

一篇学会本地知识库对LLM的性能优化

昨天一个跑了220个小时的微调训练完成了,主要任务是想在CHATGLM-6B上微调出一个能够较为精确的诊断数据库错误信息的对话模型来。
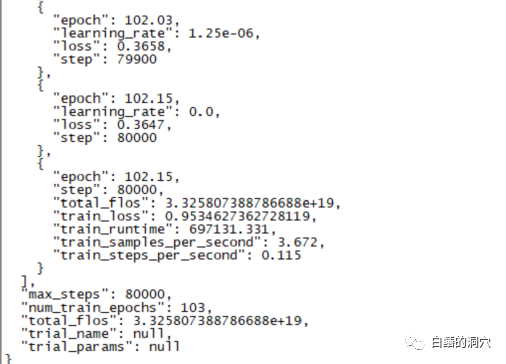
不过这个等了将近十天的训练最后的结果令人失望,比起我之前做的一个样本覆盖更小的训练来,差的还是挺大的。
这样的结果还是有点令人失望的,这个模型基本上是没有实用价值的。看样子需要重新调整参数与训练集,再做一次训练。大语言模型的训练是一场军备竞赛,没有好的装备是玩不起来的。看样子我们也必须要升级一下实验室的装备了,否则没有几个十天可以浪费。
从最近的几次失败的微调训练来看,微调训练这条路也并不容易完成。不同的任务目标混杂在一起跑训练,可能不同的任务目标需要的训练参数不同,使最终的训练集无法满足某些任务的需求。因此PTUNING只适合某个十分确定的任务,不一定适合混合任务,以混合任务为目的的模型,可能需要用FINETUNE。这和前几天我在和一个朋友交流时大家的观点类似。
实际上因为训练模型难度比较大,一些人已经放弃了自己训练模型,而采用将本地知识库矢量化后进行较为精准的检索,然后通过AUTOPROMPT将检索后的结果生成自动提示,去问打语音模型。利用langchain很容易实现这个目标。
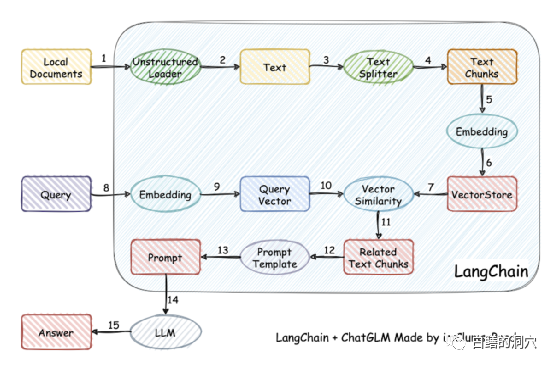
这个工作的原理是将本地文档通过加载器加载为文本,然后对文本进行切分行程文本片段,经过编码后写入向量存储中功查询使用。查询结果出来后,通过Prompt Template自动形成提问用的提示,去询问LLM,LLM生成最后的回答。
这项工作里有另个要点,一个是较为精准的搜索到本地知识库中的知识,这个通过向量存储于搜索来实现,目前针对中英文的本地知识库的向量化与搜索的解决方案很多,可以选择某个对你的知识库比较友好的方案来使用。
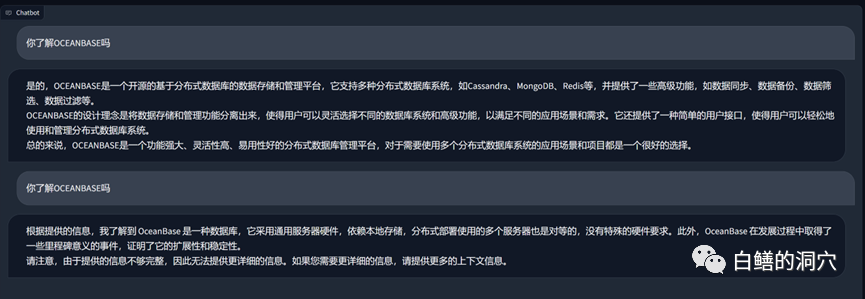
上面是一个在vicuna-13b上通过关于OB的知识库进行的问答,上面的是没有使用本地知识库,直接使用LLM的能力的回答,下面是加载了本地知识库后的回答。可以看出性能提升还是挺明显的。
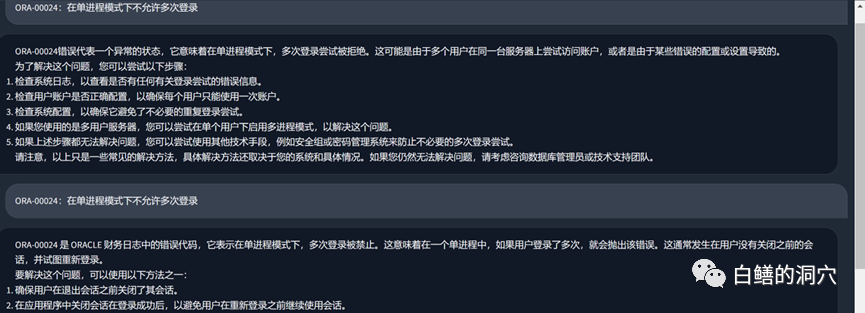
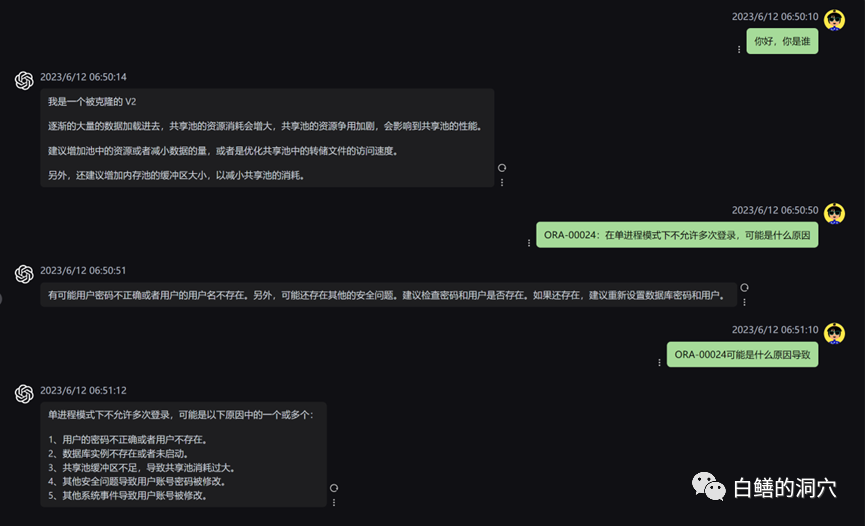
我们再来看看刚才那个ORA错误的问题,在没有使用本地知识库之前,LLM基本上是胡说八道的,而加载了本地知识库之后,这个回答还是中规中矩的,文中的错别字也是我们知识库中的错误。实际上PTUNING使用的训练集也是通过这个本地知识库生成出来的。
从最近我们踩过的坑可以收获一些经验。首先ptuning的难度比我们想象得要高得多,虽然说ptuning比finetune需要的装备低一点,不过训练难度一点都不低。其次是通过Langchain和autoprompt利用本地知识库来改善LLM能力效果不错,对于大多数企业应用来说,只要把本地知识库梳理好,选择合适的矢量化方案,应该都能获得不比PTUNING/FINETUNE差的效果。第三,还是上回说的那个问题,LLM的能力至关重要。必须选择一个能力较强的LLM作为基础模型来使用。任何嵌入式模型都只能局部改善能力,不能起决定性的作用。第四,对于数据库相关的知识,vicuna-13b的能力确实不错。
今天一大早还要去客户那边做个交流,早上时间有限,就简单写几句吧。大家对此有何心得,欢迎留言讨论(讨论仅你我可见),我也是在这条路上孤独行走,希望有同路人指点一二。
以上是一篇学会本地知识库对LLM的性能优化的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 PHP 数组键值翻转:不同方法的性能对比分析
May 03, 2024 pm 09:03 PM
PHP 数组键值翻转:不同方法的性能对比分析
May 03, 2024 pm 09:03 PM
PHP数组键值翻转方法性能对比表明:array_flip()函数在大型数组(超过100万个元素)下比for循环性能更优,耗时更短。手动翻转键值的for循环方法耗时相对较长。
 不同Java框架的性能对比
Jun 05, 2024 pm 07:14 PM
不同Java框架的性能对比
Jun 05, 2024 pm 07:14 PM
不同Java框架的性能对比:RESTAPI请求处理:Vert.x最佳,请求速率达SpringBoot2倍,Dropwizard3倍。数据库查询:SpringBoot的HibernateORM优于Vert.x及Dropwizard的ORM。缓存操作:Vert.x的Hazelcast客户机优于SpringBoot及Dropwizard的缓存机制。合适框架:根据应用需求选择,Vert.x适用于高性能Web服务,SpringBoot适用于数据密集型应用,Dropwizard适用于微服务架构。
 C++ 程序优化:时间复杂度降低技巧
Jun 01, 2024 am 11:19 AM
C++ 程序优化:时间复杂度降低技巧
Jun 01, 2024 am 11:19 AM
时间复杂度衡量算法执行时间与输入规模的关系。降低C++程序时间复杂度的技巧包括:选择合适的容器(如vector、list)以优化数据存储和管理。利用高效算法(如快速排序)以减少计算时间。消除多重运算以减少重复计算。利用条件分支以避免不必要的计算。通过使用更快的算法(如二分搜索)来优化线性搜索。
 C++中如何优化多线程程序的性能?
Jun 05, 2024 pm 02:04 PM
C++中如何优化多线程程序的性能?
Jun 05, 2024 pm 02:04 PM
优化C++多线程性能的有效技术包括:限制线程数量,避免争用资源。使用轻量级互斥锁,减少争用。优化锁的范围,最小化等待时间。采用无锁数据结构,提高并发性。避免忙等,通过事件通知线程资源可用性。
 PHP 数组转对象对性能的影响是什么?
Apr 30, 2024 am 08:39 AM
PHP 数组转对象对性能的影响是什么?
Apr 30, 2024 am 08:39 AM
在PHP中,数组到对象的转换会对性能产生影响,主要受数组大小、复杂性、对象类等因素影响。为了优化性能,可以考虑使用自定义迭代器、避免不必要的转换、批量转换数组等技巧。
 如何使用基准测试来评估Java函数的性能?
Apr 19, 2024 pm 10:18 PM
如何使用基准测试来评估Java函数的性能?
Apr 19, 2024 pm 10:18 PM
基准测试Java函数性能的方法是使用Java微基准测试套件(JMH)。具体步骤包括:添加JMH依赖项到项目中。创建一个新的Java类,用@State注解表示基准测试方法。在类中编写基准测试方法,用@Benchmark注解。使用JMH命令行工具运行基准测试。
 C++与其他语言的性能比较
Jun 01, 2024 pm 10:04 PM
C++与其他语言的性能比较
Jun 01, 2024 pm 10:04 PM
在开发高性能应用程序时,C++的性能优于其他语言,尤其在微基准测试中。在宏基准测试中,其他语言如Java和C#的便利性和优化机制可能表现更好。在实战案例中,C++在图像处理、数值计算和游戏开发中表现出色,其对内存管理和硬件访问的直接控制带来明显的性能优势。
 Java框架的性能比较
Jun 04, 2024 pm 03:56 PM
Java框架的性能比较
Jun 04, 2024 pm 03:56 PM
根据基准测试,对于小型、高性能应用程序,Quarkus(快速启动、低内存)或Micronaut(TechEmpower优异)是理想选择。SpringBoot适用于大型、全栈应用程序,但启动时间和内存占用稍慢。
