

Yann LeCun团队新研究成果:对自监督学习逆向工程,原来聚类是这样实现的

自监督学习(SSL)在最近几年取得了很大的进展,在许多下游任务上几乎已经达到监督学习方法的水平。但是,由于模型的复杂性以及缺乏有标注训练数据集,我们还一直难以理解学习到的表征及其底层的工作机制。此外,自监督学习中使用的 pretext 任务通常与特定下游任务的直接关系不大,这就进一步增大了解释所学习到的表征的复杂性。而在监督式分类中,所学到的表征的结构往往很简单。
相比于传统的分类任务(目标是准确将样本归入特定类别),现代 SSL 算法的目标通常是最小化包含两大成分的损失函数:一是对增强过的样本进行聚类(不变性约束),二是防止表征坍缩(正则化约束)。举个例子,对于同一样本经过不同增强之后的数据,对比式学习方法的目标是让这些样本的分类结果一样,同时又要能区分经过增强之后的不同样本。另一方面,非对比式方法要使用正则化器(regularizer)来避免表征坍缩。
自监督学习可以利用辅助任务(pretext)无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,从而可以学习到对下游任务有价值的表征。近日,图灵奖得主 Yann LeCun 在内的多位研究者发布了一项研究,宣称对自监督学习进行了逆向工程,让我们得以了解其训练过程的内部行为。

论文地址:https://arxiv.org/abs/2305.15614v2
这篇论文通过一系列精心设计的实验对使用 SLL 的表征学习进行了深度分析,帮助人们理解训练期间的聚类过程。具体来说,研究揭示出增强过的样本会表现出高度聚类的行为,这会围绕共享同一图像的增强样本的含义嵌入形成质心。更出人意料的是,研究者观察到:即便缺乏有关目标任务的明确信息,样本也会根据语义标签发生聚类。这表明 SSL 有能力根据语义相似性对样本进行分组。
问题设置
由于自监督学习(SSL)通常用于预训练,让模型做好准备适应下游任务,这带来了一个关键问题:SSL 训练会对所学到的表征产生什么影响?具体来说,训练期间 SSL 的底层工作机制是怎样的,这些表征函数能学到什么类别?
为了调查这些问题,研究者在多种设置上训练了 SSL 网络并使用不同的技术分析了它们的行为。
数据和增强:本文提到的所有实验都使用了 CIFAR100 图像分类数据集。为了训练模型,研究者使用了 SimCLR 中提出的图像增强协议。每一个 SSL 训练 session 都执行 1000 epoch,使用了带动量的 SGD 优化器。
骨干架构:所有的实验都使用了 RES-L-H 架构作为骨干,再加上了两层多层感知器(MLP)投射头。
线性探测(linear probing):为了评估从表征函数中提取给定离散函数(例如类别)的有效性,这里使用的方法是线性探测。这需要基于该表征训练一个线性分类器(也称为线性探针),这需要用到一些训练样本。
样本层面的分类:为了评估样本层面的可分离性,研究者创建了一个专门的新数据集。
其中训练数据集包含来自 CIFAR-100 训练集的 500 张随机图像。每张图像都代表一个特定类别并会进行 100 种不同的增强。因此,训练数据集包含 500 个类别的共计 50000 个样本。测试集依然是用这 500 张图像,但要使用 20 种不同的增强,这些增强都来自同一分布。因此,测试集中的结果由 10000 个样本构成。为了在样本层面衡量给定表征函数的线性或 NCC(nearest class-center / 最近类别中心)准确度,这里采用的方法是先使用训练数据计算出一个相关的分类器,然后再在相应测试集上评估其准确率。
揭示自监督学习的聚类过程
在帮助分析深度学习模型方面,聚类过程一直以来都发挥着重要作用。为了直观地理解 SSL 训练,图 1 通过 UMAP 可视化展示了网络的训练样本的嵌入空间,其中包含训练前后的情况并分了不同层级。
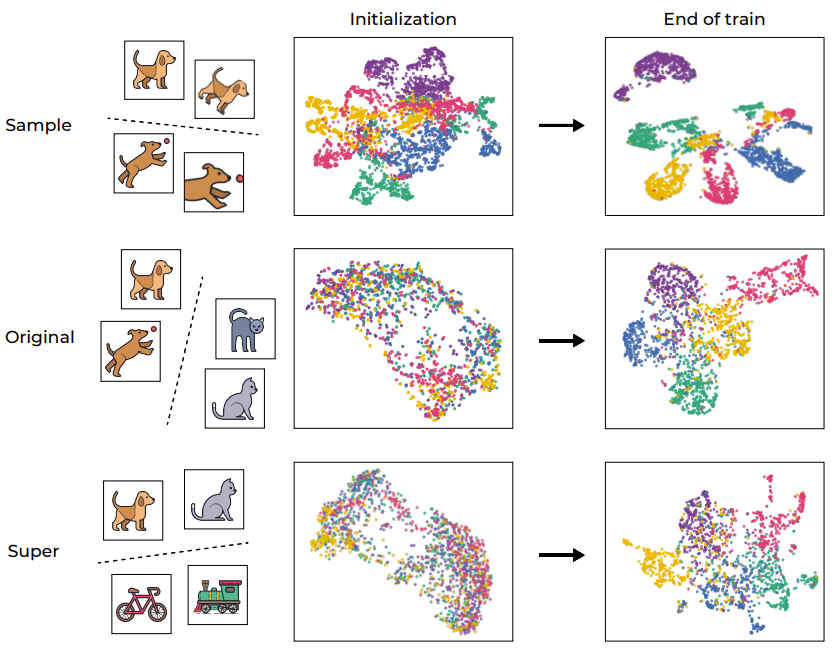
图 1:SSL 训练引起的语义聚类
正如预期的那样,训练过程成功地在样本层面上对样本进行了聚类,映射了同一图像的不同增强(如第一行图示)。考虑到目标函数本身就会鼓励这种行为(通过不变性损失项),因此这样的结果倒是不意外。然而,更值得注意的是,该训练过程还会根据标准 CIFAR-100 数据集的原始「语义类别」进行聚类,即便该训练过程期间缺乏标签。有趣的是,更高的层级(超类别)也能被有效聚类。这个例子表明,尽管训练流程直接鼓励的是样本层面的聚类,但 SSL 训练的数据表征还会在不同层面上根据语义类别来进行聚类。
为了进一步量化这个聚类过程,研究者使用 VICReg 训练了一个 RES-10-250。研究者衡量的是 NCC 训练准确度,既有样本层面的,也有基于原始类别的。值得注意的是,SSL 训练的表征在样本层面上展现出了神经坍缩(neural collapse,即 NCC 训练准确度接近于 1.0),然而在语义类别方面的聚类也很显著(在原始目标上约为 0.41)。
如图 2 左图所示,涉及增强(网络直接基于其训练的)的聚类过程大部分都发生在训练过程初期,然后陷入停滞;而在语义类别方面的聚类(训练目标中并未指定)则会在训练过程中持续提升。
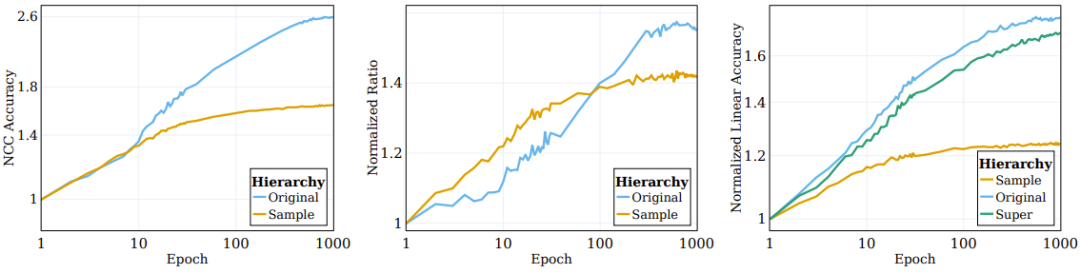
图 2:SSL 算法根据语义目标对对数据的聚类
之前有研究者观察到,监督式训练样本的顶层嵌入会逐渐向一个类质心的结构收敛。为了更好地理解 SSL 训练的表征函数的聚类性质,研究者调查了 SSL 过程中的类似情况。其 NCC 分类器是一种线性分类器,其表现不会超过最佳的线性分类器。通过评估 NCC 分类器与同样数据上训练的线性分类器的准确度之比,能够在不同粒度层级上研究数据聚类。图 2 的中图给出了样本层面类别和原始目标类别上的这一比值的变化情况,其值根据初始化的值进行了归一化。随着 SSL 训练的进行,NCC 准确度和线性准确度之间的差距会变小,这说明增强后的样本会根据其样本身份和语义属性逐渐提升聚类水平。
此外,该图还说明,样本层面的比值起初会高一些,这说明增强后的样本会根据它们的身份进行聚类,直到收敛至质心(NCC 准确度和线性准确度的比值在 100 epoch 时 ≥ 0.9)。但是,随着训练继续,样本层面的比值会饱和,而类别层面的比值会继续增长并收敛至 0.75 左右。这说明增强后的样本首先会根据样本身份进行聚类,实现之后,再根据高层面的语义类别进行聚类。
SSL 训练中隐含的信息压缩
如果能有效进行压缩,那么就能得到有益又有用的表征。但 SSL 训练过程中是否会出现那样的压缩却仍是少有人研究的课题。
为了了解这一点,研究者使用了互信息神经估计(Mutual Information Neural Estimation/MINE),这种方法可以估计训练过程中输入与其对应嵌入表征之间的互信息。这个度量可用于有效衡量表征的复杂度水平,其做法是展现其编码的信息量(比特数量)。
图 3 的中图报告了在 5 个不同的 MINE 初始化种子上计算得到的平均互信息。如图所示,训练过程会有显著的压缩,最终形成高度紧凑的训练表征。
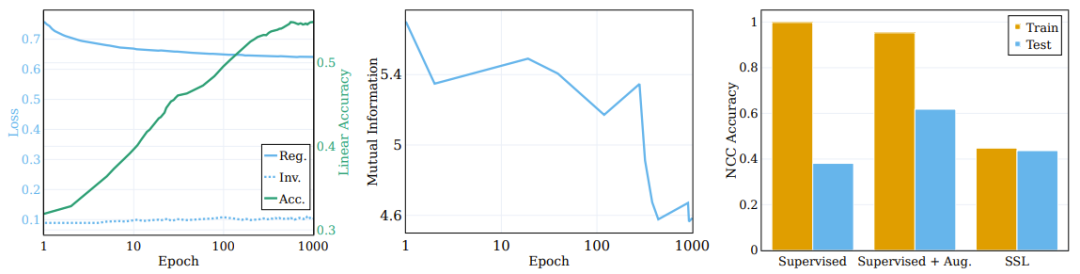
左侧图表显示了 SSL 训练模型在训练过程中正则化和不变性损失的变化以及原始目标线性测试准确度。(中)训练期间输入和表征之间的互信息的压缩。(右)SSL 训练学习聚类的表征。
正则化损失的作用
目标函数包含两项:不变性和正则化。不变性项的主要功能是强化同一样本的不同增强的表征之间的相似性。而正则化项的目标是帮助防止表征坍缩。
为了探究这些分量对聚类过程的作用,研究者将目标函数分解为了不变性项和正则化项,并观察它们在训练过程中的行为。比较结果见图 3 左图,其中给出了原始语义目标上的损失项的演变以及线性测试准确度。不同于普遍流行的想法,不变性损失项在训练过程中并不会显著改善。相反,损失(以及下游的语义准确度)的改善是通过降低正则化损失实现的。
由此可以得出结论:SSL 的大部分训练过程都是为了提升语义准确度和所学表征的聚类,而非样本层面的分类准确度和聚类。
从本质上讲,这里的发现表明:尽管自监督学习的直接目标是样本层面的分类,但其实大部分训练时间都用于不同层级上基于语义类别的数据聚类。这一观察结果表明 SSL 方法有能力通过聚类生成有语义含义的表征,这也让我们得以了解其底层机制。
监督学习和 SSL 聚类的比较
深度网络分类器往往是基于训练样本的类别将它们聚类到各个质心。但学习得到的函数要能真正聚类,必须要求这一性质对测试样本依然有效;这是我们期望得到的效果,但效果会差一点。
这里有一个有趣的问题:相比于监督学习的聚类,SSL 能在多大程度上根据样本的语义类别来执行聚类?图 3 右图报告了在不同场景(使用和不使用增强的监督学习以及 SSL)的训练结束时的 NCC 训练和测试准确度比率。
尽管监督式分类器的 NCC 训练准确度为 1.0,显著高于 SSL 训练的模型的 NCC 训练准确度,但 SSL 模型的 NCC 测试准确度却略高于监督式模型的 NCC 测试准确度。这说明两种模型根据语义类别的聚类行为具有相似的程度。有意思的是,使用增强样本训练监督式模型会稍微降低 NCC 训练准确度,却会大幅提升 NCC 测试准确度。
探索语义类别学习和随机性的影响
语义类别是根据输入的内在模式来定义输入和目标的关系。另一方面,如果将输入映射到随机目标,则会看到缺乏可辨别的模式,这会导致输入和目标之间的连接看起来很任意。
研究者还探究了随机性对模型学习所需目标的熟练程度的影响。为此,他们构建了一系列具有不同随机度的目标系统,然后检查了随机度对所学表征的影响。他们在用于分类的同一数据集上训练了一个神经网络分类器,然后使用其不同 epoch 的目标预测作为具有不同随机度的目标。在 epoch 0 时,网络是完全随机的,会得到确定的但看似任意的标签。随着训练进行,其函数的随机性下降,最终得到与基本真值目标对齐的目标(可认为是完全不随机)。这里将随机度归一化到 0(完全不随机,训练结束时)到 1(完全随机,初始化时)之间。
图 4 左图展示了不同随机度目标的线性测试准确度。每条线都对应于不同随机度的 SSL 不同训练阶段的准确度。可以看到,在训练过程中,模型会更高效地捕获与「语义」目标(更低随机度)更接近的类别,同时在高随机度的目标上没有表现出显著的性能改进。
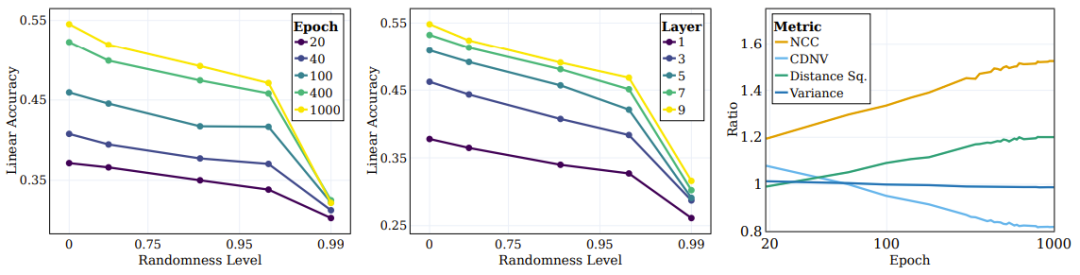
图 4:SSL 持续学习语义目标,而非随机目标
深度学习的一个关键问题是理解中间层对分类不同类型类别的作用和影响。比如,不同的层会学到不同类型的类别吗?研究者也探索了这个问题,其做法是在训练结束时不同目标随机度下评估不同层表征的线性测试准确度。如图 4 中图所示,随着随机度下降,线性测试准确度持续提升,更深度的层在所有类别类型上都表现更优,而对于接近语义类别的分类,性能差距会更大。
研究者还使用了其它一些度量来评估聚类的质量:NCC 准确度、CDNV、平均每类方差、类别均值之间的平均平方距离。为了衡量表征随训练进行的改进情况,研究者为语义目标和随机目标计算了这些指标的比率。图 4 右图展示了这些比率,结果表明相比于随机目标,表征会更加偏向根据语义目标来聚类数据。有趣的是,可以看到 CDNV(方差除以平方距离)会降低,其原因仅仅是平方距离的下降。方差比率在训练期间相当稳定。这会鼓励聚类之间的间距拉大,这一现象已被证明能带来性能提升。
了解类别层级结构和中间层
之前的研究已经证明,在监督学习中,中间层会逐渐捕获不同抽象层级的特征。初始的层倾向于低层级的特征,而更深的层会捕获更抽象的特征。接下来,研究者探究了 SSL 网络能否学习更高层面的层次属性以及哪些层面与这些属性的关联性更好。
在实验中,他们计算了三个层级的线性测试准确度:样本层级、原始的 100 个类别、20 个超类别。图 2 右图给出了为这三个不同类别集计算的数量。可以观察到,在训练过程中,相较于样本层级的类别,在原始类别和超类别层级上的表现的提升更显著。
接下来是 SSL 训练的模型的中间层的行为以及它们捕获不同层级的目标的能力。图 5 左和中图给出了不同训练阶段在所有中间层上的线性测试准确度,这里度量了原始目标和超目标。图 5 右图给出超类别和原始类别之间的比率。
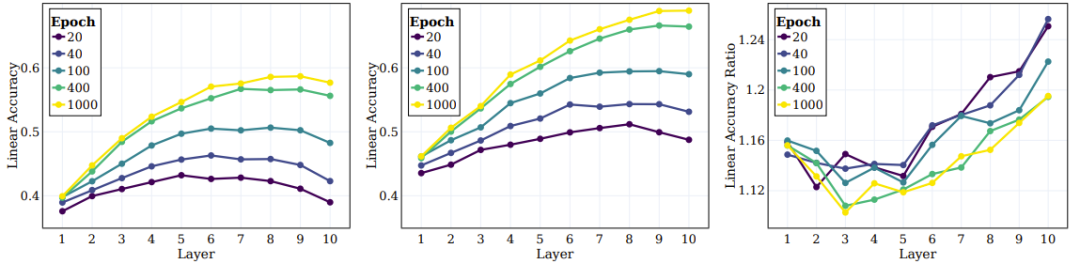
图 5:SSL 能在整体中间层中有效学习语义类别
研究者基于这些结果得到了几个结论。首先,可以观察到随着层的深入,聚类效果会持续提升。此外,与监督学习情况类似,研究者发现在 SSL 训练期间,网络每一层的线性准确度都有提升。值得注意的是,他们发现对于原始类别,最终层并不是最佳层。近期的一些 SSL 研究表明:下游任务能高度影响不同算法的性能。本文的研究拓展了这一观察结果,并且表明网络的不同部分可能适合不同的下游任务与任务层级。根据图 5 右图,可以看出,在网络的更深层,超类别的准确度的提升幅度超过原始类别。
以上是Yann LeCun团队新研究成果:对自监督学习逆向工程,原来聚类是这样实现的的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 深入探讨模型、数据和框架:一份详尽的54页高效大语言模型综述
Jan 14, 2024 pm 07:48 PM
深入探讨模型、数据和框架:一份详尽的54页高效大语言模型综述
Jan 14, 2024 pm 07:48 PM
大规模语言模型(LLMs)在许多重要任务中展现出了引人注目的能力,包括自然语言理解、语言生成和复杂推理,并对社会产生了深远的影响。然而,这些出色的能力却需要大量的训练资源(如左图所示)和较长的推理时间(如右图所示)。因此,研究人员需要开发有效的技术手段来解决它们的效率问题。此外,从图的右侧还可以看出,一些高效的LLMs(LanguageModels)如Mistral-7B,已经成功应用于LLMs的设计和部署中。这些高效的LLMs在保持与LLaMA1-33B相近的准确性的同时,能够大大减少推理内存
 扩散+超分辨率模型强强联合,谷歌图像生成器Imagen背后的技术
Apr 10, 2023 am 10:21 AM
扩散+超分辨率模型强强联合,谷歌图像生成器Imagen背后的技术
Apr 10, 2023 am 10:21 AM
近年来,多模态学习受到重视,特别是文本 - 图像合成和图像 - 文本对比学习两个方向。一些 AI 模型因在创意图像生成、编辑方面的应用引起了公众的广泛关注,例如 OpenAI 先后推出的文本图像模型 DALL・E 和 DALL-E 2,以及英伟达的 GauGAN 和 GauGAN2。谷歌也不甘落后,在 5 月底发布了自己的文本到图像模型 Imagen,看起来进一步拓展了字幕条件(caption-conditional)图像生成的边界。仅仅给出一个场景的描述,Imagen 就能生成高质量、高分辨率
 碾压H100,英伟达下一代GPU曝光!首个3nm多芯片模块设计,2024年亮相
Sep 30, 2023 pm 12:49 PM
碾压H100,英伟达下一代GPU曝光!首个3nm多芯片模块设计,2024年亮相
Sep 30, 2023 pm 12:49 PM
3纳米制程,性能超越H100!最近,据外媒DigiTimes爆料,英伟达正在开发下一代GPU,代号为「Blackwell」的B100据称,作为面向人工智能(AI)和高性能计算(HPC)应用的产品,B100将采用台积电的3nm工艺制程,以及更为复杂的多芯片模块(MCM)设计,并将于2024年第四季度现身。对于垄断了人工智能GPU市场80%以上份额的英伟达来说,则可以借着B100趁热打铁,在这波AI部署的热潮中进一步狙击AMD、英特尔等挑战者。根据英伟达的估计,到2027年,该领域的产值预计将达到约
 多模态大模型最全综述来了!7位微软研究员大力合作,5大主题,成文119页
Sep 25, 2023 pm 04:49 PM
多模态大模型最全综述来了!7位微软研究员大力合作,5大主题,成文119页
Sep 25, 2023 pm 04:49 PM
多模态大模型最全综述来了!由微软7位华人研究员撰写,足足119页——它从目前已经完善的和还处于最前沿的两类多模态大模型研究方向出发,全面总结了五个具体研究主题:视觉理解视觉生成统一视觉模型LLM加持的多模态大模型多模态agent并重点关注到一个现象:多模态基础模型已经从专用走向通用。Ps.这也是为什么论文开头作者就直接画了一个哆啦A梦的形象。谁适合阅读这份综述(报告)?用微软的原话来说:只要你有兴趣学习多模态基础模型的基础知识和最新进展,无论你是专业研究员还是在校学生,这个内容都非常适合你一起来
 SD社区的I2V-Adapter:无需配置,即插即用,完美兼容图生视频插件
Jan 15, 2024 pm 07:48 PM
SD社区的I2V-Adapter:无需配置,即插即用,完美兼容图生视频插件
Jan 15, 2024 pm 07:48 PM
图像到视频生成(I2V)任务是计算机视觉领域的一项挑战,旨在将静态图像转化为动态视频。这个任务的难点在于从单张图像中提取并生成时间维度的动态信息,同时保持图像内容的真实性和视觉上的连贯性。现有的I2V方法通常需要复杂的模型架构和大量的训练数据来实现这一目标。近期,快手主导的一项新研究成果《I2V-Adapter:AGeneralImage-to-VideoAdapterforVideoDiffusionModels》发布。该研究引入了一种创新的图像到视频转换方法,提出了一种轻量级适配器模块,即I
 揭晓2022年玻尔兹曼奖:Hopfield网络创始人荣获奖项
Aug 13, 2023 pm 08:49 PM
揭晓2022年玻尔兹曼奖:Hopfield网络创始人荣获奖项
Aug 13, 2023 pm 08:49 PM
两位获得2022年玻尔兹曼奖的科学家已经公布,这个奖项由IUPAP统计物理委员会(C3)设立,旨在表彰在统计物理学领域取得杰出成就的研究者。获奖者必须是之前没有获得过玻尔兹曼奖或诺贝尔奖的科学家。这个奖项始于1975年,每三年颁发一次,以纪念统计物理学的奠基人路德维希·玻尔兹曼DeepakDharistheoriginalstatement.获奖理由:表彰DeepakDharistheoriginalstatement.对统计物理学领域作出的开创性贡献,包括自组织临界模型的精确解、界面生长、无序
 VPR 2024 满分论文!Meta提出EfficientSAM:快速分割一切!
Mar 02, 2024 am 10:10 AM
VPR 2024 满分论文!Meta提出EfficientSAM:快速分割一切!
Mar 02, 2024 am 10:10 AM
EfficientSAM这篇工作以5/5/5满分收录于CVPR2024!作者在某社交媒体上分享了该结果,如下图所示:LeCun图灵奖得主也强烈推荐了该工作!在近期的研究中,Meta研究者提出了一种新的改进方法,即使用SAM的掩码图像预训练(SAMI)。这一方法结合了MAE预训练技术和SAM模型,旨在实现高质量的预训练ViT编码器。通过SAMI,研究者试图提高模型的性能和效率,为视觉任务提供更好的解决方案。这一方法的提出为进一步探索和发展计算机视觉和深度学习领域带来了新的思路和机遇。通过结合不同的
 谷歌AI新星转投Pika:视频生成Lumiere一作,担任创始科学家
Feb 26, 2024 am 09:37 AM
谷歌AI新星转投Pika:视频生成Lumiere一作,担任创始科学家
Feb 26, 2024 am 09:37 AM
视频生成进展如火如荼,Pika迎来一位大将——谷歌研究员OmerBar-Tal,担任Pika创始科学家。一个月前,还在谷歌以共同一作的身份发布视频生成模型Lumiere,效果十分惊艳。当时网友表示:谷歌加入视频生成战局,又有好戏可看了。StabilityAICEO、谷歌前同事等在内一些业内人士送上了祝福。Lumiere一作,刚硕士毕业OmerBar-Tal,2021年本科毕业于特拉维夫大学的数学与计算机系,随后前往魏茨曼科学研究所攻读计算机硕士,主要聚焦于图像和视频合成领域的研究。其论文成果多次
