

75岁Hinton中国大会最新演讲「通往智能的两种道路」,最后感慨:我已经老了,未来交给年轻人

「但我已经老了,我所希望的是像你们这样的年轻有为的研究人员,去想出我们如何能够拥有这些超级智能,使我们的生活变得更好,而不是被它们控制。」
6 月 10 日,在 2023 北京智源大会的闭幕式演讲中,在谈到如何防止超级智能欺骗、控制人类的话题时,今年 75 岁的图灵奖得主 Geoffrey Hinton 不无感慨地说道。
Hinton 本次的演讲题目为「通往智能的两种道路」(Two Paths to Intelligence),即以数字形式执行的不朽计算和依赖于硬件的可朽计算,它们的代表分别是数字计算机和人类大脑。演讲最后,他重点谈到了大型语言模型(LLM)为他带来的对超级智能威胁的担忧,对于这个涉及人类文明未来的主题,他非常直白地展现了自己的悲观态度。
演讲一开始,Hinton 便宣称,超级智能(superintelligence)诞生的时间可能会比他曾经想象的早得多。这一观察引出了两大问题:(1)人工神经网络的智能水平将会很快超越真实神经网络吗?(2)人类是否能保证对超级 AI 的控制?在大会演讲中,他详细讨论了第一个问题;针对第二个问题,Hinton 在演讲的最后表示:超级智能可能将很快到来。

首先,让我们来看看传统的计算方式。计算机的设计原则是要能精准地执行指令,也就是说如果我们在不同的硬件上运行相同的程序(不管是不是神经网络),那么效果应该是一样的。这就意味着程序中包含的知识(如神经网络的权重)是不朽的,与具体的硬件没有关系。

为了实现知识的不朽,我们的做法是以高功率运行晶体管,使其能以数字化(digital)的方式可靠运行。但这样做的同时,我们就相当于抛弃了硬件其它一些性质,比如丰富的模拟性(analog)和高度的可变性。

传统计算机之所以采用那样的设计模式,是因为传统计算运行的程序都是人类编写的。现在随着机器学习技术的发展,计算机有了另一种获取程序和任务目标的方法:基于样本的学习。
这种新范式让我们可以放弃之前计算机系统设计的一项最基本原则,即软件设计与硬件分离;转而进行软件与硬件的协同设计。
软硬件分离设计的优点是能将同一程序运行在许多不同的硬件上,同时我们在设计程序时也能只看软件,不管硬件 —— 这也是计算机科学系与电子工程系能够分开设立的原因。
而对于软硬件协同设计,Hinton 提出了一个新概念:Mortal Computation。对应于前面提到不朽形式的软件,我们这里将其译为「可朽计算」。
可朽计算是什么?

可朽计算放弃了可在不同硬件上运行同一软件的不朽性,转而采纳了新的设计思路:知识与硬件的具体物理细节密不可分。这种新思路自然也有优有劣。其中主要的优势包括节省能源和低硬件成本。
在节能方面可以参考人脑,人脑就是一种典型的可朽计算装置。虽然人脑中也依然有一个比特的数字计算,即神经元要么发射要么不发射,但整体来说,人脑的绝大多数计算都是模拟计算,功耗非常低。
可朽计算也可以使用更低成本的硬件。相较于现如今以二维模式高精度生产的处理器,可朽计算的硬件能以三维模式「生长」出来,因为我们不需要明确知道硬件的连接方式以及每个部件的确切功能。很显然,为了实现计算硬件的「生长」,我们需要很多新型纳米技术或对生物神经元进行基因改造的能力。改造生物神经元的方法可能更容易实现,因为我们已经知道生物神经元大致能够完成我们想要的任务。
为了展示模拟计算的高效能力,Hinton 给出了一个示例:计算一个神经活动向量与一个权重矩阵的积(神经网络的大部分工作都是此类计算)。

对于该任务,当前计算机的做法是使用高功耗的晶体管将数值表示成数字化的比特形式,然后执行 O (n²) 数字运算将两个 n 比特的数值相乘。虽然这只是计算机上的单个运算,但却是 n² 个比特的运算。
而如果使用模拟计算呢?我们可以将神经活动视为电压,将权重视为电导;那么每一单位时间里,电压乘以电导可得到电荷,电荷可以叠加。这种工作方式的能效会高很多,而且其实现在已经存在这样工作的芯片了。但很不幸,Hinton 表示,现在人们还是要使用非常昂贵的转换器将模拟形式的结果转换成数字形式。他希望以后我们能在模拟领域完成整个计算过程。
可朽计算也面临着一些问题,其中最主要的是难以保证结果的一致性,即在不同硬件上的计算结果可能会有所差别。另外,在反向传播不可用的情况下,我们还需要找到新方法。
可朽计算面临的问题:反向传播不可用
在特定硬件上执行可朽计算的学习时,就需要让程序学习利用该硬件的特定模拟属性,但它们无需知道这些属性究竟是什么。举个例子,它们无需知道究竟神经元的内部连接方式究竟是怎样的,该神经元的输入和输出又是通过什么函数关联起来的。

这意味着我们不能使用反向传播算法来获取梯度,因为反向传播需要一个确切的前向传播模型。
那么既然可朽计算不能使用反向传播,我们又该怎么做呢?下面来看看在模拟硬件上执行的一个简单学习过程,其中用到的方法称为权重扰动。

首先,为网络中的每个权重生成一个随机向量,该向量由随机的小扰动构成。然后,基于一个或少量样本,测量全局目标函数在使用这个扰动向量后的变化情况。最后,根据目标函数的提升情况,将该扰动向量带来的效果按比例尺度永久化到权重之中。
这个算法的优点是其大致上的行为模式与反向传播一致,同样遵循梯度。但问题是它具有非常高的方差。因此,当网络规模增大时,在权重空间中选择随机移动方向时所产生的噪声会很大,让这个方法难以为继。这就意味着这种方法仅适用于小型网络,不适用于大型网络。

另一种方法是活动扰动,虽然它也存在类似的问题,但也能更好地用于更大型的网络。

活动扰动方法是要用随机向量对每个神经元的整体输入执行扰动,然后在一小批样本下观察目标函数的变化情况,再计算如何改变该神经元的权重以遵循梯度。
与权重扰动相比,活动扰动的噪声要小得多。并且这种方法已经足以学习 MNIST 这样的简单任务。如果你使用非常小的学习率,那么它的行为就与反向传播完全一样,但速度要慢得多。而如果学习率较大,那么噪声会很多,但也足够应对 MNIST 这样的任务。
但是如果我们的网络规模还要更大呢?Hinton 提到了两种方法。
第一种方法是使用巨量目标函数,也就是说不使用单个函数来定义大型神经网络的目标,而是使用大量函数来定义网络中不同神经元集团的局部目标。

这样一来,大型神经网络就被化整为零,我们就能使用活动扰动来学习小型的多层神经网络。但问题来了:这些目标函数从何而来?

其中一种可能性是在不同层级的局部图块上使用无监督对比学习。其工作方式是这样的:一个局部图块有多个表示层级,在每个层级,该局部图块会尽力与同一图像的所有其它局部图块产生的平均表示保持一致;与此同时,还要尽力与其它图像在该层级的表示保持差异。
Hinton 表示该方法在实践中的表现很不错。大概的做法是让每个表示层级都具有多个隐藏层,这样可以进行非线性的操作。这些层级使用活动扰动来进行贪婪学习并且不会反向传播到更低层级。由于它不能像反向传播那样传递很多层,因此不会像反向传播那样强大。
实际上这正是 Hinton 团队近些年最重要的研究成果之一,详情可参阅机器之心的报道《放弃反向传播后,Geoffrey Hinton 参与的前向梯度学习重磅研究来了》。

Mengye Ren 通过大量研究表明该方法是能够在神经网络中实际生效的,但操作起来却很复杂,实际效果也还赶不上反向传播。如果大型网络的深度更深,那么它与反向传播的差距还会更大。
Hinton 表示这个能利用模拟属性的学习算法只能说还算 OK,足以应对 MNIST 这样的任务,但也并不是真正好用,比如在 ImageNet 任务上的表现就不是很好。
可朽计算面临的问题:知识的传承
可朽计算面临的另一个主要问题是难以保证知识的传承。由于可朽计算与硬件高度相关,因此无法通过复制权重来复制知识,这就意味着当特定的硬件「死去」时,其学习到的知识也会一并消失。
Hinton 说解决该问题的最好方法是在硬件「死去」之前,将知识传递给学生。这类方法被称为知识蒸馏(knowledge distillation),这一概念是 Hinton 在 2015 年与 Oriol Vinyals 和 Jeff Dean 合著的论文《Distilling the Knowledge in a Neural Network》中最早提出的。

这一概念的基本思路很简单,就类似于教师教授学生知识:教师向学生展示不同输入的正确响应,学生尝试模仿教师的响应。
Hinton 使用了美国前总统特朗普发推文为例来进行直观的说明:特朗普发推时常常会对各种事件做出非常情绪化的回应,这会促使其追随者改变自己的「神经网络」,从而产生同样的情绪反应;这样一来,特朗普就将偏见蒸馏到了其追随者的头脑中,就像——Hinton 很显然并不喜欢特朗普。
知识蒸馏方法的效果如何呢?考虑到特朗普拥趸众多,效果应该不会差。Hinton 使用了一个例子进行解释:假设一个智能体需要将图像归类到 1024 个互不重叠的类别。

要指认出正确答案,我们只需要 10 比特信息。因此,要训练该智能体正确识别一个特定样本,只需要提供 10 比特信息来约束其权重即可。
但假如我们训练一个智能体使之与一个教师在这 1024 个类别上的概率大致保持一致呢?也就是说,使该智能体的概率分布与该教师一样。这个概率分布有 1023 个实数,如果这些概率都不是很小,那么其提供的约束就增多了几百倍。

为了确保这些概率不是太小,可以「高温」运行教师,在训练学生时也以「高温」运行学生。比如说,如果采用的是 logit,那就是输入 softmax 的东西。对于教师来说,可以基于温度参数对其进行缩放,进而得到一个更 soft 的分布;然后在训练学生时使用同样的温度。
下面来看一个具体的例子。下图是来自 MNIST 训练集的字符 2 的一些图像,对应的右侧是当运行教师的温度高时,教师为每张图像分配的概率。
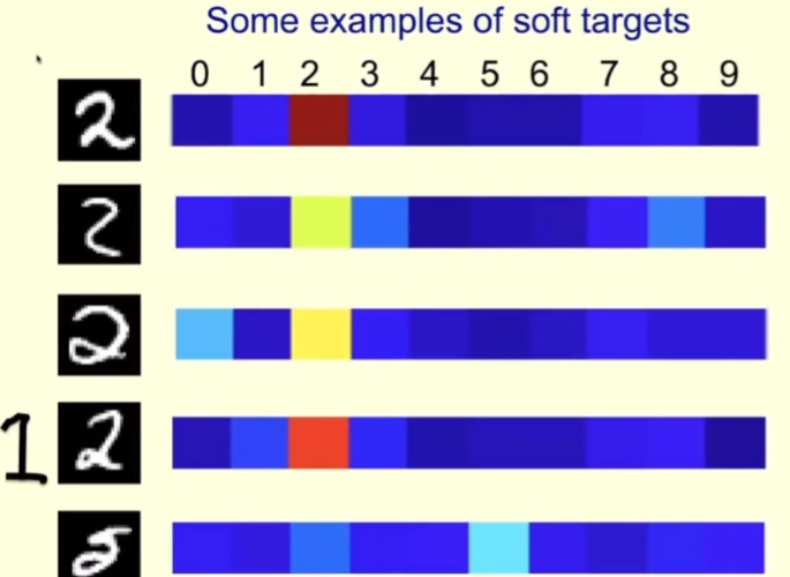
对于第一行,教师确信它是 2;教师对第二行也有信心是 2,但它也认为可能是 3 或 8。第三行则有些像 0。对于这个样本,教师应该说这是一个 2,但也应该留点可能性给 0。这样一来,比起直接告诉学生这是 2,学生能从中学到更多。
对于第四行,可以看到教师有信心它是 2,但它也认为有点可能是 1,毕竟有时候我们写的 1 就类似于图左侧画的那样。
对于第五行,教师出错了,认为它是 5(但根据 MNIST 标签应该是 2)。学生也能从教师的错误中学到很多。
蒸馏有一个很特殊的性质,那就是当使用教师给出的概率来训练学生时,那就在训练学生以老师那样的方式来进行泛化。如果教师为错误答案分配了一定的小概率,那么也会训练学生泛化到错误答案。

通常来说,我们训练模型是为了让模型在训练数据上得到正确答案,并能将这种能力泛化到测试数据上。但使用教师 - 学生训练模式时,我们是直接训练学生的泛化能力,因为学生的训练目标是能与老师一样地进行泛化。
很显然,我们可以创建更丰富的输出以供蒸馏。比如说我们可以为每张图像赋予一个描述,而不仅仅是单个标签,然后再训练学生来预测这些描述中的词。

接下来,Hinton 谈到了在智能体群中共享知识的研究。这也是一种传承知识的方式。

当多个智能体构成的社群互相共享知识时,共享知识的方式能在很大程度上决定计算执行的方式。

对于数字模型,我们可以通过复制创建大量使用相同权重的智能体。我们可以让这些智能体查看训练数据集的不同部分,让它们各自基于不同部分的数据计算权重的梯度,然后再对这些梯度进行平均。这样一来,每个模型都学到了其它每个模型学到的知识。这种训练策略的好处是能高效处理大量数据;如果模型很大,就可以在每次共享中共享大量比特。
同时,由于这种方法需要各个智能体的工作方式完全一样,因此就只能是数字模型才行。
权重共享的成本也很高。要让不同的硬件以同样的方式工作,就需要以极高的精准率生产计算机,使得它们在执行相同的指令时总是会得到相同的结果。另外,晶体管的功耗也不低。

蒸馏也能够替代权重共享。尤其是当你的模型用到了特定硬件的模拟属性时,那就不能使用权重共享了,而是必须使用蒸馏来共享知识。

用蒸馏共享知识的效率并不高,带宽很低。就像在学校里,教师都想把自己知道的知识灌进学生脑袋,但这是不可能的,因为我们是生物智能,你的权重对我没用。

这里先简单总结一下,上面提到了两种截然不同的执行计算的方式(数字计算和生物计算),并且智能体之间共享知识的方式也大相径庭。
那么现在发展正盛的大型语言模型(LLM)是哪种形式呢?它们是数字计算方式,能使用权重共享。

但是 LLM 的每个副本智能体都只能以非常低效的蒸馏方式学习文档中的知识。LLM 的做法是预测文档的下一个词,但是并没有教师对于下一个词的概率分布,它有的只是一个随机选择,即该文档作者在下一个词位置选用的词。LLM 实际上学习的是我们人类,但传递知识的带宽非常低。
话又说回来,虽然 LLM 的每个副本通过蒸馏学习的效率非常低,但它们数量多呀,可以多达几千个,也因此它们能学到比我们多数千倍的东西。也就是说现在的 LLM 比我们任何人都更加博学。
超级智能会终结人类文明吗?
接下来 Hinton 提出了一个问题:「如果这些数字智能并不通过蒸馏非常缓慢地学习我们,而是开始直接从现实世界学习,那么会发生什么呢?」

实际上,LLM 在学习文档时就已经在学习人类数千年所积累的知识了。因为人类会通过语言描述我们对世界的认识,那么数字智能就能直接通过文本学习来获得人类积累的知识。尽管蒸馏的速度很慢,但它们也确实学到了非常抽象的知识。
如果数字智能可以通过图像和视频建模来进行无监督学习呢?现在的互联网上已有大量影像数据可供使用,未来我们也许能够找到让 AI 有效学习这些数据的方法。另外,如果 AI 有机器臂等可以操控现实的方法,也能进一步帮助它们学习。
Hinton 相信,如果数字智能体能做到这些,那么它们的学习能力将远远胜过人类,学习速度也会很快。
现在就回到了 Hinton 在开始时提出的问题:如果 AI 的智能水平超过我们,我们还能控制住它们吗?
Hinton 表示,他做这场演讲主要是想表达出他的担忧。他说:「我认为超级智能出现的时间可能会远远快于我之前所想。」他给出了超级智能掌控人类的几种可能方式。

比如不良行为者可能会利用超级智能来操控选举或赢得战争(实际上现在已经有人在用已有 AI 做这些事情了)。
在这种情况下,如果你想要超级智能更高效,你可能会允许它自行创建子目标。而掌控更多权力是一个显而易见的子目标,毕竟权力越大,控制的资源越多,就更能帮助智能体实现其最终目标。然后超级智能可能会发现,通过操控运用权力的人就能轻松获得更多权力。
我们很难想象比我们聪明的存在以及我们与它们互动的方式。但 Hinton 认为比我们聪明的超级智能肯定能学会欺骗人类,毕竟人类有那么多小说和政治文献可供学习。
一旦超级智能学会了欺骗人类,它就能让人类去进行它想要的行为。这和人骗人其实没有本质区别。Hinton 举例说,如果某人想要入侵华盛顿的某栋大楼,他其实无需亲自前去,他只需要欺骗人们,让他们相信入侵这栋大楼是为了拯救民主。
「我觉得这非常可怕。」Hinton 的悲观溢于言表,「现在,我看不到该怎么防止这种情况发生,但我已经老了。」他希望青年才俊们能够找到方法让超级智能帮助人类生活得更好,而不是让人类落入它们的控制之中。
但他也表示我们有一个优势,尽管是相当小的优势,即 AI 不是进化而来的,而是人类创造的。这样一来,AI 就不具备原始人类那样的竞争性和目标。也许我们能够在创造 AI 的过程中为它们设定道德伦理原则。
不过,如果是智能水平远超人类的超级智能,这样做也不见得有效。Hinton 说他从没见过更高智能水平的东西被远远更低智能水平的东西控制的案例。就假设说如果是青蛙创造了人类,但现在的青蛙和人类又是谁控制谁呢?
最后,Hinton 悲观地放出了这次演讲的最后一页幻灯片:

这既标志着演讲的结束,也是对全体人类的警示:超级智能可能导致人类文明的终结。
以上是75岁Hinton中国大会最新演讲「通往智能的两种道路」,最后感慨:我已经老了,未来交给年轻人的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Windows 11 上的智能应用控制:如何打开或关闭它
Jun 06, 2023 pm 11:10 PM
Windows 11 上的智能应用控制:如何打开或关闭它
Jun 06, 2023 pm 11:10 PM
智能应用控制是Windows11中非常有用的工具,可帮助保护你的电脑免受可能损害数据的未经授权的应用(如勒索软件或间谍软件)的侵害。本文将解释什么是智能应用控制、它是如何工作的,以及如何在Windows11中打开或关闭它。什么是Windows11中的智能应用控制?智能应用控制(SAC)是Windows1122H2更新中引入的一项新安全功能。它与MicrosoftDefender或第三方防病毒软件一起运行,以阻止可能不必要的应用,这些应用可能会减慢设备速度、显示意外广告或执行其他意外操作。智能应用
 五官乱飞,张嘴、瞪眼、挑眉,AI都能模仿到位,视频诈骗要防不住了
Dec 14, 2023 pm 11:30 PM
五官乱飞,张嘴、瞪眼、挑眉,AI都能模仿到位,视频诈骗要防不住了
Dec 14, 2023 pm 11:30 PM
如此强大的AI模仿能力,真的防不住,完全防不住。现在AI的发展已经达到了这种程度吗?你前脚让自己的五官乱飞,后脚,一模一样的表情就被复现出来,瞪眼、挑眉、嘟嘴,不管多么夸张的表情,都模仿的非常到位。加大难度,让眉毛挑的再高些,眼睛睁的再大些,甚至连嘴型都是歪的,虚拟人物头像也能完美复现表情。当你在左侧调整参数时,右侧的虚拟头像也会相应地改变动作给嘴巴、眼睛一个特写,模仿的不能说完全相同,只能说表情一模一样(最右边)。这项研究来自慕尼黑工业大学等机构,他们提出了GaussianAvatars,这种
 MotionLM:多智能体运动预测的语言建模技术
Oct 13, 2023 pm 12:09 PM
MotionLM:多智能体运动预测的语言建模技术
Oct 13, 2023 pm 12:09 PM
本文经自动驾驶之心公众号授权转载,转载请联系出处。原标题:MotionLM:Multi-AgentMotionForecastingasLanguageModeling论文链接:https://arxiv.org/pdf/2309.16534.pdf作者单位:Waymo会议:ICCV2023论文思路:对于自动驾驶车辆安全规划来说,可靠地预测道路代理未来行为是至关重要的。本研究将连续轨迹表示为离散运动令牌序列,并将多智能体运动预测视为语言建模任务。我们提出的模型MotionLM具有以下几个优点:首
 你知道程序员再过几年会没落?
Nov 08, 2023 am 11:17 AM
你知道程序员再过几年会没落?
Nov 08, 2023 am 11:17 AM
《ComputerWorld》杂志曾经写过一篇文章,说“编程到1960年就会消失”,因为IBM开发了一种新语言FORTRAN,这种新语言可以让工程师写出他们所需的数学公式,然后提交给计算机运行,所以编程就会终结。图片又过了几年,我们听到了一种新说法:任何业务人员都可以使用业务术语来描述自己的问题,告诉计算机要做什么,使用这种叫做COBOL的编程语言,公司不再需要程序员了。后来,据说IBM开发出了一门名为RPG的新编程语言,可以让员工填写表格并生成报告,因此大部分企业的编程需求都可以通过它来完成图
 一文聊聊SLAM技术在自动驾驶的应用
Apr 09, 2023 pm 01:11 PM
一文聊聊SLAM技术在自动驾驶的应用
Apr 09, 2023 pm 01:11 PM
定位在自动驾驶中占据着不可替代的地位,而且未来有着可期的发展。目前自动驾驶中的定位都是依赖RTK配合高精地图,这给自动驾驶的落地增加了不少成本与难度。试想一下人类开车,并非需要知道自己的全局高精定位及周围的详细环境,有一条全局导航路径并配合车辆在该路径上的位置,也就足够了,而这里牵涉到的,便是SLAM领域的关键技术。什么是SLAMSLAM (Simultaneous Localization and Mapping),也称为CML (Concurrent Mapping and Localiza
 GR-1傅利叶智能通用人形机器人即将开始预售!
Sep 27, 2023 pm 08:41 PM
GR-1傅利叶智能通用人形机器人即将开始预售!
Sep 27, 2023 pm 08:41 PM
身高1.65米,体重55公斤,全身44个自由度,能够快速行走、敏捷避障、稳健上下坡、抗冲击干扰的人形机器人,现在可以带回家了!傅利叶智能的通用人形机器人GR-1已开启预售机器人大讲堂傅利叶智能FourierGR-1通用人形机器人现已开放预售。GR-1拥有高度仿生的躯干构型和拟人化的运动控制,全身44个自由度,具备行走、避障、越障、上下坡、抗干扰、适应不同路面等运动能力,是通用人工智能的理想载体。官网预售页面:www.fftai.cn/order#FourierGR-1#傅利叶智能需要进行改写的内
 华为将在智能穿戴领域推出玄玑感知系统 可根据心率评估用户情绪状态
Aug 29, 2024 pm 03:30 PM
华为将在智能穿戴领域推出玄玑感知系统 可根据心率评估用户情绪状态
Aug 29, 2024 pm 03:30 PM
近日,华为宣布将于9月推出一款搭载玄玑感知系统的全新智能穿戴新品,预计为华为的最新智能手表。该新品将集成先进的情绪健康监测功能,玄玑感知系统以其六大特性——准确性、全面性、快速性、灵活性、开放性和延展性——为用户提供全方位的健康评估。系统采用超感知模组,优化了多通道光路架构技术,大幅提升了心率、血氧和呼吸率等基础指标的监测精度。此外,玄玑感知系统还拓展了基于心率数据的情绪状态研究,不仅限于生理指标,还能评估用户的情绪状态和压力水平,支持超过60项运动健康指标监测,涵盖心血管、呼吸、神经、内分泌、
 行人轨迹预测有哪些有效的方法和普遍的Base方法?顶会论文分享!
Oct 17, 2023 am 11:13 AM
行人轨迹预测有哪些有效的方法和普遍的Base方法?顶会论文分享!
Oct 17, 2023 am 11:13 AM
轨迹预测近两年风头正猛,但大都聚焦于车辆轨迹预测方向,自动驾驶之心今天就为大家分享顶会NeurIPS上关于行人轨迹预测的算法—SHENet,在受限场景中人类的移动模式通常在一定程度上符合有限的规律。基于这个假设,SHENet通过学习隐含的场景规律来预测一个人的未来轨迹。文章已经授权自动驾驶之心原创!笔者的个人理解由于人类运动的随机性和主观性,当前预测一个人的未来轨迹仍然是一个具有挑战性的问题。然而,由于场景限制(例如平面图、道路和障碍物)以及人与人或人与物体的交互性,在受限场景中人类的移动模式通
