

Web 端实时防挡脸弹幕(基于机器学习)

防挡脸弹幕,即大量弹幕飘过,但不会遮挡视频画面中的人物,看起来像是从人物背后飘过去的。
机器学习已经火了好几年了,但很多人都不知道浏览器中也能运行这些能力;
本文介绍在视频弹幕方面的实践优化过程,文末列举了一些本方案可适用的场景,期望能开启一些脑洞。
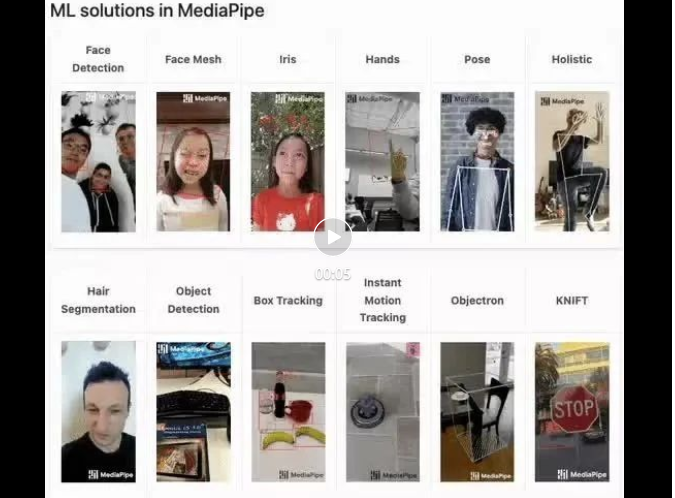
mediapipe Demo(https://google.github.io/mediapipe/)展示
主流防挡脸弹幕实现原理
点播
up 上传视频
服务器后台计算提取视频画面中的人像区域,转换成 svg 存储
客户端播放视频的同时,从服务器下载 svg 与弹幕合成,人像区域不显示弹幕
直播
- 主播推流时,实时(主播设备)从画面提取人像区域,转换成 svg
- 将 svg 数据合并到视频流中(SEI),推流至服务器
- 客户端播放视频同时,从视频流中(SEI)解析出 svg
- 将 svg 与弹幕合成,人像区域不显示弹幕
本文实现方案
客户端播放视频同时,实时从画面提取人像区域信息,将人像区域信息导出成图片与弹幕合成,人像区域不显示弹幕。
实现原理
- 采用机器学习开源库从视频画面实时提取人像轮廓,如Body Segmentation(https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation/README.md)
- 将人像轮廓转导出为图片,设置弹幕层的 mask-image(https://developer.mozilla.org/zh-CN/docs/Web/CSS/mask-image)
对比传统(直播SEI实时)方案
优点:
- 易于实现;只需要Video标签一个参数,无需多端协同配合
- 无网络带宽消耗
缺点:
- 理论性能极限劣于传统方案;相当于性能资源换网络资源
面临的问题
众所周知,JavaScript 的性能较差,因此不适合用于处理 CPU 密集型任务。由官方demo变成工程实践,最大的挑战就是——性能。
本次实践最终将 CPU 占用优化到 5% 左右(2020 M1 Macbook),达到生产可用状态。
实践调优过程
选择机器学习模型
BodyPix (https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation/src/body_pix/README.md)
精确度太差,面部偏窄,有很明显的弹幕与人物面部边缘重叠现象

BlazePose(https://github.com/tensorflow/tfjs-models/blob/master/pose-detection/src/blazepose_mediapipe/README.md)
精确度优秀,且提供了肢体点位信息,但性能较差

返回数据结构示例
[{score: 0.8,keypoints: [{x: 230, y: 220, score: 0.9, score: 0.99, name: "nose"},{x: 212, y: 190, score: 0.8, score: 0.91, name: "left_eye"},...],keypoints3D: [{x: 0.65, y: 0.11, z: 0.05, score: 0.99, name: "nose"},...],segmentation: {maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}}]MediaPipe SelfieSegmentation (https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation/src/selfie_segmentation_mediapipe/README.md)
精确度优秀(跟 BlazePose 模型效果一致),CPU 占用相对 BlazePose 模型降低 15% 左右,性能取胜,但返回数据中不提供肢体点位信息
返回数据结构示例
{maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}初版实现
参考 MediaPipe SelfieSegmentation 模型 官方实现(https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation/README.md#bodysegmentationdrawmask),未做优化的情况下 CPU 占用 70% 左右
const canvas = document.createElement('canvas')canvas.width = videoEl.videoWidthcanvas.height = videoEl.videoHeightasync function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl)const foregroundColor = { r: 0, g: 0, b: 0, a: 0 }const backgroundColor = { r: 0, g: 0, b: 0, a: 255 } const mask = await toBinaryMask(segmentation, foregroundColor, backgroundColor) await drawMask(canvas, canvas, mask, 1, 9)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 33)} detect().catch(console.error)降低提取频率,平衡 性能-体验
一般视频 30FPS,尝试弹幕遮罩(后称 Mask)刷新频率降为 15FPS,体验上还能接受
window.setTimeout(detect, 66) // 33 => 66
此时,CPU 占用 50% 左右
解决性能瓶颈
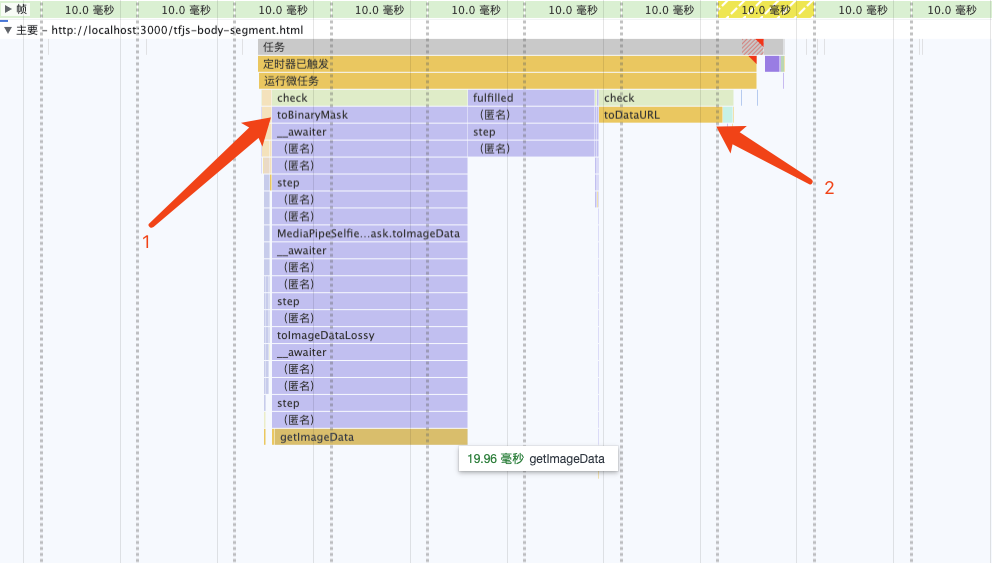
分析火焰图可发现,性能瓶颈在 toBinaryMask 和 toDataURL
重写toBinaryMask
分析源码,结合打印segmentation的信息,发现segmentation.mask.toCanvasImageSource可获取原始ImageBitmap对象,即是模型提取出来的信息。尝试自己编写代码,将ImageBitmap转换为遮罩(Mask),以代替使用开源库所提供的默认实现。
实现原理
async function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl) context.clearRect(0, 0, canvas.width, canvas.height)// 1. 将`ImageBitmap`绘制到 Canvas 上context.drawImage(// 经验证 即使出现多人,也只有一个 segmentationawait segmentation[0].mask.toCanvasImageSource(),0, 0,canvas.width, canvas.height)// 2. 设置混合模式context.globalCompositeOperation = 'source-out'// 3. 反向填充黑色context.fillRect(0, 0, canvas.width, canvas.height)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 66)}第 2、3 步相当于给人像区域外的内容填充黑色(反向填充ImageBitmap),是为了配合css(mask-image), 不然只有当弹幕飘到人像区域才可见(与目标效果正好相反)。
globalCompositeOperation MDN(https://developer.mozilla.org/zh-CN/docs/Web/API/CanvasRenderingContext2D/globalCompositeOperation)
此时,CPU 占用 33% 左右
多线程优化
我原先认为toDataURL是由浏览器内部实现的,无法再进行优化,现在只有优化toDataURL这个耗时操作了。
虽没有替换实现,但可使用 OffscreenCanvas (https://developer.mozilla.org/zh-CN/docs/Web/API/OffscreenCanvas)+ Worker,将耗时任务转移到 Worker 中去, 避免占用主线程,就不会影响用户体验了。
并且ImageBitmap实现了Transferable接口,可被转移所有权,跨 Worker 传递也没有性能损耗(https://hughfenghen.github.io/fe-basic-course/js-concurrent.html#%E4%B8%A4%E4%B8%AA%E6%96%B9%E6%B3%95%E5%AF%B9%E6%AF%94)。
// 前文 detect 的反向填充 ImageBitmap 也可以转移到 Worker 中// 用 OffscreenCanvas 实现, 此处略过 const reader = new FileReaderSync()// OffscreenCanvas 不支持 toDataURL,使用 convertToBlob 代替offsecreenCvsEl.convertToBlob({type: 'image/png',quality: 0}).then((blob) => {const dataURL = reader.readAsDataURL(blob)self.postMessage({msgType: 'mask',val: dataURL})}).catch(console.error)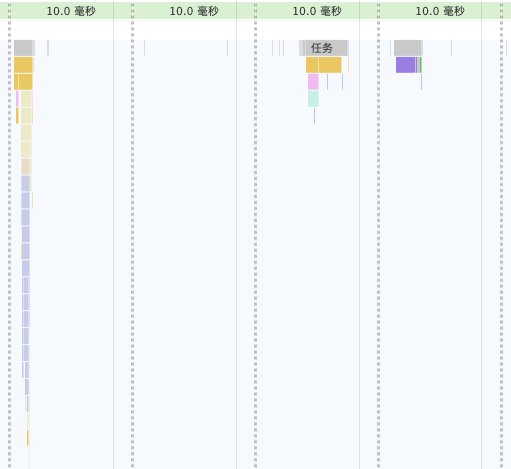
可以看到两个耗时的操作消失了
此时,CPU 占用 15% 左右
降低分辨率
继续分析,上图重新计算样式(紫色部分)耗时约 3ms
Demo 足够简单很容易推测到是这行代码导致的,发现 imgStr 大概 100kb 左右(视频分辨率 1280x720)。
danmakuContainer.style.webkitMaskImage = `url(${imgStr})通过canvas缩小图片尺寸(360P甚至更低),再进行推理。
优化后,导出的 imgStr 大概 12kb,重新计算样式耗时约 0.5ms。
此时,CPU 占用 5% 左右

启动条件优化
虽然提取 Mask 整个过程的 CPU 占用已优化到可喜程度。
当在画面没人的时候,或没有弹幕时候,可以停止计算,实现 0 CPU 占用。
无弹幕判断比较简单(比如 10s 内收超过两条弹幕则启动计算),也不在该 SDK 实现范围,略过
判定画面是否有人
第一步中为了高性能,选择的模型只有ImageBitmap,并没有提供肢体点位信息,所以只能使用getImageData返回的像素点值来判断画面是否有人。
画面无人时,CPU 占用接近 0%
发布构建优化
依赖包的提交较大,构建出的 bundle 体积:684.75 KiB / gzip: 125.83 KiB
所以,可以进行异步加载SDK,提升页面加载性能。
- 分别打包一个 loader,一个主体
- 由业务方 import loader,首次启用时异步加载主体
这个两步前端工程已经非常成熟了,略过细节。
运行效果

总结
过程
- 选择高性能模型后,初始状态 CPU 70%
- 降低 Mask 刷新频率(15FPS),CPU 50%
- 重写开源库实现(toBinaryMask),CPU 33%
- 多线程优化,CPU 15%
- 降低分辨率,CPU 5%
- 判断画面是否有人,无人时 CPU 接近 0%
CPU 数值指主线程占用
注意事项
- 兼容性:Chrome 79及以上,不支持 Firefox、Safari。因为使用了OffscreenCanvas
- 不应创建多个或多次创建segmenter实例(bodySegmentation.createSegmenter),如需复用请保存实例引用,因为:
- 创建实例时低性能设备会有明显的卡顿现象
- 会内存泄露;如果无法避免,这是mediapipe 内存泄露 解决方法(https://github.com/google/mediapipe/issues/2819#issuecomment-1160335349)
经验
- 优化完成之后,提取并应用 Mask 关键计算量在 GPU (30%左右),而不是 CPU
- 性能优化需要业务场景分析,防挡弹幕场景可以使用低分辨率、低刷新率的 mask-image,能大幅减少计算量
- 该方案其他应用场景:
- 替换/模糊人物背景
- 人像马赛克
- 人像抠图
- 卡通头套,虚拟饰品,如猫耳朵、兔耳朵、带花、戴眼镜什么的(换一个模型,略改)
- 关注Web 神经网络 API (https://mp.weixin.qq.com/s/v7-xwYJqOfFDIAvwIVZVdg)进展,以后实现相关功能也许会更简单
本期作者

刘俊
哔哩哔哩资深开发工程师
以上是Web 端实时防挡脸弹幕(基于机器学习)的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何通过CSS自定义resize符号并使其与背景色统一?
Apr 05, 2025 pm 02:30 PM
如何通过CSS自定义resize符号并使其与背景色统一?
Apr 05, 2025 pm 02:30 PM
CSS自定义resize符号的方法与背景色统一在日常开发中,我们经常会遇到需要自定义用户界面细节的情况,比如调...
 如何在网页上正确显示本地安装的'荆南麦圆体”?
Apr 05, 2025 pm 10:33 PM
如何在网页上正确显示本地安装的'荆南麦圆体”?
Apr 05, 2025 pm 10:33 PM
在网页中使用本地安装的字体文件最近,我从网上下载了一种免费字体,并成功将其安装到了我的系统中。现在...

 为什么Edge浏览器中的特定div元素无法显示?如何解决这个问题?
Apr 05, 2025 pm 08:21 PM
为什么Edge浏览器中的特定div元素无法显示?如何解决这个问题?
Apr 05, 2025 pm 08:21 PM
如何解决用户代理样式表导致的显示问题?在使用Edge浏览器时,项目中的一个div元素无法显示。经过查看,发�...
 如何通过JavaScript或CSS控制浏览器打印设置中的页首和页尾?
Apr 05, 2025 pm 10:39 PM
如何通过JavaScript或CSS控制浏览器打印设置中的页首和页尾?
Apr 05, 2025 pm 10:39 PM
如何使用JavaScript或CSS控制浏览器打印设置中的页首和页尾在浏览器的打印设置中,有一个选项可以控制是否显�...


 为什么在Safari中自定义样式表能在本地网页生效,但在百度页面上却无法生效?
Apr 05, 2025 pm 05:15 PM
为什么在Safari中自定义样式表能在本地网页生效,但在百度页面上却无法生效?
Apr 05, 2025 pm 05:15 PM
在Safari中使用自定义样式表的问题探讨今天我们来探讨一个关于Safari浏览器的自定义样式表应用问题。前端新手...
