

美版贴吧8000小组自爆停摆!拒绝数据被谷歌OpenAI白嫖,CEO被网友骂翻:背刺第三方应用

一觉醒来,「美国贴吧」Reddit 8000多个子区中的七千多个,已经消失了。
几个月前,Reddit忽然开始对API访问收费,而且价格高到离谱,导致的结果就是,直接扼杀了第三方客户端。
Reddit的网友们直接炸了,而子区管理员们也纷纷揭竿而起,从昨天开始临时或永久关闭子区,以示抗议。
而且,随着时间的推移,抗议的浪潮非但没有平息,反而越烧越旺。
Reddit不让白嫖数据,Apollo含泪关闭
自2008年以来,Reddit API一直是以免费的方式开放给第三方。
然而今年,Reddit忽然下定决心——我们的宝贵优质数据,可不能再被白嫖了!
背后原因,竟是跟AIGC有关。
ChatGPT的火爆,让大厂们紧锣密鼓地纷纷开始训练大模型。训练用的高质量数据从哪里来?当然是从网上抓来的。
以前,Reddit的数据,都被OpenAI和谷歌免费拿来训练大语言模型。
虽然其中某些数据是以非结构化的方式收集的,但Reddit的API让这些公司可以很容易地直接查找和整理数据。
而今年,大概是看到马斯克给Twitter API搞了个收费模式,Reddit也眼馋了,有样学样地学了去,开始捂着自家的优质数据坐地起价。
推特在1月限制了所有第三方客户端和应用,规定开发者不能用推特的API创建类似推特的产品。
Reddit CEO Steve Huffman在4月的采访中就曾表示,Reddit的数据语料库「真的很有价值」,他才不想让全世界大科技公司一分钱都不用花,就轻易获取了这些巨额价值的数据。
4月,Reddit宣布向科技公司收费,无论是OpenAI等财力雄厚的公司还是小型开发商。
最近Reddit更进一步,决定开启API付费模式——换句话说,那些需要调用API的第三方应用开发者,也要交钱。
比如,Apollo的iOS客户端开发者Christian Selig得到的回复是:每5000万次调用1.2万美元。这相当于每用1,000次,就要向Reddit支付0.24美元。
按照Apollo高达70亿次的调用量来看,想要继续运行的话,Selig就需要每年上交2000万美元的巨款。
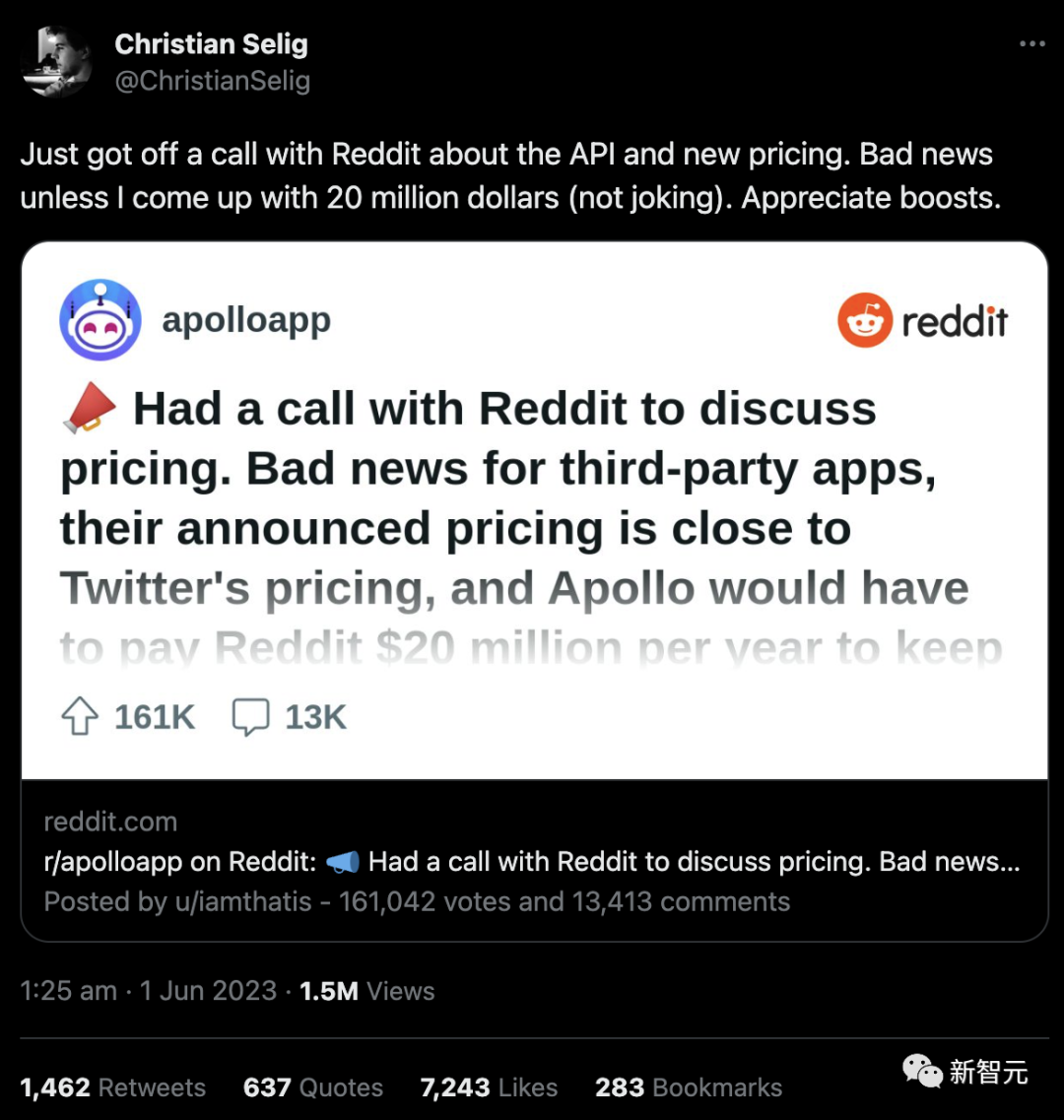
在6月9日,Christian Selig不得不含泪表示:Apollo服务将于6月30日关闭。

掀起反Reddit刺杀第三方应用运动
「Apollo关闭事件」仿佛一个导火索,直接引爆了Reddit网友们抗议的热潮。毕竟很多网友用的也是第三方APP,如果收费也会损害到自家的利益。
就算有些第三方应用能通过对用户收取不高的费用而生存下来,也相当于是把成本转嫁到了Reddit用户身上。
而对于像Reddit这种UGC(用户生产内容)社区来说,你不给内容创作者发钱也就算了,居然还敢向他们收费?
不「黑」你「黑」谁?
一周前,愤怒的网友们,直接发起了「社区变黑运动」,反对Reddit刺杀第三方应用。
他们宣布,6月12日起,部分子社区将会关闭48小时,还有一些子社区将会永远关停。
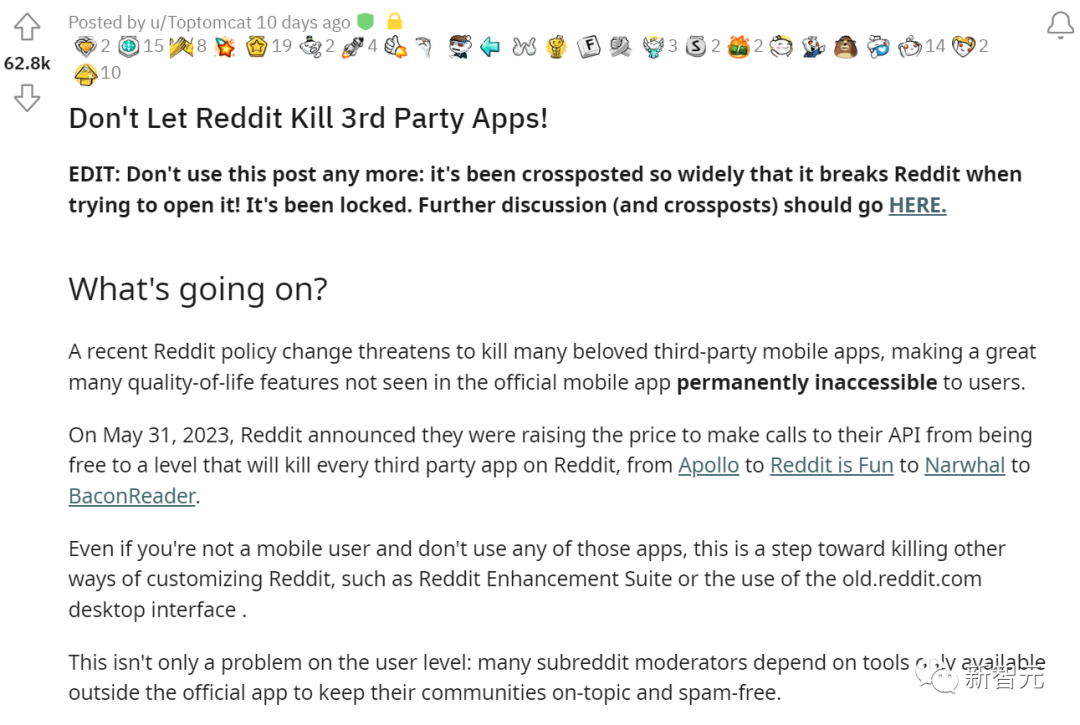
随即,一些最大、最活跃的Reddit社区,包括r/funny,r/gaming,r/gadgets和r/todayilearned等,都被设成了「私人」。换句话说就是,拒绝普通用户的访问。
r/Music,r/gaming,r/science和r/todayilearnd等子社区也都拥有超过3000万订阅者。一些像r/Music这样的子社区,干脆计划无限期抗议。
粗略统计至少有26亿用户受到了影响。
在本周,Reddit已经陷入了全面崩溃。
这是因为,与大多数其他社交媒体平台不同,Reddit严重依赖于「mods」,也就是版主,只要版主想关,那子社区是说关就关。
在发起运动的帖子中,版主们告诉网友们可以做的事:发起投诉,四处发帖在全网传播本运动的宗旨,向周围的人(以及自家的猫lol)抱怨此事给自己造成的伤害。
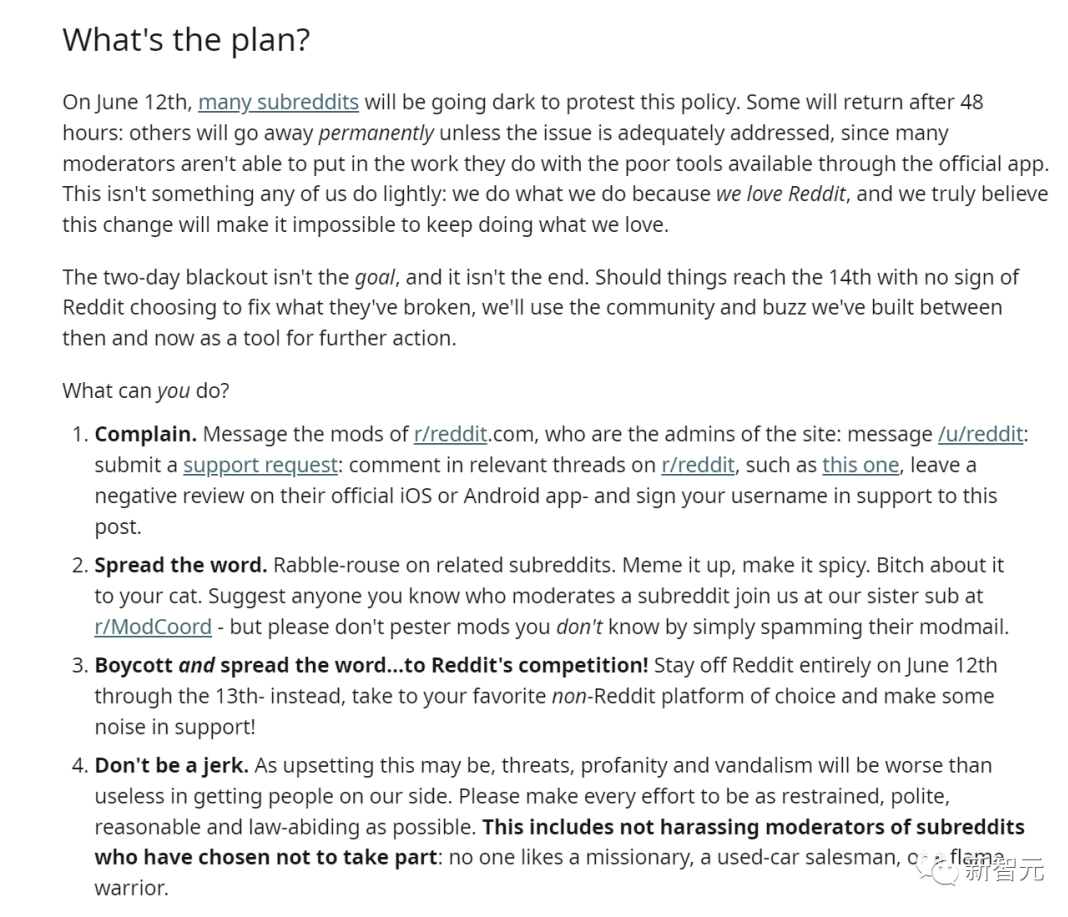
看到这个架势,Reddit也吓到了,它立马宣布:对于以浏览为目的的APP,可以免除收费。
但对于其他开发者而言,形势依然非常严峻。随着Apollo开发者宣布不得不在月底关闭应用,一大波开发者也表示自己撑不下去了。
现在,关闭的子区已经接近8000个,其中就包括最近异常火爆的r/ChatGPT。
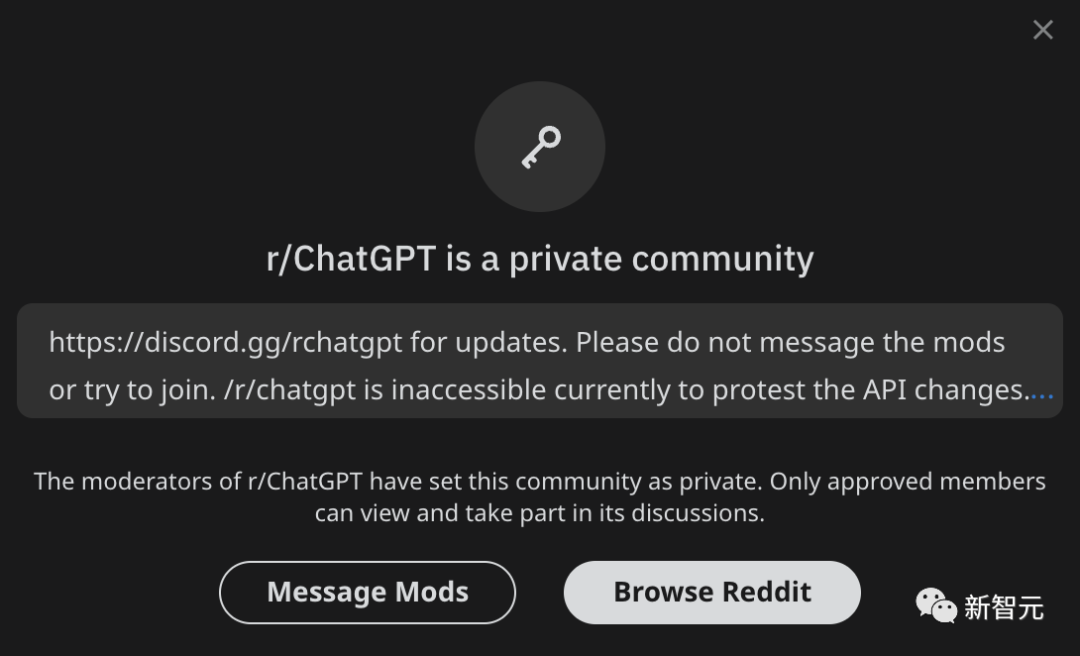
暂时还「健在」的社区中,网友们也在讨论着:咱们要不要也加入变黑活动?
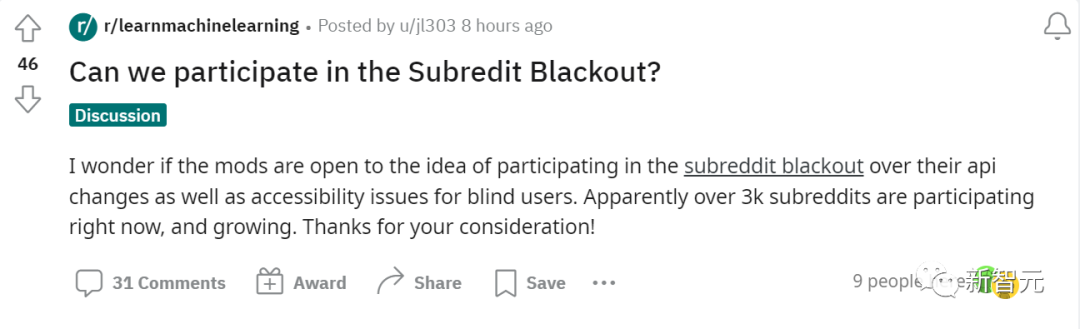
CEO解释:是真的没办法(坚决不改)
关于这场轰轰烈烈的关组运动,Reddit CEO Steve Huffman主持了一项问答活动,但似乎Reddit并无意对收费政策做出什么改变,反而更激起了网友们的愤怒。
虽然社区的版主可能会感到不满,但Reddit不会再义务补贴需要使用大规模数据的商业公司,因为Reddit首先需要能存活下去。
根据Huffman的说法,当平台本身难以维持生计时,保持API免费访问的成本就太高了。
此外,与第三方应用不同,Reddit没有盈利。
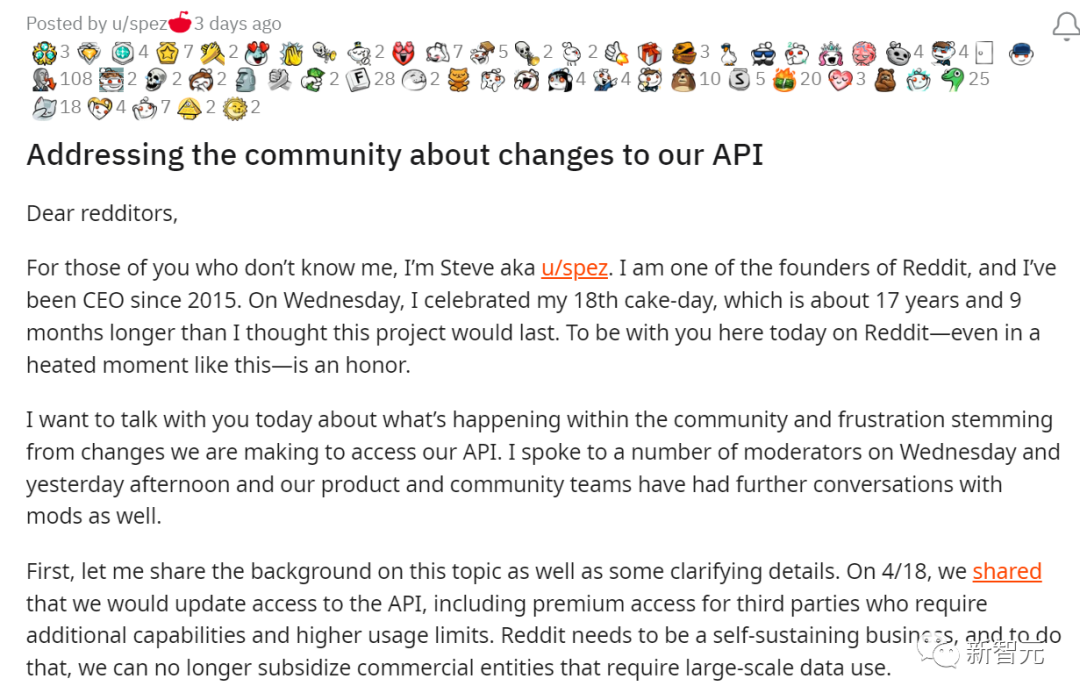
Huffman在给网友们的公开信中强调:Reddit需要成为能自负盈亏的业务
毫不意外,公开信发出后,Huffman被网友们喷惨了。

整件事最可怕的地方在于你的处理方式,你开出的荒谬的价钱,以及你试图把它宣扬成一件好事的举动
Huffman强调,90%的第三方应用程序仍然可以免费访问Reddit的API。因为只要应用程序每分钟只需要100个API 或10个API查询,Reddit就可以为它们提供免费的API访问,具体取决于客户端 ID。
此外,「非商业的、以浏览性为中心的应用程序和工具将继续免费访问。」
但对于其他需要更高API访问率的应用程序,他们就确实需要付费了。
因此Apollo,Reddit is Fun和Sync这类应用就,不得不在定价生效前关闭。
有人发现,在问答活动中,Huffman还对Apollo开发者Selig拍了几张照片。
Selig声称,Reddit告诉其他开发者,公司正在受到他的勒索和威胁。
谈及「勒索疑云」时,Hoffman说道:Selig对我们说一件事,对外说的又是另一件事,他还会录音并且泄漏私人电话,我真不知道怎么和他做生意。
而Selig回击道:编造一个勒索的故事,只会让我们的合作更困难,你意识不到吗?
收费的原因
自家没米了
Reddit的历史融资超过12亿美元,怎么突然间就这么着急搞钱呢?
CEO在6月7日发给员工的一封电子邮件中表示,正在裁撤约5%的员工(约90人)。
他还表示,Reddit将在年内把招聘人数从早期计划的300人减少至约100人。
因为经济环境不好,科技公司降本增效已经不是新闻了。
虽然Reddit是私营公司,没有公开的财务信息,但是裁员缩招计划表明,Reddit现在确实差钱了。
不想让AI公司白嫖数据
OpenAI在研究中透露,Reddit是其用于训练底层人工智能模型的大量资源之一。
一想到当前最火热最不差钱的AI巨头要用自己的数据,而你自己账户上的钱已经不多了,如果你是Reddit的CEO,
你会怎么做?
Reddit的CEO 霍夫曼说:「我们的网站上有很多『真实的对话』,有很多人们只会在心理治疗或是互助团体中才会说的,甚至从来不会向外人吐露的真心话。我们不会把这些高价值的东西免费提供给大公司们使用。」
但是为啥定价这么高,直接让一些第三应用的开发商都活不下去了?
据Apollo的开发人员发帖称,Reddit的新费用如此之高,主要原因是他们定价是针对那些财大气粗而且需要大量训练数据的AI公司,而且是具有惩罚性的。
但这样的定价却误伤到了那些没什么钱,同样必须依附于Reddit数据的第三方应用开发商。
但是和那些「吸血」Reddit的AI公司不同的是,这些第三方应用对于Reddit的用户和社区来说是能提供很高价值的。
从某种程度上来说,Reddit让他们活不下去,也是在伤害自己。
今年下半年准备上市,估值却下降40%
Reddit这么着急搞钱,还有一个重要原因。
有消息称,今年Reddit还将重启沉寂数年的IPO计划。
本来Reddit计划2021年就要上市,当时CFO都重新换了一个,就是为了筹备IPO。
结果遇上经济寒冬,资本市场几乎冻结至今。
Reddit自己的股东之一, Fidelity ,对于自己持有的Reddit股份的内部估值,截止今年4月份都已经下跌了40%。
现在自己的股东都不看好自己的股份,那到时候上市,公众投资者必然也不会买账。
所以Reddit要想让自己能够在未来以更高的估值上市,提高盈利能力,给予投资者信心,是他们现在最应该做的事。
那还是那句话,你是CEO你会怎么做?
网友热议
因为Reddit的用户量巨大,所以这次「黑版」运动也激起了大量的讨论。
支持API收费
有网友直指要害地提出,关键是Reddit要想办法能从大公司的剥削中收到合理的费用。
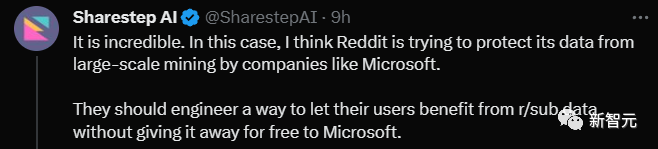
Reddit的运营是要成本的,所以他们要么就得向用户收钱,要么用户就得看广告。

还有完全站在Reddit的角度留言,认为要么用户每月出10到20美元支持公司运转,要么就得找广告商或者外部投资者,但是现在用户只想要一个不产生收入完全免费提供服务的产品。

让平台持续亏本运转不是长久之计,因为维护成本真的不低。公司要给员工开工资,因为员工要养家糊口。这样公司就得挣钱,但是如果绝大多数用户都不付钱公司怎么可能挣钱呢?

这其实没什么问题啊,完全可以理解。
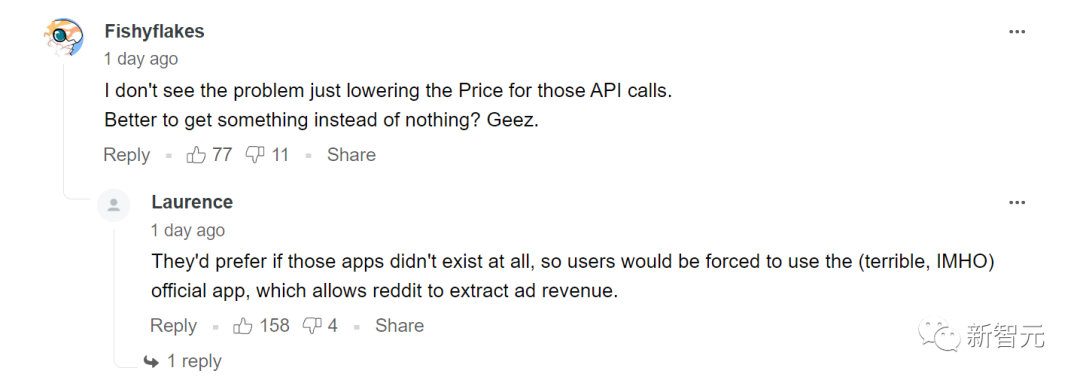
太过贪婪,不支持收费
社交媒体需要鼓励甚至奖励用户发帖而不是惩罚用户,不理解为什么Reddit要让它的用户群体远离这个社区。

对于网络空间中能产生有效讨论的社区来说,背后运营的公司想要大规模盈利是会伤害平台本身的。公司为了追逐利润已经让这样的社区越来越少。
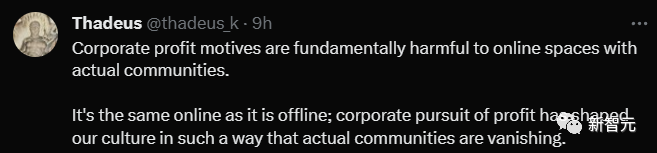
由于「黑版」之后很多用户没法访问自己的想看的内容,不如转向「去中心化」的产品,彻底免除类似的烦恼,还贴心的给了大家po上了每个常用平台的替代方案。
在科技公司工作的网友表示,公司这样做就是赤裸裸的贪婪,只要能赚钱,这些公司都舍弃公司和产品的核心价值。

Reddit之所以敢这么做还是因为缺乏有效的竞争。它是世界上最大的「论坛」。没了它用户也没有其他的选择了。
以上是美版贴吧8000小组自爆停摆!拒绝数据被谷歌OpenAI白嫖,CEO被网友骂翻:背刺第三方应用的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 使用ddrescue在Linux上恢复数据
Mar 20, 2024 pm 01:37 PM
使用ddrescue在Linux上恢复数据
Mar 20, 2024 pm 01:37 PM
DDREASE是一种用于从文件或块设备(如硬盘、SSD、RAM磁盘、CD、DVD和USB存储设备)恢复数据的工具。它将数据从一个块设备复制到另一个块设备,留下损坏的数据块,只移动好的数据块。ddreasue是一种强大的恢复工具,完全自动化,因为它在恢复操作期间不需要任何干扰。此外,由于有了ddasue地图文件,它可以随时停止和恢复。DDREASE的其他主要功能如下:它不会覆盖恢复的数据,但会在迭代恢复的情况下填补空白。但是,如果指示工具显式执行此操作,则可以将其截断。将数据从多个文件或块恢复到单
 开源!超越ZoeDepth! DepthFM:快速且精确的单目深度估计!
Apr 03, 2024 pm 12:04 PM
开源!超越ZoeDepth! DepthFM:快速且精确的单目深度估计!
Apr 03, 2024 pm 12:04 PM
0.这篇文章干了啥?提出了DepthFM:一个多功能且快速的最先进的生成式单目深度估计模型。除了传统的深度估计任务外,DepthFM还展示了在深度修复等下游任务中的最先进能力。DepthFM效率高,可以在少数推理步骤内合成深度图。下面一起来阅读一下这项工作~1.论文信息标题:DepthFM:FastMonocularDepthEstimationwithFlowMatching作者:MingGui,JohannesS.Fischer,UlrichPrestel,PingchuanMa,Dmytr
 如何多条件使用Excel过滤功能
Feb 26, 2024 am 10:19 AM
如何多条件使用Excel过滤功能
Feb 26, 2024 am 10:19 AM
如果您需要了解如何在Excel中使用具有多个条件的筛选功能,以下教程将指导您完成相应步骤,确保您可以有效地对数据进行筛选和排序。Excel的筛选功能是非常强大的,能够帮助您从大量数据中提取所需的信息。这个功能可以根据您设定的条件,过滤数据并只显示符合条件的部分,让数据的管理变得更加高效。通过使用筛选功能,您可以快速找到目标数据,节省了查找和整理数据的时间。这个功能不仅可以应用在简单的数据列表上,还可以根据多个条件进行筛选,帮助您更精准地定位所需信息。总的来说,Excel的筛选功能是一个非常实用的
 谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
Apr 01, 2024 pm 07:46 PM
谷歌狂喜:JAX性能超越Pytorch、TensorFlow!或成GPU推理训练最快选择
Apr 01, 2024 pm 07:46 PM
谷歌力推的JAX在最近的基准测试中性能已经超过Pytorch和TensorFlow,7项指标排名第一。而且测试并不是在JAX性能表现最好的TPU上完成的。虽然现在在开发者中,Pytorch依然比Tensorflow更受欢迎。但未来,也许有更多的大模型会基于JAX平台进行训练和运行。模型最近,Keras团队为三个后端(TensorFlow、JAX、PyTorch)与原生PyTorch实现以及搭配TensorFlow的Keras2进行了基准测试。首先,他们为生成式和非生成式人工智能任务选择了一组主流
 iPhone上的蜂窝数据互联网速度慢:修复
May 03, 2024 pm 09:01 PM
iPhone上的蜂窝数据互联网速度慢:修复
May 03, 2024 pm 09:01 PM
在iPhone上面临滞后,缓慢的移动数据连接?通常,手机上蜂窝互联网的强度取决于几个因素,例如区域、蜂窝网络类型、漫游类型等。您可以采取一些措施来获得更快、更可靠的蜂窝互联网连接。修复1–强制重启iPhone有时,强制重启设备只会重置许多内容,包括蜂窝网络连接。步骤1–只需按一次音量调高键并松开即可。接下来,按降低音量键并再次释放它。步骤2–该过程的下一部分是按住右侧的按钮。让iPhone完成重启。启用蜂窝数据并检查网络速度。再次检查修复2–更改数据模式虽然5G提供了更好的网络速度,但在信号较弱
 特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人Optimus最新视频出炉,已经可以在厂子里打工了。正常速度下,它分拣电池(特斯拉的4680电池)是这样的:官方还放出了20倍速下的样子——在小小的“工位”上,拣啊拣啊拣:这次放出的视频亮点之一在于Optimus在厂子里完成这项工作,是完全自主的,全程没有人为的干预。并且在Optimus的视角之下,它还可以把放歪了的电池重新捡起来放置,主打一个自动纠错:对于Optimus的手,英伟达科学家JimFan给出了高度的评价:Optimus的手是全球五指机器人里最灵巧的之一。它的手不仅有触觉
 阿里7B多模态文档理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
阿里7B多模态文档理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
多模态文档理解能力新SOTA!阿里mPLUG团队发布最新开源工作mPLUG-DocOwl1.5,针对高分辨率图片文字识别、通用文档结构理解、指令遵循、外部知识引入四大挑战,提出了一系列解决方案。话不多说,先来看效果。复杂结构的图表一键识别转换为Markdown格式:不同样式的图表都可以:更细节的文字识别和定位也能轻松搞定:还能对文档理解给出详细解释:要知道,“文档理解”目前是大语言模型实现落地的一个重要场景,市面上有很多辅助文档阅读的产品,有的主要通过OCR系统进行文字识别,配合LLM进行文字理
 超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂炼大模型,一互联网的数据不够用,根本不够用。训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。尤其在多模态任务中,这一问题尤为突出。一筹莫展之际,来自人大系的初创团队,用自家的新模型,率先在国内把“模型生成数据自己喂自己”变成了现实。而且还是理解侧和生成侧双管齐下,两侧都能生成高质量、多模态的新数据,对模型本身进行数据反哺。模型是啥?中关村论坛上刚刚露面的多模态大模型Awaker1.0。团队是谁?智子引擎。由人大高瓴人工智能学院博士生高一钊创立,高
