
间隙锁是在可重复读隔离级别下才会生效的: next-key lock 实际上是由间隙锁加行锁实现的,如果切换到读提交隔离级别 (read-committed) 的话,就好理解了,过程中去掉间隙锁的部分,也就是只剩下行锁的部分。而在读提交隔离级别下间隙锁就没有了,为了解决可能出现的数据和日志不一致问题,需要把binlog 格式设置为 row 。也就是说,许多公司的配置为:读提交隔离级别加 binlog_format=row。业务不需要可重复读的保证,这样考虑到读提交下操作数据的锁范围更小(没有间隙锁),这个选择是合理
的。
总结的加锁规则里面,包含了两个 “ “ 原则 ” ” 、两个 “ “ 优化 ” ” 和一个 “bug” 。
原则 1 :加锁的基本单位是 next-key lock 。 next-key lock 是前开后闭区间。
原则 2 :查找过程中访问到的对象才会加锁。任何辅助索引上的锁,或者非索引列上的锁,最终都要回溯到主键上,在主键上也要加一把锁。
优化 1 :索引上的等值查询,给唯一索引加锁的时候, next-key lock 退化为行锁。也就是说如果InnoDB扫描的是一个主键、或是一个唯一索引的话,那InnoDB只会采用行锁方式来加锁
优化 2 :索引上(不一定是唯一索引)的等值查询,向右遍历时且最后一个值不满足等值条件的时候, next-keylock 退化为间隙锁。
一个 bug :唯一索引上的范围查询会访问到不满足条件的第一个值为止。
我们以表test作为例子,建表语句和初始化语句如下:其中id为主键索引
CREATE TABLE `test` ( id` int(11) NOT NULL, col1` int(11) DEFAULT NULL, col2` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`col1`) ) ENGINE=InnoDB; insert into test values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
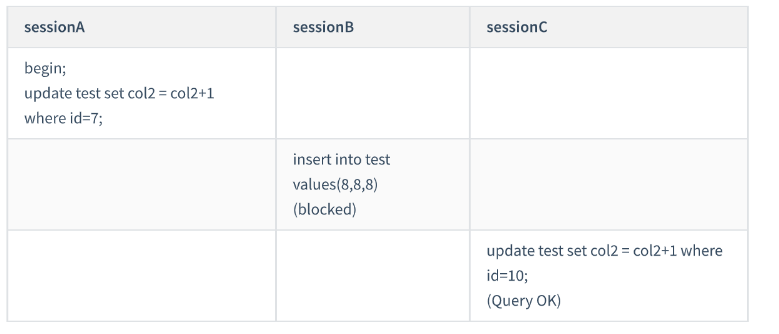
由于表 test 中没有 id=7 的记录
根据原则 1 ,加锁单位是 next-key lock , session A 加锁范围就是 (5,10] ;
同时根据优化 2 ,这是一个等值查询 (id=7) ,而 id=10 不满足查询条件, next-key lock 退化成间隙锁,因此最终加锁的范围是 (5,10)

这里 session A 要给索引 col1 上 col1=5 的这一行加上读锁.
根据原则 1 ,加锁单位是 next-key lock ,左开右闭,5是闭上的,因此会给 (0,5]加上 next-key lock
要注意 c 是普通索引,因此仅访问 c=5 这一条记录是不能马上停下来的(可能有col1=5的其他记录),
需要向右遍历,查到c=10 才放弃。根据第二个原则,需要对所有访问进行加锁,因此需要给区间(5,10]加上next-key lock。
但是同时这个符合优化 2 :等值判断,向右遍历,最后一个值不满足 col1=5 这个等值条件,因此退化成间隙锁 (5,10) 。
根据原则 2 , 只有访问到的对象才会加锁,这个查询使用覆盖索引,并不需要访问主键索引,
因此,在主键索引上没有添加任何锁,这解释了为什么会话B的更新语句可以执行成功。
但 session C 要插入一个 (7,7,7) 的记录,就会被 session A 的间隙锁 (5,10) 锁住 这个例子说明,锁是加在索引上的。
执行 for update 时,系统会认为你接下来要更新数据,因此会顺便给主键索引上满足条件的行加上行锁。
如果你要用 lock in share mode来给行加读锁避免数据被更新的话,就必须得绕过覆盖索引的优化,因为覆盖索引不会访问主键索引,不会给主键索引上加锁
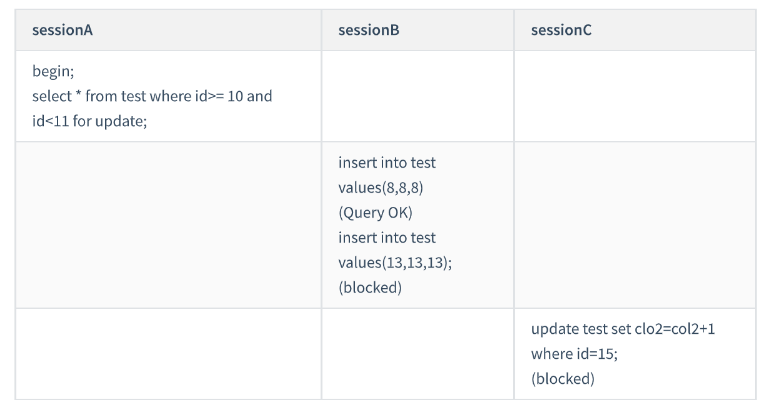
开始执行的时候,要找到第一个 id=10 的行,因此本该是 next-key lock(5,10] 。 根据优化 1 ,主键
id 上的等值条件,退化成行锁,只加了 id=10 这一行的行锁。
它是范围查询, 范围查找就往后继续找,找到 id=15 这一行停下来,不满足条件,因此需要加
next-key lock(10,15] 。
session A 这时候锁的范围就是主键索引上,行锁 id=10 和 next-key lock(10,15] 。首次 session A 定位查找
id=10 的行的时候,是当做等值查询来判断的,而向右扫描到 id=15 的时候,用的是范围查询判断。

在第一次用 col1=10 定位记录的时候,索引 c 上加了 (5,10] 这个 next-key lock 后,由于索引 col1 是非唯
一索引,没有优化规则,也就是 说不会蜕变为行锁,因此最终 sesion A 加的锁是,索引 c 上的 (5,10] 和
(10,15] 这两个 next-keylock 。
这里需要扫描到 col1=15 才停止扫描,是合理的,因为 InnoDB 要扫到 col1=15 ,才知道不需要继续往后
找了。

session A 是一个范围查询,按照原则 1 的话,应该是索引 id 上只加 (10,15] 这个 next-key lock ,并且因
为 id 是唯一键,所以循环判断到 id=15 这一行就应该停止了。
但是实现上, InnoDB 会往前扫描到第一个不满足条件的行为止,也就是 id=20 。而且由于这是个范围扫
描,因此索引 id 上的 (15,20] 这个 next-key lock 也会被锁上。照理说,这里锁住 id=20 这一行的行为,其
实是没有必要的。因为扫描到 id=15 ,就可以确定不用往后再找了。
这里,我给表 t 插入一条新记录:insert into t values(30,10,30);也就是说,现在表里面有两个c=10的行
但是它们的主键值 id 是不同的(分别是 10 和 30 ),因此这两个c=10 的记录之间,也是有间隙的。
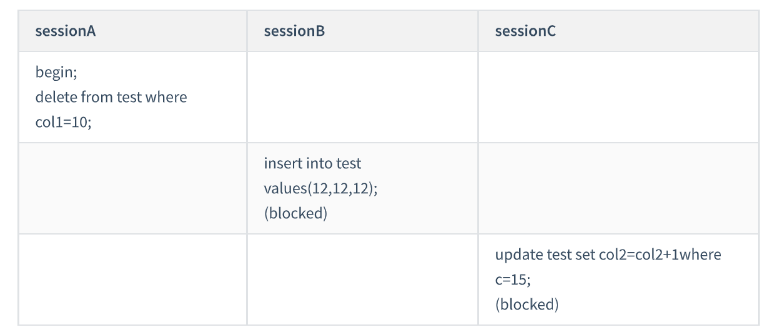
这次我们用 delete 语句来验证。注意, delete 语句加锁的逻辑,其实跟 select ... for update 是类似的,
也就是我在文章开始总结的两个 “ 原则 ” 、两个 “ 优化 ” 和一个 “bug” 。
这时, session A 在遍历的时候,先访问第一个 col1=10 的记录。同样地,根据原则 1 ,这里加的是
(col1=5,id=5) 到 (col1=10,id=10) 这个 next-key lock 。
由于c是普通索引,所以继续向右查找,直到碰到 (col1=15,id=15) 这一行循环才结束。根据优化 2 ,这是
一个等值查询,向右查找到了不满足条件的行,所以会退化成 (col1=10,id=10) 到 (col1=15,id=15) 的间隙
锁。
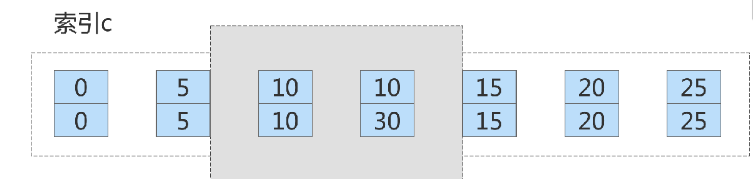
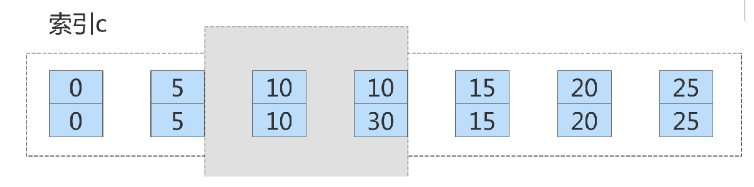
这个 delete 语句在索引 c 上的加锁范围,就是上面图中蓝色区域覆盖的部分。这个蓝色区域左右两边都
是虚线,表示开区间,即 (col1=5,id=5) 和 (col1=15,id=15) 这两行上都没有锁

session A 的 delete 语句加了 limit 2 。你知道表 t 里 c=10 的记录其实只有两条,因此加不加 limit 2 ,删
除的效果都是一样的。但是加锁效果却不一样
这是因为,案例七里的 delete 语句明确加了 limit 2 的限制,因此在遍历到 (col1=10, id=30) 这一行之后,
满足条件的语句已经有两条,循环就结束了。因此,索引 col1 上的加锁范围就变成了从( col1=5,id=5)
到( col1=10,id=30) 这个前开后闭区间,如下图所示:
这个例子对我们实践的指导意义就是, 在删除数据的时候尽量加 limit 。
这样不仅可以控制删除数据的条数,让操作更安全,还可以减小加锁的范围。
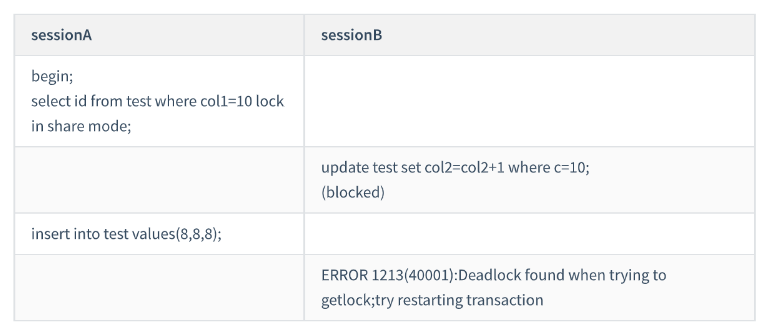
session A 启动事务后执行查询语句加 lock in share mode ,在索引 col1 上加了 next-keylock(5,10] 和
间隙锁 (10,15) (索引向右遍历退化为间隙锁);
session B 的 update 语句也要在索引 c 上加 next-key lock(5,10] ,进入锁等待; 实际上分成了两步,
先是加 (5,10) 的间隙锁,加锁成功;然后加 col1=10 的行锁,因为sessionA上已经给这行加上了读
锁,此时申请死锁时会被阻塞
然后 session A 要再插入 (8,8,8) 这一行,被 session B 的间隙锁锁住。由于出现了死锁, InnoDB 让
session B 回滚
如下面一条语句
下图为这个表的索引id的示意图。
begin;
select * from test where id>9 and id<12 order by id desc for update;

首先这个查询语句的语义是 order by id desc ,要拿到满足条件的所有行,优化器必须先找到 “ 第
一个 id<12 的值 ” 。
这个过程是通过索引树的搜索过程得到的,在引擎内部,其实是要找到 id=12 的这个值,只是最终
没找到,但找到了 (10,15) 这个间隙。( id=15 不满足条件,所以 next-key lock 退化为了间隙锁 (10,
15) 。)
然后向左遍历,在遍历过程中,就不是等值查询了,会扫描到 id=5 这一行,又因为区间是左开右
闭的,所以会加一个next-key lock (0,5] 。 也就是说,在执行过程中,通过树搜索的方式定位记录
的时候,用的是 “ 等值查询 ” 的方法。
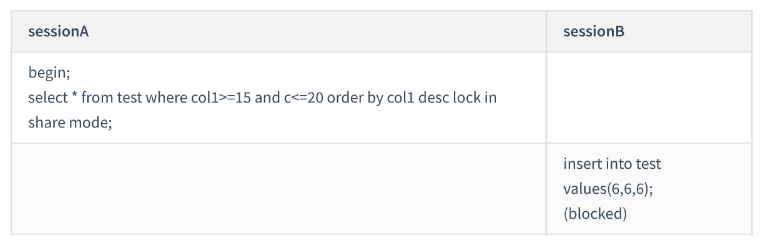
由于是 order by col1 desc ,第一个要定位的是索引 col1 上 “ 最右边的 ”col1=20 的行。这是一个非唯一索引的等值查询:
首先在左侧开区间加入 next-key 锁定,形成 (15,20] 区间。 向右遍历,col1=25不满足条件,退化为间隙锁 所以会加上间隙锁(20,25) 和 next-key lock (15,20] 。
遍历到 col1=10 时停止向左扫描索引。下一个键锁定(next-keylock)会被应用于右开左闭区间 (5,10)
这正是阻塞session B 的 insert 语句的原因。在扫描过程中, col1=20 、 col1=15 、 col1=10 这三行都存在值,由于是 select * ,所以会在主键
id 上加三个行锁。 因此, session A 的 select 语句锁的范围就是:
索引 col1 上 (5, 25) ;
主键索引上 id=15 、 20 两个行锁。

注意:根据 col1>5 查到的第一个记录是 col1=10 ,因此不会加 (0,5] 这个 next-key lock 。
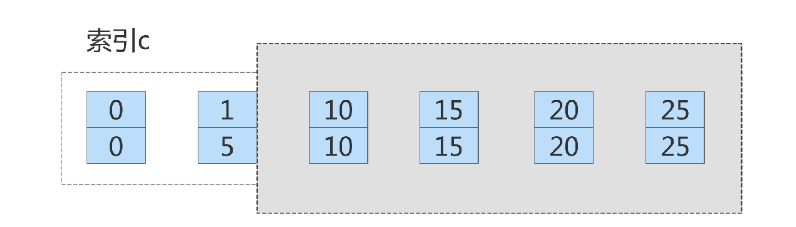
session A 的加锁范围是索引 col1 上的 (5,10] 、 (10,15] 、 (15,20] 、 (20,25] 和(25,supremum] 。
之后 session B 的第一个 update 语句,要把 col1=5 改成 col1=1 ,你可以理解为两步:
插入 (col1=1, id=5) 这个记录;
删除 (col1=5, id=5) 这个记录。
通过这个操作, session A 的加锁范围变成了图 7 所示的样子:
好,接下来 session B 要执行 update t set col1 = 5 where col1 = 1 这个语句了,一样地可以拆成两步:
插入 (col1=5, id=5) 这个记录;
删除 (col1=1, id=5) 这个记录。 第一步试图在已经加了间隙锁的 (1,10) 中插入数据,所以就被堵住
了。
以上是mysql间隙锁加锁的规则有哪些的详细内容。更多信息请关注PHP中文网其他相关文章!





















