

羊驼家族大模型集体进化!32k上下文追平GPT-4,田渊栋团队出品

开源羊驼大模型LLaMA上下文追平GPT-4,只需要一个简单改动!
Meta AI这篇刚刚提交的论文表示,LLaMA上下文窗口从2k扩展到32k后只需要小于1000步的微调。
与预训练相比,成本忽略不计。

扩展上下文窗口,就意味着AI的“工作记忆”容量增加,具体来说可以:
- 支持更多轮对话,减少遗忘现象,如更稳定的角色扮演
- 输入更多资料完成更复杂的任务,如一次处理更长文档或多篇文档
更重要的意义在于,所有基于LLaMA的羊驼大模型家族岂不是可以低成本采用此方法,集体进化?
羊驼是目前综合能力最强的开源基础模型,已经衍生出不少完全开源可商用大模型和垂直行业模型。
论文通信作者田渊栋也激动地在朋友圈分享这一新进展。
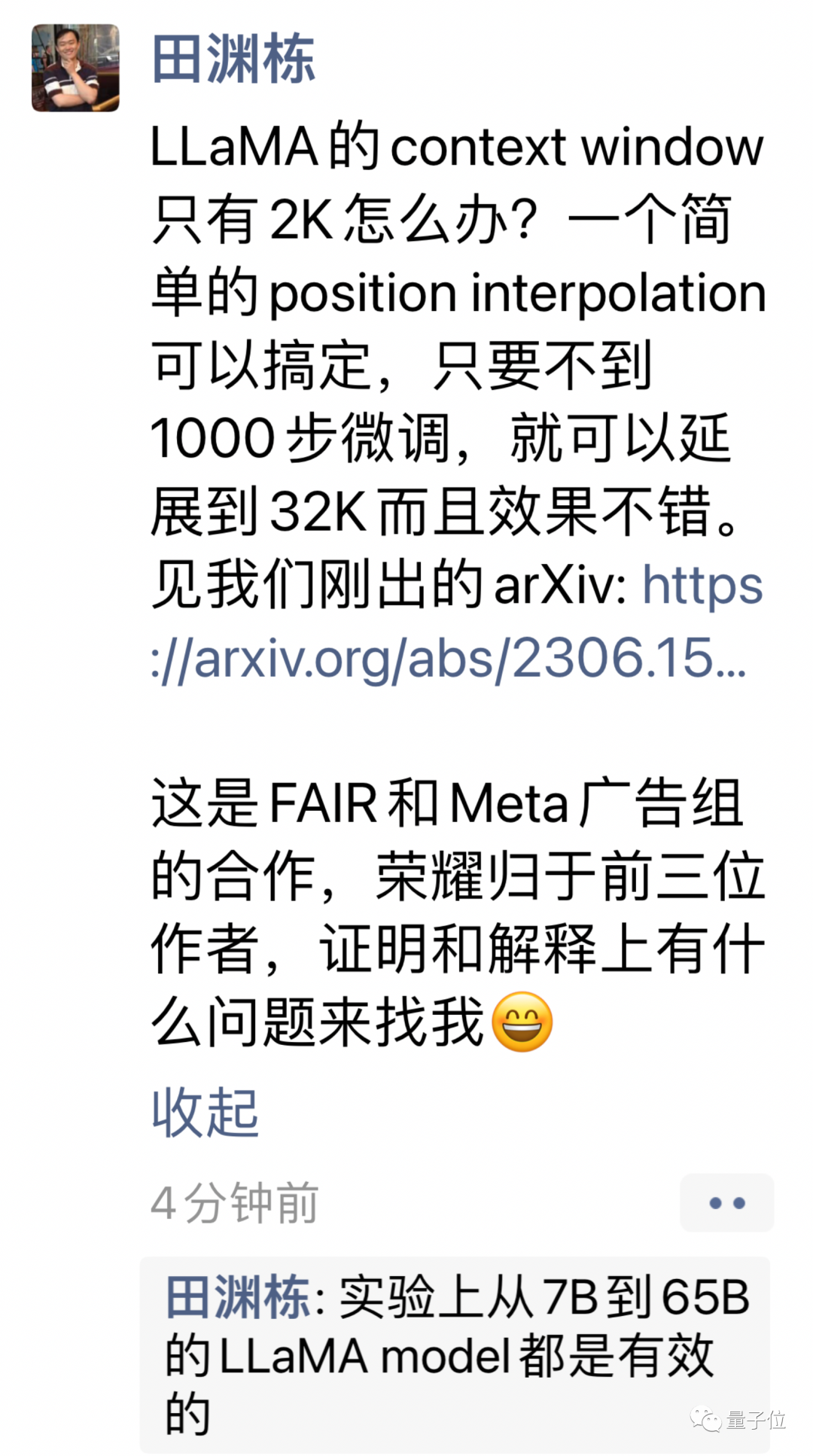
基于RoPE的大模型都能用
新方法名为位置插值(Position Interpolation),对使用RoPE(旋转位置编码)的大模型都适用。
RoPE早在2021年就由追一科技团队提出,到现在已成为大模型最常见的位置编码方法之一。

但在此架构下直接使用外推法(Extrapolation)扩展上下文窗口,会完全破坏自注意力机制。
具体来说,超出预训练上下文长度之外的部分,会使模型困惑度(perplexity)飙升至和未经训练的模型相当。
新方法改成线性地缩小位置索引,扩展前后位置索引和相对距离的范围对齐。

用图表现二者的区别更加直观。
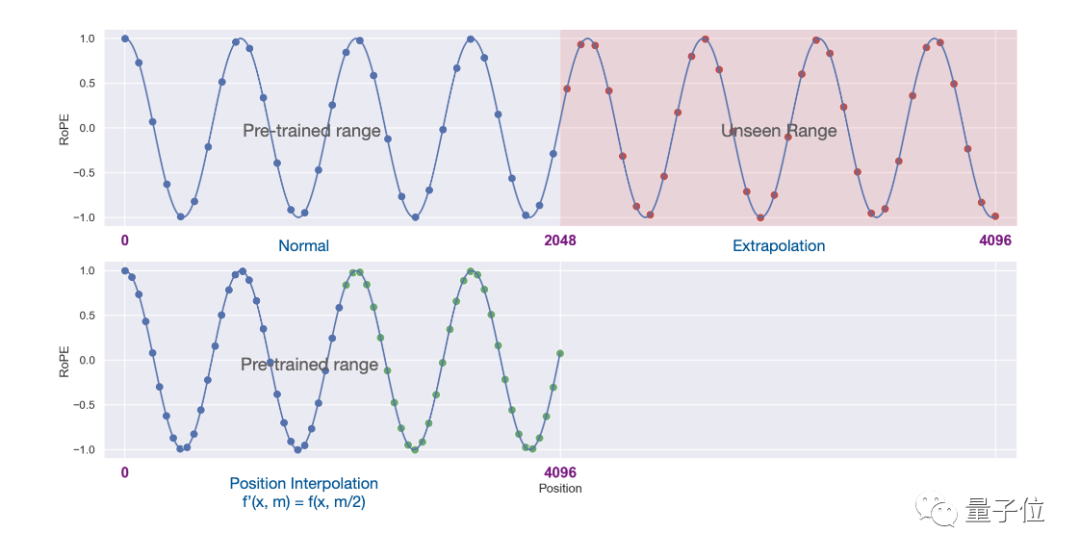
实验结果显示,新方法对从7B到65B的LLaMA大模型都有效。
在长序列语言建模(Long Sequence Language Modeling)、密钥检索(Passkey Retrieval)、长文档摘要(Long Document Summarization)中性能都没有明显下降。
除了实验之外,论文附录中也给出了对新方法的详细证明。
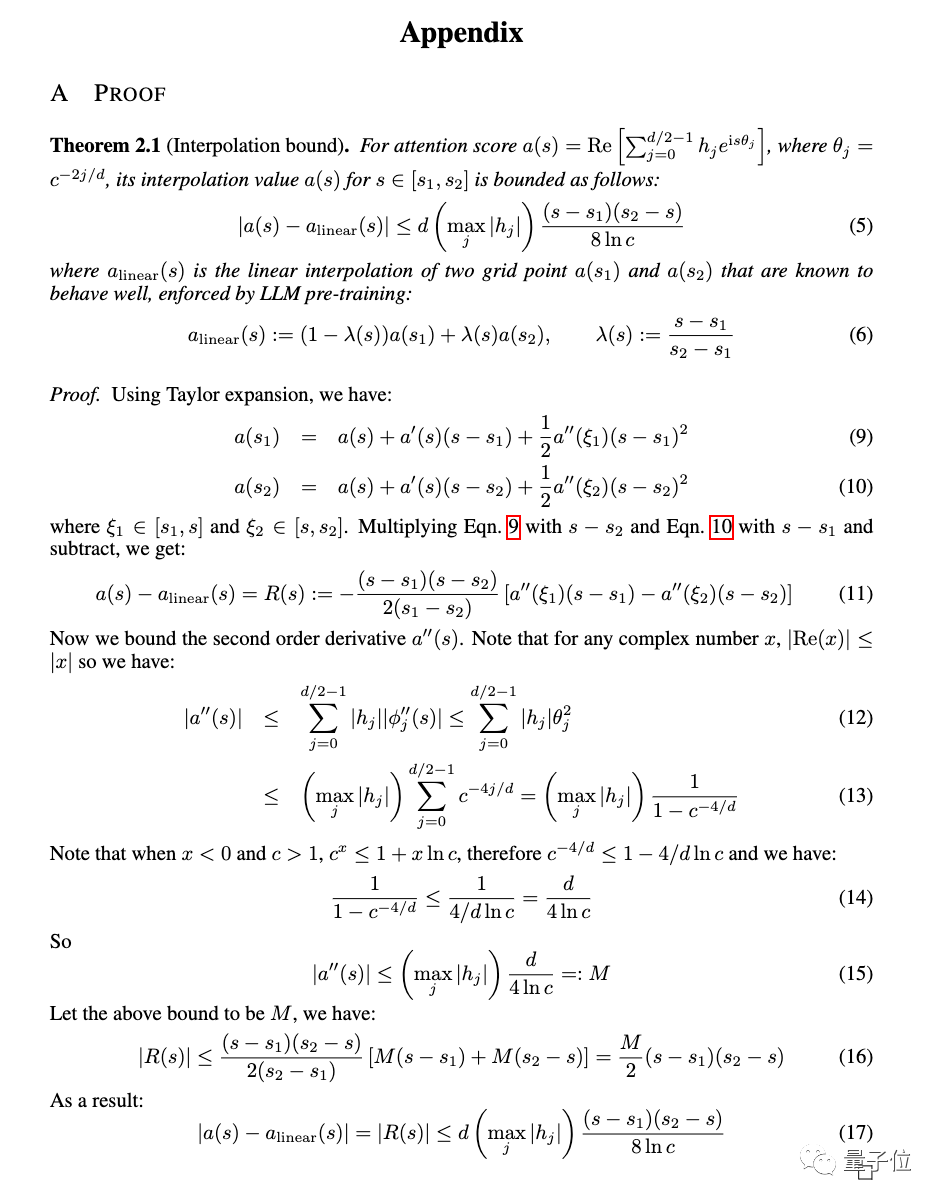
Three More Thing
上下文窗口曾经是开源大模型与商业大模型之间一个重要差距。
比如OpenAI的GPT-3.5最高支持16k,GPT-4支持32k,AnthropicAI的Claude更是高达100k。
与此同时许多开源大模型如LLaMA和Falcon还停留在2k。
现在,Meta AI的新成果直接把这一差距抹平了。
扩展上下文窗口也是近期大模型研究的焦点之一,除了位置插值方法之外,还有很多尝试引起业界关注。
1、开发者kaiokendev在一篇技术博客中探索了一种将LLaMa上下文窗口扩展到8k的方法。
2、数据安全公司Soveren机器学习负责人Galina Alperovich在一篇文章中总结了扩展上下文窗口的6个技巧。

3、来自Mila、IBM等机构的团队还在一篇论文中尝试了在Transformer中完全去掉位置编码的方法。

有需要的小伙伴可以点击下方链接查看~
Meta论文:https://www.php.cn/link/0bdf2c1f053650715e1f0c725d754b96
Extending Context is Hard…but not Impossiblehttps://www.php.cn/link/9659078925b57e621eb3f9ef19773ac3
The Secret Sauce behind 100K context window in LLMshttps://www.php.cn/link/09a630e07af043e4cae879dd60db1cac
无位置编码论文https://www.php.cn/link/fb6c84779f12283a81d739d8f088fc12
以上是羊驼家族大模型集体进化!32k上下文追平GPT-4,田渊栋团队出品的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 大模型App腾讯元宝上线!混元再升级,打造可随身携带的全能AI助理
Jun 09, 2024 pm 10:38 PM
大模型App腾讯元宝上线!混元再升级,打造可随身携带的全能AI助理
Jun 09, 2024 pm 10:38 PM
5月30日,腾讯宣布旗下混元大模型全面升级,基于混元大模型的App“腾讯元宝”正式上线,苹果及安卓应用商店均可下载。相比此前测试阶段的混元小程序版本,面向工作效率场景,腾讯元宝提供了AI搜索、AI总结、AI写作等核心能力;面向日常生活场景,元宝的玩法也更加丰富,提供了多个特色AI应用,并新增了创建个人智能体等玩法。“腾讯做大模型不争一时之先。”腾讯云副总裁、腾讯混元大模型负责人刘煜宏表示:“过去的一年,我们持续推进腾讯混元大模型的能力爬坡,在丰富、海量的业务场景中打磨技术,同时洞察用户的真实需求
 字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
火山引擎总裁谭待企业要做好大模型落地,面临模型效果、推理成本、落地难度的三大关键挑战:既要有好的基础大模型做支撑,解决复杂难题,也要有低成本的推理服务让大模型被广泛应用,还要更多工具、平台和应用帮助企业做好场景落地。——谭待火山引擎总裁01.豆包大模型首次亮相大使用量打磨好模型模型效果是AI落地最关键的挑战。谭待指出,只有大的使用量,才能打磨出好模型。目前,豆包大模型日均处理1,200亿tokens文本、生成3,000万张图片。为助力企业做好大模型场景落地,字节跳动自主研发的豆包大模型将通过火山
 揭秘NVIDIA大模型推理框架:TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
揭秘NVIDIA大模型推理框架:TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
一、TensorRT-LLM的产品定位TensorRT-LLM是NVIDIA为大型语言模型(LLM)开发的可扩展推理方案。它基于TensorRT深度学习编译框架构建、编译和执行计算图,并借鉴了FastTransformer中高效的Kernels实现。此外,它还利用NCCL实现设备间的通信。开发者可以根据技术发展和需求差异,定制算子以满足特定需求,例如基于cutlass开发定制的GEMM。TensorRT-LLM是NVIDIA官方推理方案,致力于提供高性能并不断完善其实用性。TensorRT-LL
 对标GPT-4!中国移动九天大模型通过双备案
Apr 04, 2024 am 09:31 AM
对标GPT-4!中国移动九天大模型通过双备案
Apr 04, 2024 am 09:31 AM
4月4日消息,日前,国家网信办公布已备案大模型清单,中国移动“九天自然语言交互大模型”名列其中,标志着中国移动九天AI大模型可正式对外提供生成式人工智能服务。中国移动表示,这是同时通过国家“生成式人工智能服务备案”和“境内深度合成服务算法备案”双备案的首个央企研发的大模型。据介绍,九天自然语言交互大模型具有行业能力增强、安全可信、支持全栈国产化等特点,已形成90亿、139亿、570亿、千亿等多种参数量版本,可灵活部署于云、边、端不同场
 新测试基准发布,最强开源Llama 3尴尬了
Apr 23, 2024 pm 12:13 PM
新测试基准发布,最强开源Llama 3尴尬了
Apr 23, 2024 pm 12:13 PM
如果试题太简单,学霸和学渣都能考90分,拉不开差距……随着Claude3、Llama3甚至之后GPT-5等更强模型发布,业界急需一款更难、更有区分度的基准测试。大模型竞技场背后组织LMSYS推出下一代基准测试Arena-Hard,引起广泛关注。Llama3的两个指令微调版本实力到底如何,也有了最新参考。与之前大家分数都相近的MTBench相比,Arena-Hard区分度从22.6%提升到87.4%,孰强孰弱一目了然。Arena-Hard利用竞技场实时人类数据构建,与人类偏好一致率也高达89.1%
 利用升腾AI技术,秦岭·秦川交通大模型助力西安打造智慧交通创新中心
Oct 15, 2023 am 08:17 AM
利用升腾AI技术,秦岭·秦川交通大模型助力西安打造智慧交通创新中心
Oct 15, 2023 am 08:17 AM
“高度复杂、碎片化程度高、跨领域”一直是交通行业数智化升级路上的首要痛点。近日,由中科视语、西安市雁塔区政府、西安未来人工智能计算中心联合打造的参数规模千亿级的“秦岭·秦川交通大模型”,面向智慧交通领域,为西安及其周边地区打造智慧交通创新支点。 “秦岭·秦川交通大模型”结合西安当地海量开放场景下的交通生态数据、中科视语自研的原创先进算法以及西安未来人工智能计算中心升腾AI的强大算力,为路网监测、应急指挥、养护管理、公众出行等智慧交通全场景带来数智化变革。交通管理在不同城市有不同的特点,不同道路的交
 工业知识图谱进阶实战
Jun 13, 2024 am 11:59 AM
工业知识图谱进阶实战
Jun 13, 2024 am 11:59 AM
一、背景简介首先来介绍一下云问科技的发展历程。云问科技公...2023年,正是大模型盛行的时期,很多企业认为已经大模型之后图谱的重要性大大降低了,之前研究的预置的信息化系统也都不重要了。不过随着RAG的推广、数据治理的盛行,我们发现更高效的数据治理和高质量的数据是提升私有化大模型效果的重要前提,因此越来越多的企业开始重视知识建设的相关内容。这也推动了知识的构建和加工开始向更高水平发展,其中有很多技巧和方法可以挖掘。可见一个新技术的出现,并不是将所有的旧技术打败,也有可能将新技术和旧技术相互融合后
 小米字节联手!小爱同学接入豆包大模型:手机、SU7已搭载
Jun 13, 2024 pm 05:11 PM
小米字节联手!小爱同学接入豆包大模型:手机、SU7已搭载
Jun 13, 2024 pm 05:11 PM
6月13日消息,据字节旗下“火山引擎”公众号介绍,小米旗下人工智能助手“小爱同学”与火山引擎达成合作,双方基于豆包大模型实现更智能的AI交互体验。据悉,字节跳动打造的豆包大模型,每日能够高效处理数量多达1200亿个的文本tokens、生成3000万张内容。小米借助豆包大模型提升自身模型的学习与推理能力,打造出全新的“小爱同学”,不仅更加精准地把握用户需求,还以更快的响应速度和更全面的内容服务。例如,当用户询问复杂的科学概念时,&ldq
