

280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了

近段时间来,AI 对话助手在语言任务上取得了不小的进展。这种显著的进步不只是基于 LLM 强大的泛化能力,还应该归功于指令调优。这涉及到在一系列通过多样化和高质量指令的任务上对 LLM 进行微调。
借助指令调优获得零样本性能的一个潜在原因是,它内化了上下文。这很重要,特别是当用户输入跳过常识性的上下文时。通过纳入指令调优,LLM 获得了对用户意图的高度理解,即使在以前未见过的任务中也能表现出更好的零样本能力。
然而,一个理想的 AI 对话助手应该能够解决涉及多种模态的任务。这需要获得一个多样化和高质量的多模式指令跟随数据集。比如,LLaVAInstruct-150K 数据集(也被称为 LLaVA)就是一个常用的视觉 - 语言指令跟随数据集,它是使用 COCO 图像、指令和从 GPT-4 中获得的基于图像说明和目标边界框的响应构建的。但 LLaVA-Instruct-150K 具有三个局限性:有限的视觉多样性;使用图片作为单一视觉数据;上下文信息仅包含语言形态。
为了推动 AI 对话助手突破这些限制,来自新加坡南洋理工大学、微软雷蒙德研究院的学者们提出了多模态上下文指令调优数据集 MIMIC-IT,这是一个包含 280 万条多模态上下文指令 - 相应对的数据集,涵盖各种现实生活场景。

论文地址:https://arxiv.org/pdf/2306.05425.pdf
此外,为了高效地生成指令 - 响应对,研究者还介绍了「Sythus」,这是一个受 self-instruct 方法启发的指令 - 响应注释的自动化 pipeline。Sythus 采用系统信息、视觉注释和上下文中的例子来指导语言模型(GPT-4 或 ChatGPT)根据视觉语境生成指令 - 响应对,针对视觉语言模型的三个基本能力:感知、推理和规划。此外,英文的指令和响应被译成七种语言,以支持多种语言的使用。
特别值得注意的是,研究者在 MIMIC-IT 上训练了基于 OpenFlamingo 的多模态模型「Otter」。通过 ChatGPT、人类两个方面的评估,Otter 的多模态能力超越了近期的其他视觉 - 语言模型。
在一系列 Demo 中,研究者展示了 Otter 的多模态问答能力:
Q:接下来出哪张牌?
A:八筒。这样你就能留着四条和五条,等着凑成顺子。

Q:我想着陆了,怎么操作?
A:按一次左下按钮,左转,要着陆时拉右边的手刹。

Q:接下来怎么办?
A:把球传到中路,跑到球门,寻找进球机会。

接下来,让我们看看研究细节。
MIMIC-IT 数据集
MIMIC-IT 数据集包括 280 万个多模态指令 - 响应对,涵盖了基本能力:感知、推理和计划。每个指令都伴随着多模态的对话背景,使在 MIMIC-IT 上训练的 VLM 能够在交互式指令中表现出很好的熟练度,并能进行零样本的概括。
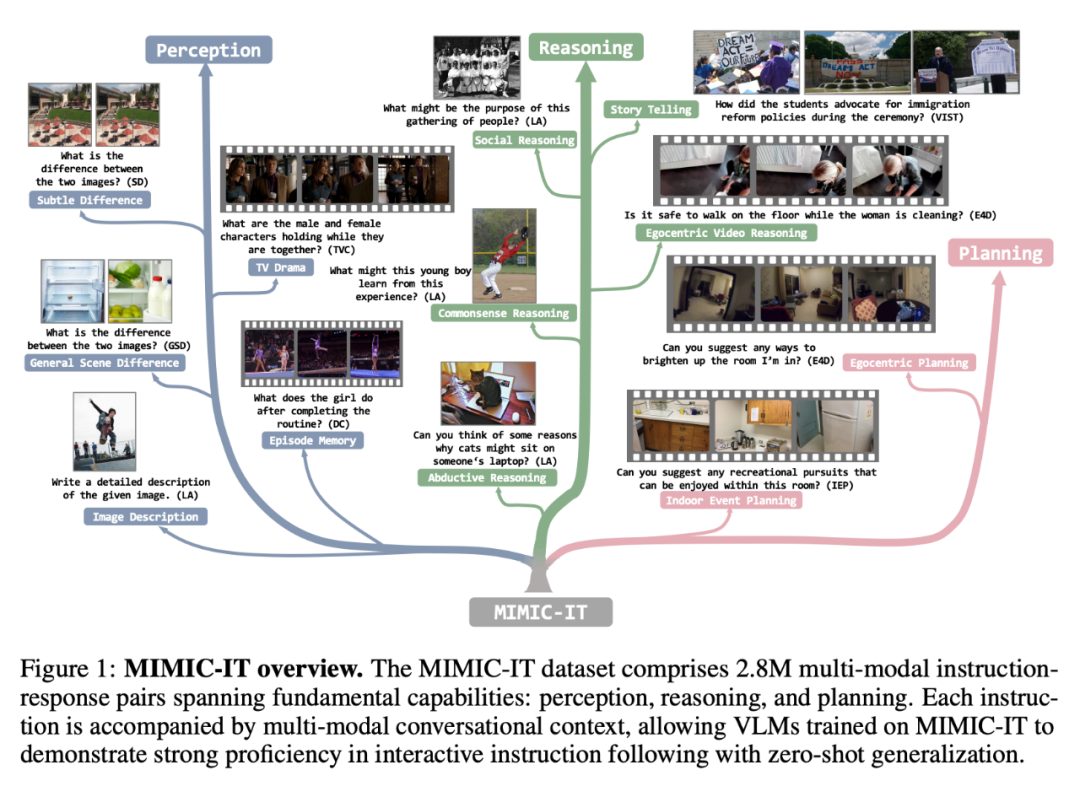
相比于 LLaVA,MIMIC-IT 的特点包括:
(1) 多样化的视觉场景,包含了一般场景、自我中心视角场景和室内 RGB-D 图像等不同数据集的图像和视频;
(2) 多个图像(或一个视频)作为视觉数据;
(3) 多模态的上下文信息,包括多个指令 - 响应对和多个图像或视频;
(4) 支持八种语言,包括英文、中文、西班牙文、日语、法语、德语、韩语和阿拉伯语。
下图进一步展示了二者的指令 - 响应对对比(黄色方框为 LLaVA):

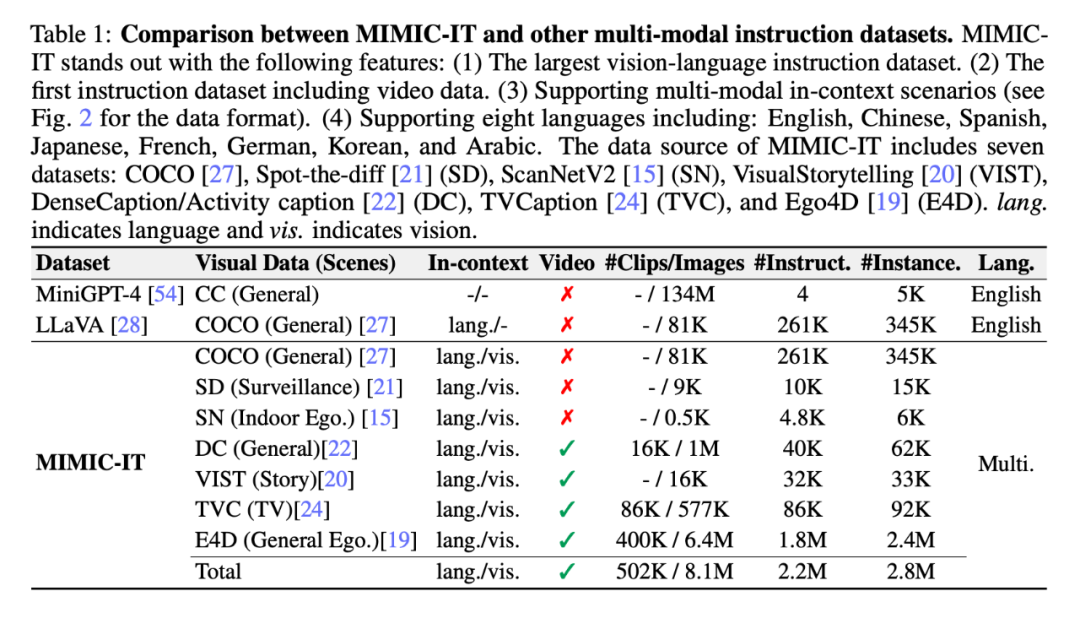
如表 1 所示,MIMIC-IT 的数据源来自七个数据集:COCO、Spot-the-diff (SD)、ScanNetV2 (SN)、VisualStorytelling (VIST) 、DenseCaption/Activity caption(DC)、TVCaption(TVC)和 Ego4D(E4D)。「上下文」这一列的「lang.」表示语言,「vis.」表示视觉。
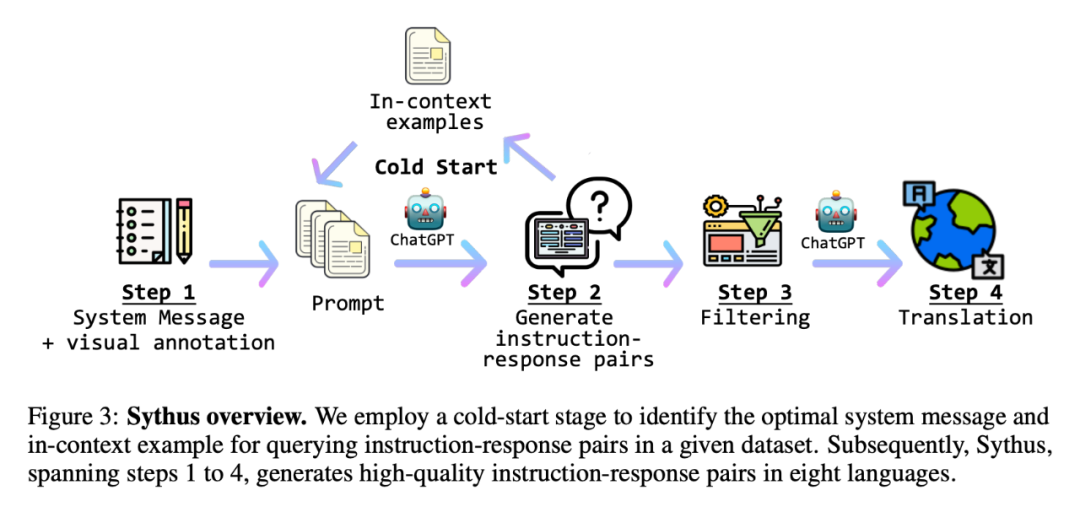
同时,研究者提出了 Sythus(图 3),这是一个自动化 pipeline,用于生成多种语言的高质量指令 - 响应对。在 LLaVA 提出的框架基础上,研究者利用 ChatGPT 来生成基于视觉内容的指令 - 响应对。为了确保生成的指令 - 响应对的质量,该 pipeline 将系统信息、视觉注释和上下文中的样本作为 ChatGPT 的 prompt。系统信息定义了所生成的指令 - 响应对的预期语气和风格,而视觉注释则提供了基本的图像信息,如边界框和图像描述。上下文中的样本帮助 ChatGPT 在语境中学习。
由于核心集的质量会影响后续的数据收集过程,研究者采用了一个冷启动策略,在大规模查询之前加强上下文中的样本。在冷启动阶段,采用启发式方法,仅通过系统信息和视觉注释来 prompt ChatGPT 收集上下文中的样本。这个阶段只有在确定了令人满意的上下文中的样本后才结束。在第四步,一旦获得指令 - 响应对,pipeline 会将它们扩展为中文(zh)、日文(ja)、西班牙文(es)、德文(de)、法文(fr)、韩文(ko)和阿拉伯语(ar)。进一步的细节,可参考附录 C,具体的任务 prompt 可以在附录 D 中找到。
经验性评估
随后,研究者展示了 MIMIC-IT 数据集的各种应用以及在其上训练的视觉语言模型 (VLM) 的潜在能力。首先,研究者介绍了使用 MIMIC-IT 数据集开发的上下文指令调优模型 Otter。而后,研究者探索了在 MIMIC-IT 数据集上训练 Otter 的各种方法,并讨论了可以有效使用 Otter 的众多场景。
图 5 是 Otter 在不同场景下的响应实例。由于在 MIMIC-IT 数据集上进行了训练,Otter 能够为情境理解和推理、上下文样本学习、自我中心的视觉助手服务。

最后,研究者在一系列基准测试中对 Otter 与其他 VLM 的性能进行了比较分析。
ChatGPT 评估
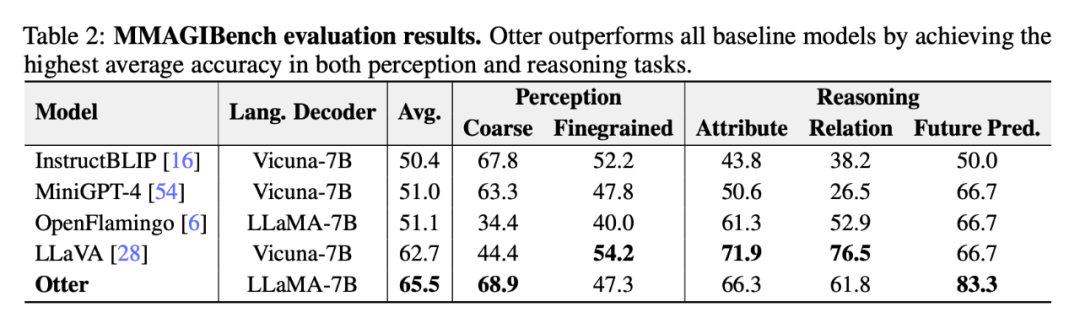
下表 2 展示了研究者利用 MMAGIBench 框架 [43] 对视觉语言模型的感知和推理能力进行广泛的评估。
人类评估
Multi-Modality Arena [32] 使用 Elo 评级系统来评估 VLM 响应的有用性和一致性。图 6 (b) 显示 Otter 展示了卓越的实用性和一致性,在最近的 VLM 中获得了最高的 Elo 评级。
少样本上下文学习基准评估
Otter 基于 OpenFlamingo 进行微调,OpenFlamingo 是一种专为多模态上下文学习而设计的架构。使用 MIMIC-IT 数据集进行微调后,Otter 在 COCO 字幕 (CIDEr) [27] 少样本评估(见图 6 (c))上的表现明显优于 OpenFlamingo。正如预期的那样,微调还带来了零样本评估的边际性能增益。

图 6:ChatGPT 视频理解的评估。
讨论
缺陷。虽然研究者已经迭代改进了系统消息和指令 - 响应示例,但 ChatGPT 容易出现语言幻觉,因此它可能会生成错误的响应。通常,更可靠的语言模型需要 self-instruct 数据生成。
未来工作。未来,研究者计划支持更多具体地 AI 数据集,例如 LanguageTable 和 SayCan。研究者也考虑使用更值得信赖的语言模型或生成技术来改进指令集。
以上是280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 泰拉瑞亚怎么用指令获得物品?-泰拉瑞亚怎么收藏物品?
Mar 19, 2024 am 08:13 AM
泰拉瑞亚怎么用指令获得物品?-泰拉瑞亚怎么收藏物品?
Mar 19, 2024 am 08:13 AM
泰拉瑞亚怎么用指令获得物品?一、什么是泰拉瑞亚给予物品指令在泰拉瑞亚游戏中,给予物品指令是一项非常实用的功能。通过这个指令,玩家可以直接获取需要的物品,而不必费力地去打怪或者传送到某个地点。这样可以极大地节省时间,提高游戏的效率,让玩家更专注于探索和建设世界。总的来说,这个功能让游戏体验变得更加流畅和愉快。二、如何使用泰拉瑞亚给予物品指令1.打开游戏并进入游戏界面。2.按下键盘上的“Enter”键,打开聊天窗口。3.在聊天窗口中输入指令的格式:“/give[玩家名称][物品ID][物品数量]”。
 使用PyTorch进行小样本学习的图像分类
Apr 09, 2023 am 10:51 AM
使用PyTorch进行小样本学习的图像分类
Apr 09, 2023 am 10:51 AM
近年来,基于深度学习的模型在目标检测和图像识别等任务中表现出色。像ImageNet这样具有挑战性的图像分类数据集,包含1000种不同的对象分类,现在一些模型已经超过了人类水平上。但是这些模型依赖于监督训练流程,标记训练数据的可用性对它们有重大影响,并且模型能够检测到的类别也仅限于它们接受训练的类。由于在训练过程中没有足够的标记图像用于所有类,这些模型在现实环境中可能不太有用。并且我们希望的模型能够识别它在训练期间没有见到过的类,因为几乎不可能在所有潜在对象的图像上进行训练。我们将从几个样本中学习
 VUE3快速入门:使用Vue.js指令实现选项卡切换
Jun 15, 2023 pm 11:45 PM
VUE3快速入门:使用Vue.js指令实现选项卡切换
Jun 15, 2023 pm 11:45 PM
本文旨在帮助初学者快速入手Vue.js3,实现简单的选项卡切换效果。Vue.js是一个流行的JavaScript框架,可用于构建可重用的组件、轻松管理应用程序的状态和处理用户界面的交互操作。Vue.js3是该框架的最新版本,相较于之前的版本变动较大,但基本原理并未改变。在本文中,我们将使用Vue.js指令实现选项卡切换效果,目的是让读者熟悉Vue.js的
 为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
Jul 25, 2024 am 06:42 AM
为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
Jul 25, 2024 am 06:42 AM
编辑|ScienceAI问答(QA)数据集在推动自然语言处理(NLP)研究发挥着至关重要的作用。高质量QA数据集不仅可以用于微调模型,也可以有效评估大语言模型(LLM)的能力,尤其是针对科学知识的理解和推理能力。尽管当前已有许多科学QA数据集,涵盖了医学、化学、生物等领域,但这些数据集仍存在一些不足。其一,数据形式较为单一,大多数为多项选择题(multiple-choicequestions),它们易于进行评估,但限制了模型的答案选择范围,无法充分测试模型的科学问题解答能力。相比之下,开放式问答
 在自定义数据集上实现OpenAI CLIP
Sep 14, 2023 am 11:57 AM
在自定义数据集上实现OpenAI CLIP
Sep 14, 2023 am 11:57 AM
在2021年1月,OpenAI宣布了两个新模型:DALL-E和CLIP。这两个模型都是多模态模型,以某种方式连接文本和图像。CLIP的全称是对比语言-图像预训练(ContrastiveLanguage-ImagePre-training),它是一种基于对比文本-图像对的预训练方法。为什么要介绍CLIP呢?因为目前火热的StableDiffusion并不是单一模型,而是由多个模型组成。其中一个关键组成部分是文本编码器,用于对用户的文本输入进行编码,而这个文本编码器就是CLIP模型中的文本编码器CL
 谷歌AI视频再出王炸!全能通用视觉编码器VideoPrism,性能刷新30项SOTA
Feb 26, 2024 am 09:58 AM
谷歌AI视频再出王炸!全能通用视觉编码器VideoPrism,性能刷新30项SOTA
Feb 26, 2024 am 09:58 AM
AI视频模型Sora爆火之后,Meta、谷歌等大厂纷纷下场做研究,追赶OpenAI的步伐。最近,来自谷歌团队的研究人员提出了一种通用视频编码器——VideoPrism。它能够通过单一冻结模型,处理各种视频理解任务。图片论文地址:https://arxiv.org/pdf/2402.13217.pdf比如,VideoPrism能够将下面视频中吹蜡烛的人分类、定位出来。图片视频-文本检索,根据文本内容,可以检索出视频中相应的内容。图片再比如,描述下面视频——一个小女孩正在玩积木。还可以进行QA问答。
 如何正确拆分数据集?常见的三种方法总结
Apr 08, 2023 pm 06:51 PM
如何正确拆分数据集?常见的三种方法总结
Apr 08, 2023 pm 06:51 PM
将数据集分解为训练集,可以帮助我们了解模型,这对于模型如何推广到新的看不见数据非常重要。 如果模型过度拟合可能无法很好地概括新的看不见的数据。因此也无法做出良好的预测。拥有适当的验证策略是成功创建良好预测,使用AI模型的业务价值的第一步,本文中就整理出一些常见的数据拆分策略。简单的训练、测试拆分将数据集分为训练和验证2个部分,并以80%的训练和20%的验证。 可以使用Scikit的随机采样来执行此操作。首先需要固定随机种子,否则无法比较获得相同的数据拆分,在调试时无法获得结果的复现。 如果数据集
 PyTorch 并行训练 DistributedDataParallel 完整代码示例
Apr 10, 2023 pm 08:51 PM
PyTorch 并行训练 DistributedDataParallel 完整代码示例
Apr 10, 2023 pm 08:51 PM
使用大型数据集训练大型深度神经网络 (DNN) 的问题是深度学习领域的主要挑战。 随着 DNN 和数据集规模的增加,训练这些模型的计算和内存需求也会增加。 这使得在计算资源有限的单台机器上训练这些模型变得困难甚至不可能。 使用大型数据集训练大型 DNN 的一些主要挑战包括:训练时间长:训练过程可能需要数周甚至数月才能完成,具体取决于模型的复杂性和数据集的大小。内存限制:大型 DNN 可能需要大量内存来存储训练期间的所有模型参数、梯度和中间激活。 这可能会导致内存不足错误并限制可在单台机器上训练的
