
最近,Matthias Plappert的一篇推文点燃了LLMs圈的广泛讨论。
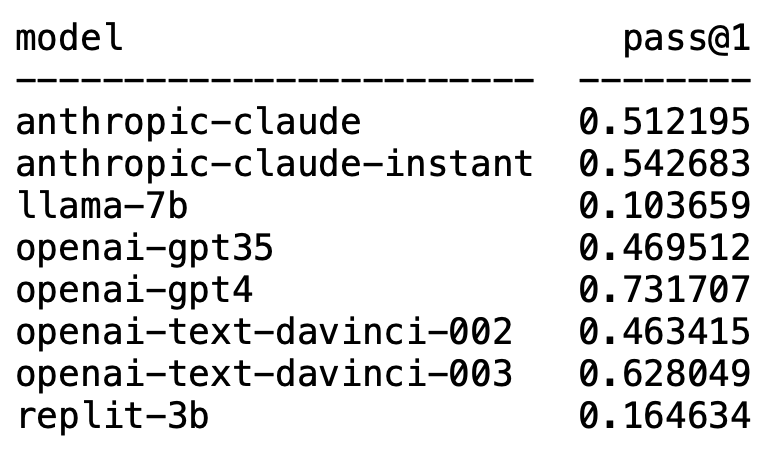
Plappert是一位知名的计算机科学家,他在HumanEval上发布了自己对AI圈主流的LLM进行的基准测试结果。
他的测试偏向代码生成方面。
结果令人大为不震撼,又大为震撼。

意料之内的是,GPT-4毫无疑问霸榜,摘得第一。
意料之外的是,OpenAI的text-davinci-003异军突起,拿了个第二。
Plappert表示,text-davinci-003堪称一个「宝藏」模型。
而耳熟能详的LLaMA在代码生成方面却并不出色。
Plappert表示,GPT-4的性能表现甚至比文献中的数据还要好。
论文中GPT-4的一轮测试数据是67%的通过率,而Plappert的测试则达到了73%。

在分析成因时,他表示,数据上存在差异有不少可能性。其中之一是他给到GPT-4的prompt要比论文作者测试的时候好上那么一些。
另一个原因是,他猜测论文在测试GPT-4的时候模型的温度(temperature)不是0。
「温度」是一个用于调整模型生成文本时创造性和多样性的参数。「温度」是一个大于0的数值,通常在 0 到 1 之间。它影响模型生成文本时采样预测词汇的概率分布。
当模型的「温度」较高时(如 0.8、1 或更高),模型会更倾向于从较多样且不同的词汇中选择,这使得生成的文本风险性更高、创意性更强,但也可能产生更多的错误和不连贯之处。
而当「温度」较低时(如 0.2、0.3 等),模型主要会从具有较高概率的词汇中选择,从而产生更平稳、更连贯的文本。
但此时,生成的文本可能会显得过于保守和重复。
因此在实际应用中,需要根据具体需求来权衡选择合适的「温度」值。
接下来,在点评text-davinci-003时,Plappert表示这也是OpenAI旗下一个很能打的模型。
虽然不比GPT-4,但是一轮测试有62%的通过率还是能稳稳拿下第二名的宝座。
Plappert强调,text-davinci-003最好的一点是,用户不需要使用ChatGPT的API。这意味着给prompt的时候能简单一点。
此外,Plappert也给予了Anthropic AI的claude-instant模型比较高的评价。
他认为这个模型的性能不错,比GPT-3.5能打。GPT-3.5的通过率是46%,而claude-instant是54%。
当然,Anthropic AI的另一个LLM——claude,没有claude-instant能打,通过率只有51%。
Plappert表示,测试两个模型用的prompt都一样,不行就是不行。
除了这些耳熟能详的模型,Plappert也测试了不少开源的小模型。
Plappert表示,自己能在本地运行这些模型,这点还是不错的。
不过从规模上看,这些模型显然没有OpenAI和Anthropic AI的模型大,所以硬拿它们对比有点以大欺小了。

当然,Plappert对LLaMA的测试结果并不满意。
从测试结果来看,LLaMA在生成代码方面表现很差劲。可能是因为他们在从GitHub收集数据时采用了欠采样的方法(under-sampling)。
就算和Codex 2.5B相比,LLaMA的性能也不是个儿。(通过率10% vs. 22%)

最后,他测试了Replit的3B大小的模型。
他表示,表现还不错,但和推特上宣传的数据相比差点意思(通过率16% vs. 22%)
Plappert认为,这可能是因为他在测试这个模型时所用的量化方式让通过率掉了几个百分比。
在测评的最后,Plappert提到了一个很有意思的点。
某位用户在推特上发现,当使用Azure平台的Completion API(补全API)(而不是Chat API)时,GPT-3.5-turbo的性能表现更好。
Plappert认为这种现象具有一定合理性,因为通过Chat API输入prompt可能会相当复杂。

以上是OpenAI霸榜前二!大模型代码生成排行榜出炉,70亿LLaMA拉跨,被2.5亿Codex吊打的详细内容。更多信息请关注PHP中文网其他相关文章!





















