

GPT-4 模型架构泄露:包含 1.8 万亿参数、采用混合专家模型


7 月 13 日消息,外媒 Semianalysis 近日对 OpenAI 今年 3 月发布的 GPT-4 大模型进行了揭秘,其中包括 GPT-4 模型架构、训练和推理的基础设施、参数量、训练数据集、token 数、成本、混合专家模型(Mixture of Experts)等具体的参数和信息。
▲ 图源 Semianalysis
外媒表示,GPT-4 在 120 层中总共包含了 1.8 万亿参数,而 GPT-3 只有约 1750 亿个参数。而为了保持合理的成本,OpenAI 采用混合专家模型来进行构建。
IT之家注:混合专家模型(Mixture of Experts)是一种神经网络,该系统根据数据进行分离训练多个模型,在各模型输出后,系统将这些模型整合输出为一个单独的任务。
▲ 图源 Semianalysis
据悉,GPT-4 使用了 16 个混合专家模型 (mixture of experts),每个有 1110 亿个参数,每次前向传递路由经过两个专家模型。
此外,它有 550 亿个共享注意力参数,使用了包含 13 万亿 tokens 的数据集训练,tokens 不是唯一的,根据迭代次数计算为更多的 tokens。
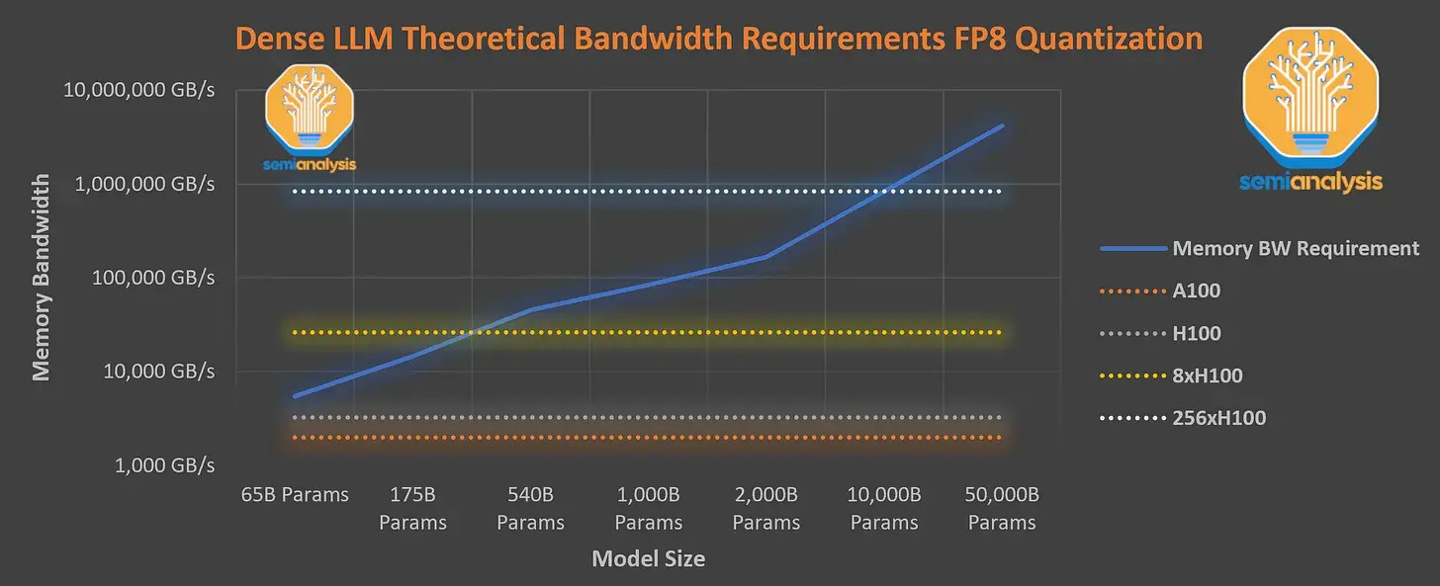
GPT-4 预训练阶段的上下文长度为 8k,32k 版本是对 8k 微调的结果,训练成本相当高,外媒表示,8x H100 也无法以每秒 33.33 个 Token 的速度提供所需的密集参数模型,因此训练该模型需要导致极高的推理成本,以 H100 物理机每小时 1 美元计算,那么一次的训练成本就高达 6300 万美元(约 4.51 亿元人民币)。
对此,OpenAI 选择使用云端的 A100 GPU 训练模型,将最终训练成本降至 2150 万美元(约 1.54 亿元人民币)左右,用稍微更长的时间,降低了训练成本。
以上是GPT-4 模型架构泄露:包含 1.8 万亿参数、采用混合专家模型的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想象一下,一个人工智能模型,不仅拥有超越传统计算的能力,还能以更低的成本实现更高效的性能。这不是科幻,DeepSeek-V2[1],全球最强开源MoE模型来了。DeepSeek-V2是一个强大的专家混合(MoE)语言模型,具有训练经济、推理高效的特点。它由236B个参数组成,其中21B个参数用于激活每个标记。与DeepSeek67B相比,DeepSeek-V2性能更强,同时节省了42.5%的训练成本,减少了93.3%的KV缓存,最大生成吞吐量提高到5.76倍。DeepSeek是一家探索通用人工智
 选择最适合数据的嵌入模型:OpenAI 和开源多语言嵌入的对比测试
Feb 26, 2024 pm 06:10 PM
选择最适合数据的嵌入模型:OpenAI 和开源多语言嵌入的对比测试
Feb 26, 2024 pm 06:10 PM
OpenAI最近宣布推出他们的最新一代嵌入模型embeddingv3,他们声称这是性能最出色的嵌入模型,具备更高的多语言性能。这一批模型被划分为两种类型:规模较小的text-embeddings-3-small和更为强大、体积较大的text-embeddings-3-large。这些模型的设计和训练方式的信息披露得很少,模型只能通过付费API访问。所以就出现了很多开源的嵌入模型但是这些开源的模型与OpenAI闭源模型相比如何呢?本文将对这些新模型与开源模型的性能进行实证比较。我们计划建立一个数据
 编程新范式,当Spring Boot遇上OpenAI
Feb 01, 2024 pm 09:18 PM
编程新范式,当Spring Boot遇上OpenAI
Feb 01, 2024 pm 09:18 PM
2023年,AI技术已经成为热点话题,对各行业产生了巨大影响,编程领域尤其如此。人们越来越认识到AI技术的重要性,Spring社区也不例外。随着GenAI(GeneralArtificialIntelligence)技术的不断进步,简化具备AI功能的应用程序的创建变得至关重要和迫切。在这个背景下,"SpringAI"应运而生,旨在简化开发AI功能应用程序的过程,使其变得简单直观,避免不必要的复杂性。通过"SpringAI",开发者可以更轻松地构建具备AI功能的应用程序,将其变得更加易于使用和操作
 第二代Ameca来了!和观众对答如流,面部表情更逼真,会说几十种语言
Mar 04, 2024 am 09:10 AM
第二代Ameca来了!和观众对答如流,面部表情更逼真,会说几十种语言
Mar 04, 2024 am 09:10 AM
人形机器人Ameca升级第二代了!最近,在世界移动通信大会MWC2024上,世界上最先进机器人Ameca又现身了。会场周围,Ameca引来一大波观众。得到GPT-4加持后,Ameca能够对各种问题做出实时反应。「来一段舞蹈」。当被问及是否有情感时,Ameca用一系列的面部表情做出回应,看起来非常逼真。就在前几天,Ameca背后的英国机器人公司EngineeredArts刚刚演示了团队最新的开发成果。视频中,机器人Ameca具备了视觉能力,能看到并描述房间整个情况、描述具体物体。最厉害的是,她还能
 大模型一对一战斗75万轮,GPT-4夺冠,Llama 3位列第五
Apr 23, 2024 pm 03:28 PM
大模型一对一战斗75万轮,GPT-4夺冠,Llama 3位列第五
Apr 23, 2024 pm 03:28 PM
关于Llama3,又有测试结果新鲜出炉——大模型评测社区LMSYS发布了一份大模型排行榜单,Llama3位列第五,英文单项与GPT-4并列第一。图片不同于其他Benchmark,这份榜单的依据是模型一对一battle,由全网测评者自行命题并打分。最终,Llama3取得了榜单中的第五名,排在前面的是GPT-4的三个不同版本,以及Claude3超大杯Opus。而在英文单项榜单中,Llama3反超了Claude,与GPT-4打成了平手。对于这一结果,Meta的首席科学家LeCun十分高兴,转发了推文并
 OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
如果AI模型给的答案一点也看不懂,你敢用吗?随着机器学习系统在更重要的领域得到应用,证明为什么我们可以信任它们的输出,并明确何时不应信任它们,变得越来越重要。获得对复杂系统输出结果信任的一个可行方法是,要求系统对其输出产生一种解释,这种解释对人类或另一个受信任的系统来说是可读的,即可以完全理解以至于任何可能的错误都可以被发现。例如,为了建立对司法系统的信任,我们要求法院提供清晰易读的书面意见,解释并支持其决策。对于大型语言模型来说,我们也可以采用类似的方法。不过,在采用这种方法时,确保语言模型生
 基于Rust的Zed编辑器已开源,内置对OpenAI和GitHub Copilot的支持
Feb 01, 2024 pm 02:51 PM
基于Rust的Zed编辑器已开源,内置对OpenAI和GitHub Copilot的支持
Feb 01, 2024 pm 02:51 PM
作者丨TimAnderson编译丨诺亚出品|51CTO技术栈(微信号:blog51cto)Zed编辑器项目目前仍处于预发布阶段,已在AGPL、GPL和Apache许可下开源。该编辑器以高性能和多种AI辅助选择为特色,但目前仅适用于Mac平台使用。内森·索博(NathanSobo)在一篇帖子中解释道,Zed项目在GitHub上的代码库中,编辑器部分采用了GPL许可,服务器端组件则使用了AGPL许可证,而GPUI(GPU加速用户界面)部分则采用了Apache2.0许可。GPUI是Zed团队开发的一款
 全球最强大模型一夜易主,GPT-4时代终结!Claude 3提前狙击GPT-5,3秒读懂万字论文理解力接近人类
Mar 06, 2024 pm 12:58 PM
全球最强大模型一夜易主,GPT-4时代终结!Claude 3提前狙击GPT-5,3秒读懂万字论文理解力接近人类
Mar 06, 2024 pm 12:58 PM
卷疯了卷疯了,大模型又变天了。就在刚刚,全球最强AI模型一夜易主,GPT-4被拉下神坛。Anthropic发布了最新的Claude3系列模型,一句话评价:真·全面碾压GPT-4!多模态和语言能力指标上,Claude3都赢麻了。用Anthropic的话说,Claude3系列模型在推理、数学、编码、多语言理解和视觉方面,都树立了新的行业基准!Anthropic,就是曾因安全理念不合,而从OpenAI「叛逃」出的员工组成的初创公司,他们的产品一再给OpenAI暴击。这次的Claude3,更是整了个大的
