

Redis怎么让Spark提速

Apache Spark is increasingly becoming a model for next-generation big data processing tools.。通过借鉴开源算法,并将处理任务分布到计算节点集群上,无论在它们在单一平台上所能执行的数据分析类型方面,还是在执行这些任务的速度方面,Spark和Hadoop这一代框架都轻松胜过传统框架。Spark利用内存来处理数据,因而速度比基于磁盘的Hadoop大幅加快(快100倍)。
但是如果得到一点帮助,Spark可以运行得还要快。如果结合Spark和Redis(流行的内存数据结构存储技术),你可以再次大幅提升处理分析任务的性能。这归功于Redis经过优化的数据结构,以及它在执行操作时,能够尽量降低复杂性和开销。使用连接器连接到Redis的数据结构和API能够进一步加快Spark的速度。
提速幅度有多大?如果Redis和Spark结合使用,结果证明,处理数据(以便分析下面描述的时间序列数据)的速度比Spark单单使用进程内存或堆外缓存来存储数据要快45倍――不是快45%,而是快整整45倍!
分析交易速度的重要性日益逐渐增长,因为许多公司需要实现与业务交易速度同等快速的分析。越来越多的决策变得自动化,驱动这些决策所需的分析应该实时进行。Apache Spark是一种出色的通用数据处理框架;虽然它并非***实时,还是往更及时地让数据发挥用途迈出了一大步。
Spark使用弹性分布式数据集(RDD),这些数据集可以存储在易失性内存中或HDFS之类的持久性存储系统中。所有分布在Spark集群的节点上的RDD都保持不变,但可以通过转换操作创建其他RDD。
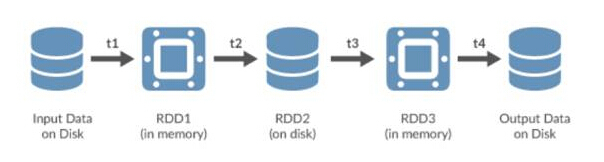
Spark RDD
RDD是Spark中的重要抽象对象。它们代表了一种高效地将数据呈现给迭代进程的容错方法。使用内存进行处理意味着相较于使用HDFS和MapReduce,处理时间将减少若干数量级。
Redis是专门为高性能设计的。亚毫秒延迟得益于经过优化的数据结构,由于让操作可以在邻近数据存储的地方执行,提高了效率。这种数据结构不仅可以高效地利用内存、降低应用程序的复杂性,还降低了网络开销、带宽消耗量和处理时间。Redis支持多个数据结构,其中包括字符串、集合、有序集合、哈希、位图、hyperloglog和地理空间索引。Redis数据结构就像乐高积木一样,为开发人员提供了简单的通道来实现复杂功能。
为了直观地表明这种数据结构如何简化应用程序的处理时间和复杂性,我们不妨以有序集合(Sorted Set)数据结构为例。有序集合基本上是一组按分数排序的成员。

Redis有序集合
你可以将多种类型的数据存储在这里,它们自动由分数来排序。存储在有序集合中的常见数据类型包括:物品(按价格)、商品名称(按数量)、股价等时间序列数据,以及时间戳等传感器读数。
有序集合的魅力在于Redis的内置操作,让范围查询、多个有序集合交叉、按成员等级和分数检索及更多事务可以简单地执行,具有***的速度,还可以大规模执行。内置操作不仅节省了需要编写的代码,内存中执行操作还缩短了网络延迟、节省了带宽,因而能够实现亚毫秒延迟的高吞吐量。如果将有序集合用于分析时间序列数据,相比其他内存键/值存储系统或基于磁盘的数据库,通常可以将性能提升好几个数量级。
Spark-Redis连接件是为了提高Spark的分析能力而由Redis团队开发的。这个程序包让Spark得以使用Redis作为其数据源之一。通过该连接件,Spark可以直接访问Redis的数据结构,从而显著提高各种类型的分析性能。

Spark Redis连接件
为了展示给Spark带来的好处,Redis团队决定在几种不同的场景下执行时间片(范围)查询,以此横向比较Spark中的时间序列分析。这几种场景包括:Spark在堆内内存中存储所有数据,Spark使用Tachyon作为堆外缓存,Spark使用HDFS,以及结合使用Spark和Redis。
Redis团队使用Cloudera的Spark时间序列程序包,构建了一个Spark-Redis时间序列程序包,使用Redis有序集合来加快时间序列分析。该软件包除了提供让Spark能够访问Redis的全部数据结构,还执行了两项附加任务
自动确保Redis节点与Spark集群一致,从而确保每个Spark节点使用本地Redis数据,因而优化延迟。
与Spark数据帧和数据源API整合起来,以便自动将Spark SQL查询转换成对Redis中的数据来说***效的那种检索机制。
简单地说,这意味着用户不必担心Spark和Redis之间的操作一致性,可以继续使用Spark SQL来分析,同时大大提升了查询性能。
在此横向比较中所使用的时间序列数据包括:随机生成的金融数据以及32年内每天的1024支股票。每只股票由各自的有序集合来表示,分数是日期,数据成员包括开盘价、***价、***价、收盘价、成交量以及调整后的收盘价。The following image depicts the data representation in a Redis sorted set used for Spark analysis:
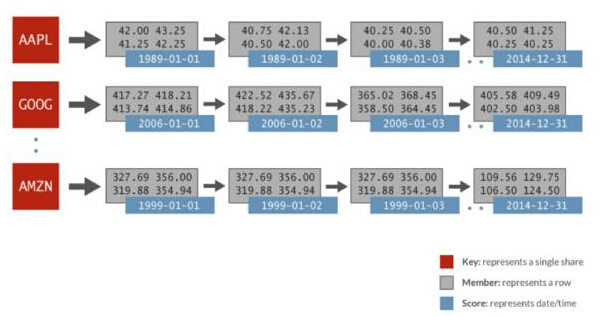
Spark Redis时间序列
在上述例子中,就有序集合AAPL而言,有表示每天(1989-01-01)的分数,还有全天中表示为一个相关行的多个值。只要在Redis中使用一个简单的ZRANGEBYSCORE命令,就可以执行这一操作:获取某个时间片的所有值,因而获得指定的日期范围内的所有股价。Redis可以比其他键/值存储系统更快地执行这类查询,速度可以快100倍。
这番横向比较证实了性能提升。结果发现,Spark使用Redis执行时间片查询的速度比Spark使用HDFS快135倍,比Spark使用堆内(进程)内存或Spark使用Tachyon作为堆外缓存快45倍。下图显示了针对不同场景所比较的平均执行时间:
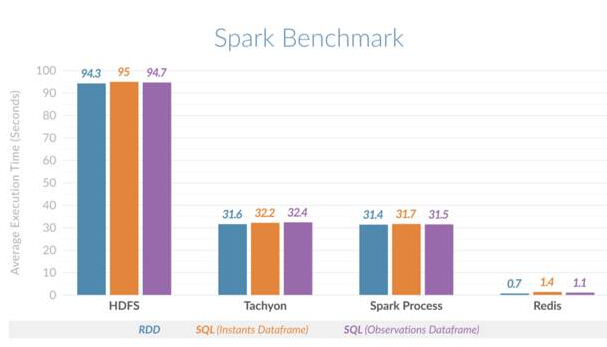
Spark Redis横向比较
这个指南会步步引导你安装标准的Spark集群和Spark-Redis套件。通过一个简单的单词计数示例,它演示了如何集成Spark和Redis的使用。你在试用过Spark和Spark-Redis程序包后,可以进一步探究利用其他Redis数据结构的更多场景。
虽然有序集合很适合时间序列数据,但Redis的其他数据结构(比如集合、列表和地理空间索引)可以进一步丰富Spark分析。想象一下:一个Spark进程正在尝试获取有哪些地区适合发布新产品,考虑人群偏好以及离市中心的距离等因素来优化发布效果。想象一下,具有内置分析功能的数据结构(如地理空间索引和集合)可以显著加快该过程。Spark-Redis这对组合拥有***的应用前景。
Spark提供广泛的分析能力,包括SQL、机器学习、图形计算和Spark Streaming。使用Spark的内存处理功能只能让你达到一定的规模。然而有了Redis后,你可以更进一步:不仅可以通过利用Redis的数据结构来提升性能,还可以更轻松自如地扩展Spark,即通过充分利用Redis提供的共享分布式内存数据存储机制,处理数百万个记录,乃至数十亿个记录。
时间序列这个例子只是开了个头。将Redis数据结构用于机器学习和图形分析同样有望为这些工作负载带来执行时间大幅缩短的好处。
以上是Redis怎么让Spark提速的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
redis集群模式怎么搭建
Apr 10, 2025 pm 10:15 PM
Redis集群模式通过分片将Redis实例部署到多个服务器,提高可扩展性和可用性。搭建步骤如下:创建奇数个Redis实例,端口不同;创建3个sentinel实例,监控Redis实例并进行故障转移;配置sentinel配置文件,添加监控Redis实例信息和故障转移设置;配置Redis实例配置文件,启用集群模式并指定集群信息文件路径;创建nodes.conf文件,包含各Redis实例的信息;启动集群,执行create命令创建集群并指定副本数量;登录集群执行CLUSTER INFO命令验证集群状态;使
 redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
redis怎么读取队列
Apr 10, 2025 pm 10:12 PM
要从 Redis 读取队列,需要获取队列名称、使用 LPOP 命令读取元素,并处理空队列。具体步骤如下:获取队列名称:以 "queue:" 前缀命名,如 "queue:my-queue"。使用 LPOP 命令:从队列头部弹出元素并返回其值,如 LPOP queue:my-queue。处理空队列:如果队列为空,LPOP 返回 nil,可先检查队列是否存在再读取元素。
 redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
redis数据怎么清空
Apr 10, 2025 pm 10:06 PM
如何清空 Redis 数据:使用 FLUSHALL 命令清除所有键值。使用 FLUSHDB 命令清除当前选定数据库的键值。使用 SELECT 切换数据库,再使用 FLUSHDB 清除多个数据库。使用 DEL 命令删除特定键。使用 redis-cli 工具清空数据。
 centos redis如何配置Lua脚本执行时间
Apr 14, 2025 pm 02:12 PM
centos redis如何配置Lua脚本执行时间
Apr 14, 2025 pm 02:12 PM
在CentOS系统上,您可以通过修改Redis配置文件或使用Redis命令来限制Lua脚本的执行时间,从而防止恶意脚本占用过多资源。方法一:修改Redis配置文件定位Redis配置文件:Redis配置文件通常位于/etc/redis/redis.conf。编辑配置文件:使用文本编辑器(例如vi或nano)打开配置文件:sudovi/etc/redis/redis.conf设置Lua脚本执行时间限制:在配置文件中添加或修改以下行,设置Lua脚本的最大执行时间(单位:毫秒)
 redis命令行怎么用
Apr 10, 2025 pm 10:18 PM
redis命令行怎么用
Apr 10, 2025 pm 10:18 PM
使用 Redis 命令行工具 (redis-cli) 可通过以下步骤管理和操作 Redis:连接到服务器,指定地址和端口。使用命令名称和参数向服务器发送命令。使用 HELP 命令查看特定命令的帮助信息。使用 QUIT 命令退出命令行工具。
 redis过期策略怎么设置
Apr 10, 2025 pm 10:03 PM
redis过期策略怎么设置
Apr 10, 2025 pm 10:03 PM
Redis数据过期策略有两种:定期删除:定期扫描删除过期键,可通过 expired-time-cap-remove-count、expired-time-cap-remove-delay 参数设置。惰性删除:仅在读取或写入键时检查删除过期键,可通过 lazyfree-lazy-eviction、lazyfree-lazy-expire、lazyfree-lazy-user-del 参数设置。
 如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系统中,readdir系统调用用于读取目录内容。如果其性能表现不佳,可尝试以下优化策略:精简目录文件数量:尽可能将大型目录拆分成多个小型目录,降低每次readdir调用处理的项目数量。启用目录内容缓存:构建缓存机制,定期或在目录内容变更时更新缓存,减少对readdir的频繁调用。内存缓存(如Memcached或Redis)或本地缓存(如文件或数据库)均可考虑。采用高效数据结构:如果自行实现目录遍历,选择更高效的数据结构(例如哈希表而非线性搜索)存储和访问目录信
 redis计数器怎么实现
Apr 10, 2025 pm 10:21 PM
redis计数器怎么实现
Apr 10, 2025 pm 10:21 PM
Redis计数器是一种使用Redis键值对存储来实现计数操作的机制,包含以下步骤:创建计数器键、增加计数、减少计数、重置计数和获取计数。Redis计数器的优势包括速度快、高并发、持久性和简单易用。它可用于用户访问计数、实时指标跟踪、游戏分数和排名以及订单处理计数等场景。
