

解决AI落地的最大障碍,OpenAI找到办法了?

OpenAI似乎找到了解决生成式人工智能“一本正经胡说八道”的办法。
5月31日,OpenAI在其官网宣布,已经训练了一个模型,能够有助于消除生成式AI常见的“幻觉”和其他常见问题。
OpenAI表示,可以训练奖励模型来检测幻觉,奖励模型又分为结果监督(根据最终结果提供反馈)或过程监督(为思维链中的每个步骤提供反馈)模型。
也就是说,过程监督奖励推理的每个正确步骤,而结果监督只是简单地奖励正确的答案。
OpenAI表示,相比之下,过程监督有一个重要的优势——它直接训练模型以产生由人类认可的思维链:
过程监督与结果监督相比有几个一致性优势。每个步骤都得到精确监督,因此它奖励遵循一致思维链模型的行为。
过程监督也更有可能产生可解释的推理,因为它鼓励模型遵循人类批准的过程
结果监督可能会奖励一个不一致的过程,而且通常更难审查。
OpenAI在数学数据集上测试了这两种模型,发现过程监督方法导致了“显著更好的性能”。
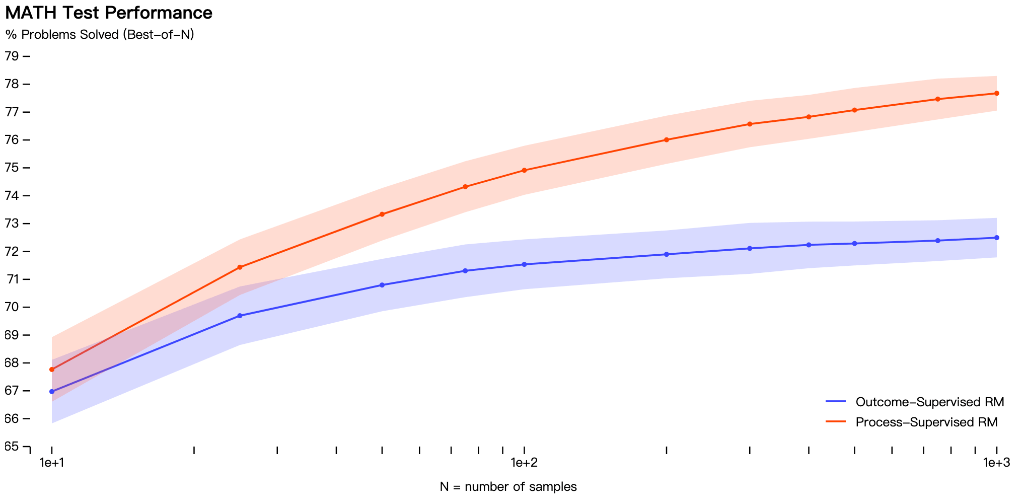
但需要注意的是,到目前为止,过程监督方法仅在数学领域进行了测试,并且需要更多的工作来观察它如何更普遍地执行。
此外,OpenAI没有说明这一研究需要多长时间才能应用在ChatGPT,它仍然处于研究阶段。
虽然最初的结果是好的,但OpenAI确实提到,更安全的方法会产生降低的性能,称为对齐税(alignment tax)。
目前的结果显示,在处理数学问题时,过程监督不会产生对齐税,但在一般的信息上的情况尚不知晓。
生成式AI的“幻觉”
生成式AI问世以来,围绕其编造虚假信息、“产生幻觉”的指控从未消失,这也是目前生成式AI模型最大的问题之一。
今年2月,谷歌为应对微软资助下ChatGPT,仓促推出了聊天机器人Bard,结果却被发现在演示中出现了常识性错误,导致谷歌股价大跌。
导致AI出现幻觉的原因有多种,输入数据欺骗AI程序进行错误分类是其中一种。
例如,开发人员使用数据(如图像、文本或其他类型)来训练人工智能系统,如果数据被改变或扭曲,应用程序将以不同的方式解释输入并产生不正确的结果。
幻觉可能会出现在像ChatGPT这样的基于语言的大型模型中,这是由于不正确的转换器解码,导致语言模型可能会产生一个没有不合逻辑或模糊的故事或叙述。
以上是解决AI落地的最大障碍,OpenAI找到办法了?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 最佳AI艺术生成器(免费付款)创意项目
Apr 02, 2025 pm 06:10 PM
最佳AI艺术生成器(免费付款)创意项目
Apr 02, 2025 pm 06:10 PM
本文回顾了AI最高的艺术生成器,讨论了他们的功能,对创意项目的适用性和价值。它重点介绍了Midjourney是专业人士的最佳价值,并建议使用Dall-E 2进行高质量的可定制艺术。
 开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础
 最佳AI聊天机器人比较(Chatgpt,Gemini,Claude&更多)
Apr 02, 2025 pm 06:09 PM
最佳AI聊天机器人比较(Chatgpt,Gemini,Claude&更多)
Apr 02, 2025 pm 06:09 PM
本文比较了诸如Chatgpt,Gemini和Claude之类的顶级AI聊天机器人,重点介绍了其独特功能,自定义选项以及自然语言处理和可靠性的性能。
 Chatgpt 4 o可用吗?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o可用吗?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4当前可用并广泛使用,与诸如ChatGpt 3.5(例如ChatGpt 3.5)相比,在理解上下文和产生连贯的响应方面取得了重大改进。未来的发展可能包括更多个性化的间
 顶级AI写作助理来增强您的内容创建
Apr 02, 2025 pm 06:11 PM
顶级AI写作助理来增强您的内容创建
Apr 02, 2025 pm 06:11 PM
文章讨论了Grammarly,Jasper,Copy.ai,Writesonic和Rytr等AI最高的写作助手,重点介绍了其独特的内容创建功能。它认为Jasper在SEO优化方面表现出色,而AI工具有助于保持音调的组成
 选择最佳的AI语音生成器:评论的顶级选项
Apr 02, 2025 pm 06:12 PM
选择最佳的AI语音生成器:评论的顶级选项
Apr 02, 2025 pm 06:12 PM
本文评论了Google Cloud,Amazon Polly,Microsoft Azure,IBM Watson和Discript等高级AI语音生成器,重点介绍其功能,语音质量和满足不同需求的适用性。
 构建AI代理的前7个代理抹布系统
Mar 31, 2025 pm 04:25 PM
构建AI代理的前7个代理抹布系统
Mar 31, 2025 pm 04:25 PM
2024年见证了从简单地使用LLM进行内容生成的转变,转变为了解其内部工作。 这种探索导致了AI代理的发现 - 自主系统处理任务和最少人工干预的决策。 Buildin
 AV字节:Meta' llama 3.2,Google的双子座1.5等
Apr 11, 2025 pm 12:01 PM
AV字节:Meta' llama 3.2,Google的双子座1.5等
Apr 11, 2025 pm 12:01 PM
本周的AI景观:进步,道德考虑和监管辩论的旋风。 OpenAI,Google,Meta和Microsoft等主要参与者已经释放了一系列更新,从开创性的新车型到LE的关键转变
