

RLHF中的「RL」是必需的吗?有人用二进制交叉熵直接微调LLM,效果更好

近来,在大型数据集上训练的无监督语言模型已经获得了令人惊讶的能力。然而,这些模型是在具有各种目标、优先事项和技能集的人类生成的数据上训练的,其中一些目标和技能设定未必希望被模仿。
从模型非常广泛的知识和能力中选择其期望的响应和行为,对于构建安全、高性能和可控的人工智能系统至关重要。很多现有的方法通过使用精心策划的人类偏好集将所需的行为灌输到语言模型中,这些偏好集代表了人类认为安全和有益的行为类型,这个偏好学习阶段发生在对大型文本数据集进行大规模无监督预训练的初始阶段之后。
虽然最直接的偏好学习方法是对人类展示的高质量响应进行监督性微调,但最近相对热门的一类方法是从人类(或人工智能)反馈中进行强化学习(RLHF/RLAIF)。RLHF 方法将奖励模型与人类偏好的数据集相匹配,然后使用 RL 来优化语言模型策略,以产生分配高奖励的响应,而不过度偏离原始模型。
虽然 RLHF 产生的模型具有令人印象深刻的对话和编码能力,但 RLHF pipeline 比监督学习复杂得多,涉及训练多个语言模型,并在训练的循环中从语言模型策略中采样,产生大量的计算成本。
而最近的一项研究表明:现有方法使用的基于 RL 的目标可以用一个简单的二进制交叉熵目标来精确优化,从而大大简化偏好学习 pipeline。也就是说,完全可以直接优化语言模型以坚持人类的偏好,而不需要明确的奖励模型或强化学习。

论文链接:https://arxiv.org/pdf/2305.18290.pdf
来自斯坦福大学等机构研究者提出了直接偏好优化(Direct Preference Optimization,DPO),这种算法隐含地优化了与现有 RLHF 算法相同的目标(带有 KL - 发散约束的奖励最大化),但实施起来很简单,而且可直接训练。
实验表明,至少当用于 60 亿参数语言模型的偏好学习任务,如情感调节、摘要和对话时,DPO 至少与现有的方法一样有效,包括基于 PPO 的 RLHF。
DPO 算法
与现有的算法一样,DPO 也依赖于理论上的偏好模型(如 Bradley-Terry 模型),以此衡量给定的奖励函数与经验偏好数据的吻合程度。然而,现有的方法使用偏好模型定义偏好损失来训练奖励模型,然后训练优化所学奖励模型的策略,而 DPO 使用变量的变化来直接定义偏好损失作为策略的一个函数。鉴于人类对模型响应的偏好数据集,DPO 因此可以使用一个简单的二进制交叉熵目标来优化策略,而不需要明确地学习奖励函数或在训练期间从策略中采样。
DPO 的更新增加了首选 response 与非首选 response 的相对对数概率,但它包含了一个动态的、每个样本的重要性权重,以防止模型退化,研究者发现这种退化会发生在一个朴素概率比目标上。
为了从机制上理解 DPO,分析损失函数 的梯度是很有用的。关于参数 θ 的梯度可以写成:
的梯度是很有用的。关于参数 θ 的梯度可以写成:
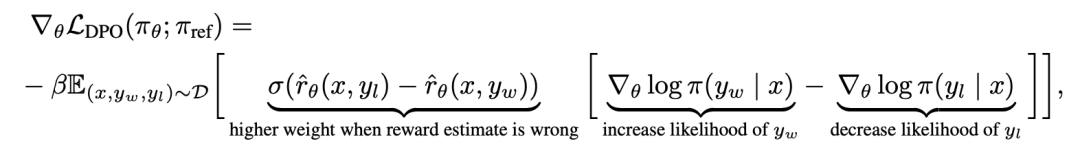
其中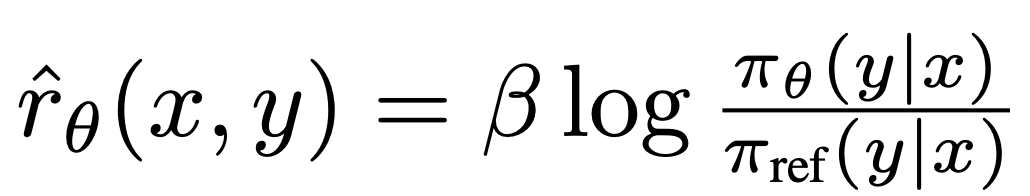 是由语言模型
是由语言模型 和参考模型
和参考模型 隐含定义的奖励。直观地说,损失函数
隐含定义的奖励。直观地说,损失函数 的梯度增加了首选补全 y_w 的可能性,减少了非首选补全 y_l 的可能性。
的梯度增加了首选补全 y_w 的可能性,减少了非首选补全 y_l 的可能性。
重要的是,这些样本的权重是由隐性奖励模型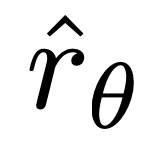 对不喜欢的完成度的评价高低来决定的,以 β 为尺度,即隐性奖励模型对完成度的排序有多不正确,这也是 KL 约束强度的体现。实验表明了这种加权的重要性,因为没有加权系数的这种方法的 naive 版本会导致语言模型的退化(附录表 2)。
对不喜欢的完成度的评价高低来决定的,以 β 为尺度,即隐性奖励模型对完成度的排序有多不正确,这也是 KL 约束强度的体现。实验表明了这种加权的重要性,因为没有加权系数的这种方法的 naive 版本会导致语言模型的退化(附录表 2)。
在论文的第五章,研究者对 DPO 方法做了进一步的解释,提供了理论支持,并将 DPO 的优势与用于 RLHF 的 Actor-Critic 算法(如 PPO)的问题联系起来。具体细节可参考原论文。
实验
在实验中,研究者评估了 DPO 直接根据偏好训练策略的能力。
首先,在一个控制良好的文本生成环境中,他们思考了这样一个问题:与 PPO 等常见偏好学习算法相比,DPO 在参考策略中权衡奖励最大化和 KL-divergence 最小化的效率如何?接着,研究者还评估了 DPO 在更大模型和更困难的 RLHF 任务 (包括摘要和对话) 上的性能。
最终发现,在几乎没有超参数调整的情况下,DPO 的表现往往与带有 PPO 的 RLHF 等强大的基线一样好,甚至更好,同时在学习奖励函数下返回最佳的 N 个采样轨迹结果。
从任务上说,研究者探索了三个不同的开放式文本生成任务。在所有实验中,算法从偏好数据集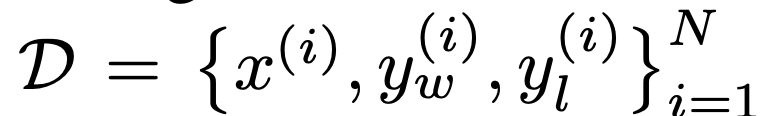 中学习策略。
中学习策略。
在可控情感生成中,x 是来自 IMDb 数据集的电影评论的前缀,策略必须生成具有积极情感的 y。为了进行对照评估,实验使用了预先训练好的情感分类器去生成偏好对,其中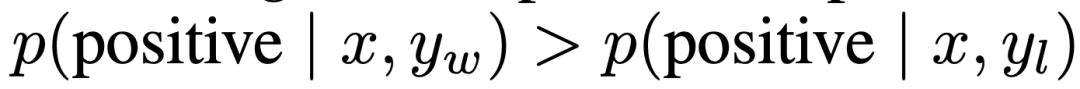 。
。
对于 SFT,研究者微调了 GPT-2-large,直到收敛于 IMDB 数据集的训练分割的评论。总之,x 是来自 Reddit 的论坛帖子,该策略必须生成帖子中要点的总结。基于此前工作,实验使用了 Reddit TL;DR 摘要数据集以及 Stiennon et al. 收集的人类偏好。实验还使用了一个 SFT 模型,该模型是根据人类撰写的论坛文章摘要 2 和 RLHF 的 TRLX 框架进行微调的。人类偏好数据集是由 Stiennon et al. 从一个不同的但经过类似训练的 SFT 模型中收集的样本。
最后,在单轮对话中,x 是一个人类问题,可以是从天体物理到建立关系建议的任何问题。一个策略必须对用户的查询做出有吸引力和有帮助的响应;策略必须对用户的查询做出有意思且有帮助的响应;实验使用 Anthropic Helpful and Harmless 对话集,其中包含人类和自动化助手之间的 170k 对话。每个文本以一对由大型语言模型 (尽管未知) 生成的响应以及表示人类首选响应的偏好标签结束。在这种情况下,没有预训练的 SFT 模型可用。因此,实验只在首选完成项上微调现成的语言模型,以形成 SFT 模型。
研究者使用了两种评估方法。为了分析每种算法在优化约束奖励最大化目标方面的效率,在可控情感生成环境中,实验通过其实现奖励的边界和与参考策略的 KL-divergence 来评估每种算法。实验可以使用 ground-truth 奖励函数 (情感分类器),因此这一边界是可以计算得出的。但事实上,ground truth 奖励函数是未知的。因此研究者通过基线策略的胜率评估算法的胜率,并用 GPT-4 作为在摘要和单轮对话设置中人类评估摘要质量和响应有用性的代理。针对摘要,实验使用测试机中的参考摘要作为极限;针对对话,选用测试数据集中的首选响应作为基线。虽然现有研究表明语言模型可以成为比现有度量更好的自动评估器,但研究者进行了一项人类研究,证明了使用 GPT-4 进行评估的可行性 GPT-4 判断与人类有很强的相关性,人类与 GPT-4 的一致性通常类似或高于人类标注者之间的一致性。
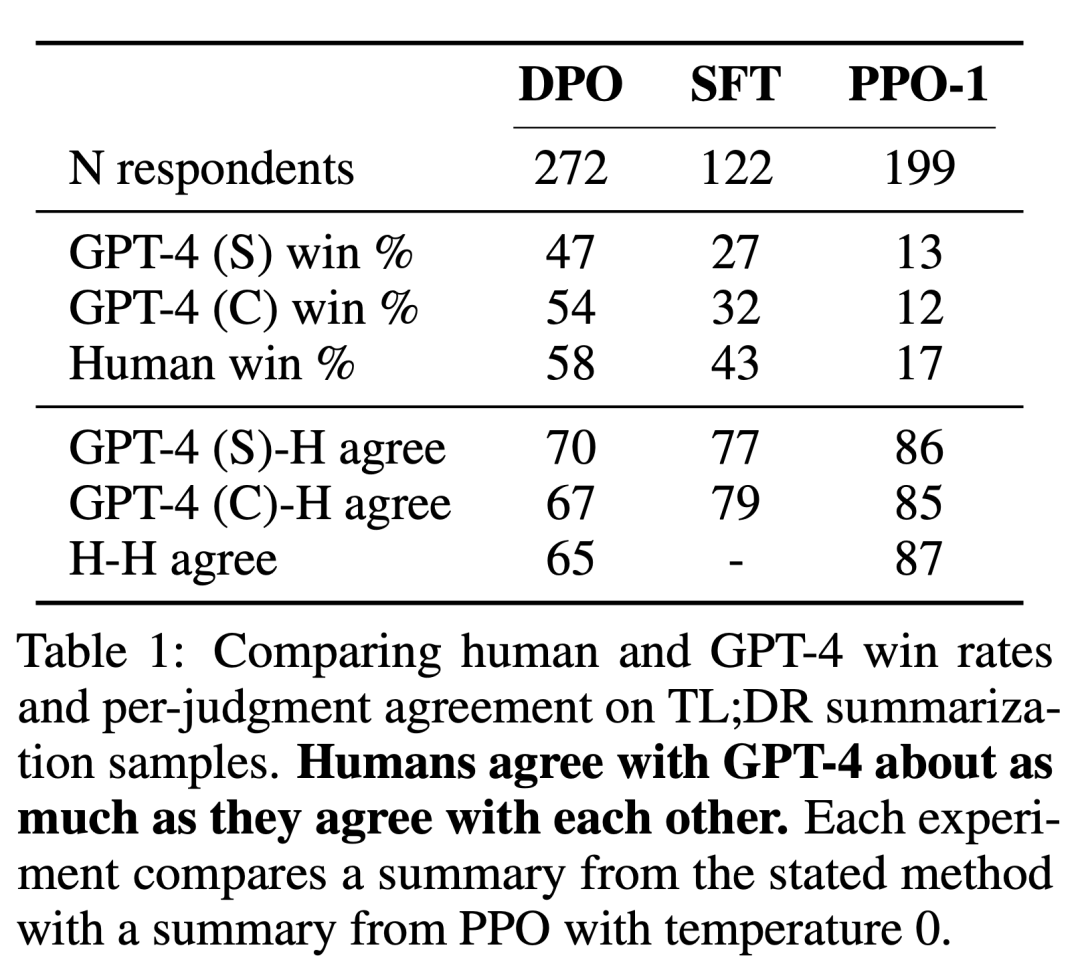
除了 DPO 之外,研究者还评估了几种现有的训练语言模型来与人类偏好保持一致。最简单的是,实验在摘要任务中探索了 GPT-J 的零样本 prompt,在对话任务中探索了 Pythia-2.8B 的 2-shot prompt。此外,实验还评估了 SFT 模型和 Preferred-FT。Preferred-FT 是一个通过监督学习从 SFT 模型 (可控情感和摘要) 或通用语言模型 (单回合对话) 中选择的完成 y_w 进行微调的模型。另一种伪监督方法是 Unlikelihood,它简单地优化策略,使分配给 y_w 的概率最大化,分配给 y_l 的概率最小化。实验在「Unlikehood」上使用了一个可选系数 α∈[0,1]。他们还考虑了 PPO,使用从偏好数据中学习的奖励函数,以及 PPO-GT。PPO-GT 是从可控情感设置中可用的 ground truth 奖励函数学习的 oracle。在情感实验中,团队使用了 PPO-GT 的两个实现,一个是现成的版本,以及一个修改版本。后者将奖励归一化,并进一步调整超参数以提高性能 (在运行具有学习奖励的「Normal」PPO 时,实验也使用了这些修改)。最后,研究者考虑了 N 个基线中的最优值,从 SFT 模型 (或对话中的 Preferred-FT) 中采样 N 个回答,并根据从偏好数据集中学习的奖励函数返回得分最高的回答。这种高性能方法将奖励模型的质量与 PPO 优化解耦,但即使对中度 N 来说,在计算上也是不切实际的,因为它在测试时需要对每个查询进行 N 次采样完成。
图 2 展示了情绪设置中各种算法的奖励 KL 边界。
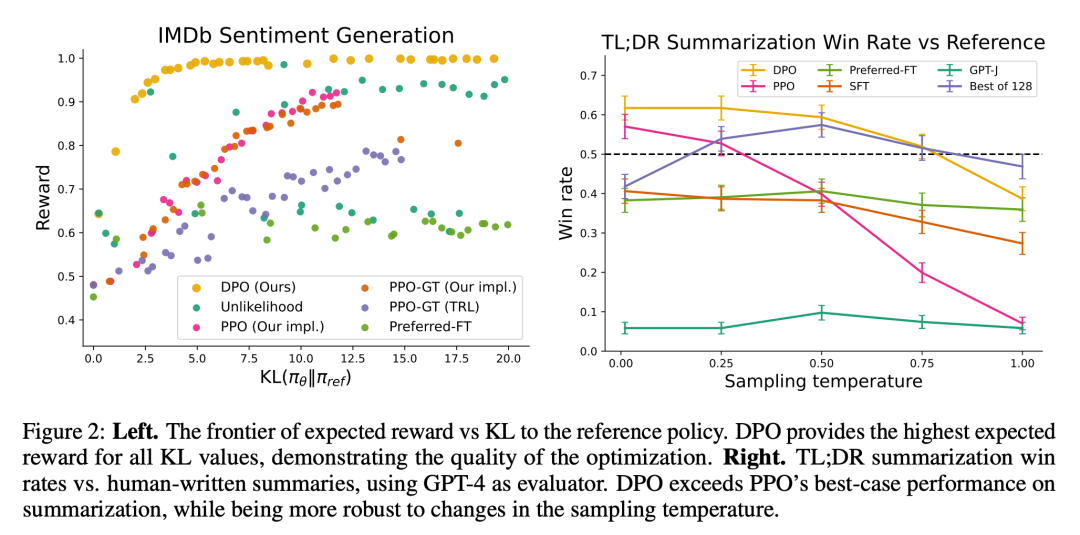
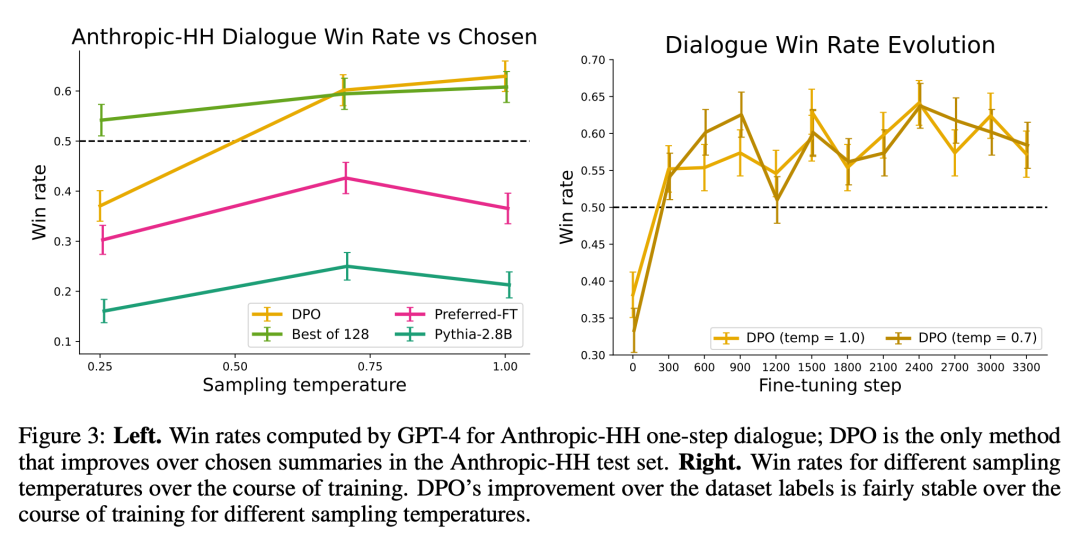
图 3 展示了 DPO 收敛到其最佳性能的速度相对较快。
更多研究细节,可参考原论文。
以上是RLHF中的「RL」是必需的吗?有人用二进制交叉熵直接微调LLM,效果更好的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 centos关机命令行
Apr 14, 2025 pm 09:12 PM
centos关机命令行
Apr 14, 2025 pm 09:12 PM
CentOS 关机命令为 shutdown,语法为 shutdown [选项] 时间 [信息]。选项包括:-h 立即停止系统;-P 关机后关电源;-r 重新启动;-t 等待时间。时间可指定为立即 (now)、分钟数 ( minutes) 或特定时间 (hh:mm)。可添加信息在系统消息中显示。
 CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系统下GitLab的备份与恢复策略为了保障数据安全和可恢复性,CentOS上的GitLab提供了多种备份方法。本文将详细介绍几种常见的备份方法、配置参数以及恢复流程,帮助您建立完善的GitLab备份与恢复策略。一、手动备份利用gitlab-rakegitlab:backup:create命令即可执行手动备份。此命令会备份GitLab仓库、数据库、用户、用户组、密钥和权限等关键信息。默认备份文件存储于/var/opt/gitlab/backups目录,您可通过修改/etc/gitlab
 如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
检查CentOS系统中HDFS配置的完整指南本文将指导您如何有效地检查CentOS系统上HDFS的配置和运行状态。以下步骤将帮助您全面了解HDFS的设置和运行情况。验证Hadoop环境变量:首先,确认Hadoop环境变量已正确设置。在终端执行以下命令,验证Hadoop是否已正确安装并配置:hadoopversion检查HDFS配置文件:HDFS的核心配置文件位于/etc/hadoop/conf/目录下,其中core-site.xml和hdfs-site.xml至关重要。使用
 CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
在CentOS系统上启用PyTorchGPU加速,需要安装CUDA、cuDNN以及PyTorch的GPU版本。以下步骤将引导您完成这一过程:CUDA和cuDNN安装确定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA显卡支持的CUDA版本。例如,您的MX450显卡可能支持CUDA11.1或更高版本。下载并安装CUDAToolkit:访问NVIDIACUDAToolkit官网,根据您显卡支持的最高CUDA版本下载并安装相应的版本。安装cuDNN库:前
 docker原理详解
Apr 14, 2025 pm 11:57 PM
docker原理详解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux内核特性,提供高效、隔离的应用运行环境。其工作原理如下:1. 镜像作为只读模板,包含运行应用所需的一切;2. 联合文件系统(UnionFS)层叠多个文件系统,只存储差异部分,节省空间并加快速度;3. 守护进程管理镜像和容器,客户端用于交互;4. Namespaces和cgroups实现容器隔离和资源限制;5. 多种网络模式支持容器互联。理解这些核心概念,才能更好地利用Docker。
 centos安装mysql
Apr 14, 2025 pm 08:09 PM
centos安装mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安装 MySQL 涉及以下步骤:添加合适的 MySQL yum 源。执行 yum install mysql-server 命令以安装 MySQL 服务器。使用 mysql_secure_installation 命令进行安全设置,例如设置 root 用户密码。根据需要自定义 MySQL 配置文件。调整 MySQL 参数和优化数据库以提升性能。
 CentOS下GitLab的日志如何查看
Apr 14, 2025 pm 06:18 PM
CentOS下GitLab的日志如何查看
Apr 14, 2025 pm 06:18 PM
CentOS系统下查看GitLab日志的完整指南本文将指导您如何查看CentOS系统中GitLab的各种日志,包括主要日志、异常日志以及其他相关日志。请注意,日志文件路径可能因GitLab版本和安装方式而异,若以下路径不存在,请检查GitLab安装目录及配置文件。一、查看GitLab主要日志使用以下命令查看GitLabRails应用程序的主要日志文件:命令:sudocat/var/log/gitlab/gitlab-rails/production.log此命令会显示produc
 CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系统上进行PyTorch分布式训练,需要按照以下步骤操作:PyTorch安装:前提是CentOS系统已安装Python和pip。根据您的CUDA版本,从PyTorch官网获取合适的安装命令。对于仅需CPU的训练,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,请确保已安装对应版本的CUDA和cuDNN,并使用相应的PyTorch版本进行安装。分布式环境配置:分布式训练通常需要多台机器或单机多GPU。所
