

阿里云大模型上新!AI神器「通义听悟」公测中:长视频一秒总结,还能自动做笔记、翻字幕 | 羊毛可薅

又一个接入大模型能力的组会神器实用工具,开启免费公测啦!
背后大模型,是阿里的通义千问。至于为什么说是组会神器嘛——
注意看,这是我的B站导师李沐老师,他正在带同学们精读一篇大模型论文。
不巧就在这时,老板催我抓紧搬砖。我只好默默摘下耳机,点开名为“通义听悟”的插件,然后切换页面。
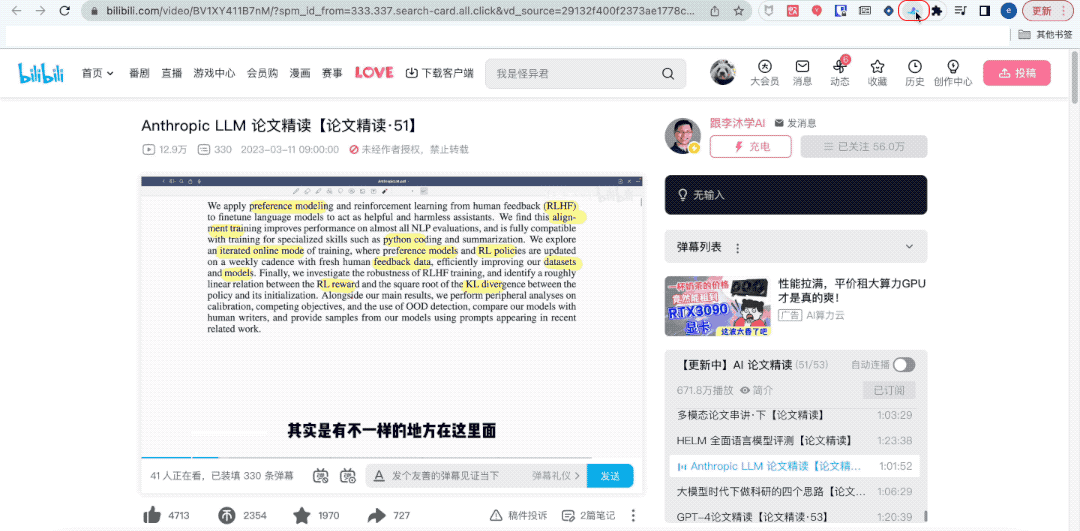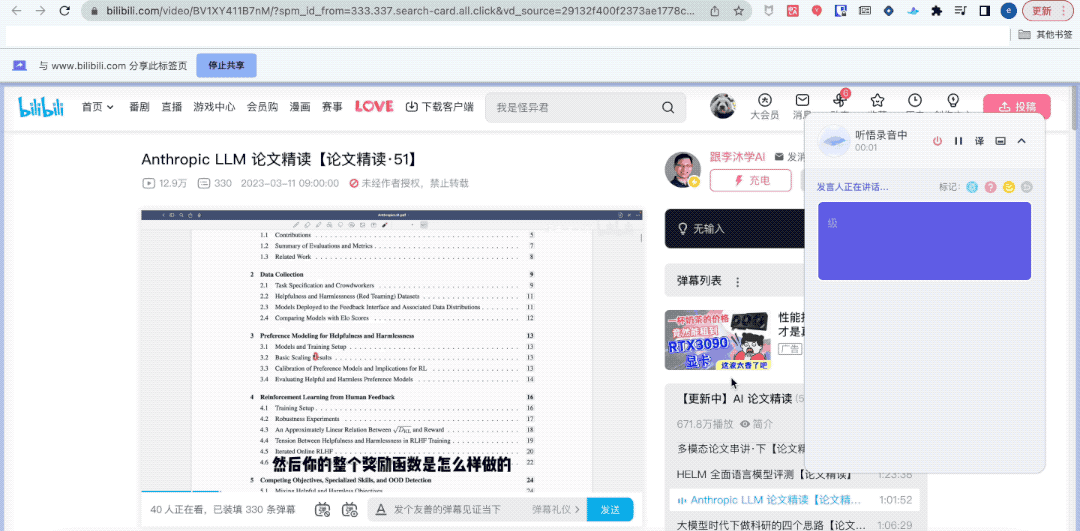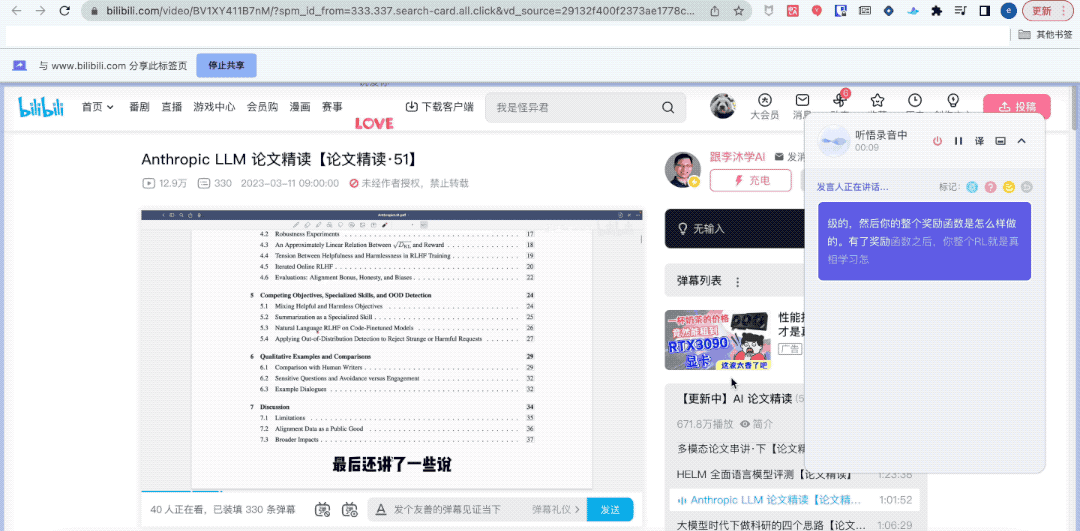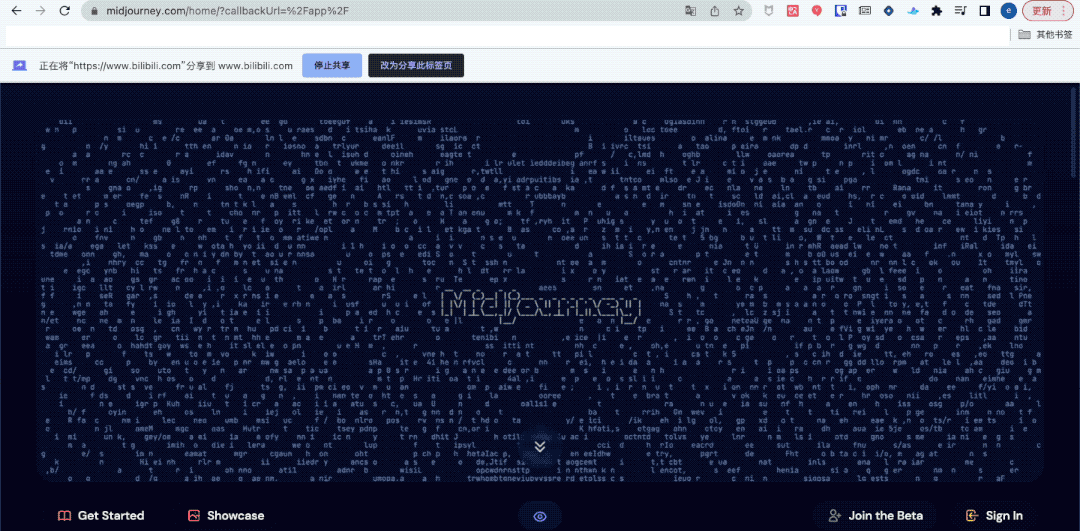
你猜怎么着?虽然我人不在“组会”现场,但听悟已经帮我完整记录下了组会内容。
甚至还帮我一键总结出了关键词、全文摘要和学习要点。

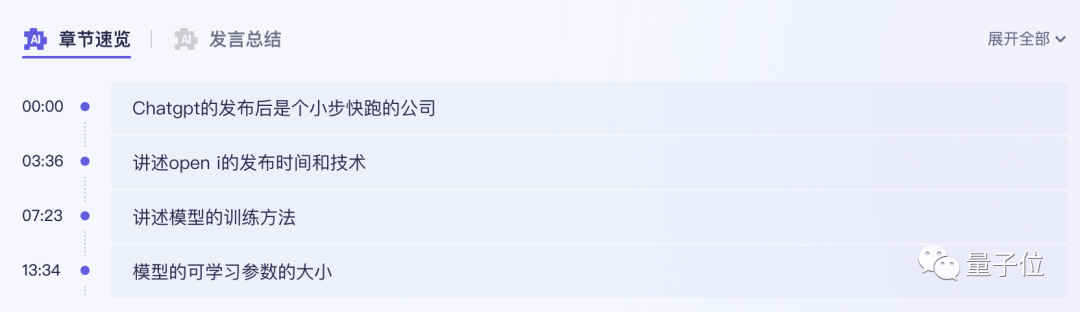
简单来说,这个刚刚接入大模型能力的“通义听悟”,是一个大模型版的聚焦音视频内容的工作学习AI助手。
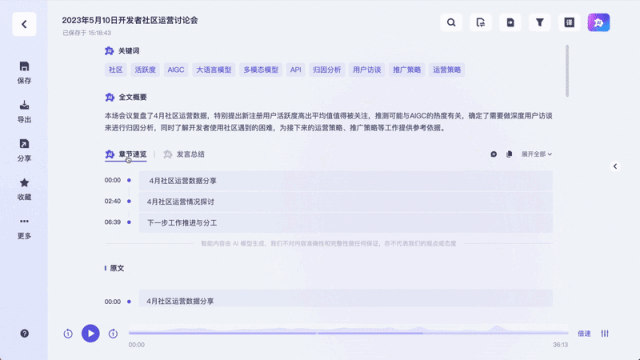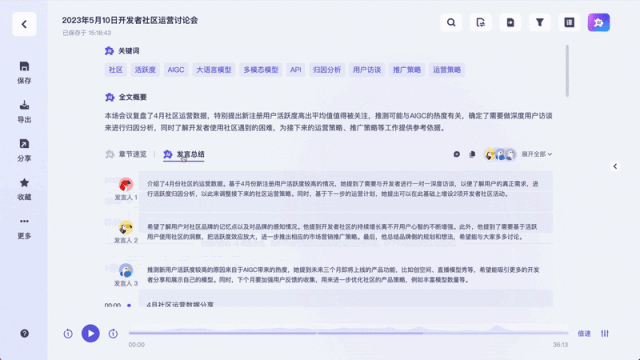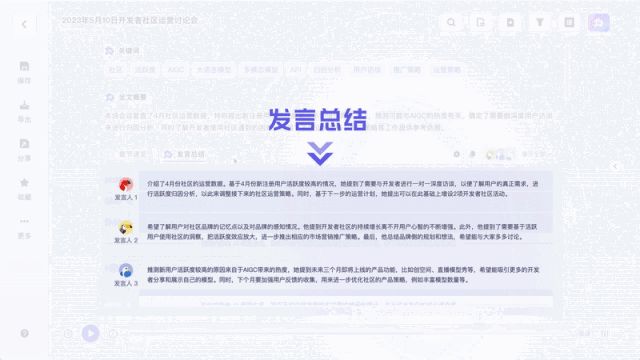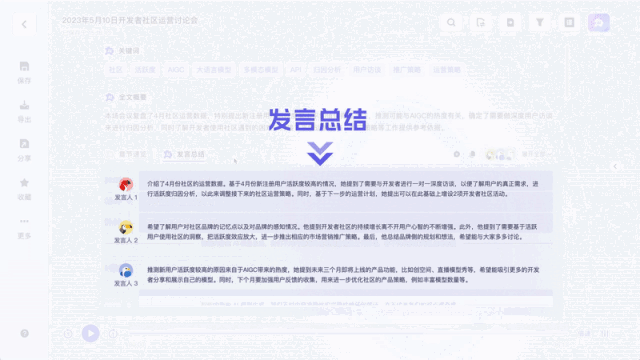
不同于以往的录音转写工具,它不仅能将录音和视频转化为文本。能一键总结全文不说,总结不同发言人观点也能做到:
甚至还能当实时字幕翻译来用:

看上去,不仅开组会好使,对于经常要处理一大堆录音、熬夜跟各种国外发布会的量子位来说,也实属日常工作新神器。
我们赶紧第一时间深入测试了一波。
通义听悟上手实测
音频内容的整理和分析,最基础也是最重要的,就是转写的准确性。
Round 1,我们先上传一个时长在10分钟左右的中文视频,看看听悟与同类工具相比,在准确性方面表现如何。
基本上,AI处理这种中等长度音视频的速度很快,大概不到2分钟就能转写完成。

先来看看听悟的表现:

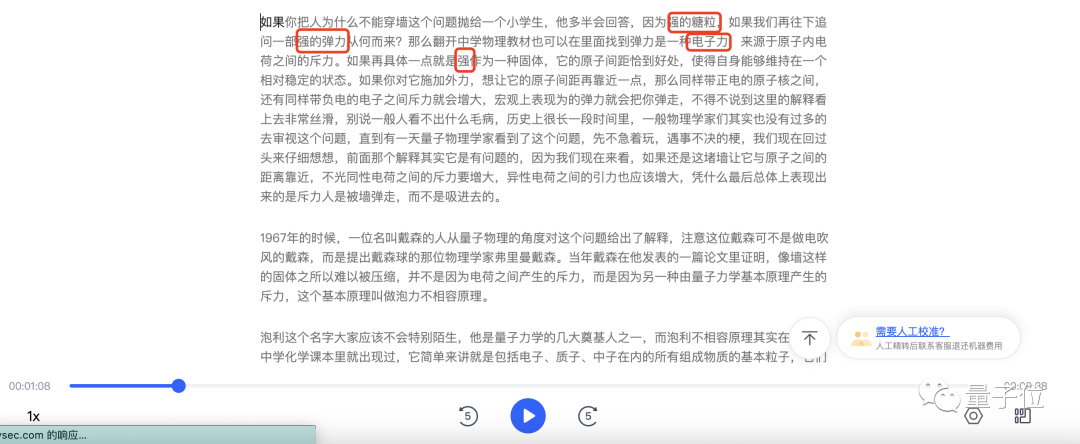
在这个200字左右的段落中,听悟只出现了两处错误:强 → 墙,都好处 → 恰到好处。像原子核、电荷、斥力这些物理名词,听悟都能弄明白。
我们用同一段视频在飞书妙记上也进行了测试。基本问题也不大,但相比听悟,飞书多了两处错误,把其中一处“原子”写成了“园子”,把“斥力”听成了“势力”。

有意思的是,听悟犯的错,飞书也一比一复刻了。看来这口锅还得量子位某说话吞字的up主来背(手动狗头)。
讯飞听见,倒是分辨出了前两位选手没有识别出来的“恰到好处”。但讯飞听见基本上把“墙”全部都转写成了“强”,还出现了“强的糖粒”这种神奇的搭配。另外,三位选手中,只有讯飞听见把“电磁力”听成了“电子力”。
总体来说,中文的识别对这些AI工具来说难度不大。那么在英文材料面前,它们又会表现如何?
我们上传了一段马斯克的最新访谈,内容是他与OpenAI过去的恩怨纠葛。
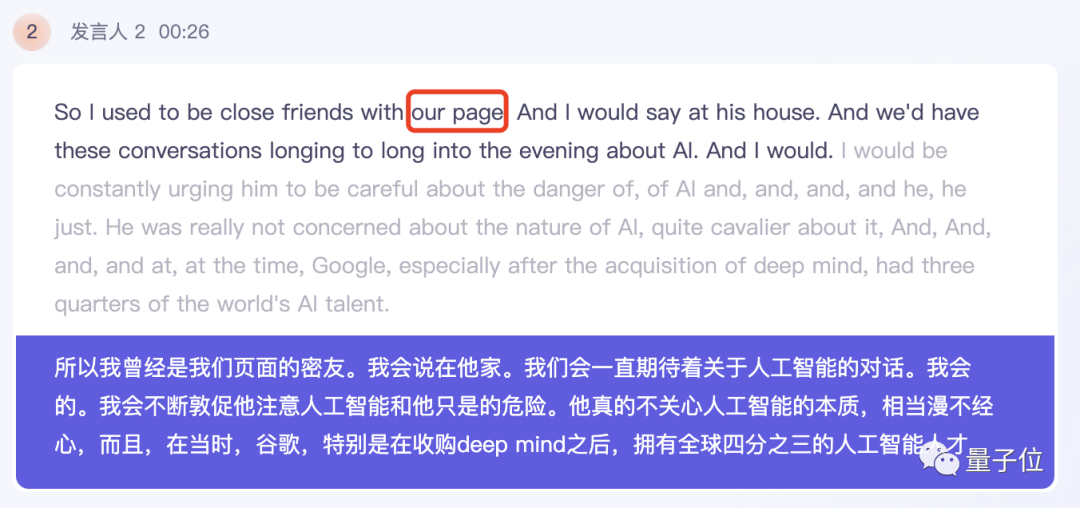
还是先来看听悟给出的结果。在马斯克的回答中,除了拉里·佩奇的名字,听悟基本上能正确识别其他所有人。
值得一提的是,听悟能够直接将英文转写结果翻译成中文,并将双语对照显示,翻译质量也相当不错。
飞书妙记则成功听出了拉里·佩奇的名字,不过和听悟一样,由于马斯克整体语速较快并且有一些口语化的表达,存在一些小错误,比如把“stay at his house”写成了“say this house”。

讯飞听见这边,人名、连读细节处理得都不错,不过同样存在被马斯克的口语化表达误导的情况,比如把“long into the evening”当成了“longing to the evening”。

如此看来,在基础能力语音识别方面,AI工具们都已经达到了很高的准确率,在极高的效率面前,一些小问题已经瑕不掩瑜。
那么,我们将难度再升一级,Round 2,来测试测试它们对1小时左右长视频的总结能力。
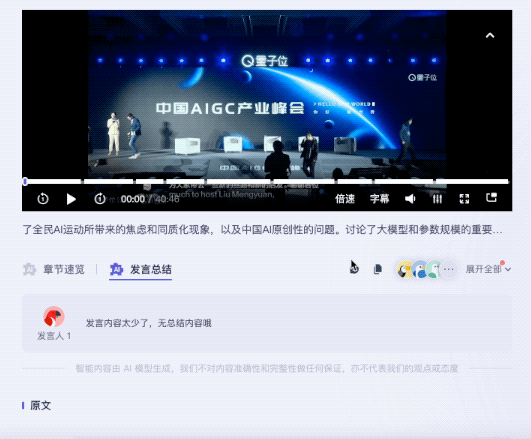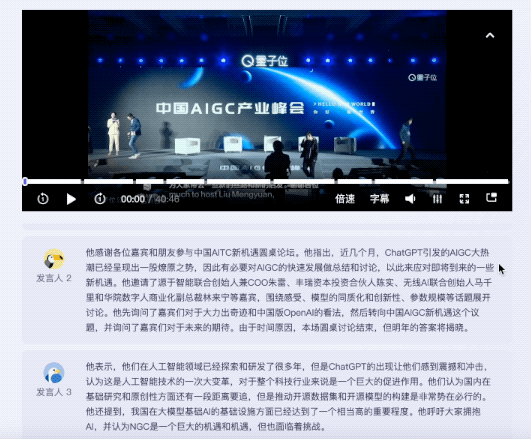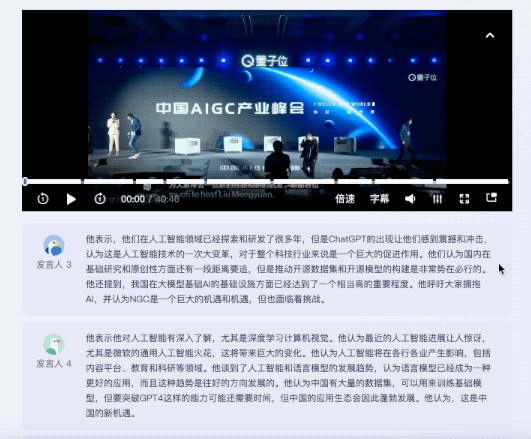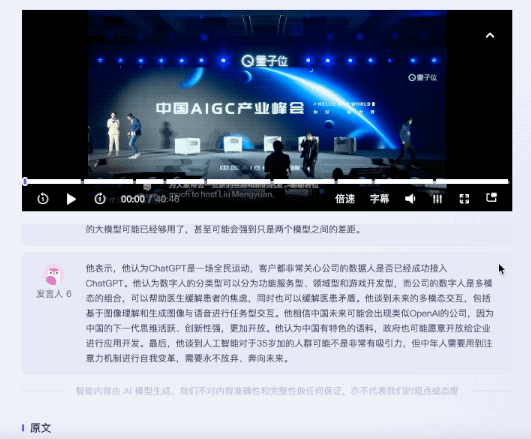
测试视频是一段40分钟的圆桌讨论,主题是中国AIGC新机遇。参与圆桌讨论的共有5人。
听悟这边,从转写完成到AI提取关键词、给出全文摘要,一共花了不到5分钟的时间。
结果是酱婶的:


不仅给出了关键词,圆桌讨论的内容也总结得很到位,并且还给视频划分了关键点。
对比人类编辑摘录的话题要点,我嗅到了一丝危机……

值得一提的是,针对不同嘉宾的发言,听悟都能给出对应的发言总结。
同样的题目抛给飞书妙记。目前,在内容总结方面,飞书妙记还只能给出关键词。

会议纪要需要手动在转写文字上标注。

讯飞听说他们正在内测一个基于星火认知大模型的产品,能够分析文件内容,但需要填写申请并排队等待。(有内测资格的小伙伴欢迎分享体验~)
在基础的讯飞听见中,目前没有类似的总结功能。

看来这一轮测试:
不过要说在本次实测中,通义听悟最令人感觉惊喜的,其实是一个“小”设计:
Chrome插件功能。
无论是看英文视频,看直播,还是上课开会,点开听悟插件,就能实现音视频的实时转录和翻译。
就像开头所展示的那样,拿来当实时字幕用,延迟低,翻译快,还有双语对照功能,同时,录音和转写文字都能一键保存下来,方便后续使用。
妈妈再也不用担心我啃不下来英文视频资料了。
另外,我还有个大胆的想法……
开组会的时候打开听悟,开会儿小差再也不用怕被导师突然抽查了。
目前,听悟已经和阿里云盘打通,存放在云盘中的音视频内容可以一键转写,在线播放云盘视频时还能自动显示字幕。AI处理过的音视频文件将来可以在企业版本中快速内部分享。

听悟官方还透露,接下来,听悟还会持续上新大模型能力,比如直接抽取视频内的PPT截图、针对音视频内容可以直接向AI提问……
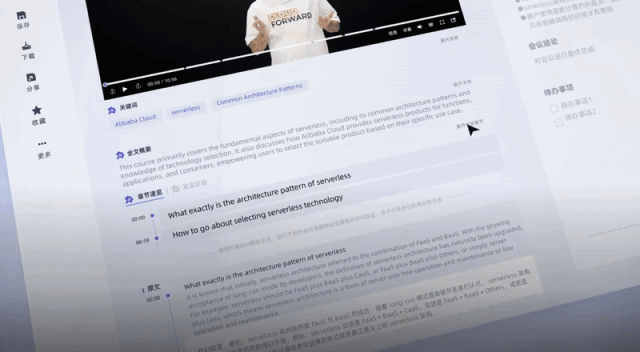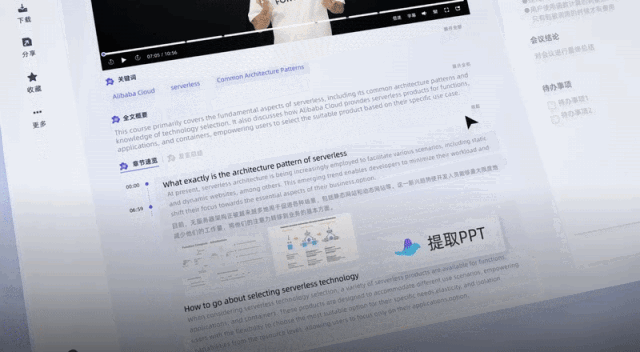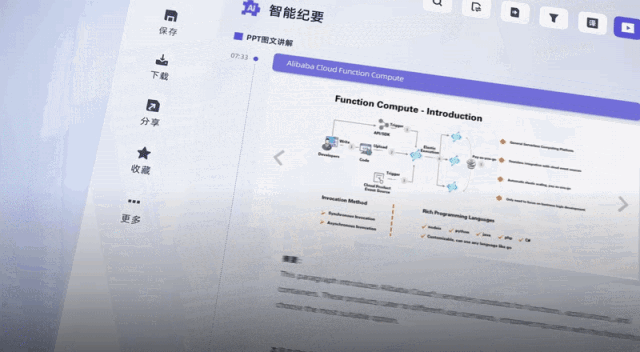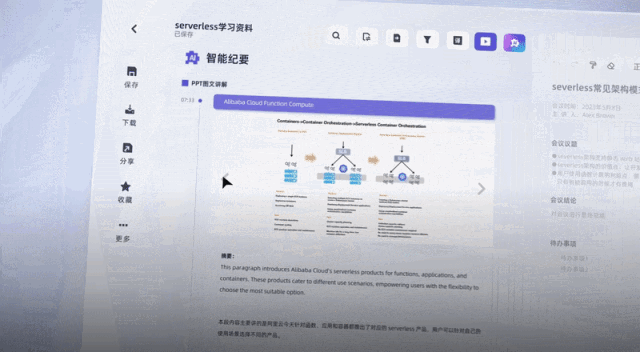

关键是,公测福利现在人人可薅,每天登陆即可自动获得2小时转写时长,阿里云官方微博、微信及各大平台社区还会发放大量20小时转写口令码,并且时长均可叠加,一年内有效。
勤快点的羊毛大师,攒出100小时以上的免费时长不是梦(手动狗头)。

背后技术:大语言模型+语音SOTA
其实,在公测之前,通义听悟就已经在阿里内部精心打磨过了。
在去年年底,有一些量子位读者获得了听悟内测体验卡,当时的版本已经包含了离线语音/视频转写和实时转写的功能。
这次公测,听悟主要是接入了通义千问大模型的摘要及对话能力。更具体地说,这项工作是建立在通义千问大模型的基础之上,将研究团队在推理、对齐和对话问答等方面的研究成果集成到一起。
首先,如何准确抽取关键信息,是这类神器提升工作效率的关键。这就需要借助大模型的推理能力。
阿里AI团队在2022年提出了基于大语言模型的知识探测与推理利用框架Proton(Probing Turning from Large Language Models)。The relevant paper will be published at top international conferences such as KDD2022 and SIGIR2023.。

该框架的核心思路在于,探测大模型的内部知识,以思维链为载体进行知识流动和利用。
在通用常识推理CommonsenseQA2.0、物理常识推理PIQA、数值常识推理Numbersense三大榜单上,Proton曾先后取得第一。
在TabFact(事实验证)榜单上,Proton凭借知识分解和可信思维链技术,首次实现了超越人类的效果。
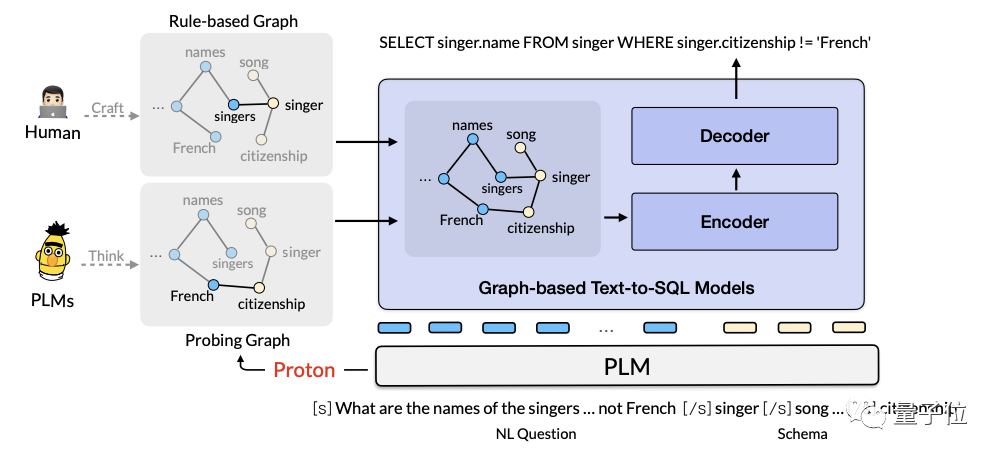
其次,为了确保摘要内容和格式符合用户预期,在对齐方面,听悟还用上了ELHF,即基于人类反馈的高效对齐方法。
该方法仅需少量高质量人工反馈样本,就能实现对齐。在模型效果主观评测中,ELHF能使模型胜率提高20%。
此外,悟背后的研发团队还发布了中文超大规模文档对话数据集Doc2Bot。该团队提升模型问答能力的Re3G方法,已经入选ICASSP 2023:该方法通过Retrieve(检索)、Rerank(重排序)、Refine(精调)和Generate(生成)四个阶段,能提升模型对用户问题的理解、知识检索和回复生成能力,在Doc2Dial和Multi Doc2Dial两大文档对话榜单中取得第一。
除了大模型能力,听悟还是阿里语音技术的集大成者。
其背后的语音识别模型Paraformer,来自阿里达摩院,首次在工业级应用层面解决了端到端识别效果与效率兼顾的难题:
它不仅在推理效率方面比传统模型提高了10倍,而且最初推出时还打破了多项权威数据集的记录,刷新了语音识别的准确率SOTA。在专业第三方全网公共云中文语音识别评测SpeechIO TIOBE白盒测试中,目前,Paraformer-large仍是准确率最高的中文语音识别模型。
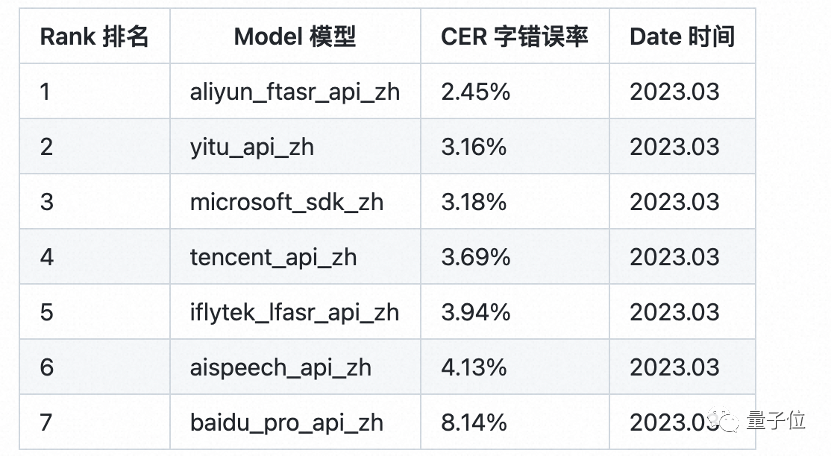
Paraformer是单轮非自回归模型,由编码器、预测器、采样器、解码器和损失函数这五个部分组成。
通过对预测器的创新设计,Paraformer实现了对目标文字个数及对应声学隐变量的精准预测。
另外,研究人员还引入了机器翻译领域中浏览语言模型(GLM)的思路,设计了基于GLM的采样器,增强了模型对上下文语义的建模。
同时,Paraformer还使用了数万小时、覆盖丰富场景的超大规模工业数据集进行训练,进一步提升了识别准确率。
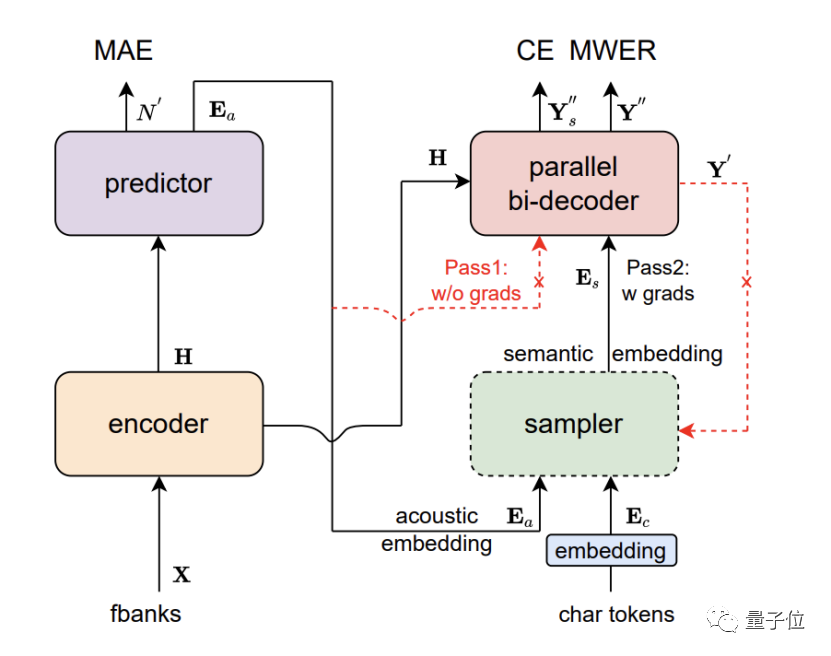
而准确的多人讨论发言人区分,则得益于达摩院的CAM++说话人识别基础模型。该模型采用基于密集型连接的时延网络D-TDNN,每一层的输入均由前面所有层的输出拼接而成,这种层级特征复用和时延网络的一维卷积,可以显著提高网络的计算效率。
在行业主流的中英文测试集VoxCeleb和CN-Celeb上,CAM++均刷新了最优准确率。
大模型开卷,用户受益
据中国科学技术信息研究所报告,据不完全统计,目前国内已经发布了79个大模型。
这种大模型开卷的趋势下,AI应用进化的速度再次进入到一个冲刺阶段。
站在用户的角度来说,喜闻乐见的局面正逐步形成:
大模型的“统筹”之下,各种AI技术开始在应用侧百花齐放,使得工具越来越高效,越来越智能。
从一个斜杠就能帮你自动写完工作计划的智能文档,到快速帮你总结要素的音视频记录和分析工具,生成式大模型这朵AGI的火花,正在让越来越多的人感受到AI的魔力。
与此同时,对于科技企业来说,新的挑战和新的机会,无疑也已经出现。
挑战是,所有产品都将被大模型的风暴席卷,技术创新已经成为了无可回避的关键问题。
现有市场格局对于新型杀手级应用而言,已经到了重写的机会时刻。谁能取得领先优势,将取决于谁的技术准备更完备,谁的技术进化速度更快。
无论如何,技术开卷,终将是用户受益。
以上是阿里云大模型上新!AI神器「通义听悟」公测中:长视频一秒总结,还能自动做笔记、翻字幕 | 羊毛可薅的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 阿里云宣布 2024 云栖大会于 9 月 19 日至 21 日在杭州举办,畅享票免费申请
Aug 07, 2024 pm 07:12 PM
阿里云宣布 2024 云栖大会于 9 月 19 日至 21 日在杭州举办,畅享票免费申请
Aug 07, 2024 pm 07:12 PM
本站8月5日消息,阿里云宣布,2024云栖大会将于9月19日~21日在杭州云栖小镇举办,将设三日主论坛、400场分论坛与并行话题以及近四万平方米展区。云栖大会对公众免费开放,即日起公众可以通过云栖大会官网免费申请畅享票,另有5000元的全通票可购买,本站附门票网址:https://yunqi.aliyun.com/2024/ticket-list据介绍,云栖大会起源于2009年,最初命名为第一届中国网站发展论坛,2011年演变成阿里云开发者大会,2015年正式更名为“云栖大会”,至今已连续成功举
 大模型App腾讯元宝上线!混元再升级,打造可随身携带的全能AI助理
Jun 09, 2024 pm 10:38 PM
大模型App腾讯元宝上线!混元再升级,打造可随身携带的全能AI助理
Jun 09, 2024 pm 10:38 PM
5月30日,腾讯宣布旗下混元大模型全面升级,基于混元大模型的App“腾讯元宝”正式上线,苹果及安卓应用商店均可下载。相比此前测试阶段的混元小程序版本,面向工作效率场景,腾讯元宝提供了AI搜索、AI总结、AI写作等核心能力;面向日常生活场景,元宝的玩法也更加丰富,提供了多个特色AI应用,并新增了创建个人智能体等玩法。“腾讯做大模型不争一时之先。”腾讯云副总裁、腾讯混元大模型负责人刘煜宏表示:“过去的一年,我们持续推进腾讯混元大模型的能力爬坡,在丰富、海量的业务场景中打磨技术,同时洞察用户的真实需求
 字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
火山引擎总裁谭待企业要做好大模型落地,面临模型效果、推理成本、落地难度的三大关键挑战:既要有好的基础大模型做支撑,解决复杂难题,也要有低成本的推理服务让大模型被广泛应用,还要更多工具、平台和应用帮助企业做好场景落地。——谭待火山引擎总裁01.豆包大模型首次亮相大使用量打磨好模型模型效果是AI落地最关键的挑战。谭待指出,只有大的使用量,才能打磨出好模型。目前,豆包大模型日均处理1,200亿tokens文本、生成3,000万张图片。为助力企业做好大模型场景落地,字节跳动自主研发的豆包大模型将通过火山
 揭秘NVIDIA大模型推理框架:TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
揭秘NVIDIA大模型推理框架:TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
一、TensorRT-LLM的产品定位TensorRT-LLM是NVIDIA为大型语言模型(LLM)开发的可扩展推理方案。它基于TensorRT深度学习编译框架构建、编译和执行计算图,并借鉴了FastTransformer中高效的Kernels实现。此外,它还利用NCCL实现设备间的通信。开发者可以根据技术发展和需求差异,定制算子以满足特定需求,例如基于cutlass开发定制的GEMM。TensorRT-LLM是NVIDIA官方推理方案,致力于提供高性能并不断完善其实用性。TensorRT-LL
 工业知识图谱进阶实战
Jun 13, 2024 am 11:59 AM
工业知识图谱进阶实战
Jun 13, 2024 am 11:59 AM
一、背景简介首先来介绍一下云问科技的发展历程。云问科技公...2023年,正是大模型盛行的时期,很多企业认为已经大模型之后图谱的重要性大大降低了,之前研究的预置的信息化系统也都不重要了。不过随着RAG的推广、数据治理的盛行,我们发现更高效的数据治理和高质量的数据是提升私有化大模型效果的重要前提,因此越来越多的企业开始重视知识建设的相关内容。这也推动了知识的构建和加工开始向更高水平发展,其中有很多技巧和方法可以挖掘。可见一个新技术的出现,并不是将所有的旧技术打败,也有可能将新技术和旧技术相互融合后
 对标GPT-4!中国移动九天大模型通过双备案
Apr 04, 2024 am 09:31 AM
对标GPT-4!中国移动九天大模型通过双备案
Apr 04, 2024 am 09:31 AM
4月4日消息,日前,国家网信办公布已备案大模型清单,中国移动“九天自然语言交互大模型”名列其中,标志着中国移动九天AI大模型可正式对外提供生成式人工智能服务。中国移动表示,这是同时通过国家“生成式人工智能服务备案”和“境内深度合成服务算法备案”双备案的首个央企研发的大模型。据介绍,九天自然语言交互大模型具有行业能力增强、安全可信、支持全栈国产化等特点,已形成90亿、139亿、570亿、千亿等多种参数量版本,可灵活部署于云、边、端不同场
 新测试基准发布,最强开源Llama 3尴尬了
Apr 23, 2024 pm 12:13 PM
新测试基准发布,最强开源Llama 3尴尬了
Apr 23, 2024 pm 12:13 PM
如果试题太简单,学霸和学渣都能考90分,拉不开差距……随着Claude3、Llama3甚至之后GPT-5等更强模型发布,业界急需一款更难、更有区分度的基准测试。大模型竞技场背后组织LMSYS推出下一代基准测试Arena-Hard,引起广泛关注。Llama3的两个指令微调版本实力到底如何,也有了最新参考。与之前大家分数都相近的MTBench相比,Arena-Hard区分度从22.6%提升到87.4%,孰强孰弱一目了然。Arena-Hard利用竞技场实时人类数据构建,与人类偏好一致率也高达89.1%
 小米字节联手!小爱同学接入豆包大模型:手机、SU7已搭载
Jun 13, 2024 pm 05:11 PM
小米字节联手!小爱同学接入豆包大模型:手机、SU7已搭载
Jun 13, 2024 pm 05:11 PM
6月13日消息,据字节旗下“火山引擎”公众号介绍,小米旗下人工智能助手“小爱同学”与火山引擎达成合作,双方基于豆包大模型实现更智能的AI交互体验。据悉,字节跳动打造的豆包大模型,每日能够高效处理数量多达1200亿个的文本tokens、生成3000万张内容。小米借助豆包大模型提升自身模型的学习与推理能力,打造出全新的“小爱同学”,不仅更加精准地把握用户需求,还以更快的响应速度和更全面的内容服务。例如,当用户询问复杂的科学概念时,&ldq
