

一家 380 亿美元的数据巨头,要掀起企业「AI 化」革命

作者 | 宛辰、Li Yuan
编辑 | 靖宇
当地时间 6 月 28 日,美国知名数据平台 Databricks 举办了自己的年度大会——数据与人工智能峰会。会上,Databricks 公布了 LakehouseIQ、Lakehouse AI、Databricks Marketplace 、 Lakehouse Apps 等一系列重要新品。
无论是从峰会的名称,还是新产品的命名,都能看出这家知名数据平台,正在趁着大语言模型的东风,加速向 AI 转变的脚步。

Databricks 公司 CEO Ali Ghodsi 所说的数据和 AI 普惠化|Databricks
「Databricks 要实现的是『数据普惠』和 AI 普惠,前者让数据通向每一个雇员,后者让 AI 进入每一个产品。Databricks 公司 CEO Ali Ghodsi 在发言中宣布了团队的使命。
就在大会开始之前,Databricks 刚刚宣布以 13 亿美元收购 AI 领域的新生力量 MosaicML,创下了当前 AI 领域收购纪录,可见公司在 AI 转型上的力度和决心。
正在前方参会的 PingCAP 创始人兼 CEO 刘奇告诉极客公园,Databricks 平台刚刚上线 AI 的企业级应用,就已经有超过 1500 家公司在上面进行模型训练,「数字超出预期」。同时,他认为 Databricks 由于之前在数据+ AI 方面的积累,让公司能在 AI 大火之际,迅速在之前平台基础上加入新产品,就能快速给出和大模型相关的服务。
「最关键的就是速度。」刘奇说道,在大模型时代,如何用更快的速度让大模型和现有产品整合,解决用户的痛点,可能是当下所有数据公司最大的挑战,同时也是最大的机会。
Talking points
- 通过交互界面的升级,不是数据分析师的普通人,也可以直接使用自然语言查询和分析数据。
- 企业将大模型部署到云端数据库将越来越容易,直接使用成品大模型工具分析数据,也将变得更加简单。
- 随着AI的进展,数据的价值还将越来越高,数据潜力将被进一步释放。
数据库迎来自然语言交互
Databricks 在会议上发布了一款全新的LakehouseIQ工具,被誉为"神器"。LakehouseIQ 承载着 Databricks 近期最大的发力方向之一——数据分析普惠化,即不掌握 Python 和 SQL 的普通人也能轻轻松松接入公司数据,用自然语言就能进行数据分析。
为达到这个目的,LakehouseIQ 被设计为一个功能合集,既可以被普通终端用户使用,也可以被开发者使用,针对不同的用户设计了不同的功能。
LakehouseIQ 产品图|Databricks
对于开发者方面,发布了 LakehouseIQ in Notebooks,这项功能中,LakehouseIQ 可以利用大语言模型帮助开发人员完成、生成和解释代码,以及进行代码修复、调试和报告生成。
而对于普通的非程序员群体,Databricks 则提供了可以直接用自然语言交互的界面,背后由大语言模型驱动,可以直接用自然语言来搜索和查询数据。同时,该功能与 Unity Catalog 集成,让公司可以对数据的搜索和查询进行访问权限控制,只返回提问者被授权查看的数据。
自大模型推出以来,用自然语言对数据进行查询和分析,其实一直是一个数据分析方向的热点,许多公司在此方向都有所布局。包括 Databricks 的老对手 Snowflake,刚刚宣布的 Document AI 功能也是主打这个方向。
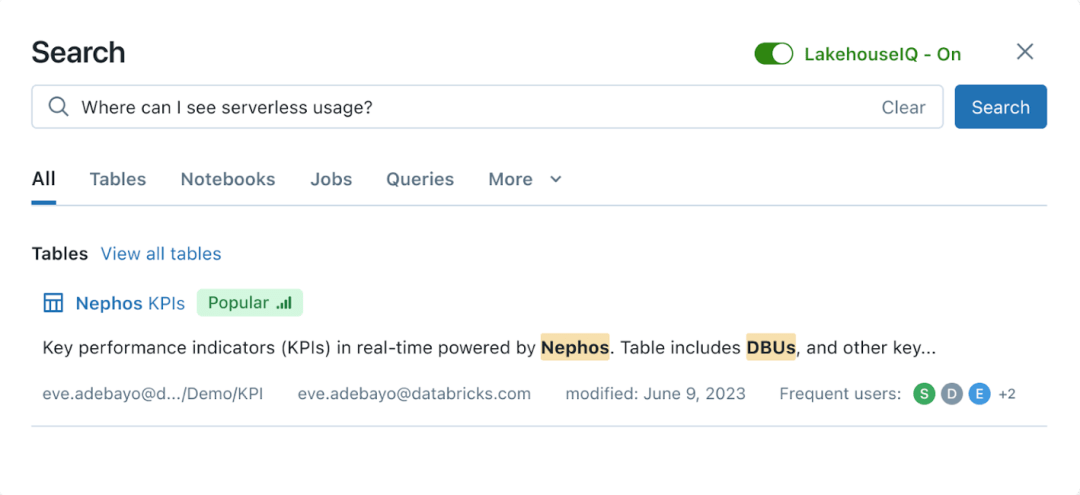
LakehouseIQ 自然语言查询界面|Databricks
然而,Databricks声称LakehouseIQ在功能上表现更出色。它指出,通用大语言模型在理解特定客户数据、内部术语和使用模式上存在限制。而 Databricks 的技术,能够利用客户自己的模式(schema)、文档、查询、受欢迎程度、线程、笔记本和商业智能仪表盘来获取智能,回答更多查询。
Databricks 的功能与 Snowflake 的功能还有一个差别,Snowflake 平台的 Document AI 功能,仅限于对文档中的非结构化数据进行查询,而 LakehouseIQ 适用于结构化的 Lakehouse 数据和代码。
02
从机器学习到 AI
Databricks 与 Snowflake 在发布会上的相似之处还不局限于此。
此次发布会中,Databricks 发布了 Databricks Marketplace 和 Lakehouse AI,这与 Snowflake 这两天大会的重点也完全吻合,二者都主打将大语言模型部署到数据库环境中。
在 Databricks 的设想中,Databricks 未来既可以协助客户部署大模型,也提供成品的大模型工具。
Databricks 过去就有 Databricks Machine Learning 的品牌,在此次发布会上,Databricks 对其进行品牌全面的重新定位,升级为 Lakehouse AI,主打协助客户部署大模型。
Databricks Marketplace is now available on Databricks.。在 Databricks Marketplace 中,用户可以接入经过筛选的开源大语言模型集合,包括 MPT-7B、Falcon-7B 和 Stable Diffusion,还可以发现和获取数据集、数据资产。Lakehouse AI也提供了一些大语言模型操作(LLMOps)的功能。
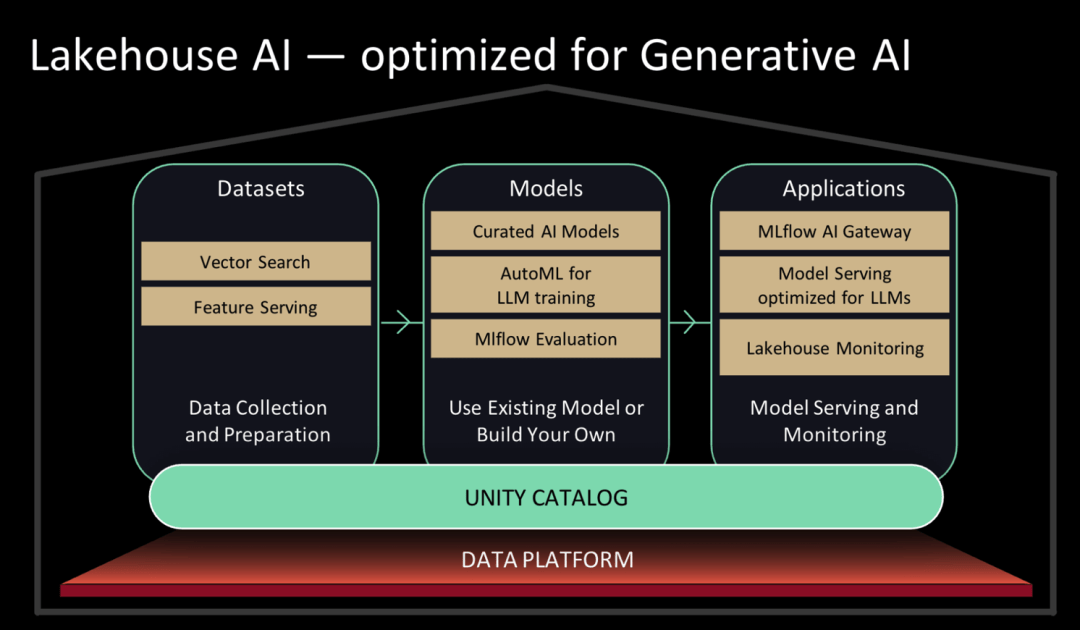
Lakehouse AI架构图|Databricks
Snowflake 也在对此进行积极部署,其相似功能由 Nvidia NeMo、Nvidia AI Enterprise、Dataiku 和 John Snow Labs 提供(与英伟达的合作正是 Snowflake 大会的重点之一,见极客公园的报道)。
在协助客户部署大模型方向,Snowflake 与 Databricks 显现出了分歧。Snowflake 选择积极地与合作伙伴进行合作,而 Databricks 则试图将该功能作为其核心平台的本地特性添加进去。
而在提供成品工具方面,Databricks 宣布 Databricks Marketplace 未来还将可以提供 Lakehouse Apps。Lakehouse Apps 将直接在客户的 Databricks 实例上运行,它们可以与客户的数据集成,使用和扩展 Databricks 服务,并使用户能够通过单点登录体验进行互动。数据永远不需要离开客户的实例,没有数据移动和安全/访问问题。
这点与 Snowflake 公司的产品在命名和功能上完全一致。Snowflake 公司与之相似的 Snowflake Marketplace 和 Snowflake Native App 已经上线,是其发布会的重点之一。彭博社就在 Snowflake 的大会上宣布了一个由彭博社提供的 Data License Plus (DL+) APP,允许客户在云端用几分钟时间就能配置一个随时可用的环境,内部设有完全建模的彭博订阅数据和来自多供应商的 ESG 内容。
03
数据平台迎来新变革
开幕式主旨演讲上,Databricks 公布了一个数字:过去 30 天,已经在 Databricks 平台上训练 Transformer 模型的客户超过 1500 家。
在谈及这个令人印象深刻的数字时,PingCAP 刘奇认为,这说明企业应用 AI 的速度比预期的要快得多,「应用模型不一定要去训练模型,所以如果训练的都有 1500 家,那应用的肯定要比这个(数字)大的多得多。」
另一个观点是,这表明Databricks在AI领域的战略布局相当全面。它现在已不只是一个数据仓库或数据湖了。现在它还提供:AI 的 training(训练)、AI 的 serving(服务),模型的管理等一整套。」

Ali Ghodsi 以计算和互联网的革命,类比大模型之于机器学习的变革|Databricks
换句话说,底层模型可以在 Databricks 的平台上进行训练,只需调整参数即可实现训练最底层的模型。在这个模型之上所需要的 AI 服务,Databricks 也布局了相应的基础设施——今天发布了 vector search(向量搜索)和 feature store(特征库)。
Databricks 全面向大模型升级。
过去,Databricks 在 AI 方面有很多积累,比如在建索引、查数据、预测工作负载等方面,用小模型来提高效率、降低时延。但是,以如此快的速度补上大模型的能力,还是让不少人意外。
在今天峰会全面展示的 AI 布局之前,Databricks 收购了 Okera(AI 数据治理),推出了自家的开源大模型 Dolly 2.0,又以 13 亿美元并购了 MosaicML,一连串的动作一气呵成。
对此,硅谷徐老师 Howie 认为,Databricks 和 Snowflake 这两个大会都可以比较明确地看出:两家公司的创始人认为,基于数据库、数据湖他们所做的行动、接下来会面临根本性的改变。按照一年前他们在做的思路,在未来几年行不通。
相应地,快速补齐大模型的能力,也意味着可以获得由于大模型带来的增量市场。
刘奇认为,大模型的出现引发了许多新需求,这些需求在没有大模型之前是不存在的。没有数据支持,模型将无法发挥作用,尤其在差异化方面无法展现。如果大家都是一个大模型,那你跟别人可能也没有差别。」
但比起大模型,峰会现场的观众似乎更关注小模型,因为小模型的几个优势:速度、成本、安全性。刘奇表示,基于自己独有的数据,做出差异化的模型,模型要足够小才能满足这三条:足够便宜、足够快、足够安全。
值得注意的是,Databricks 和 Snowflake 在日前都公布了它的营收数据,平台年营收增长在 60% 以上。在整个市场软件支出放缓的背景下,数据的关注程度不断增加,这种增长速度得以反映出来。随着大型模型的出现,数据的价值在这次 Databricks 峰会上强调了数据加 AI 主题。
随着大规模模型的引入,数据自动生成变得有可能,预计数据量将以指数级增加。怎么轻松地访问数据、怎么支持不同的数据格式、挖掘数据背后的价值,会成为越来越频繁的需求。
另一方面,今天很多企业还在还在探索观望将大模型接入企业软件,但考虑到安全、隐私、成本,敢直接用的,还很少。一旦通过将大模型直接部署到企业数据上,无需移动数据,部署大模型的门槛将被进一步降低,数据被消费的数量和速度都将被进一步释放。
以上是一家 380 亿美元的数据巨头,要掀起企业「AI 化」革命的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题
 7649
7649
 15
1392
52
91
11
73
19
36
110
15
1392
52
91
11
73
19
36
110

 最佳AI艺术生成器(免费付款)创意项目
Apr 02, 2025 pm 06:10 PM
最佳AI艺术生成器(免费付款)创意项目
Apr 02, 2025 pm 06:10 PM
本文回顾了AI最高的艺术生成器,讨论了他们的功能,对创意项目的适用性和价值。它重点介绍了Midjourney是专业人士的最佳价值,并建议使用Dall-E 2进行高质量的可定制艺术。
 Chatgpt 4 o可用吗?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4 o可用吗?
Mar 28, 2025 pm 05:29 PM
Chatgpt 4当前可用并广泛使用,与诸如ChatGpt 3.5(例如ChatGpt 3.5)相比,在理解上下文和产生连贯的响应方面取得了重大改进。未来的发展可能包括更多个性化的间
 开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
开始使用Meta Llama 3.2 -Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta的Llama 3.2:多模式和移动AI的飞跃 Meta最近公布了Llama 3.2,这是AI的重大进步,具有强大的视觉功能和针对移动设备优化的轻量级文本模型。 以成功为基础
 最佳AI聊天机器人比较(Chatgpt,Gemini,Claude&更多)
Apr 02, 2025 pm 06:09 PM
最佳AI聊天机器人比较(Chatgpt,Gemini,Claude&更多)
Apr 02, 2025 pm 06:09 PM
本文比较了诸如Chatgpt,Gemini和Claude之类的顶级AI聊天机器人,重点介绍了其独特功能,自定义选项以及自然语言处理和可靠性的性能。
 顶级AI写作助理来增强您的内容创建
Apr 02, 2025 pm 06:11 PM
顶级AI写作助理来增强您的内容创建
Apr 02, 2025 pm 06:11 PM
文章讨论了Grammarly,Jasper,Copy.ai,Writesonic和Rytr等AI最高的写作助手,重点介绍了其独特的内容创建功能。它认为Jasper在SEO优化方面表现出色,而AI工具有助于保持音调的组成
 如何访问猎鹰3? - 分析Vidhya
Mar 31, 2025 pm 04:41 PM
如何访问猎鹰3? - 分析Vidhya
Mar 31, 2025 pm 04:41 PM
猎鹰3:革命性的开源大语模型 Falcon 3是著名的猎鹰系列LLMS系列中的最新迭代,代表了AI技术的重大进步。由技术创新研究所(TII)开发
 选择最佳的AI语音生成器:评论的顶级选项
Apr 02, 2025 pm 06:12 PM
选择最佳的AI语音生成器:评论的顶级选项
Apr 02, 2025 pm 06:12 PM
本文评论了Google Cloud,Amazon Polly,Microsoft Azure,IBM Watson和Discript等高级AI语音生成器,重点介绍其功能,语音质量和满足不同需求的适用性。
 构建AI代理的前7个代理抹布系统
Mar 31, 2025 pm 04:25 PM
构建AI代理的前7个代理抹布系统
Mar 31, 2025 pm 04:25 PM
2024年见证了从简单地使用LLM进行内容生成的转变,转变为了解其内部工作。 这种探索导致了AI代理的发现 - 自主系统处理任务和最少人工干预的决策。 Buildin
