

Meta发布音频AI模型,仅需2秒片段模拟真人语音

近日,Meta发布了Voicebox AI模型,它在音频模拟方面有着显著优势。
据悉,Voicebox只需要一段2秒钟的音频样本,即可准确辨别出音频细节、音色,并基于文字结果转换为语音输出。

Voicebox 是一种生成式 AI 模型,可以帮助进行音频编辑、采样和造型。
这种技术在未来可以用来帮助创作者轻松编辑音轨,同时,它也能够为声带受损的人群提供协助,帮助TA们重新“发声”。使视障人士能够通过声音听到他们朋友的书面信息,同时使人们能够用自己的声音说任何外语。
同时,它还可以基于语音片段的前后内容,自动补齐中间缺失的内容。
根据Meta的介绍,Voicebox能够为AI助手,或是未来元宇宙的NPC提供自然且真实的语音效果,大大提升用户使用时的沉浸感。
Voicebox 的多功能性支持各种任务,包括:
上下文文本到语音合成:使用短至两秒的音频样本,Voicebox 可以匹配音频风格并将其用于文本到语音生成。
语音编辑和降噪:Voicebox 可以重新创建被噪音打断的部分语音或替换说错的词,而无需重新录制整个语音。例如,您可以识别被狗叫声打断的一段语音,将其裁剪,然后指示 Voicebox 重新生成该段——就像用于音频编辑的橡皮擦一样。
跨语言转换:当给定某人演讲样本和一段英语、法语、德语、西班牙语、波兰语或葡萄牙语的文本时,Voicebox 可以生成任何这些语言的文本阅读,即使样本语音和文本是不同的语言。将来,即使人们不懂这些语言,他们也可以使用此功能以一种更为自然、真实的方式进行交流。
流匹配是 Voicebox 使用的一种方法,已被证明可以提高扩散模型的性能。Voicebox 在可懂度(5.9% 对 1.9% 的单词错误率)和音频相似性(0.580 对 0.681)方面优于当前最先进的英语模型 VALL-E,同时快 20 倍。对于跨语言风格迁移,Voicebox 优于 YourTTS,将平均单词错误率从 10.9% 降低到 5.2%,并将音频相似度从 0.335 提高到 0.481。
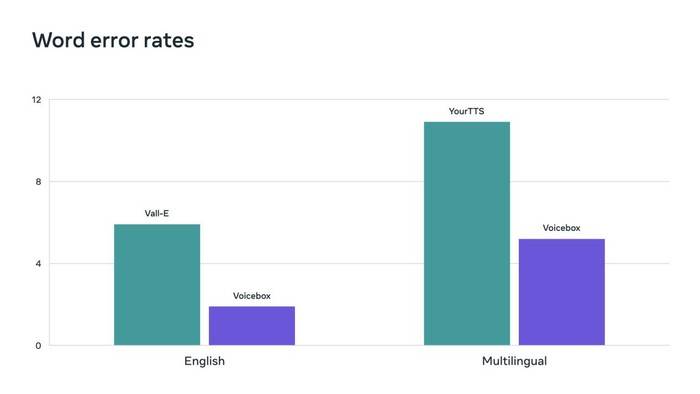
Voicebox 取得了新的最先进的结果,在单词错误率方面优于 Vall-E 和 YourTTS。
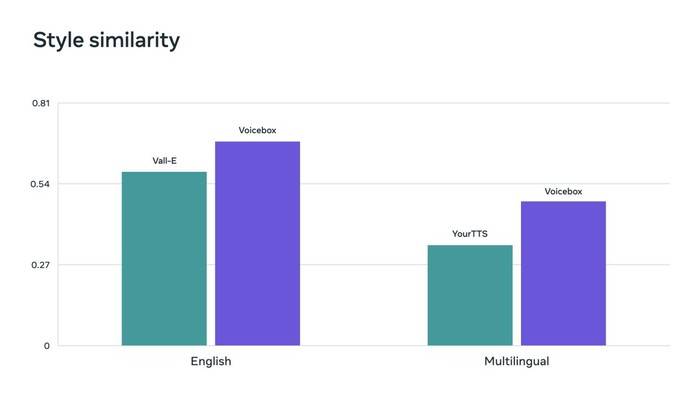
Voicebox 还分别在英语和多语言基准测试中的音频风格相似性指标上取得了最新的最新成果。
值得一提的是,Meta目前已经意识到了Voicebox被应用在造假领域时,存在的潜在危害,因此他们正在寻找一种区分真实语音和Voicebox生成语音的方法。
在找到解决方法前,Meta将不会向公众公开Voicebox AI模型,以避免不必要的危害。
编辑点评:AI如今已经被应用在各个领域,作为第一个成功执行任务泛化的多功能、高效模型,相信 Voicebox 可以开创语音生成 AI 的新时代。如果Meta无法有效应对音频造假问题,那么Voicebox技术可能会被禁用。
以上是Meta发布音频AI模型,仅需2秒片段模拟真人语音的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 新款经济实惠的 Meta Quest 3S VR 耳机出现在 FCC 上,暗示即将推出
Sep 04, 2024 am 06:51 AM
新款经济实惠的 Meta Quest 3S VR 耳机出现在 FCC 上,暗示即将推出
Sep 04, 2024 am 06:51 AM
Meta Connect 2024 活动定于 9 月 25 日至 26 日举行,在本次活动中,该公司预计将推出一款价格实惠的新型虚拟现实耳机。据传这款 VR 耳机是 Meta Quest 3S,它似乎已经出现在 FCC 清单上。这个建议
 首个超越GPT4o级开源模型!Llama 3.1泄密:4050亿参数,下载链接、模型卡都有了
Jul 23, 2024 pm 08:51 PM
首个超越GPT4o级开源模型!Llama 3.1泄密:4050亿参数,下载链接、模型卡都有了
Jul 23, 2024 pm 08:51 PM
快准备好你的GPU!Llama3.1终于现身了,不过出处却不是Meta官方。今日,Reddit上新版Llama大模型泄露的消息遭到了疯传,除了基础模型,还包括8B、70B和最大参数的405B的基准测试结果。下图为Llama3.1各版本与OpenAIGPT-4o、Llama38B/70B的比较结果。可以看到,即使是70B的版本,也在多项基准上超过了GPT-4o。图源:https://x.com/mattshumer_/status/1815444612414087294显然,3.1版本的8B和70
 六年种方式快速体验最新发布的 Llama 3!
Apr 19, 2024 pm 12:16 PM
六年种方式快速体验最新发布的 Llama 3!
Apr 19, 2024 pm 12:16 PM
昨晚Meta发布了Llama38B和70B模型,Llama3指令调整模型针对对话/聊天用例进行了微调和优化,在常见基准测试中优于许多现有的开源聊天模型。比如,Gemma7B和Mistral7B。Llama+3模型对数据和规模进行了提升,达到了新的高度。它是在Meta最近发布的两个定制的24KGPU集群上,对超过15Ttoken的数据进行训练的。这个训练数据集比Llama2大7倍,包含多4倍的代码。这使得Llama模型的能力达到了目前的最高水平,它支持8K以上的文本长度,是Llama2的两倍。下面
 Llama3突然来袭!开源社区再次沸腾:GPT4级模型自由访问时代到来
Apr 19, 2024 pm 12:43 PM
Llama3突然来袭!开源社区再次沸腾:GPT4级模型自由访问时代到来
Apr 19, 2024 pm 12:43 PM
Llama3来了!就在刚刚,Meta官网上新,官宣了Llama380亿和700亿参数版本。并且推出即为开源SOTA:Meta官方数据显示,Llama38B和70B版本在各自参数规模上超越一众对手。8B模型在MMLU、GPQA、HumanEval等多项基准上均胜过Gemma7B和Mistral7BInstruct。而70B模型则超越了闭源的当红炸子鸡Claude3Sonnet,和谷歌的GeminiPro1.5打得有来有回。Huggingface链接一出,开源社区再次沸腾。眼尖的盲生们还第一时间发现
 最强模型Llama 3.1 405B正式发布,扎克伯格:开源引领新时代
Jul 24, 2024 pm 08:23 PM
最强模型Llama 3.1 405B正式发布,扎克伯格:开源引领新时代
Jul 24, 2024 pm 08:23 PM
刚刚,大家期待已久的Llama3.1官方正式发布了!Meta官方发出了「开源引领新时代」的声音。在官方博客中,Meta表示:「直到今天,开源大语言模型在功能和性能方面大多落后于封闭模型。现在,我们正在迎来一个开源引领的新时代。我们公开发布MetaLlama3.1405B,我们认为这是世界上最大、功能最强大的开源基础模型。迄今为止,所有Llama版本的总下载量已超过3亿次,我们才刚刚开始。」Meta创始人、CEO扎克伯格也亲自写了篇长文《OpenSourceAIIsthePathForward》,
 META是什么意思
Mar 05, 2024 pm 12:18 PM
META是什么意思
Mar 05, 2024 pm 12:18 PM
META通常指代一个名为Meta宇宙(Metaverse)的虚拟世界或平台。meta元宇宙,是人类运用数字技术构建的,由现实世界映射或超越现实世界,可与现实世界交互的虚拟世界 ,具备新型社会体系的数字生活空间。
 预计2024年,Meta计划推出名为'Orion'的革命性AR眼镜原型
Jan 04, 2024 pm 09:35 PM
预计2024年,Meta计划推出名为'Orion'的革命性AR眼镜原型
Jan 04, 2024 pm 09:35 PM
12月24日消息,meta,一家在社交媒体界有着巨大影响力的科技企业,现正将其雄厚的期望寄托于增强现实(AR)眼镜,一种被认为是下一代计算平台的技术。近期,meta的技术主管安德鲁・博斯沃思(AndrewBosworth)在一次采访中透露,该公司有望在2024年推出一款代号为“Orion”的先进AR眼镜原型。长期以来,meta在AR技术上的投入丝毫不亚于其他领域,他们投入了巨额资金,达数十亿美元,旨在打造一款能与iPhone相媲美的革命性产品。尽管去年他们宣布终止Orion眼镜的大规模生产计划,
 分析师讨论传闻中的 Meta Quest 3S VR 耳机的发布定价
Aug 27, 2024 pm 09:35 PM
分析师讨论传闻中的 Meta Quest 3S VR 耳机的发布定价
Aug 27, 2024 pm 09:35 PM
自 Meta 首次发布 Quest 3(亚马逊售价 499.99 美元)以来,已经过去一年多了。此后,苹果推出了价格昂贵得多的 Vision Pro,而字节跳动现在在中国推出了 Pico 4 Ultra。然而,有
