

大模型的“黄金搭档”来了!腾讯云正式发布AI原生向量数据库,提供10亿级向量检索能力

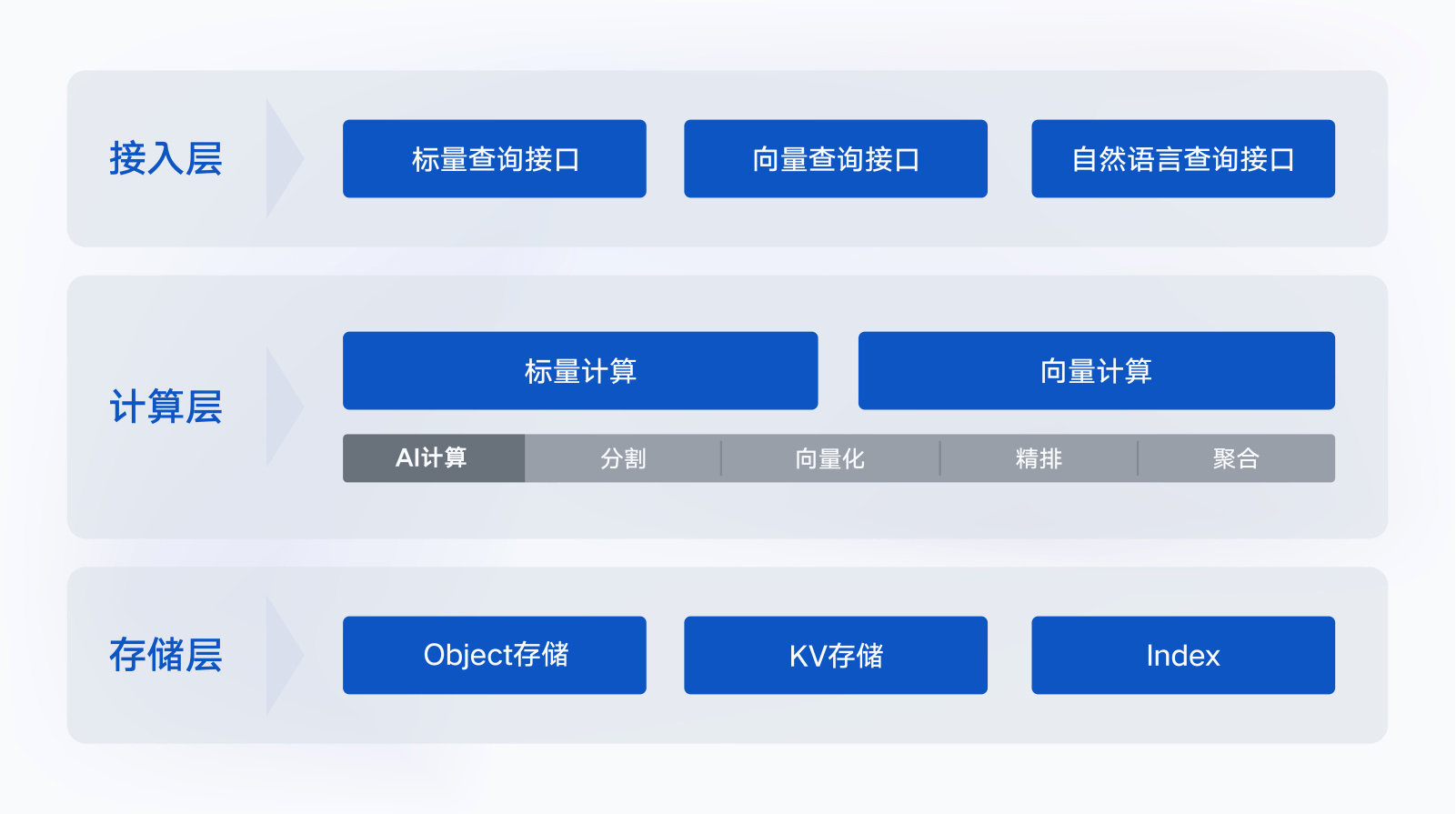
7月4日,腾讯云正式发布AI 原生(AI Native)向量数据库Tencent Cloud VectorDB。该数据库能够被广泛应用于大模型的训练、推理和知识库补充等场景,是国内首个从接入层、计算层、到存储层提供全生命周期AI化的向量数据库。
在业界被称为大型模型的"海马体",向量数据库被专门设计用于存储和查询向量数据。据介绍,腾讯云向量数据库最高支持10亿级向量检索规模,延迟控制在毫秒级,相比传统单机插件式数据库检索规模提升10倍,同时具备百万级每秒查询(QPS)的峰值能力。
腾讯云定义AI Native向量数据库
大模型时代的到来,拥抱大模型成为企业的刚需。
通过将数据向量化存储,向量数据库可显著提高效率并降低成本。它能解决大模型预训练成本高、没有“长期记忆”、知识更新不足、提示词工程复杂等问题,突破大模型在时间和空间上的限制,加速大模型落地行业场景。
统计显示,将腾讯云向量数据库用于大模型预训练数据的分类、去重和清洗相比传统方式可以实现10倍效率的提升,如果将向量数据库作为外部知识库用于模型推理,则可以将成本降低2-4个数量级。
值得关注的是,腾讯云重新定义了AI Native的开发范式,提供了接入层、计算层、存储层的全面AI化解决方案,使用户在使用向量数据库的全生命周期,都能应用到AI能力。
具体而言,在接入层,腾讯云向量数据库支持自然语言文本的输入,同时采用“标量+向量”的查询方式,支持全内存索引,最高支持每秒百万的查询量(QPS);在计算层,AI Native开发范式能实现全量数据AI计算,一站式解决企业在搭建私域知识库时的文本切分(segment)、向量化(embedding)等难题;在存储层,腾讯云向量数据库支持数据智能存储分布,助力企业存储成本降低50%。
企业原先接入一个大模型需要花1个月左右时间,使用腾讯云向量数据库后,3天时间即可完成,极大降低了企业的接入成本。
据了解,腾讯云向量数据库的向量化能力(embedding)曾多次获得权威机构认可,2021年曾登顶MS MARCO榜单第一、相关成果已发表于NLP顶会ACL。
腾讯云数据库副总经理罗云表示,AI Native(AI原生)时代已经到来,“向量数据库+大模型+数据”,三者将产生“飞轮效应”,共同助力企业步入AI Native(AI原生)时代。
腾讯云向量数据库助力数据接入效率提升10倍
腾讯云向量数据库基于腾讯集团每日处理千亿次检索的向量引擎(OLAMA),经过腾讯内部海量场景的实践,数据接入AI的效率也比传统方案提升10倍,运行稳定性高达99.99%,目前已经应用在了腾讯视频、QQ浏览器、QQ音乐等30多款国民级产品中。
腾讯云向量数据库能有效助力产品提升运营效率。数据显示,使用腾讯云向量数据库后,QQ音乐人均听歌时长提升3.2%、腾讯视频有效曝光人均时长提升1.74%、QQ浏览器成本降低37.9%。
以腾讯视频的应用为例,视频库中的图片、音频、标题文本等内容使用腾讯云向量数据库,月均完成的检索和计算量高达200亿次,有效满足了版权保护、原创识别、相似性检索等场景需求。
大模型加速向量数据库进入飞速发展期,据东北证券预测,到2030年,全球向量数据库市场规模有望达到500亿美元,国内向量数据库市场规模有望超过600亿人民币。
向量数据库可以帮助企业更高效、便捷地使用大模型,将数据的价值释放到最大,随着大模型的不断发展和普及,AI Native向量数据库将成为企业数据处理的标配。
以上是大模型的“黄金搭档”来了!腾讯云正式发布AI原生向量数据库,提供10亿级向量检索能力的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 大模型App腾讯元宝上线!混元再升级,打造可随身携带的全能AI助理
Jun 09, 2024 pm 10:38 PM
大模型App腾讯元宝上线!混元再升级,打造可随身携带的全能AI助理
Jun 09, 2024 pm 10:38 PM
5月30日,腾讯宣布旗下混元大模型全面升级,基于混元大模型的App“腾讯元宝”正式上线,苹果及安卓应用商店均可下载。相比此前测试阶段的混元小程序版本,面向工作效率场景,腾讯元宝提供了AI搜索、AI总结、AI写作等核心能力;面向日常生活场景,元宝的玩法也更加丰富,提供了多个特色AI应用,并新增了创建个人智能体等玩法。“腾讯做大模型不争一时之先。”腾讯云副总裁、腾讯混元大模型负责人刘煜宏表示:“过去的一年,我们持续推进腾讯混元大模型的能力爬坡,在丰富、海量的业务场景中打磨技术,同时洞察用户的真实需求
 字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
字节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
Jun 05, 2024 pm 07:59 PM
火山引擎总裁谭待企业要做好大模型落地,面临模型效果、推理成本、落地难度的三大关键挑战:既要有好的基础大模型做支撑,解决复杂难题,也要有低成本的推理服务让大模型被广泛应用,还要更多工具、平台和应用帮助企业做好场景落地。——谭待火山引擎总裁01.豆包大模型首次亮相大使用量打磨好模型模型效果是AI落地最关键的挑战。谭待指出,只有大的使用量,才能打磨出好模型。目前,豆包大模型日均处理1,200亿tokens文本、生成3,000万张图片。为助力企业做好大模型场景落地,字节跳动自主研发的豆包大模型将通过火山
 利用升腾AI技术,秦岭·秦川交通大模型助力西安打造智慧交通创新中心
Oct 15, 2023 am 08:17 AM
利用升腾AI技术,秦岭·秦川交通大模型助力西安打造智慧交通创新中心
Oct 15, 2023 am 08:17 AM
“高度复杂、碎片化程度高、跨领域”一直是交通行业数智化升级路上的首要痛点。近日,由中科视语、西安市雁塔区政府、西安未来人工智能计算中心联合打造的参数规模千亿级的“秦岭·秦川交通大模型”,面向智慧交通领域,为西安及其周边地区打造智慧交通创新支点。 “秦岭·秦川交通大模型”结合西安当地海量开放场景下的交通生态数据、中科视语自研的原创先进算法以及西安未来人工智能计算中心升腾AI的强大算力,为路网监测、应急指挥、养护管理、公众出行等智慧交通全场景带来数智化变革。交通管理在不同城市有不同的特点,不同道路的交
 揭秘NVIDIA大模型推理框架:TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
揭秘NVIDIA大模型推理框架:TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
一、TensorRT-LLM的产品定位TensorRT-LLM是NVIDIA为大型语言模型(LLM)开发的可扩展推理方案。它基于TensorRT深度学习编译框架构建、编译和执行计算图,并借鉴了FastTransformer中高效的Kernels实现。此外,它还利用NCCL实现设备间的通信。开发者可以根据技术发展和需求差异,定制算子以满足特定需求,例如基于cutlass开发定制的GEMM。TensorRT-LLM是NVIDIA官方推理方案,致力于提供高性能并不断完善其实用性。TensorRT-LL
 对标GPT-4!中国移动九天大模型通过双备案
Apr 04, 2024 am 09:31 AM
对标GPT-4!中国移动九天大模型通过双备案
Apr 04, 2024 am 09:31 AM
4月4日消息,日前,国家网信办公布已备案大模型清单,中国移动“九天自然语言交互大模型”名列其中,标志着中国移动九天AI大模型可正式对外提供生成式人工智能服务。中国移动表示,这是同时通过国家“生成式人工智能服务备案”和“境内深度合成服务算法备案”双备案的首个央企研发的大模型。据介绍,九天自然语言交互大模型具有行业能力增强、安全可信、支持全栈国产化等特点,已形成90亿、139亿、570亿、千亿等多种参数量版本,可灵活部署于云、边、端不同场
 工业知识图谱进阶实战
Jun 13, 2024 am 11:59 AM
工业知识图谱进阶实战
Jun 13, 2024 am 11:59 AM
一、背景简介首先来介绍一下云问科技的发展历程。云问科技公...2023年,正是大模型盛行的时期,很多企业认为已经大模型之后图谱的重要性大大降低了,之前研究的预置的信息化系统也都不重要了。不过随着RAG的推广、数据治理的盛行,我们发现更高效的数据治理和高质量的数据是提升私有化大模型效果的重要前提,因此越来越多的企业开始重视知识建设的相关内容。这也推动了知识的构建和加工开始向更高水平发展,其中有很多技巧和方法可以挖掘。可见一个新技术的出现,并不是将所有的旧技术打败,也有可能将新技术和旧技术相互融合后
 新测试基准发布,最强开源Llama 3尴尬了
Apr 23, 2024 pm 12:13 PM
新测试基准发布,最强开源Llama 3尴尬了
Apr 23, 2024 pm 12:13 PM
如果试题太简单,学霸和学渣都能考90分,拉不开差距……随着Claude3、Llama3甚至之后GPT-5等更强模型发布,业界急需一款更难、更有区分度的基准测试。大模型竞技场背后组织LMSYS推出下一代基准测试Arena-Hard,引起广泛关注。Llama3的两个指令微调版本实力到底如何,也有了最新参考。与之前大家分数都相近的MTBench相比,Arena-Hard区分度从22.6%提升到87.4%,孰强孰弱一目了然。Arena-Hard利用竞技场实时人类数据构建,与人类偏好一致率也高达89.1%
 小米字节联手!小爱同学接入豆包大模型:手机、SU7已搭载
Jun 13, 2024 pm 05:11 PM
小米字节联手!小爱同学接入豆包大模型:手机、SU7已搭载
Jun 13, 2024 pm 05:11 PM
6月13日消息,据字节旗下“火山引擎”公众号介绍,小米旗下人工智能助手“小爱同学”与火山引擎达成合作,双方基于豆包大模型实现更智能的AI交互体验。据悉,字节跳动打造的豆包大模型,每日能够高效处理数量多达1200亿个的文本tokens、生成3000万张内容。小米借助豆包大模型提升自身模型的学习与推理能力,打造出全新的“小爱同学”,不仅更加精准地把握用户需求,还以更快的响应速度和更全面的内容服务。例如,当用户询问复杂的科学概念时,&ldq
