

怎么掌握MySQL复制架构


一主多从复制架构
在实际应用中,MySQL复制的架构模式大多数都是将一个Master复制到一个或多个Slave。
在主库读取请求压力非常大的场景下,可以通过配置一主多从复制架构实现读写分离,把大量的对实时性要求不是特别高的读请求通过负载均衡分部到多个从库上(对于实时性要求很高的读请求可以让从主库去读),降低主库的读取压力,如下图所示。
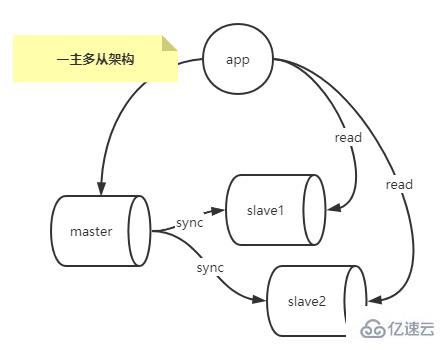
缺点:
master不能停机,停机就不能接收写请求
slave过多会出现延迟
由于master需要进行常规维护停机了,那么必须要把一个slave提成master,选哪一个是一个问题?
某一个slave提成master了,就存在当前master和之前的master数据不一致的情况,并且之前master并没有保存当前master节点的binlog文件和pos位置。
多主复制架构
多主复制架构解决了一主多从复制架构中master的单点故障问题。
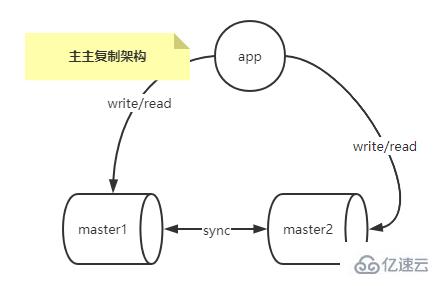
可以配合一个第三方的工具,比如keepalived轻松做到IP的漂移,这样master停机维护也不会影响写操作。
级联复制架构
一主多从中如果slave过多,会导致主库的I/O压力和网络压力会随着从库的增加而增长,因为每个从库都会在主库上有一个独立的BINLOG Dump线程来发送事件,而级联复制架构解决了一主多从场景下的,主库额外的I/O和网络压力。
如下图所示。
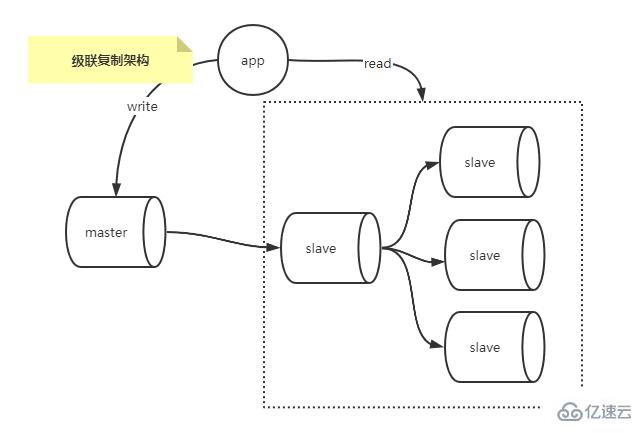
对比一主多从的架构,级联复制仅仅是从主库Master复制到少量的从库,其他从库再从这少量的从库中复制数据,这样就减轻了主库Master的压力。
当然也有缺点:MySQL的传统复制是异步的,级联复制场景下主库的数据是经历两次复制才到达其他从库中,期间的延迟要比一主多从复制场景下只经历一次复制的还大。
通过在二级从库上选择BLACKHOLE表引擎,可以降低级联复制的延迟。顾名思义,BLACKHOLE引擎是一个“黑洞”引擎,写入BLACKHOLE表的数据并不会写会到磁盘上,BLACKHOLE表永远都是空表,INSERT、UPDATE、DELETE操作仅仅在BINLOG中记录事件。
下面演示下BLACKHOLE引擎:
mysql> CREATE TABLE `user` (
-> `id` int NOT NULL AUTO_INCREMENT PRIMARY KEY,
-> `name` varchar(255) NOT NULL DEFAULT '',
-> `age` tinyint unsigned NOT NULL DEFAULT 0
-> )ENGINE=BLACKHOLE charset=utf8mb4;Query OK, 0 rows affected (0.00 sec)mysql> INSERT INTO `user` (`name`,`age`) values("itbsl", "26");Query OK, 1 row affected (0.00 sec)mysql> select * from user;Empty set (0.00 sec)可以看到,存储引擎为BLACKHOLE的user表里没有数据。
多主与级联复制结合架构
结合多主与级联复制架构,这样解决了单点master的问题,解决了slave级联延迟的问题。
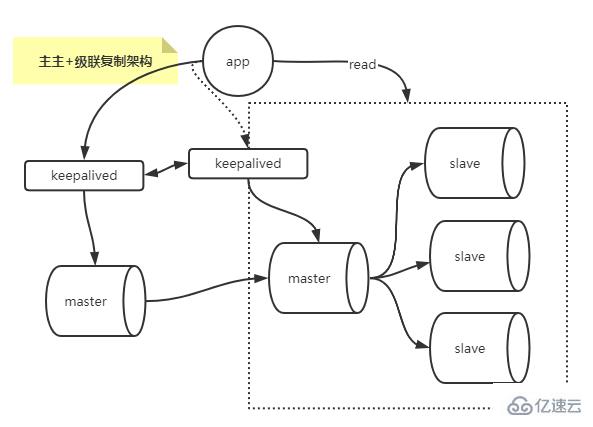
多主复制架构的搭建
主机规划:
master1:docker,端口3314
master2:docker,端口3315
master1的配置
配置文件my.cnf:
$ cat /home/mysql/docker-data/3315/conf/my.cnf [mysqld] character_set_server=utf8 init_connect='SET NAMES utf8' symbolic-links=0 lower_case_table_names=1 server-id=1403314 log-bin=mysql-bin binlog-format=ROW auto_increment_increment=2 # 几个主库,这里就配几 auto_increment_offset=1 # 每个主库的偏移量需要不一致 gtid_mode=ON enforce-gtid-consistency=true binlog-do-db=order # 要同步的数据库
启动docker:
$ docker run --name mysql3314 -p 3314:3306 --privileged=true -ti -e MYSQL_ROOT_PASSWORD=root -e MYSQL_DATABASE=order -e MYSQL_USER=user -e MYSQL_PASSWORD=pass -v /home/mysql/docker-data/3314/conf:/etc/mysql/conf.d -v /home/mysql/docker-data/3314/data/:/var/lib/mysql -v /home/mysql/docker-data/3314/logs/:/var/log/mysql -d mysql:5.7
添加用于复制的用户并授权:
mysql> GRANT REPLICATION SLAVE,FILE,REPLICATION CLIENT ON *.* TO 'repluser'@'%' IDENTIFIED BY '123456'; Query OK, 0 rows affected, 1 warning (0.01 sec) mysql> FLUSH PRIVILEGES; Query OK, 0 rows affected (0.01 sec)
开启同步master1(这里的user来自master2):
mysql> change master to master_host='172.23.252.98',master_port=3315,master_user='repluser',master_password='123456',master_auto_position=1; Query OK, 0 rows affected, 2 warnings (0.03 sec) mysql> start slave; Query OK, 0 rows affected (0.00 sec)
master2的配置
master2的配置与master1类似。
主要区别在于my.cnf中有一个属性需要不一致:
auto_increment_offset=2 # 每个主库的偏移量需要不一致
测试:
在master2创建表,并添加数据:
mysql> create table t_order(id int primary key auto_increment, name varchar(20));
Query OK, 0 rows affected (0.01 sec)
mysql> insert into t_order(name) values("A");
Query OK, 1 row affected (0.01 sec)
mysql> insert into t_order(name) values("B");
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
+----+------+
2 rows in set (0.00 sec)可以发现master2中id的步长为2,且从2开始自增。
然后在master1查询数据,并添加:
mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
+----+------+
2 rows in set (0.00 sec)
mysql> insert into t_order(name) values("E");
Query OK, 1 row affected (0.00 sec)
mysql> select * from t_order;
+----+------+
| id | name |
+----+------+
| 2 | A |
| 4 | B |
| 5 | E |
+----+------+
3 rows in set (0.00 sec)可以发现master1中id的步长为2,且从1开始自增,再去master2中查询能发现id为5的数据,说明主主复制配置没有问题。
为什么两个主中id自增的偏移量要不一致呢?当两个主同时接受到插入请求时就能保证id不冲突,其实这样只能保证插入数据不冲突,无法保证删除和修改导致的数据不一致。
所以在实际的应用场景中,只能暴露一个主给客户端才能保证数据的一致性。
MySQL高可用的搭建
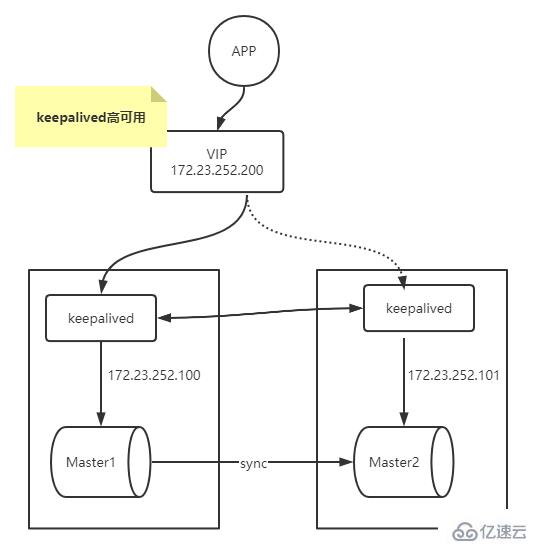
这里借助keepalived来对上面的多主复制架构改造来实现MySQL的高可用。
keepalived的安装:
$ sudo apt-get install -y keepalived
keepalived.conf
$ cat /etc/keepalived/keepalived3314.conf! Configuration File for keepalived#简单的头部,这里主要可以做邮件通知报警等的设置,此处就暂不配置了;global_defs {
#notificationd LVS_DEVEL}#预先定义一个脚本,方便后面调用,也可以定义多个,方便选择;vrrp_script chk_haproxy {
script "/etc/keepalived/chkmysql.sh" #具体脚本路径
interval 2 #脚本循环运行间隔}#VRRP虚拟路由冗余协议配置vrrp_instance VI_1 { #VI_1 是自定义的名称;
state BACKUP #MASTER表示是一台主设备,BACKUP表示为备用设备【我们这里因为设置为开启不抢占,所以都设置为备用】
nopreempt #开启不抢占
interface eth0 #指定VIP需要绑定的物理网卡
virtual_router_id 11 #VRID虚拟路由标识,也叫做分组名称,该组内的设备需要相同
priority 130 #定义这台设备的优先级 1-254;开启了不抢占,所以此处优先级必须高于另一台
advert_int 1 #生存检测时的组播信息发送间隔,组内一致
authentication { #设置验证信息,组内一致
auth_type PASS #有PASS 和 AH 两种,常用 PASS
auth_pass asd #密码
}
virtual_ipaddress {
172.23.252.200 #指定VIP地址,组内一致,可以设置多个IP
}
track_script { #使用在这个域中使用预先定义的脚本,上面定义的
chk_haproxy }
#notify_backup "/etc/init.d/haproxy restart" #表示当切换到backup状态时,要执行的脚本
#notify_fault "/etc/init.d/haproxy stop" #故障时执行的脚本}/etc/keepalived/chkmysql.sh
$ cat /etc/keepalived/chkmysql.s.sh#!/bin/bashmysql -uroot -proot -P 3314 -e "show status;" > /dev/null 2>&1if [ $? == 0 ];then
echo "$host mysql login successfully"
exit 0else
echo "$host login failed"
killall keepalived exit 2fi以上是怎么掌握MySQL复制架构的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 MySQL的角色:Web应用程序中的数据库
Apr 17, 2025 am 12:23 AM
MySQL的角色:Web应用程序中的数据库
Apr 17, 2025 am 12:23 AM
MySQL在Web应用中的主要作用是存储和管理数据。1.MySQL高效处理用户信息、产品目录和交易记录等数据。2.通过SQL查询,开发者能从数据库提取信息生成动态内容。3.MySQL基于客户端-服务器模型工作,确保查询速度可接受。
 laravel入门实例
Apr 18, 2025 pm 12:45 PM
laravel入门实例
Apr 18, 2025 pm 12:45 PM
Laravel 是一款 PHP 框架,用于轻松构建 Web 应用程序。它提供一系列强大的功能,包括:安装: 使用 Composer 全局安装 Laravel CLI,并在项目目录中创建应用程序。路由: 在 routes/web.php 中定义 URL 和处理函数之间的关系。视图: 在 resources/views 中创建视图以呈现应用程序的界面。数据库集成: 提供与 MySQL 等数据库的开箱即用集成,并使用迁移来创建和修改表。模型和控制器: 模型表示数据库实体,控制器处理 HTTP 请求。
 docker怎么启动mysql
Apr 15, 2025 pm 12:09 PM
docker怎么启动mysql
Apr 15, 2025 pm 12:09 PM
在 Docker 中启动 MySQL 的过程包含以下步骤:拉取 MySQL 镜像创建并启动容器,设置根用户密码并映射端口验证连接创建数据库和用户授予对数据库的所有权限
 解决数据库连接问题:使用minii/db库的实际案例
Apr 18, 2025 am 07:09 AM
解决数据库连接问题:使用minii/db库的实际案例
Apr 18, 2025 am 07:09 AM
在开发一个小型应用时,我遇到了一个棘手的问题:需要快速集成一个轻量级的数据库操作库。尝试了多个库后,我发现它们要么功能过多,要么兼容性不佳。最终,我找到了minii/db,这是一个基于Yii2的简化版本,完美地解决了我的问题。
 centos7如何安装mysql
Apr 14, 2025 pm 08:30 PM
centos7如何安装mysql
Apr 14, 2025 pm 08:30 PM
优雅安装 MySQL 的关键在于添加 MySQL 官方仓库。具体步骤如下:下载 MySQL 官方 GPG 密钥,防止钓鱼攻击。添加 MySQL 仓库文件:rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm更新 yum 仓库缓存:yum update安装 MySQL:yum install mysql-server启动 MySQL 服务:systemctl start mysqld设置开机自启动
 centos安装mysql
Apr 14, 2025 pm 08:09 PM
centos安装mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安装 MySQL 涉及以下步骤:添加合适的 MySQL yum 源。执行 yum install mysql-server 命令以安装 MySQL 服务器。使用 mysql_secure_installation 命令进行安全设置,例如设置 root 用户密码。根据需要自定义 MySQL 配置文件。调整 MySQL 参数和优化数据库以提升性能。
 laravel框架安装方法
Apr 18, 2025 pm 12:54 PM
laravel框架安装方法
Apr 18, 2025 pm 12:54 PM
文章摘要:本文提供了详细分步说明,指导读者如何轻松安装 Laravel 框架。Laravel 是一个功能强大的 PHP 框架,它 упростил 和加快了 web 应用程序的开发过程。本教程涵盖了从系统要求到配置数据库和设置路由等各个方面的安装过程。通过遵循这些步骤,读者可以快速高效地为他们的 Laravel 项目打下坚实的基础。
 MySQL和PhpMyAdmin:核心功能和功能
Apr 22, 2025 am 12:12 AM
MySQL和PhpMyAdmin:核心功能和功能
Apr 22, 2025 am 12:12 AM
MySQL和phpMyAdmin是强大的数据库管理工具。1)MySQL用于创建数据库和表、执行DML和SQL查询。2)phpMyAdmin提供直观界面进行数据库管理、表结构管理、数据操作和用户权限管理。
