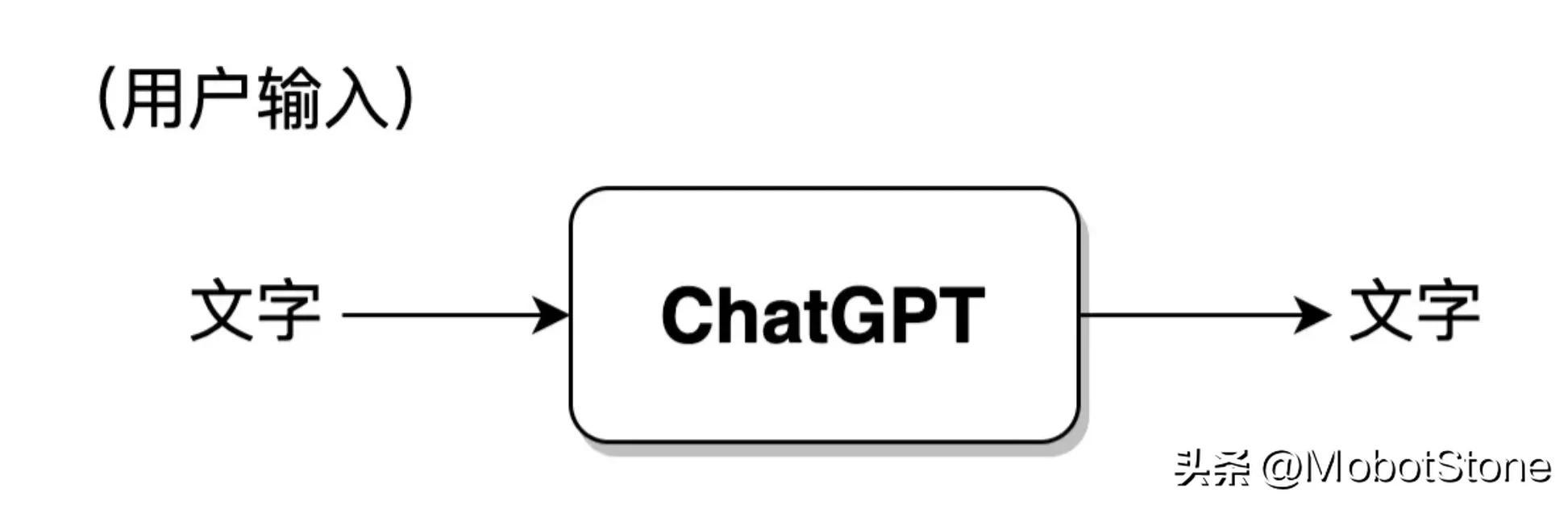
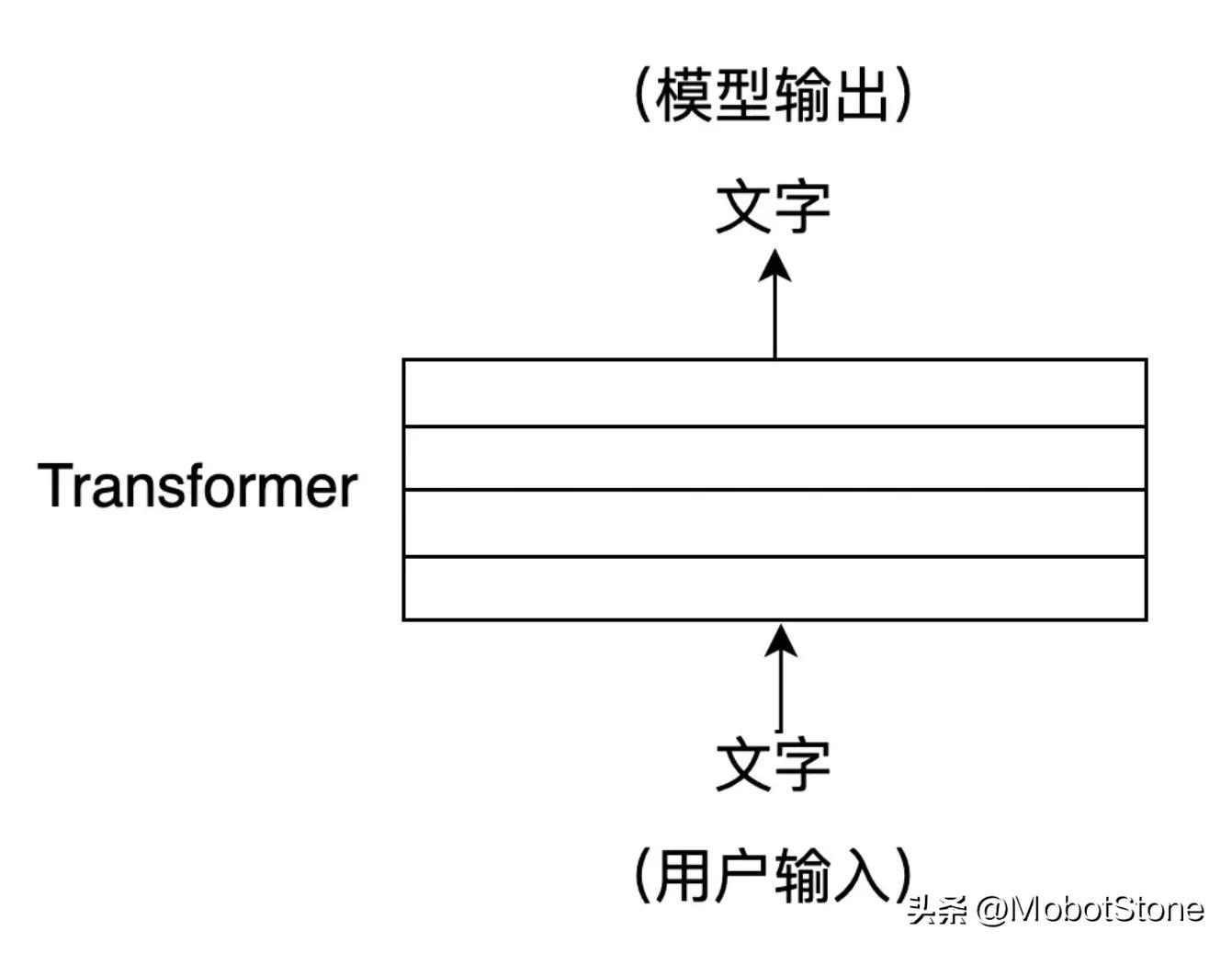
ChatGPT 的工作形式非常简单,用户向 ChatGPT 提问任何一个问题,模型都会做出解答。

其中,用户的输入和模型的输出都是文字形式。一次用户输入和一次模型对应的输出,叫做一轮对话。我们可以把 ChatGPT 的模型抽象成如下流程:
此外,ChatGPT 也可以回答用户的连续提问,也就是多轮对话,多轮对话之间是有信息关联的。其具体的形式也非常简单,第二次用户输入时,系统默认把第一次的输入、输出信息都拼接在一起,供 ChatGPT 参考上次对话的信息。
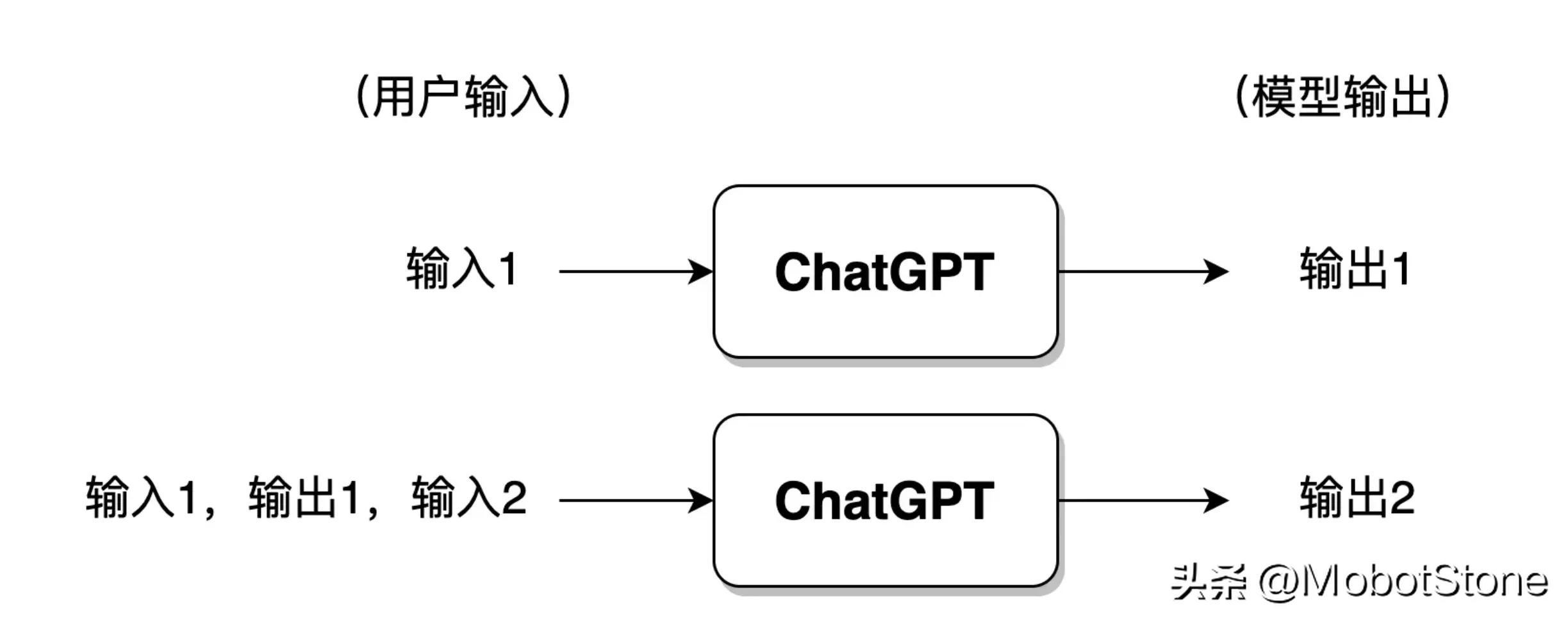
如果用户与 ChatGPT 对话的轮次过多,一般来讲模型仅会保留最近几轮对话的信息,此前的对话信息将被遗忘。
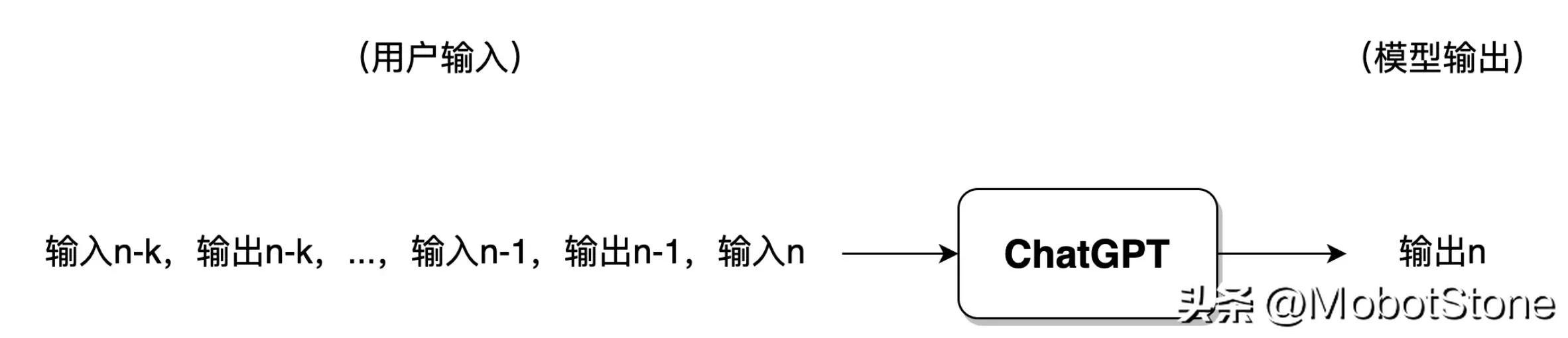
ChatGPT 在接收到用户的提问输入后,输出的文字并不是一口气直接生成的,而是一个字、一个字生成的,这种逐字生成,即生成式(Generative) 。如下图所示。
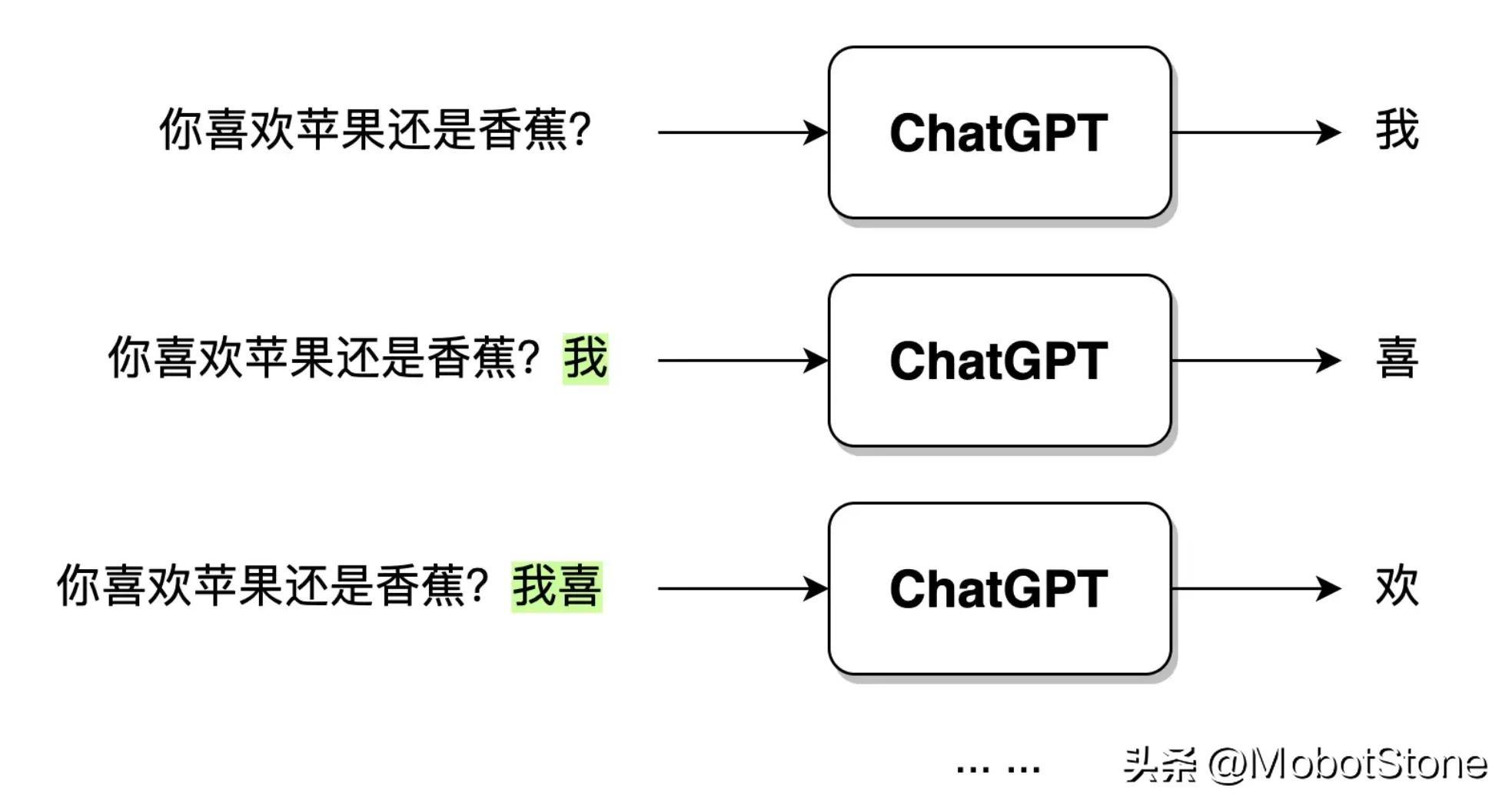
当用户输入问句:“你喜欢苹果还是香蕉?”,ChatGPT 接收到数据之后,首先会生成一个“我”字,然后,模型会综合用户的问句和生成的“我”字,继续生成下一个字“喜”。以此类推,直到生成一个完整的句子“我喜欢苹果。”。
ChatGPT 与 NLP 的发展历程
前面介绍了 ChatGPT 的建模形式,可以试想一下,如果让你来实现一个 ChatGPT 模型,有哪些思路和方法呢?事实上,大致有两种策略,基于规则的 NLP 和基于统计的 NLP。自从 ChatGPT 开始,NLP 领域又进入了强化学习时代,即基于强化学习的 NLP。
基于规则的 NLP
基于规则的 NLP,是指使用人工编写的规则来处理自然语言。这些规则通常基于语法、语义和语用等方面的知识,可以用来解析和生成自然语言。例如,我们可以基于以下规则设计一个对话系统:
规则 1:当模型接收到用户的问句后,把问句中的“吗”字去掉,“?”换成“。”
规则 2:把“你”换成“我”,“我”字换成“你”
由此,我们可以根据这些规则,制作一个对话模型,开启对话模式了。
用户:Hello。 模型:Hello。用户:你是 ChatGPT 吗? 模型:是的,我是 ChatGPT。 用户:你喜欢掘金社区吗? 模型:我喜欢掘金社区。用户:你有使用过jionlp工具包吗? 模型:我曾使用过jionlp工具包。
以上是一个基于规则的非常粗浅的对话系统示例。其中存在的问题,相信读者能够很容易找出来。如果用户问题太复杂了怎么办?问题中没有加问号怎么办?我们需要不断编写出各种规则来覆盖上面的特殊情况。这说明基于规则存在几个明显的缺点:
- 在自然语言中,任何规则都无法完全覆盖需求,因此在处理复杂的自然语言任务时效果不佳;
- 规则无穷无尽,靠人力来完成将是一项天量的工作;
- 本质上并没有把自然语言处理的任务交给计算机来完成,依然是人在主导。
这就是 NLP 发展早期的方式方法:基于规则完成模型系统构建。在早期,一般也被称为符号主义。
基于统计的 NLP
基于统计的 NLP 则是利用机器学习算法从大量的语料库中学习自然语言的规律特征,在早期也被称为连接主义。这种方法不需要人工编写规则,规则主要通过学习语言的统计特征,暗含在模型中。换句话说,基于规则的方法中,规则是显性的,人工编写的;基于统计的方法中,规则是隐形的,暗含在模型参数中,由模型根据数据训练得到。
这些模型,在近年来发展迅速,ChatGPT 就是其中一种。除此之外,还有各式各样不同形态构造的模型,其根基原理是相同的。它们的处理方式主要如下:
训练模型 => 利用已训练好的模型进行工作
在 ChatGPT 中,主要采用预训练( Pre-training ) 技术来完成基于统计的 NLP 模型学习。最早,NLP 领域的预训练是由 ELMO 模型(Embedding from Language Models)首次引进的,后续 ChatGPT 等各种深度神经网络模型广泛采用了这种方式。
它的重点在于,根据大规模原始语料学习一个语言模型,而这个模型并不直接学习如何解决具体的某种任务,而是学习从语法、词法、语用,到常识、知识等信息,把它们融汇在语言模型中。直观地讲,它更像是一个知识记忆器,而非运用知识解决实际问题。
预训练的好处很多,它已经成为了几乎所有 NLP 模型训练的必备步骤。我们将在后续章节展开讲。
基于统计的方法远远比基于规则的方法受欢迎,然而它最大的缺点是黑盒不确定性,即规则是隐形的,暗含在参数中。例如,ChatGPT 也会给出一些模棱两可、不知所云的结果,我们无从依照结果来判断模型为什么给出这样的答案。

基于强化学习的 NLP
ChatGPT 模型是基于统计的,然而它又利用了新的方法,带人工反馈的强化学习(Reinforcement Learning with Human Feedback,RLHF) ,以此取得了卓越的效果,把 NLP 的发展带入了一个新阶段。
几年前,Alpha GO 击败了柯洁。这几乎可以说明,强化学习如果在适合的条件下,完全可以打败人类,逼近完美的极限。当前,我们依然处在弱人工智能时代,但局限于围棋这个领域,Alpha GO 就是一个强人工智能,它的核心就在于强化学习 。
所谓强化学习,就是一种机器学习的方法,旨在让智能体(agent,在 NLP 中主要指深度神经网络模型,就是 ChatGPT 模型)通过与环境的交互来学习如何做出最优决策。
这种方式就像是训练一只狗(智能体)听哨声(环境)进食(学习目标)。
一只小狗,当听到主人吹哨后,就会被奖励食物;而当主人不吹哨时,小狗只能挨饿。通过反复的进食、挨饿,小狗就能建立起相应的条件反射,实际上就是完成了一次强化学习。
而在 NLP 领域,这里的环境要复杂得多。针对 NLP 模型的环境并非真正的人类语言环境,而是人为构造出来的一种语言环境模型。因此,这里强调是带人工反馈的强化学习。

基于统计的方式能够让模型以最大自由度去拟合训练数据集;而强化学习就是赋予模型更大的自由度,让模型能够自主学习,突破既定的数据集限制。ChatGPT 模型是融合统计学习方法和强化学习方法的,它的模型训练流程如下图所示:
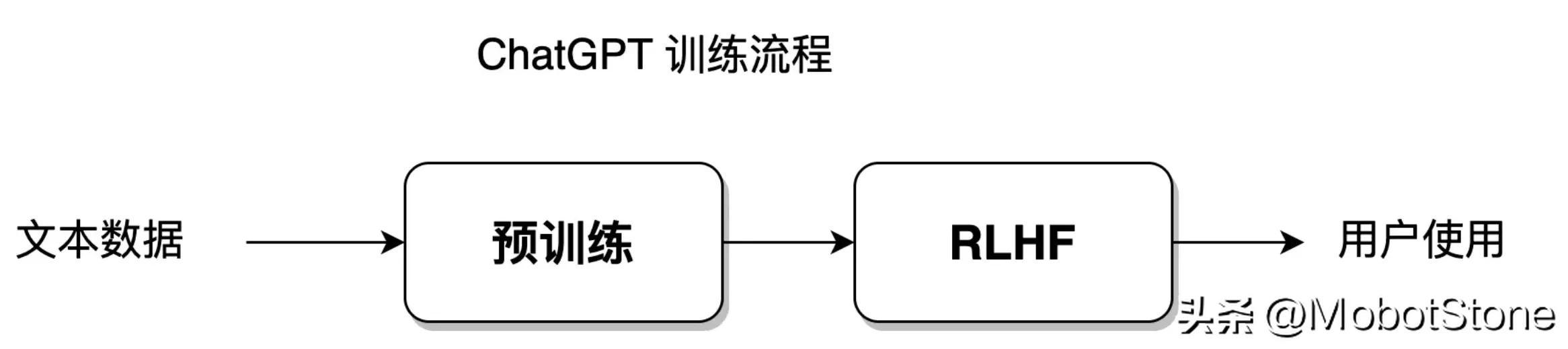
这部分训练流程将在第 8-11 节展开讲。
NLP 技术的发展脉络
实际上,基于规则、基于统计、基于强化学习 这 三种方式,并不仅仅是一种处理自然语言的手段,而是一种思想。一个解决某一问题的算法模型,往往是融合了这三种解决思想的产物。
如果把计算机比作一个小孩,自然语言处理就像是由人类来教育小孩成长。
基于规则的方式,就好比家长 100% 控制小孩,要求他按照自己的指令和规则行事,如每天规定学习几小时,教会小孩每一道题。整个过程,强调的是手把手教,主动权和重心都在家长身上。对于 NLP 而言,整个过程的主动权和重心,都在编写语言规则的程序员、研究员身上。
基于统计的方式,就好比家长只告诉小孩学习方法,而不教授具体每一道题,强调的是半引导。对于 NLP 而言,学习重心放在神经网络模型上,但主动权仍由算法工程师控制。
基于强化学习的方式,则好比家长只对小孩制定了教育目标,比如,要求小孩能够考试达到 90 分,但并不去管小孩他是如何学习的,全靠自学完成,小孩拥有极高的自由度和主动权。家长只对最终结果做出相应的_奖励或惩罚_,不参与整个教育过程。对于 NLP 来说,整个过程的重心和主动权都在于模型本身。
NLP 的发展一直以来都在逐渐向基于统计的方式靠拢,最终由基于强化学习的方式取得完全的胜利,胜利的标志,即 ChatGPT 的问世;而基于规则方式逐渐式微,沦为了一种辅助式的处理手段。ChatGPT 模型的发展,从一开始,就在坚定不移地沿着让模型自学的方向发展进步着。
ChatGPT 的神经网络结构 Transformer
前面的介绍中,为了方便读者理解,没有提 ChatGPT 模型内部的具体构造。
ChatGPT 是一个大型的神经网络,其内部结构是由若干层 Transformer 构成的,Transformer 是一种神经网络的结构。自从 2018 年开始,它就已经成为了 NLP 领域的一种通用的标准模型结构,Transformer 几乎遍布各种 NLP 模型之中。
如果说,ChatGPT 是一幢房子的话,那么,Transformer 就是构建 ChatGPT 的砖头。
Transformer 的核心是自注意力机制(Self-Attention),它可以帮助模型在处理输入的文字序列时,自动地关注到与当前位置字符相关的其他位置字符。自注意力机制可以将输入序列中的每个位置都表示为一个向量,这些向量可以同时参与计算,从而实现高效的并行计算。举一个例子:
在机器翻译中,在将英文句子 "I am a good student" 翻译成中文时,传统的机器翻译模型可能会将其翻译成 "我是一个好学生",但是这个翻译结果可能不够准确。英文中的冠词“a”,在翻译为中文时,需要结合上下文才能确定。
而使用 Transformer 模型进行翻译时,可以得到更加准确的翻译结果,例如 "我是一名好学生"。
这是因为 Transformer 能够更好地捕捉英文句子中,跨越很长距离的词汇之间的关系,解决文本上下文的长依赖。自注意力机制将在第 5-6 节展开介绍,Transformer 结构详解将在第 6-7 节展开介绍。
总结
- NLP 领域的发展逐渐由人为编写规则、逻辑控制计算机程序,到完全交由网络模型去适应语言环境。
- ChatGPT 是目前最接近通过图灵测试的 NLP 模型,未来GPT4、GPT5将会更加接近。
- ChatGPT 的工作流程是一个生成式的对话系统。
- ChatGPT 的训练过程包括语言模型的预训练,RLHF 带人工反馈的强化学习。
- ChatGPT 的模型结构采用以自注意力机制为核心的 Transformer。
以上是人人都懂ChatGPT第一章:ChatGPT 与自然语言处理的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 YOLO不死!YOLOv9出炉:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
YOLO不死!YOLOv9出炉:性能速度SOTA~
Feb 26, 2024 am 11:31 AM
如今的深度学习方法专注于设计最适合的目标函数,以使模型的预测结果与实际情况最接近。同时,必须设计一个合适的架构,以便为预测获取足够的信息。现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。本文将深入探讨数据通过深度网络传输时的重要问题,即信息瓶颈和可逆函数。基于此提出了可编程梯度信息(PGI)的概念,以应对深度网络实现多目标所需的各种变化。PGI可以为目标任务提供完整的输入信息,以计算目标函数,从而获得可靠的梯度信息以更新网络权重。此外设计了一种新的轻量级网络架
 GNN的基础、前沿和应用
Apr 11, 2023 pm 11:40 PM
GNN的基础、前沿和应用
Apr 11, 2023 pm 11:40 PM
近年来,图神经网络(GNN)取得了快速、令人难以置信的进展。图神经网络又称为图深度学习、图表征学习(图表示学习)或几何深度学习,是机器学习特别是深度学习领域增长最快的研究课题。本次分享的题目为《GNN的基础、前沿和应用》,主要介绍由吴凌飞、崔鹏、裴健、赵亮几位学者牵头编撰的综合性书籍《图神经网络基础、前沿与应用》中的大致内容。一、图神经网络的介绍1、为什么要研究图?图是一种描述和建模复杂系统的通用语言。图本身并不复杂,它主要由边和结点构成。我们可以用结点表示任何我们想要建模的物体,可以用边表示两
 一文通览自动驾驶三大主流芯片架构
Apr 12, 2023 pm 12:07 PM
一文通览自动驾驶三大主流芯片架构
Apr 12, 2023 pm 12:07 PM
当前主流的AI芯片主要分为三类,GPU、FPGA、ASIC。GPU、FPGA均是前期较为成熟的芯片架构,属于通用型芯片。ASIC属于为AI特定场景定制的芯片。行业内已经确认CPU不适用于AI计算,但是在AI应用领域也是必不可少。 GPU方案GPU与CPU的架构对比CPU遵循的是冯·诺依曼架构,其核心是存储程序/数据、串行顺序执行。因此CPU的架构中需要大量的空间去放置存储单元(Cache)和控制单元(Control),相比之下计算单元(ALU)只占据了很小的一部分,所以CPU在进行大规模并行计算
 "B站UP主成功打造全球首个基于红石的神经网络在社交媒体引起轰动,得到Yann LeCun的点赞赞赏"
May 07, 2023 pm 10:58 PM
"B站UP主成功打造全球首个基于红石的神经网络在社交媒体引起轰动,得到Yann LeCun的点赞赞赏"
May 07, 2023 pm 10:58 PM
在我的世界(Minecraft)中,红石是一种非常重要的物品。它是游戏中的一种独特材料,开关、红石火把和红石块等能对导线或物体提供类似电流的能量。红石电路可以为你建造用于控制或激活其他机械的结构,其本身既可以被设计为用于响应玩家的手动激活,也可以反复输出信号或者响应非玩家引发的变化,如生物移动、物品掉落、植物生长、日夜更替等等。因此,在我的世界中,红石能够控制的机械类别极其多,小到简单机械如自动门、光开关和频闪电源,大到占地巨大的电梯、自动农场、小游戏平台甚至游戏内建的计算机。近日,B站UP主@
 扛住强风的无人机?加州理工用12分钟飞行数据教会无人机御风飞行
Apr 09, 2023 pm 11:51 PM
扛住强风的无人机?加州理工用12分钟飞行数据教会无人机御风飞行
Apr 09, 2023 pm 11:51 PM
当风大到可以把伞吹坏的程度,无人机却稳稳当当,就像这样:御风飞行是空中飞行的一部分,从大的层面来讲,当飞行员驾驶飞机着陆时,风速可能会给他们带来挑战;从小的层面来讲,阵风也会影响无人机的飞行。目前来看,无人机要么在受控条件下飞行,无风;要么由人类使用遥控器操作。无人机被研究者控制在开阔的天空中编队飞行,但这些飞行通常是在理想的条件和环境下进行的。然而,要想让无人机自主执行必要但日常的任务,例如运送包裹,无人机必须能够实时适应风况。为了让无人机在风中飞行时具有更好的机动性,来自加州理工学院的一组工
 多路径多领域通吃!谷歌AI发布多领域学习通用模型MDL
May 28, 2023 pm 02:12 PM
多路径多领域通吃!谷歌AI发布多领域学习通用模型MDL
May 28, 2023 pm 02:12 PM
面向视觉任务(如图像分类)的深度学习模型,通常用来自单一视觉域(如自然图像或计算机生成的图像)的数据进行端到端的训练。一般情况下,一个为多个领域完成视觉任务的应用程序需要为每个单独的领域建立多个模型,分别独立训练,不同领域之间不共享数据,在推理时,每个模型将处理特定领域的输入数据。即使是面向不同领域,这些模型之间的早期层的有些特征都是相似的,所以,对这些模型进行联合训练的效率更高。这能减少延迟和功耗,降低存储每个模型参数的内存成本,这种方法被称为多领域学习(MDL)。此外,MDL模型也可以优于单
 1.3ms耗时!清华最新开源移动端神经网络架构 RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms耗时!清华最新开源移动端神经网络架构 RepViT
Mar 11, 2024 pm 12:07 PM
论文地址:https://arxiv.org/abs/2307.09283代码地址:https://github.com/THU-MIG/RepViTRepViT在移动端ViT架构中表现出色,展现出显着的优势。接下来,我们将探讨本研究的贡献所在。文中提到,轻量级ViTs通常比轻量级CNNs在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(MSHA)可以让模型学习全局表示。然而,轻量级ViTs和轻量级CNNs之间的架构差异尚未得到充分研究。在这项研究中,作者们通过整合轻量级ViTs的有效
 对比学习算法在转转的实践
Apr 11, 2023 pm 09:25 PM
对比学习算法在转转的实践
Apr 11, 2023 pm 09:25 PM
1 什么是对比学习1.1 对比学习的定义1.2 对比学习的原理1.3 经典对比学习算法系列2 对比学习的应用3 对比学习在转转的实践3.1 CL在推荐召回的实践3.2 CL在转转的未来规划1 什么是对比学习1.1 对比学习的定义对比学习(Contrastive Learning, CL)是近年来 AI 领域的热门研究方向,吸引了众多研究学者的关注,其所属的自监督学习方式,更是在 ICLR 2020 被 Bengio 和 LeCun 等大佬点名称为 AI 的未来,后陆续登陆 NIPS, ACL,
