

MySQL中join语句如何优化

Simple Nested-Loop Join
我们来看一下当进行 join 操作时,mysql是如何工作的。常见的 join 方式有哪些?
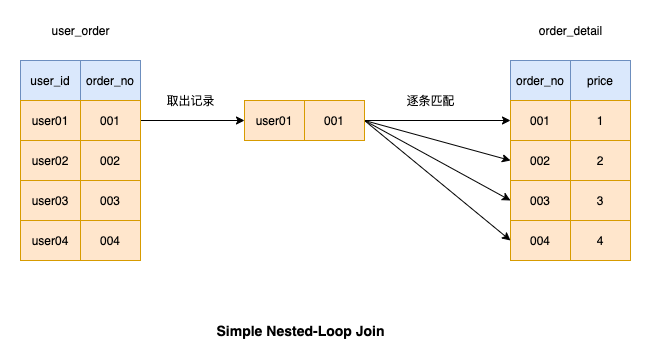
如图,当我们进行连接操作时,左边的表是驱动表,右边的表是被驱动表
Simple Nested-Loop Join 这种连接操作是从驱动表中取出一条记录然后逐条匹配被驱动表的记录,如果条件匹配则将结果返回。接着,继续匹配驱动表的下一条记录,直到驱动表的所有数据都被匹配完
因为每次从驱动表取数据比较耗时,所以MySQL并没有采用这种算法来进行连接操作
Block Nested-Loop Join
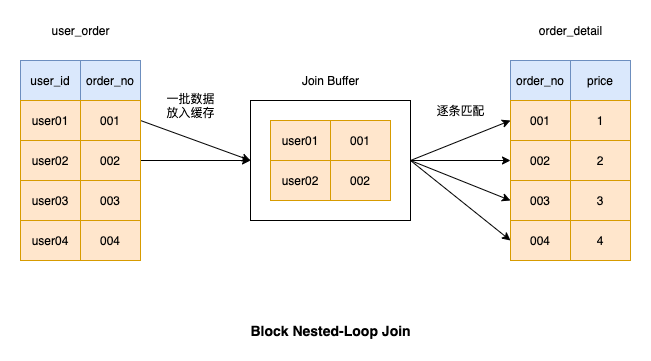
为了避免每次从驱动表取数据耗时,我们可以将一批数据一次性从驱动表取出,并在内存中进行匹配操作。这批数据匹配完毕,再从驱动表中取一批数据放到内存中,直到驱动表的数据全都匹配完毕
批量取数据能减少很多IO操作,因此执行效率比较高,这种连接操作也被MySQL采用
对了,这块内存在MySQ中有一个专有的名词,叫做 join buffer,我们可以执行如下语句查看 join buffer 的大小
show variables like '%join_buffer%'

把我们之前用的 single_table 表搬出来,基于 single_table 表创建2个表,每个表插入1w条随机记录
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
create table t1 like single_table;
create table t2 like single_table;如果直接使用 join 语句,MySQL优化器可能会选择表 t1 或者 t2 作为驱动表,这样会影响我们分析sql语句的过程,所以我们用 straight_join 让mysql使用固定的连接方式执行查询
select * from t1 straight_join t2 on (t1.common_field = t2.common_field)
运行时间为0.035s

执行计划如下

在Extra列中看到了 Using join buffer ,说明连接操作是基于 Block Nested-Loop Join 算法
Index Nested-Loop Join
了解了 Block Nested-Loop Join 算法之后,可以看到驱动表的每条记录会把被驱动表的所有记录都匹配一遍,非常耗时,能不能提高一下被驱动表匹配的效率呢?
估计这种算法你也想到了,就是给被驱动表连接的列加上索引,这样匹配的过程就非常快,如图所示
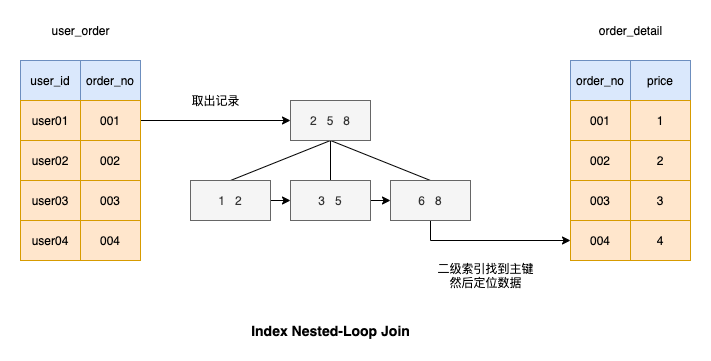
我们来看一下基于索引列进行连接执行查询有多快?
select * from t1 straight_join t2 on (t1.id = t2.id)
执行时间为0.001秒,可以看到比基于普通的列进行连接快了不止一个档次

执行计划如下

驱动表的记录并不是所有列都会被放到 join buffer,只有查询列表中的列和过滤条件中的列才会被放入 join buffer,因此我们不要把 * 作为查询列表,只需要把我们关心的列放到查询列表就好了,这样可以在 join buffer 中放置更多的记录
如何选择驱动表?
知道了 join 的具体实现,我们来聊一个常见的问题,即如何选择驱动表?
如果是 Block Nested-Loop Join 算法:
当 join buffer 足够大时,谁做驱动表没有影响
当 join buffer 不够大时,应该选择小表做驱动表(小表数据量少,放入 join buffer 的次数少,减少表的扫描次数)
如果是 Index Nested-Loop Join 算法
假设驱动表的行数是M,因此需要扫描驱动表M行
每次从被驱动表中获取一行数据时,需要先查找索引a,然后再查找主键索引。被驱动表的行数为N。每次搜索一颗树近似复杂度是以2为底N的对数,所以在被驱动表上查一行的时间复杂度是 2 ∗ l o g 2 N 2*log2^N 2∗log2N
驱动表的每一行数据都要到被驱动表上搜索一次,整个执行过程近似复杂度为 M + M ∗ 2 ∗ l o g 2 N M + M*2*log2^N M+M∗2∗log2N
显然M对扫描行数影响更大,因此应该让小表做驱动表。当然这个结论的前提是可以使用被驱动表的索引
总而言之,我们让小表做驱动表即可
当 join 语句执行的比较慢时,我们可以通过如下方法来进行优化
进行连接操作时,能使用被驱动表的索引
小表做驱动表
增大 join buffer 的大小
不要用 * 作为查询列表,只返回需要的列
以上是MySQL中join语句如何优化的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 MySQL:初学者的数据管理易用性
Apr 09, 2025 am 12:07 AM
MySQL:初学者的数据管理易用性
Apr 09, 2025 am 12:07 AM
MySQL适合初学者使用,因为它安装简单、功能强大且易于管理数据。1.安装和配置简单,适用于多种操作系统。2.支持基本操作如创建数据库和表、插入、查询、更新和删除数据。3.提供高级功能如JOIN操作和子查询。4.可以通过索引、查询优化和分表分区来提升性能。5.支持备份、恢复和安全措施,确保数据的安全和一致性。
 忘记数据库密码,能在Navicat中找回吗?
Apr 08, 2025 pm 09:51 PM
忘记数据库密码,能在Navicat中找回吗?
Apr 08, 2025 pm 09:51 PM
Navicat本身不存储数据库密码,只能找回加密后的密码。解决办法:1. 检查密码管理器;2. 检查Navicat的“记住密码”功能;3. 重置数据库密码;4. 联系数据库管理员。
 navicat premium怎么创建
Apr 09, 2025 am 07:09 AM
navicat premium怎么创建
Apr 09, 2025 am 07:09 AM
使用 Navicat Premium 创建数据库:连接到数据库服务器并输入连接参数。右键单击服务器并选择“创建数据库”。输入新数据库的名称和指定字符集和排序规则。连接到新数据库并在“对象浏览器”中创建表。右键单击表并选择“插入数据”来插入数据。
 mysql:简单的概念,用于轻松学习
Apr 10, 2025 am 09:29 AM
mysql:简单的概念,用于轻松学习
Apr 10, 2025 am 09:29 AM
MySQL是一个开源的关系型数据库管理系统。1)创建数据库和表:使用CREATEDATABASE和CREATETABLE命令。2)基本操作:INSERT、UPDATE、DELETE和SELECT。3)高级操作:JOIN、子查询和事务处理。4)调试技巧:检查语法、数据类型和权限。5)优化建议:使用索引、避免SELECT*和使用事务。
 MySQL和SQL:开发人员的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL:开发人员的基本技能
Apr 10, 2025 am 09:30 AM
MySQL和SQL是开发者必备技能。1.MySQL是开源的关系型数据库管理系统,SQL是用于管理和操作数据库的标准语言。2.MySQL通过高效的数据存储和检索功能支持多种存储引擎,SQL通过简单语句完成复杂数据操作。3.使用示例包括基本查询和高级查询,如按条件过滤和排序。4.常见错误包括语法错误和性能问题,可通过检查SQL语句和使用EXPLAIN命令优化。5.性能优化技巧包括使用索引、避免全表扫描、优化JOIN操作和提升代码可读性。
 navicat怎么新建连接mysql
Apr 09, 2025 am 07:21 AM
navicat怎么新建连接mysql
Apr 09, 2025 am 07:21 AM
可在 Navicat 中通过以下步骤新建 MySQL 连接:打开应用程序并选择“新建连接”(Ctrl N)。选择“MySQL”作为连接类型。输入主机名/IP 地址、端口、用户名和密码。(可选)配置高级选项。保存连接并输入连接名称。
 phpmyadmin怎么打开
Apr 10, 2025 pm 10:51 PM
phpmyadmin怎么打开
Apr 10, 2025 pm 10:51 PM
可以通过以下步骤打开 phpMyAdmin:1. 登录网站控制面板;2. 找到并点击 phpMyAdmin 图标;3. 输入 MySQL 凭据;4. 点击 "登录"。
 navicat如何执行sql
Apr 08, 2025 pm 11:42 PM
navicat如何执行sql
Apr 08, 2025 pm 11:42 PM
在 Navicat 中执行 SQL 的步骤:连接到数据库。创建 SQL 编辑器窗口。编写 SQL 查询或脚本。单击“运行”按钮执行查询或脚本。查看结果(如果执行查询的话)。
