

支持跨语言、人声狗吠互换,仅利用最近邻的简单语音转换模型有多神奇

AI 参与的语音世界真神奇,既可以将一个人的语音换成任何其他人的语音,也可以与动物之间的语音互换。
我们知道,语音转换的目标是将源语音转换为目标语音,并保持内容不变。最近的任意到任意(any-to-any)语音转换方法提高了自然度和说话者相似度,但复杂性却大大增加了。这意味着训练和推理的成本变得更高,使得改进效果难以评估和建立。
问题来了,高质量的语音转换需要复杂性吗?在近日南非斯坦陵布什大学的一篇论文中,几位研究者探究了这个问题。

- 论文地址:https://arxiv.org/pdf/2305.18975.pdf
- GitHub 地址:https://bshall.github.io/knn-vc/
研究亮点在于:他们引入了 K 最近邻语音转换(kNN-VC),一种简单而强大的任意到任意语音转换方法。在过程中不训练显式转换模型,而是简单地使用了 K 最近邻回归。
具体而言,研究者首先使用自监督语音表示模型来提取源话语和参照话语的特征序列,然后通过将源表示的每个帧替换为参照中的最近邻来转换成目标说话者,最后使用神经声码器对转换后的特征进行合成以获得转换后的语音。
从结果来看,尽管 KNN-VC 很简单,但与几个基线语音转换系统相比,它在主观和客观评估中都能媲美甚至提高了清晰度和说话者相似度。
我们来欣赏一下 KNN-VC 语音转换的效果。先来看人声转换,将 KNN-VC 应用于 LibriSpeech 数据集中未见过的源说话者和目标说话者。
源语音00:11
合成语音100:11
合成语音200:11
KNN-VC 还支持了跨语言语音转换,比如西班牙语到德语、德语到日语、汉语到西班牙语。
源汉语00:08
目标西班牙语00:05
合成语音300:08
更令人称奇的是,KNN-VC 还能将人声与狗吠声互换。
源狗吠00:09
源人声00:05
合成语音400:08
合成语音500:05
我们接下来看 KNN-VC 如何运行以及与其他 jixian 方法的比较结果。
方法概览及实验结果
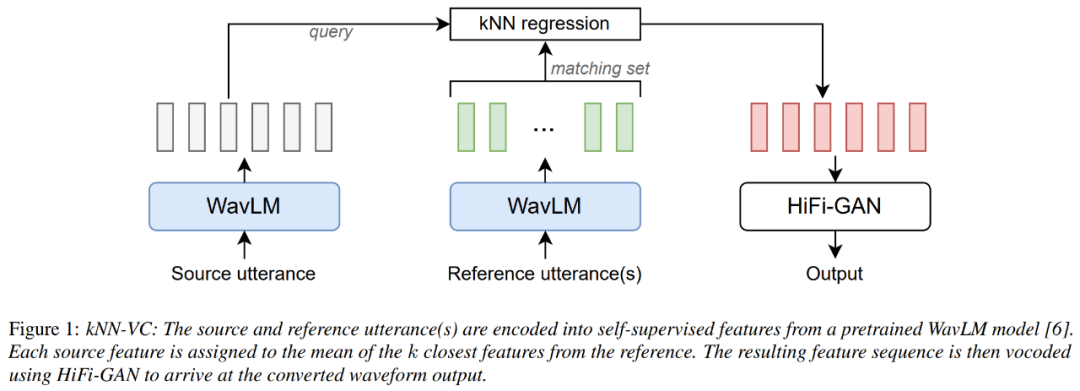
kNN-VC 的架构图如下所示,遵循了编码器 - 转换器 - 声码器结构。首先编码器提取源语音和参照语音的自监督表示,然后转换器将每个源帧映射到参照中它们的最近邻,最后声码器根据转换后的特征生成音频波形。
其中编码器采用 WavLM,转化器采用 K 最近邻回归、声码器采用 HiFiGAN。唯一需要训练的组件是声码器。
对于 WavLM 编码器,研究者只使用预训练的 WavLM-Large 模型,并在文中不对它做任何训练。对于 kNN 转换模型,kNN 是非参数,不需要任何训练。对于 HiFiGAN 声码器,采用原始 HiFiGAN 作者的 repo 对 WavLM 特征进行声码处理,成为唯一需要训练的部分。
 图片
图片
在实验中,研究者首先将 KNN-VC 与其他基线方法进行比较,使用了最大可用目标数据(每个说话者大约 8 分钟的音频)来测试语音转换系统。
对于 KNN-VC,研究者使用所有目标数据作为匹配集。对于基线方法,他们对每个目标话语的说话者嵌入求平均。
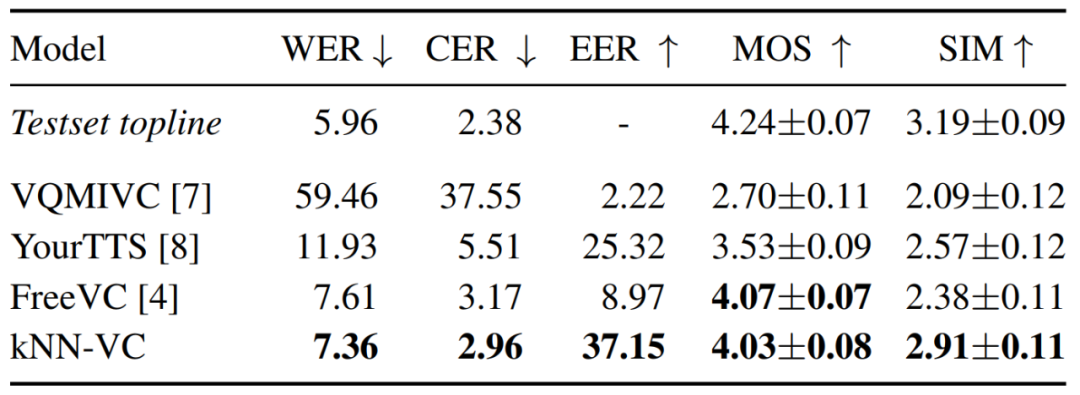
下表 1 报告了每个模型的清晰度、自然度和说话者相似度的结果。可以看到,kNN-VC 实现了与最佳基线 FreeVC 相似的自然度和清晰度,但说话者相似度却显著提高了。这也印证了本文的论断:高质量的语音转换不需要增加复杂性。
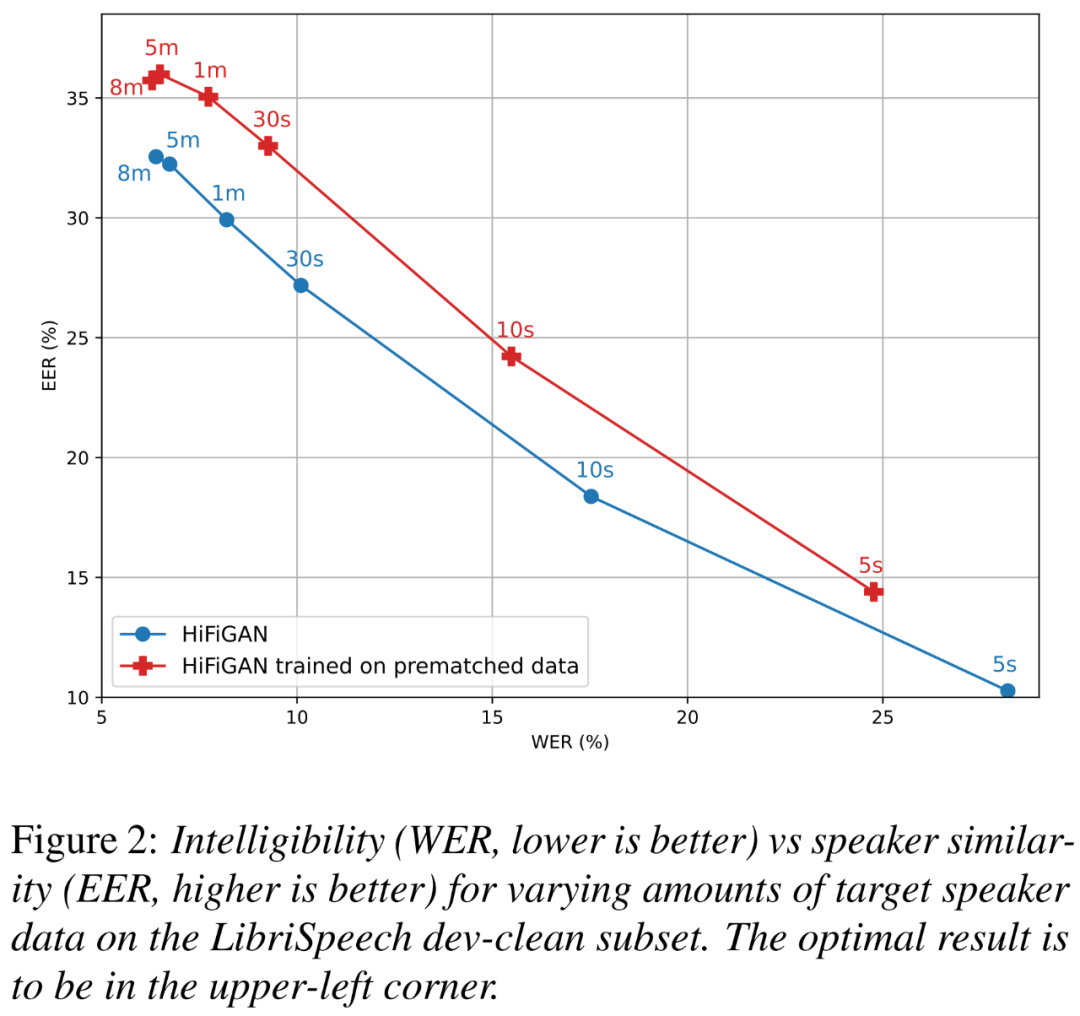
此外,研究者想要了解有多少改进得益于在预匹配数据上训练的 HiFi-GAN,以及目标说话者数据大小对清晰度和说话者相似度的影响有多大。
下图 2 展示了两种 HiFi-GAN 变体在不同目标说话者大小时的 WER(越小越好)和 EER(越高越好)关系图。
 图片
图片
网友热评
对于这个「仅利用最近邻」的语音转换新方法 kNN-VC,有人认为,文中使用了预训练语音模型,因此用「仅」不太准确。但不可否认,kNN-VC 仍然要比其他模型简单。
结果也证明了,与非常复杂的任意到任意语音转换方法相比,kNN-VC 即便不是最好,也同样有效。
 图片
图片
还有人表示,人声与狗吠互换的例子非常有趣。
 图片
图片
以上是支持跨语言、人声狗吠互换,仅利用最近邻的简单语音转换模型有多神奇的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 phpmyadmin建立数据表
Apr 10, 2025 pm 11:00 PM
phpmyadmin建立数据表
Apr 10, 2025 pm 11:00 PM
要使用 phpMyAdmin 创建数据表,以下步骤必不可少:连接到数据库并单击“新建”标签。为表命名并选择存储引擎(推荐 InnoDB)。通过单击“添加列”按钮添加列详细信息,包括列名、数据类型、是否允许空值以及其他属性。选择一个或多个列作为主键。单击“保存”按钮创建表和列。
 怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
怎么创建oracle数据库 oracle怎么创建数据库
Apr 11, 2025 pm 02:33 PM
创建Oracle数据库并非易事,需理解底层机制。1. 需了解数据库和Oracle DBMS的概念;2. 掌握SID、CDB(容器数据库)、PDB(可插拔数据库)等核心概念;3. 使用SQL*Plus创建CDB,再创建PDB,需指定大小、数据文件数、路径等参数;4. 高级应用需调整字符集、内存等参数,并进行性能调优;5. 需注意磁盘空间、权限和参数设置,并持续监控和优化数据库性能。 熟练掌握需不断实践,才能真正理解Oracle数据库的创建和管理。
 oracle数据库怎么创建 oracle数据库怎么建库
Apr 11, 2025 pm 02:36 PM
oracle数据库怎么创建 oracle数据库怎么建库
Apr 11, 2025 pm 02:36 PM
创建Oracle数据库,常用方法是使用dbca图形化工具,步骤如下:1. 使用dbca工具,设置dbName指定数据库名;2. 设置sysPassword和systemPassword为强密码;3. 设置characterSet和nationalCharacterSet为AL32UTF8;4. 设置memorySize和tablespaceSize根据实际需求调整;5. 指定logFile路径。 高级方法为使用SQL命令手动创建,但更复杂易错。 需要注意密码强度、字符集选择、表空间大小及内存
 oracle数据库的语句怎么写
Apr 11, 2025 pm 02:42 PM
oracle数据库的语句怎么写
Apr 11, 2025 pm 02:42 PM
Oracle SQL语句的核心是SELECT、INSERT、UPDATE和DELETE,以及各种子句的灵活运用。理解语句背后的执行机制至关重要,如索引优化。高级用法包括子查询、连接查询、分析函数和PL/SQL。常见错误包括语法错误、性能问题和数据一致性问题。性能优化最佳实践涉及使用适当的索引、避免使用SELECT *、优化WHERE子句和使用绑定变量。掌握Oracle SQL需要实践,包括代码编写、调试、思考和理解底层机制。
 MySQL数据表字段操作指南之添加、修改与删除方法
Apr 11, 2025 pm 05:42 PM
MySQL数据表字段操作指南之添加、修改与删除方法
Apr 11, 2025 pm 05:42 PM
MySQL 中字段操作指南:添加、修改和删除字段。添加字段:ALTER TABLE table_name ADD column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY] [AUTO_INCREMENT]修改字段:ALTER TABLE table_name MODIFY column_name data_type [NOT NULL] [DEFAULT default_value] [PRIMARY KEY]
 MySQL数据库中的嵌套查询实例详解
Apr 11, 2025 pm 05:48 PM
MySQL数据库中的嵌套查询实例详解
Apr 11, 2025 pm 05:48 PM
嵌套查询是一种在一个查询中包含另一个查询的方式,主要用于检索满足复杂条件、关联多张表以及计算汇总值或统计信息的数据。实例示例包括:查找高于平均工资的雇员、查找特定类别的订单以及计算每种产品的总订购量。编写嵌套查询时,需要遵循:编写子查询、将其结果写入外层查询(使用别名或 AS 子句引用)、优化查询性能(使用索引)。
 oracle数据库表的完整性约束有哪些
Apr 11, 2025 pm 03:42 PM
oracle数据库表的完整性约束有哪些
Apr 11, 2025 pm 03:42 PM
Oracle 数据库的完整性约束可确保数据准确性,包括:NOT NULL:禁止空值;UNIQUE:保证唯一性,允许单个 NULL 值;PRIMARY KEY:主键约束,加强 UNIQUE,禁止 NULL 值;FOREIGN KEY:维护表间关系,外键引用主表主键;CHECK:根据条件限制列值。
 oracle是干嘛的
Apr 11, 2025 pm 06:06 PM
oracle是干嘛的
Apr 11, 2025 pm 06:06 PM
Oracle 是全球最大的数据库管理系统(DBMS)软件公司,其主要产品包括以下功能:关系数据库管理系统(Oracle 数据库)开发工具(Oracle APEX、Oracle Visual Builder)中间件(Oracle WebLogic Server、Oracle SOA Suite)云服务(Oracle Cloud Infrastructure)分析和商业智能(Oracle Analytics Cloud、Oracle Essbase)区块链(Oracle Blockchain Pla
