

腾讯机器狗进化:通过深度学习掌握自主决策能力

6月14日,腾讯Robotics X机器人实验室公布了智能体研究的最新进展,通过将前沿的预训练AI模型和强化学习技术应用到机器人控制领域,让机器狗 Max 的灵活性和自主决策能力得到大幅提升。
让机器狗像人和动物一样灵活且稳定的运动,是机器人研究领域长期追求的目标,深度学习技术的不断进步,使得让机器通过“学习”来掌握相关能力,学会应对复杂多变的环境变得可行。
引入预训练和强化学习:让机器狗更加灵动
腾讯Robotics X机器人实验室通过引入预训练模型和强化学习技术,可以让机器狗分阶段进行学习,有效的将不同阶段的技能、知识积累并存储下来,让机器人在解决新的复杂任务时,不必重新学习,而是可以复用已经学会的姿态、环境感知、策略规划多个层面的知识,进行“举一反三”,灵活应对复杂环境


这一系列的学习分为三个阶段:
第一阶段通过游戏技术中常使用动作捕捉系统,研究员收集真狗的运动姿态数据,包括走、跑、跳、站立等动作,并利用这些数据,在仿真器中构建了一个模仿学习任务,再将这些数据中的信息抽象并压缩到深度神经网络模型中。这些模型不仅能够准确地涵盖收集的动物运动姿态信息,而且具有相当高的可解释性。
腾讯Robotics X机器人实验室和腾讯游戏合作,用游戏技术提升了仿真引擎的准确和高效,同时游戏制作和研发过程中积累了多元的动捕素材。这些技术和数据在基于物理仿真的智能体训练和真实世界机器人策略部署中扮演了一定的辅助角色。
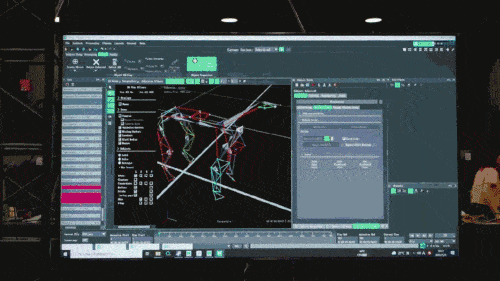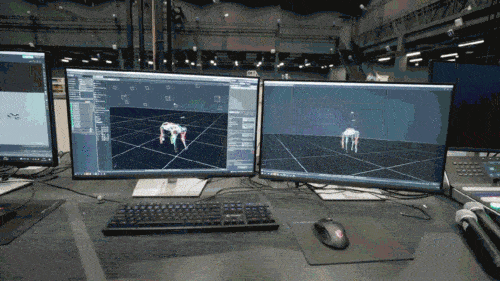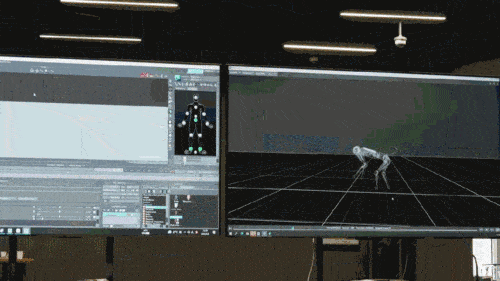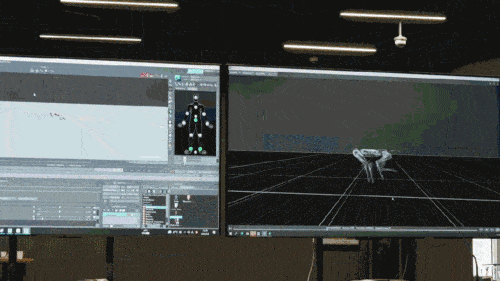
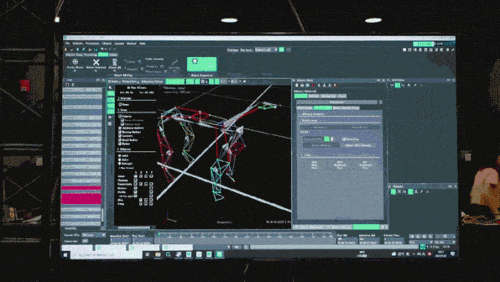

神经网络模型只接受机器狗的本体感知信息(如电机状态)作为输入,以模仿学习的方式进行训练。在下一步中,模型会融合周围环境的感知数据,例如利用其他传感器来探测脚底下的障碍物。
第二阶段,通过额外的网络参数来将第一阶段掌握的机器狗灵动姿态与外界感知联系在一起,使得机器狗能够通过已经学会的灵动姿态来应对外界环境。当机器狗适应了多种复杂的环境后,这些将灵动姿态与外界感知联系在一起的知识也会被固化下来,存在神经网络结构中。



第三阶段,利用上述两个预训练阶段获取的神经网络,机器狗才有前提和机会来聚焦解决最上层的策略学习问题,最终具备端到端解决复杂的任务的能力。在第三阶段中,额外添加的网络将会收集与复杂任务有关的数据,例如在游戏中获取对手和旗帜的信息。此外,通过综合分析所有信息,负责策略学习的神经网络会学习出针对任务的高阶策略,例如往哪个方向跑动,预判对手的行为来决定是否继续追逐等等。
上述每一阶段学习到的知识都可以扩充和调整,不需要重新学习,因此可以不断积累,持续学习。
机器狗障碍追逐比赛 :拥有自主决策和控制能力
为了测试Max所掌握的这些新技能,研究员受到障碍追逐比赛“World Chase Tag“的启发,设计了一个双狗障碍追逐的游戏。World Chase Tag是一个竞技性障碍追逐赛组织,2014年创立于英国,由民间儿童追逐游戏标准化而来。一般来说,障碍追逐比赛每轮次由两名互为对手的运动员参加,一名是追击者(称为攻方),一名是躲避者(称为守方),当一名运动员在整个追逐回合中(即20秒)成功躲避对手(即未发生触碰)时,团队将获得一分。 在预定的追逐回合数中得分最多的战队赢得比赛。
机器狗障碍追逐比赛的场地尺寸为4.5米 x 4.5米,上面分布着一些障碍物。游戏起始,两个MAX机器狗会被放置在场地中的随机位置,且随机一个机器狗被赋予追击者的角色,另一个为躲避者,同时,场地中会在随机位置摆放一个旗子。
躲避者的目标是尽可能接近旗子,但要确保不被追击者捉住。追击者的任务则是抓住躲避者。如果躲避者在被抓到之前成功触碰到旗子,则两个机器狗的角色会瞬间发生互换,同时旗子会重新出现在另一个随机的位置。当躲避者被当前的追击者抓住并且此时扮演追击者角色的机器狗获胜时,游戏即告结束。在所有游戏中,两个机器狗的平均前进速度限制为0.5m/s。
从这个游戏看来,在基于预训练好的模型下,机器狗通过深度强化学习,已经具备一定的推理和决策能力:
比如,当追击者意识到自己在躲避者碰到旗子之前已经无法追上它的时候,追击者就会放弃追击,而是在远离躲避者的位置徘徊,目的是为了等待下一个重置的旗子出现。
另外,当追击者即将抓到躲避者的最后时刻,它喜欢跳起来向着躲避者做出一个"扑"的动作,非常类似动物捕捉猎物时候的行为,或者躲避者在快要接触旗子的时候也会表现出同样的行为。这些都是机器狗为了确保自己的胜利采取的主动加速措施。
据介绍,游戏中机器狗的所有控制策略都是神经网络策略,在仿真中进行学习并通过zero-shot transfer(零调整迁移),让神经网络模拟人类的推理方式,来识别从未见过的新事物,并把这些知识部署到真实机器狗上。例如下图所示,机器狗在预训练模型中学会的躲避障碍物的知识,被用在游戏中,即使带有障碍物的场景并未在Chase Tag Game的虚拟世界进行训练(虚拟世界中仅训练了平地下的游戏场景),机器狗也能顺利完成任务。
腾讯Robotics X机器人实验室长期致力于机器人前沿技术的研究,以此前在机器人本体、运动、控制领域等领先技术和积累为基础,研究员们也在尝试将前沿的预训练模型和深度强化学习技术引入到机器人领域,提升机器人的控制能力,让其更具灵活性,这也为机器人走入现实生活,服务人类打下了坚实的基础。
以上是腾讯机器狗进化:通过深度学习掌握自主决策能力的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 大模型App腾讯元宝上线!混元再升级,打造可随身携带的全能AI助理
Jun 09, 2024 pm 10:38 PM
大模型App腾讯元宝上线!混元再升级,打造可随身携带的全能AI助理
Jun 09, 2024 pm 10:38 PM
5月30日,腾讯宣布旗下混元大模型全面升级,基于混元大模型的App“腾讯元宝”正式上线,苹果及安卓应用商店均可下载。相比此前测试阶段的混元小程序版本,面向工作效率场景,腾讯元宝提供了AI搜索、AI总结、AI写作等核心能力;面向日常生活场景,元宝的玩法也更加丰富,提供了多个特色AI应用,并新增了创建个人智能体等玩法。“腾讯做大模型不争一时之先。”腾讯云副总裁、腾讯混元大模型负责人刘煜宏表示:“过去的一年,我们持续推进腾讯混元大模型的能力爬坡,在丰富、海量的业务场景中打磨技术,同时洞察用户的真实需求
 超越ORB-SLAM3!SL-SLAM:低光、严重抖动和弱纹理场景全搞定
May 30, 2024 am 09:35 AM
超越ORB-SLAM3!SL-SLAM:低光、严重抖动和弱纹理场景全搞定
May 30, 2024 am 09:35 AM
写在前面今天我们探讨下深度学习技术如何改善在复杂环境中基于视觉的SLAM(同时定位与地图构建)性能。通过将深度特征提取和深度匹配方法相结合,这里介绍了一种多功能的混合视觉SLAM系统,旨在提高在诸如低光条件、动态光照、弱纹理区域和严重抖动等挑战性场景中的适应性。我们的系统支持多种模式,包括拓展单目、立体、单目-惯性以及立体-惯性配置。除此之外,还分析了如何将视觉SLAM与深度学习方法相结合,以启发其他研究。通过在公共数据集和自采样数据上的广泛实验,展示了SL-SLAM在定位精度和跟踪鲁棒性方面优
 一文搞懂:AI、机器学习与深度学习的联系与区别
Mar 02, 2024 am 11:19 AM
一文搞懂:AI、机器学习与深度学习的联系与区别
Mar 02, 2024 am 11:19 AM
在当今科技日新月异的浪潮中,人工智能(ArtificialIntelligence,AI)、机器学习(MachineLearning,ML)与深度学习(DeepLearning,DL)如同璀璨星辰,引领着信息技术的新浪潮。这三个词汇频繁出现在各种前沿讨论和实际应用中,但对于许多初涉此领域的探索者来说,它们的具体含义及相互之间的内在联系可能仍笼罩着一层神秘面纱。那让我们先来看看这张图。可以看出,深度学习、机器学习和人工智能之间存在着紧密的关联和递进关系。深度学习是机器学习的一个特定领域,而机器学习
 超强!深度学习Top10算法!
Mar 15, 2024 pm 03:46 PM
超强!深度学习Top10算法!
Mar 15, 2024 pm 03:46 PM
自2006年深度学习概念被提出以来,20年快过去了,深度学习作为人工智能领域的一场革命,已经催生了许多具有影响力的算法。那么,你所认为深度学习的top10算法有哪些呢?以下是我心目中深度学习的顶尖算法,它们在创新性、应用价值和影响力方面都占据重要地位。1、深度神经网络(DNN)背景:深度神经网络(DNN)也叫多层感知机,是最普遍的深度学习算法,发明之初由于算力瓶颈而饱受质疑,直到近些年算力、数据的爆发才迎来突破。DNN是一种神经网络模型,它包含多个隐藏层。在该模型中,每一层将输入传递给下一层,并
 腾讯QQ NT架构版本内存优化进展公布,聊天场景控制在300M内
Mar 05, 2024 pm 03:52 PM
腾讯QQ NT架构版本内存优化进展公布,聊天场景控制在300M内
Mar 05, 2024 pm 03:52 PM
据了解,腾讯QQ桌面客户端进行了一系列的大刀阔斧的改革。针对用户关于高内存占用、超大安装包、启动缓慢等问题,QQ技术团队在内存上进行了专项优化,取得了阶段性进展。日前,QQ技术团队在InfoQ平台发布了一篇介绍文章,分享了其在内存上进行专项优化的阶段性进展。据介绍,新版QQ在内存上的挑战主要表现在以下4个方面:产品形态:由1个复杂的大面板(100+复杂程度不等的模块)和一系列独立功能窗口构成。窗口与渲染进程一一对应,窗口进程数很大程度影响Electron的内存占用。对于那个复杂的大面板,一旦没有
 腾讯光子H工作室在杭州招人 计划做3A开放世界RPG
Feb 05, 2024 pm 01:45 PM
腾讯光子H工作室在杭州招人 计划做3A开放世界RPG
Feb 05, 2024 pm 01:45 PM
近期,腾讯互娱招聘公布了一则招聘信息,表明光子H工作室正致力于研发一款内容丰富、3A级别的开放世界RPG项目。此次热招岗位涵盖了UE5工程师、后台、关卡设计、动作场景设计、角色建模、特效及发行等多个领域,而这些岗位的目标工作地点位于网易总部所在地的杭州。
 AlphaFold 3 重磅问世,全面预测蛋白质与所有生命分子相互作用及结构,准确性远超以往水平
Jul 16, 2024 am 12:08 AM
AlphaFold 3 重磅问世,全面预测蛋白质与所有生命分子相互作用及结构,准确性远超以往水平
Jul 16, 2024 am 12:08 AM
编辑|萝卜皮自2021年发布强大的AlphaFold2以来,科学家们一直在使用蛋白质结构预测模型来绘制细胞内各种蛋白质结构的图谱、发现药物,并绘制每种已知蛋白质相互作用的「宇宙图」 。就在刚刚,GoogleDeepMind发布了AlphaFold3模型,该模型能够对包括蛋白质、核酸、小分子、离子和修饰残基在内的复合物进行联合结构预测。 AlphaFold3的准确性对比过去许多专用工具(蛋白质-配体相互作用、蛋白质-核酸相互作用、抗体-抗原预测)有显着提高。这表明,在单个统一的深度学习框架内,可以实现
 Up主已经开始鬼畜,腾讯开源「AniPortrait」让照片唱歌说话
Apr 07, 2024 am 09:01 AM
Up主已经开始鬼畜,腾讯开源「AniPortrait」让照片唱歌说话
Apr 07, 2024 am 09:01 AM
AniPortrait模型是开源的,可以自由畅玩。「小破站鬼畜区的新质生产力工具。」近日,腾讯开源发布的一个新项目在推上获得了如此评价。这个项目是AniPortrait,其可基于音频和一张参考图像生成高质量动画人像。话不说多,我们先看看可能会被律师函警告的demo:动漫图像也能轻松开口说话:该项目刚上线几天,就已经收获了广泛好评:GitHubStar数已经突破2800。下面我们来看看AniPortrait的创新之处。论文标题:AniPortrait:Audio-DrivenSynthesisof
