

iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了

Stable Diffusion (SD)是当前最热门的文本到图像(text to image)生成扩散模型。尽管其强大的图像生成能力令人震撼,一个明显的不足是需要的计算资源巨大,推理速度很慢:以 SD-v1.5 为例,即使用半精度存储,其模型大小也有 1.7GB,近 10 亿参数,端上推理时间往往要接近 2min。
为了解决推理速度问题,学术界与业界已经开始对 SD 加速的研究,主要集中于两条路线:(1)减少推理步数,这条路线又可以分为两条子路线,一是通过提出更好的 noise scheduler 来减少步数,代表作是 DDIM [1],PNDM [2],DPM [3] 等;二是通过渐进式蒸馏(Progressive Distillation)来减少步数,代表作是 Progressive Distillation [4] 和 w-conditioning [5] 等。(2)工程技巧优化,代表作是 Qualcomm 通过 int8 量化 + 全栈式优化实现 SD-v1.5 在安卓手机上 15s 出图 [6],Google 通过端上 GPU 优化将 SD-v1.4 在三星手机上加速到 12s [7]。
尽管这些工作取得了长足的进步,但仍然不够快。
近日,Snap 研究院推出最新高性能 Stable Diffusion 模型,通过对网络结构、训练流程、损失函数全方位进行优化,在 iPhone 14 Pro 上实现 2 秒出图(512x512),且比 SD-v1.5 取得更好的 CLIP score。这是目前已知最快的端上 Stable Diffusion 模型!

- 论文地址:https://arxiv.org/pdf/2306.00980.pdf
- Webpage: https://snap-research.github.io/SnapFusion
核心方法
Stable Diffusion 模型分为三部分:VAE encoder/decoder, text encoder, UNet,其中 UNet 无论是参数量还是计算量,都占绝对的大头,因此 SnapFusion 主要是对 UNet 进行优化。具体分为两部分:(1)UNet 结构上的优化:通过分析原有 UNet 的速度瓶颈,本文提出一套 UNet 结构自动评估、进化流程,得到了更为高效的 UNet 结构(称为 Efficient UNet)。(2)推理步数上的优化:众所周知,扩散模型在推理时是一个迭代的去噪过程,迭代的步数越多,生成图片的质量越高,但时间代价也随着迭代步数线性增加。为了减少步数并维持图片质量,我们提出一种 CFG-aware 蒸馏损失函数,在训练过程中显式考虑 CFG (Classifier-Free Guidance)的作用,这一损失函数被证明是提升 CLIP score 的关键!
下表是 SD-v1.5 与 SnapFusion 模型的概况对比,可见速度提升来源于 UNet 和 VAE decoder 两个部分,UNet 部分是大头。UNet 部分的改进有两方面,一是单次 latency 下降(1700ms -> 230ms,7.4x 加速),这是通过提出的 Efficient UNet 结构得到的;二是 Inference steps 降低(50 -> 8,6.25x 加速),这是通过提出的 CFG-aware Distillation 得到的。VAE decoder 的加速是通过结构化剪枝实现。

下面着重介绍 Efficient UNet 的设计和 CFG-aware Distillation 损失函数的设计。
(1)Efficient UNet
我们通过分析 UNet 中的 Cross-Attention 和 ResNet 模块,定位速度瓶颈在于 Cross-Attention 模块(尤其是第一个 Downsample 阶段的 Cross-Attention),如下图所示。这个问题的根源是因为 attention 模块的复杂度跟特征图的 spatial size 成平方关系,在第一个 Downsample 阶段,特征图的 spatial size 仍然较大,导致计算复杂度高。
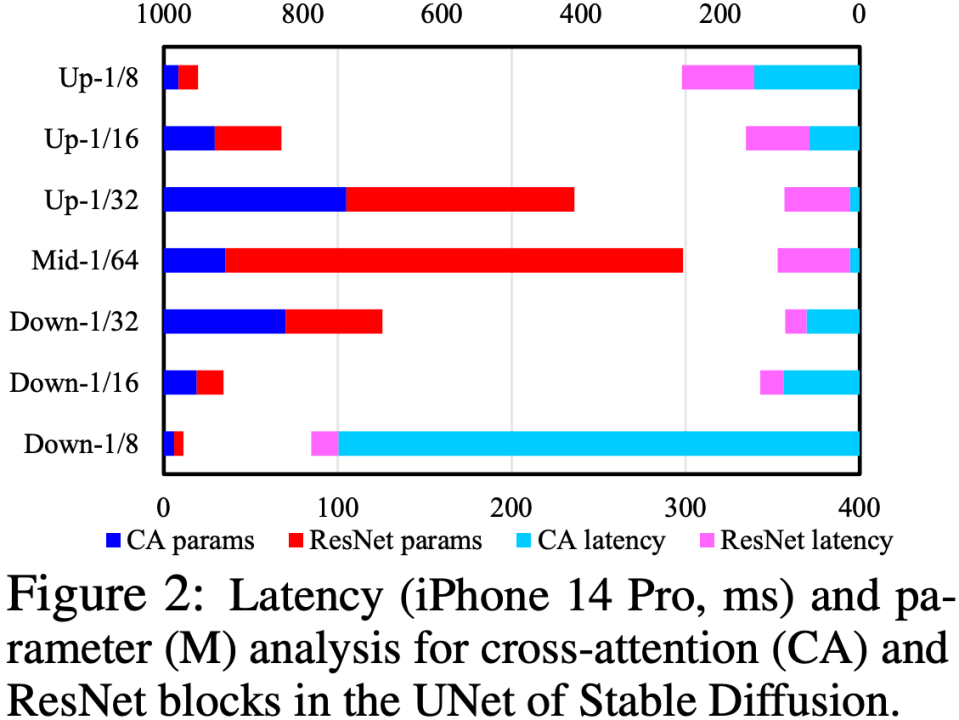
为了优化 UNet 结构,我们提出一套 UNet 结构自动评估、进化流程:先对 UNet 进行鲁棒性训练(Robust Training),在训练中随机 drop 一些模块,以此来测试出每个模块对性能的真实影响,从而构建一个 “对 CLIP score 的影响 vs. latency” 的查找表;然后根据该查找表,优先去除对 CLIP score 影响不大同时又很耗时的模块。这一套流程是在线自动进行,完成之后,我们就得到了一个全新的 UNet 结构,称为 Efficient UNet。相比原版 UNet,实现 7.4x 加速且性能不降。
(2)CFG-aware Step Distillation
CFG(Classifier-Free Guidance)是 SD 推理阶段的必备技巧,可以大幅提升图片质量,非常关键!尽管已有工作对扩散模型进行步数蒸馏(Step Distillation)来加速 [4],但是它们没有在蒸馏训练中把 CFG 纳入优化目标,也就是说,蒸馏损失函数并不知道后面会用到 CFG。这一点根据我们的观察,在步数少的时候会严重影响 CLIP score。
为了解决这个问题,我们提出在计算蒸馏损失函数之前,先让 teacher 和 student 模型都进行 CFG,这样损失函数是在经过 CFG 之后的特征上计算,从而显式地考虑了不同 CFG scale 的影响。实验中我们发现,完全使用 CFG-aware Distillation 尽管可以提高 CLIP score, 但 FID 也明显变差。我们进而提出了一个随机采样方案来混合原来的 Step Distillation 损失函数和 CFG-aware Distillation 损失函数,实现了二者的优势共存,既显著提高了 CLIP score,同时 FID 也没有变差。这一步骤,实现进一步推理阶段加速 6.25 倍,实现总加速约 46 倍。
除了以上两个主要贡献,文中还有对 VAE decoder 的剪枝加速以及蒸馏流程上的精心设计,具体内容请参考论文。
实验结果
SnapFusion 对标 SD-v1.5 text to image 功能,目标是实现推理时间大幅缩减并维持图像质量不降,最能说明这一点的是下图:
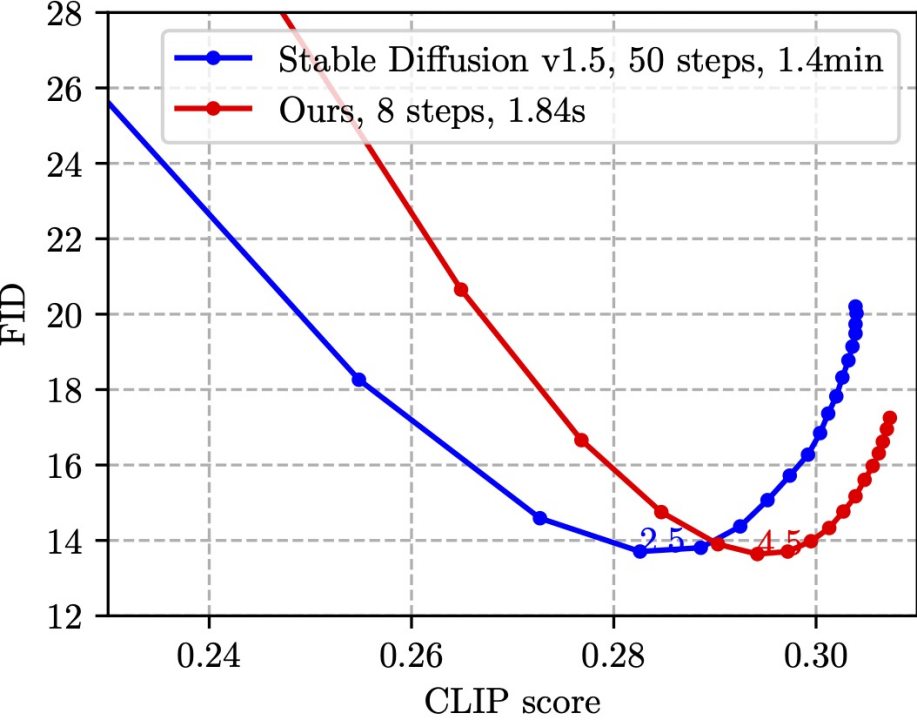
该图是在 MS COCO’14 验证集上随机选取 30K caption-image pairs 测算 CLIP score 和 FID。CLIP score 衡量图片与文本的语义吻合程度,越大越好;FID 衡量生成图片与真实图片之间的分布距离(一般被认为是生成图片多样性的度量),越小越好。图中不同的点是使用不同的 CFG scale 获得,每一个 CFG scale 对应一个数据点。从图中可见,我们的方法(红线)可以达到跟 SD-v1.5(蓝线)同样的最低 FID,同时,我们方法的 CLIP score 更好。值得注意的是,SD-v1.5 需要 1.4min 生成一张图片,而 SnapFusion 仅需要 1.84s,这也是目前我们已知最快的移动端 Stable Diffusion 模型!
下面是一些 SnapFusion 生成的样本:

更多样本请参考文章附录。
除了这些主要结果,文中也展示了众多烧蚀分析(Ablation Study)实验,希望能为高效 SD 模型的研发提供参考经验:
(1)之前 Step Distillation 的工作通常采用渐进式方案 [4, 5],但我们发现,在 SD 模型上渐进式蒸馏并没有比直接蒸馏更有优势,且过程繁琐,因此我们在文中采用的是直接蒸馏方案。
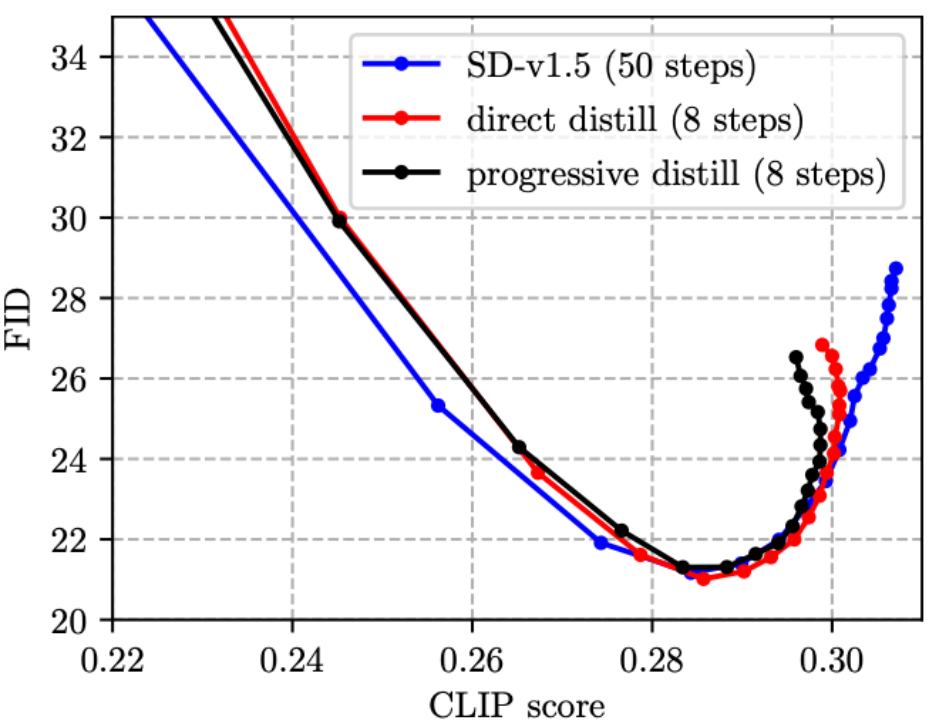
(2)CFG 虽然可以大幅提升图像质量,但代价是推理成本翻倍。今年 CVPR’23 Award Candidate 的 On Distillation 一文 [5] 提出 w-conditioning,将 CFG 参数作为 UNet 的输入进行蒸馏(得到的模型叫做 w-conditioned UNet),从而在推理时省却 CFG 这一步,实现推理成本减半。但是我们发现,这样做其实会造成图片质量下降,CLIP score 降低(如下图中,四条 w-conditioned 线 CLIP score 均未超过 0.30, 劣于 SD-v1.5)。而我们的方法则可以减少步数,同时将 CLIP score 提高,得益于所提出的 CFG-aware 蒸馏损失函数!尤其值得主要的是,下图中绿线(w-conditioned, 16 steps)与橙线(Ours,8 steps)的推理代价是一样的,但明显橙线更优,说明我们的技术路线比 w-conditioning [5] 在蒸馏 CFG guided SD 模型上更为有效。
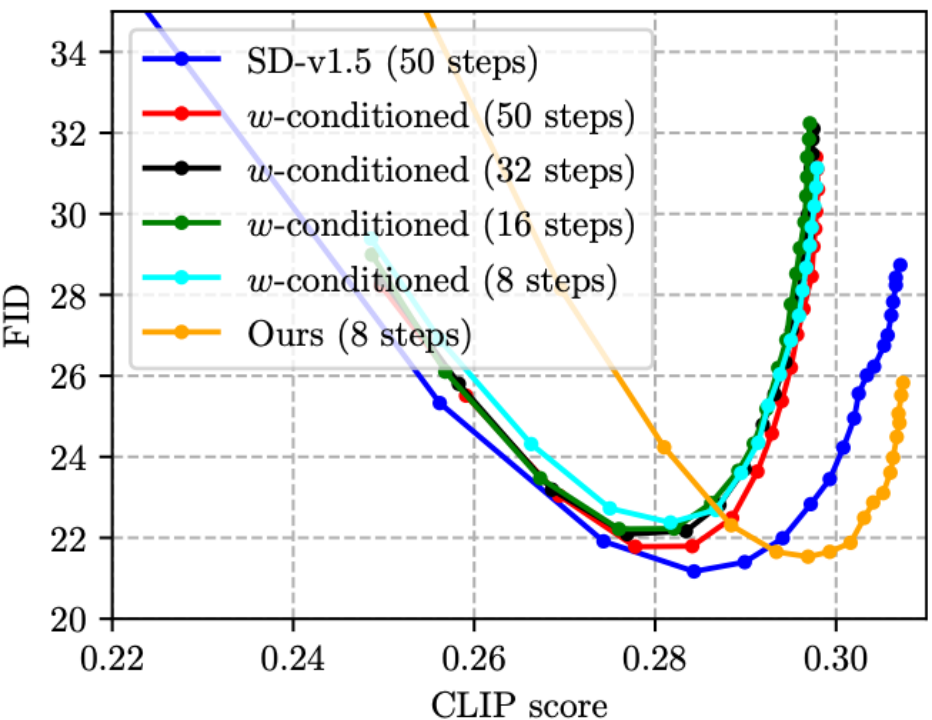
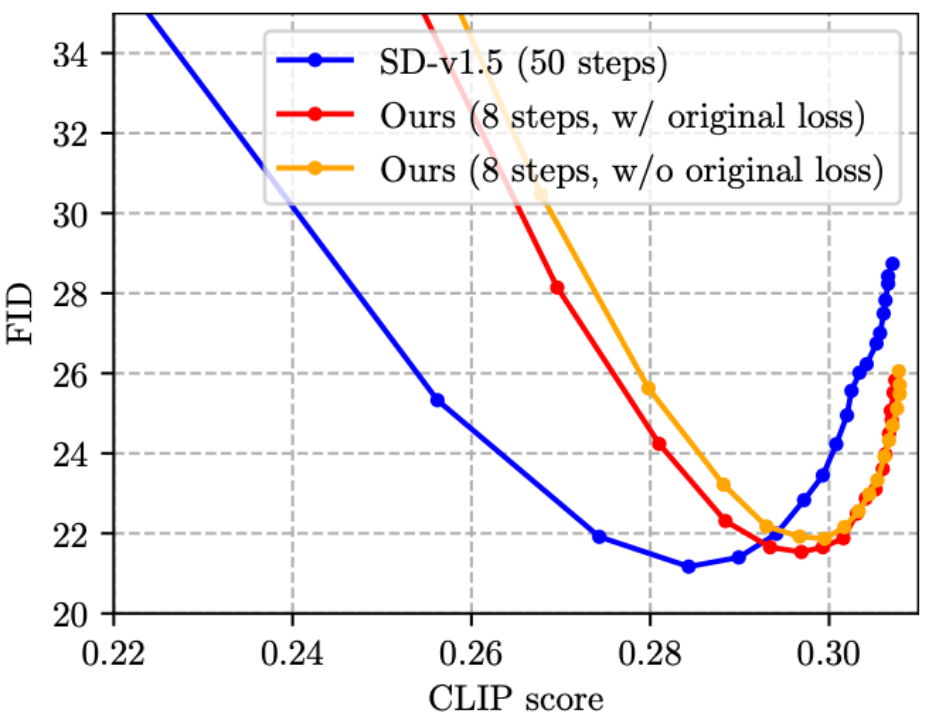
(3)既有 Step Distillation 的工作 [4, 5] 没有将原有的损失函数和蒸馏损失函数加在一起,熟悉图像分类知识蒸馏的朋友应该知道,这种设计直觉上来说是欠优的。于是我们提出把原有的损失函数加入到训练中,如下图所示,确实有效(小幅降低 FID)。
总结与未来工作
本文提出 SnapFusion,一种移动端高性能 Stable Diffusion 模型。SnapFusion 有两点核心贡献:(1)通过对现有 UNet 的逐层分析,定位速度瓶颈,提出一种新的高效 UNet 结构(Efficient UNet),可以等效替换原 Stable Diffusion 中的 UNet,实现 7.4x 加速;(2)对推理阶段的迭代步数进行优化,提出一种全新的步数蒸馏方案(CFG-aware Step Distillation),减少步数的同时可显著提升 CLIP score,实现 6.25x 加速。总体来说,SnapFusion 在 iPhone 14 Pro 上实现 2 秒内出图,这是目前已知最快的移动端 Stable Diffusion 模型。
未来工作:
1.SD 模型在多种图像生成场景中都可以使用,本文囿于时间,目前只关注了 text to image 这个核心任务,后期将跟进其他任务(如 inpainting,ControlNet 等等)。
2. 本文主要关注速度上的提升,并未对模型存储进行优化。我们相信所提出的 Efficient UNet 仍然具备压缩的空间,结合其他的高性能优化方法(如剪枝,量化),有望缩小存储,并将时间降低到 1 秒以内,离端上实时 SD 更进一步。
以上是iPhone两秒出图,目前已知的最快移动端Stable Diffusion模型来了的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 开源!超越ZoeDepth! DepthFM:快速且精确的单目深度估计!
Apr 03, 2024 pm 12:04 PM
开源!超越ZoeDepth! DepthFM:快速且精确的单目深度估计!
Apr 03, 2024 pm 12:04 PM
0.这篇文章干了啥?提出了DepthFM:一个多功能且快速的最先进的生成式单目深度估计模型。除了传统的深度估计任务外,DepthFM还展示了在深度修复等下游任务中的最先进能力。DepthFM效率高,可以在少数推理步骤内合成深度图。下面一起来阅读一下这项工作~1.论文信息标题:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想象一下,一个人工智能模型,不仅拥有超越传统计算的能力,还能以更低的成本实现更高效的性能。这不是科幻,DeepSeek-V2[1],全球最强开源MoE模型来了。DeepSeek-V2是一个强大的专家混合(MoE)语言模型,具有训练经济、推理高效的特点。它由236B个参数组成,其中21B个参数用于激活每个标记。与DeepSeek67B相比,DeepSeek-V2性能更强,同时节省了42.5%的训练成本,减少了93.3%的KV缓存,最大生成吞吐量提高到5.76倍。DeepSeek是一家探索通用人工智
 AI颠覆数学研究!菲尔兹奖得主、华裔数学家领衔11篇顶刊论文|陶哲轩转赞
Apr 09, 2024 am 11:52 AM
AI颠覆数学研究!菲尔兹奖得主、华裔数学家领衔11篇顶刊论文|陶哲轩转赞
Apr 09, 2024 am 11:52 AM
AI,的确正在改变数学。最近,一直十分关注这个议题的陶哲轩,转发了最近一期的《美国数学学会通报》(BulletinoftheAmericanMathematicalSociety)。围绕「机器会改变数学吗?」这个话题,众多数学家发表了自己的观点,全程火花四射,内容硬核,精彩纷呈。作者阵容强大,包括菲尔兹奖得主AkshayVenkatesh、华裔数学家郑乐隽、纽大计算机科学家ErnestDavis等多位业界知名学者。AI的世界已经发生了天翻地覆的变化,要知道,其中很多文章是在一年前提交的,而在这一
 替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
本月初,来自MIT等机构的研究者提出了一种非常有潜力的MLP替代方法——KAN。KAN在准确性和可解释性方面表现优于MLP。而且它能以非常少的参数量胜过以更大参数量运行的MLP。比如,作者表示,他们用KAN以更小的网络和更高的自动化程度重现了DeepMind的结果。具体来说,DeepMind的MLP有大约300,000个参数,而KAN只有约200个参数。KAN与MLP一样具有强大的数学基础,MLP基于通用逼近定理,而KAN基于Kolmogorov-Arnold表示定理。如下图所示,KAN在边上具
 你好,电动Atlas!波士顿动力机器人复活,180度诡异动作吓坏马斯克
Apr 18, 2024 pm 07:58 PM
你好,电动Atlas!波士顿动力机器人复活,180度诡异动作吓坏马斯克
Apr 18, 2024 pm 07:58 PM
波士顿动力Atlas,正式进入电动机器人时代!昨天,液压Atlas刚刚「含泪」退出历史舞台,今天波士顿动力就宣布:电动Atlas上岗。看来,在商用人形机器人领域,波士顿动力是下定决心要和特斯拉硬刚一把了。新视频放出后,短短十几小时内,就已经有一百多万观看。旧人离去,新角色登场,这是历史的必然。毫无疑问,今年是人形机器人的爆发年。网友锐评:机器人的进步,让今年看起来像人类的开幕式动作、自由度远超人类,但这真不是恐怖片?视频一开始,Atlas平静地躺在地上,看起来应该是仰面朝天。接下来,让人惊掉下巴
 快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
什么?疯狂动物城被国产AI搬进现实了?与视频一同曝光的,是一款名为「可灵」全新国产视频生成大模型。Sora利用了相似的技术路线,结合多项自研技术创新,生产的视频不仅运动幅度大且合理,还能模拟物理世界特性,具备强大的概念组合能力和想象力。数据上看,可灵支持生成长达2分钟的30fps的超长视频,分辨率高达1080p,且支持多种宽高比。另外再划个重点,可灵不是实验室放出的Demo或者视频结果演示,而是短视频领域头部玩家快手推出的产品级应用。而且主打一个务实,不开空头支票、发布即上线,可灵大模型已在快影
 超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂炼大模型,一互联网的数据不够用,根本不够用。训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。尤其在多模态任务中,这一问题尤为突出。一筹莫展之际,来自人大系的初创团队,用自家的新模型,率先在国内把“模型生成数据自己喂自己”变成了现实。而且还是理解侧和生成侧双管齐下,两侧都能生成高质量、多模态的新数据,对模型本身进行数据反哺。模型是啥?中关村论坛上刚刚露面的多模态大模型Awaker1.0。团队是谁?智子引擎。由人大高瓴人工智能学院博士生高一钊创立,高
 美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
最近,军事圈被这个消息刷屏了:美军的战斗机,已经能由AI完成全自动空战了。是的,就在最近,美军的AI战斗机首次公开,揭开了神秘面纱。这架战斗机的全名是可变稳定性飞行模拟器测试飞机(VISTA),由美空军部长亲自搭乘,模拟了一对一的空战。5月2日,美国空军部长FrankKendall在Edwards空军基地驾驶X-62AVISTA升空注意,在一小时的飞行中,所有飞行动作都由AI自主完成!Kendall表示——在过去的几十年中,我们一直在思考自主空对空作战的无限潜力,但它始终显得遥不可及。然而如今,
