

你能一口说出go中字符串转字节切片的容量嘛?
前一篇文章讲的是切片, 今天遇到的神奇问题还是和切片有关, 具体怎么个神奇法, 我们来看看下面几个现象
现象一
a := "abc" bs := []byte(a) fmt.Println(bs, len(bs), cap(bs)) // 输出: [97 98 99] 3 8
现象二
a := "abc" bs := []byte(a) fmt.Println(len(bs), cap(bs)) // 输出: 3 32
现象三
bs := []byte("abc")
fmt.Println(len(bs), cap(bs))
// 输出: 3 3现象四
a := "" bs := []byte(a) fmt.Println(bs, len(bs), cap(bs)) // 输出: [] 0 0
现象五
a := "" bs := []byte(a) fmt.Println(len(bs), cap(bs)) // 输出: 0 32
分析
到这儿我已经满脑子问号了

字符串变量转切片
一个小小的字符串转切片, 内部究竟发生了什么, 竟然如此的神奇。这种时候只好祭出前一篇文章的套路了, 看看汇编代码(希望之后有机会能够对go的汇编语法进行简单的介绍)有没有什么关键词能够帮助我们
以下为现象一转换的汇编代码关键部分
"".main STEXT size=495 args=0x0 locals=0xd8 0x0000 00000 (test.go:5) TEXT "".main(SB), ABIInternal, $216-0 0x0000 00000 (test.go:5) MOVQ (TLS), CX 0x0009 00009 (test.go:5) LEAQ -88(SP), AX 0x000e 00014 (test.go:5) CMPQ AX, 16(CX) 0x0012 00018 (test.go:5) JLS 485 0x0018 00024 (test.go:5) SUBQ $216, SP 0x001f 00031 (test.go:5) MOVQ BP, 208(SP) 0x0027 00039 (test.go:5) LEAQ 208(SP), BP 0x002f 00047 (test.go:5) FUNCDATA $0, gclocals·7be4bbacbfdb05fb3044e36c22b41e8b(SB) 0x002f 00047 (test.go:5) FUNCDATA $1, gclocals·648d0b72bb9d7f59fbfdbee57a078eee(SB) 0x002f 00047 (test.go:5) FUNCDATA $2, gclocals·2dfddcc7190380b1ae77e69d81f0a101(SB) 0x002f 00047 (test.go:5) FUNCDATA $3, "".main.stkobj(SB) 0x002f 00047 (test.go:6) PCDATA $0, $1 0x002f 00047 (test.go:6) PCDATA $1, $0 0x002f 00047 (test.go:6) LEAQ go.string."abc"(SB), AX 0x0036 00054 (test.go:6) MOVQ AX, "".a+96(SP) 0x003b 00059 (test.go:6) MOVQ $3, "".a+104(SP) 0x0044 00068 (test.go:7) MOVQ $0, (SP) 0x004c 00076 (test.go:7) PCDATA $0, $0 0x004c 00076 (test.go:7) MOVQ AX, 8(SP) 0x0051 00081 (test.go:7) MOVQ $3, 16(SP) 0x005a 00090 (test.go:7) CALL runtime.stringtoslicebyte(SB) 0x005f 00095 (test.go:7) MOVQ 40(SP), AX 0x0064 00100 (test.go:7) MOVQ 32(SP), CX 0x0069 00105 (test.go:7) PCDATA $0, $2 0x0069 00105 (test.go:7) MOVQ 24(SP), DX 0x006e 00110 (test.go:7) PCDATA $0, $0 0x006e 00110 (test.go:7) PCDATA $1, $1 0x006e 00110 (test.go:7) MOVQ DX, "".bs+112(SP) 0x0073 00115 (test.go:7) MOVQ CX, "".bs+120(SP) 0x0078 00120 (test.go:7) MOVQ AX, "".bs+128(SP)
以下为现象二转换的汇编代码关键部分
"".main STEXT size=393 args=0x0 locals=0xe0 0x0000 00000 (test.go:5) TEXT "".main(SB), ABIInternal, $224-0 0x0000 00000 (test.go:5) MOVQ (TLS), CX 0x0009 00009 (test.go:5) LEAQ -96(SP), AX 0x000e 00014 (test.go:5) CMPQ AX, 16(CX) 0x0012 00018 (test.go:5) JLS 383 0x0018 00024 (test.go:5) SUBQ $224, SP 0x001f 00031 (test.go:5) MOVQ BP, 216(SP) 0x0027 00039 (test.go:5) LEAQ 216(SP), BP 0x002f 00047 (test.go:5) FUNCDATA $0, gclocals·0ce64bbc7cfa5ef04d41c861de81a3d7(SB) 0x002f 00047 (test.go:5) FUNCDATA $1, gclocals·00590b99cfcd6d71bbbc6e05cb4f8bf8(SB) 0x002f 00047 (test.go:5) FUNCDATA $2, gclocals·8dcadbff7c52509cfe2d26e4d7d24689(SB) 0x002f 00047 (test.go:5) FUNCDATA $3, "".main.stkobj(SB) 0x002f 00047 (test.go:6) PCDATA $0, $1 0x002f 00047 (test.go:6) PCDATA $1, $0 0x002f 00047 (test.go:6) LEAQ go.string."abc"(SB), AX 0x0036 00054 (test.go:6) MOVQ AX, "".a+120(SP) 0x003b 00059 (test.go:6) MOVQ $3, "".a+128(SP) 0x0047 00071 (test.go:7) PCDATA $0, $2 0x0047 00071 (test.go:7) LEAQ ""..autotmp_5+64(SP), CX 0x004c 00076 (test.go:7) PCDATA $0, $1 0x004c 00076 (test.go:7) MOVQ CX, (SP) 0x0050 00080 (test.go:7) PCDATA $0, $0 0x0050 00080 (test.go:7) MOVQ AX, 8(SP) 0x0055 00085 (test.go:7) MOVQ $3, 16(SP) 0x005e 00094 (test.go:7) CALL runtime.stringtoslicebyte(SB) 0x0063 00099 (test.go:7) MOVQ 40(SP), AX 0x0068 00104 (test.go:7) MOVQ 32(SP), CX 0x006d 00109 (test.go:7) PCDATA $0, $3 0x006d 00109 (test.go:7) MOVQ 24(SP), DX 0x0072 00114 (test.go:7) PCDATA $0, $0 0x0072 00114 (test.go:7) PCDATA $1, $1 0x0072 00114 (test.go:7) MOVQ DX, "".bs+136(SP) 0x007a 00122 (test.go:7) MOVQ CX, "".bs+144(SP) 0x0082 00130 (test.go:7) MOVQ AX, "".bs+152(SP)
在看汇编代码之前, 我们首先来看一看runtime.stringtoslicebyte的函数签名
func stringtoslicebyte(buf *tmpBuf, s string) []byte
到这里只靠关键词已经无法看出更多的信息了,还是需要稍微了解一下汇编的语法,笔者在这里列出一点简单的分析, 之后我们还是可以通过取巧的方法发现更多的东西
// 现象一给runtime.stringtoslicebyte的传参 0x002f 00047 (test.go:6) LEAQ go.string."abc"(SB), AX // 将字符串"abc"放入寄存器AX 0x0036 00054 (test.go:6) MOVQ AX, "".a+96(SP) // 将AX中的内容存入变量a中 0x003b 00059 (test.go:6) MOVQ $3, "".a+104(SP) // 将字符串长度3存入变量a中 0x0044 00068 (test.go:7) MOVQ $0, (SP) // 将0 传递个runtime.stringtoslicebyte(SB)的第一个参数(笔者猜测对应go中的nil) 0x004c 00076 (test.go:7) PCDATA $0, $0 // 据说和gc有关, 具体还不清楚, 一般情况可以忽略 0x004c 00076 (test.go:7) MOVQ AX, 8(SP) // 将AX中的内容传递给runtime.stringtoslicebyte(SB)的第二个参数 0x0051 00081 (test.go:7) MOVQ $3, 16(SP) // 将字符串长度传递给runtime.stringtoslicebyte(SB)的第二个参数 0x005a 00090 (test.go:7) CALL runtime.stringtoslicebyte(SB) // 调用函数, 此行后面的几行代码是将返回值赋值给变量bs // 现象二给runtime.stringtoslicebyte的传参 0x002f 00047 (test.go:6) LEAQ go.string."abc"(SB), AX // 将字符串"abc"放入寄存器AX 0x0036 00054 (test.go:6) MOVQ AX, "".a+120(SP) // 将AX中的内容存入变量a中 0x003b 00059 (test.go:6) MOVQ $3, "".a+128(SP) // 将字符串长度3存入变量a中 0x0047 00071 (test.go:7) PCDATA $0, $2 0x0047 00071 (test.go:7) LEAQ ""..autotmp_5+64(SP), CX // 将内部变量autotmp_5放入寄存器CX 0x004c 00076 (test.go:7) PCDATA $0, $1 0x004c 00076 (test.go:7) MOVQ CX, (SP) // 将CX中的内容传递给runtime.stringtoslicebyte(SB)的第一个参数 0x0050 00080 (test.go:7) PCDATA $0, $0 0x0050 00080 (test.go:7) MOVQ AX, 8(SP) // 将AX中的内容传递给runtime.stringtoslicebyte(SB)的第二个参数 0x0055 00085 (test.go:7) MOVQ $3, 16(SP) // 将字符串长度传递给runtime.stringtoslicebyte(SB)的第二个参数 0x005e 00094 (test.go:7) CALL runtime.stringtoslicebyte(SB)
通过上面汇编代码的分析可以知道,现象一和现象二的区别就是传递给runtime.stringtoslicebyte的第一个参数不同。通过对runtime包中stringtoslicebyte函数分析,第一个参数是否有值和字符串长度会影响代码执行的分支,从而生成不同的切片, 因此容量不一样也是常理之中, 下面我们看源码
func stringtoslicebyte(buf *tmpBuf, s string) []byte {
var b []byte
if buf != nil && len(s) <= len(buf) {
*buf = tmpBuf{}
b = buf[:len(s)]
} else {
b = rawbyteslice(len(s))
}
copy(b, s)
return b
}然而, stringtoslicebyte的第一个参数什么情况下才会有值,什么情况下为nil, 我们仍然不清楚。那怎么办呢, 只好祭出全局搜索大法:
# 在go源码根目录执行下面的命令 grep stringtoslicebyte -r . | grep -v "//"
最终在go的编译器源码cmd/compile/internal/gc/walk.go发现了如下代码块
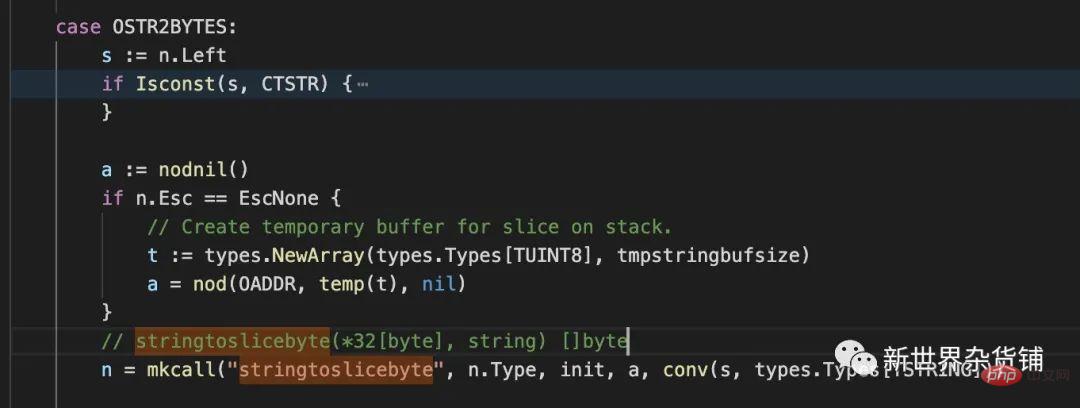
我们查看mkcall 函数签名可以知道, 从第四个参数开始的所有变量都会作为参数传递给第一个参数对应的函数, 最后生成一个*Node的变量。其中Node结构体解释如下:
// A Node is a single node in the syntax tree. // Actually the syntax tree is a syntax DAG, because there is only one // node with Op=ONAME for a given instance of a variable x. // The same is true for Op=OTYPE and Op=OLITERAL. See Node.mayBeShared.
综合上述信息我们得出的结论是,编译器会对stringtoslicebyte的函数调用生成一个AST(抽象语法树)对应的节点。因此我们也知道传递给stringtoslicebyte函数的第一个变量也就对应于上图中的变量a.
其中a的初始值为nodnil()的返回值,即默认为nil. 但是n.Esc == EscNone时,a会变成一个数组。我们看一下EscNone的解释.
// 此代码位于cmd/compile/internal/gc/esc.go中
const (
// ...
EscNone // Does not escape to heap, result, or parameters.
...
)由上可知, EscNone用来判断变量是否逃逸,到这儿了我们就很好办了,接下来我们对现象一和现象二的代码进行逃逸分析.
# 执行变量逃逸分析命令: go run -gcflags '-m -l' test.go # 现象一逃逸分析如下: ./test.go:7:14: ([]byte)(a) escapes to heap ./test.go:8:13: main ... argument does not escape ./test.go:8:13: bs escapes to heap ./test.go:8:21: len(bs) escapes to heap ./test.go:8:30: cap(bs) escapes to heap [97 98 99] 3 8 # 现象二逃逸分析如下: ./test.go:7:14: main ([]byte)(a) does not escape ./test.go:8:13: main ... argument does not escape ./test.go:8:17: len(bs) escapes to heap ./test.go:8:26: cap(bs) escapes to heap 3 32
根据上面的信息我们知道在现象一中,bs变量发生了逃逸,现象二中变量未发生逃逸,也就是说stringtoslicebyte函数的第一个参数在变量未发生逃逸时其值不为nil,变量发生逃逸时其值为nil。到这里我们已经搞明白stringtoslicebyte的第一个参数了, 那我们继续分析stringtoslicebyte的内部逻辑
我们在runtime/string.go中看到stringtoslicebyte第一个参数的类型定义如下:
const tmpStringBufSize = 32 type tmpBuf [tmpStringBufSize]byte
综上: 现象二中bs变量未发生变量逃逸, stringtoslicebyte第一个参数不为空且是一个长度为32的byte数组, 因此在现象二中生成了一个容量为32的切片
根据对stringtoslicebyte的源码分析, 我们知道现象一调用了rawbyteslice函数
func rawbyteslice(size int) (b []byte) {
cap := roundupsize(uintptr(size))
p := mallocgc(cap, nil, false)
if cap != uintptr(size) {
memclrNoHeapPointers(add(p, uintptr(size)), cap-uintptr(size))
}
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, int(cap)}
return
}由上面的代码知道, 切片的容量通过runtime/msize.go中的roundupsize函数计算得出, 其中_MaxSmallSize和class_to_size均定义在runtime/sizeclasses.go
func roundupsize(size uintptr) uintptr {
if size < _MaxSmallSize {
if size <= smallSizeMax-8 {
return uintptr(class_to_size[size_to_class8[(size+smallSizeDiv-1)/smallSizeDiv]])
} else {
return uintptr(class_to_size[size_to_class128[(size-smallSizeMax+largeSizeDiv-1)/largeSizeDiv]])
}
}
if size+_PageSize < size {
return size
}
return round(size, _PageSize)
}由于字符串abc的长度小于_MaxSmallSize(32768),故切片的长度只能取数组class_to_size中的值, 即0, 8, 16, 32, 48, 64, 80, 96, 112, 128....s
至此, 现象一中切片容量为什么为8也真相大白了。相信到这里很多人已经明白现象四和现象五是怎么回事儿了, 其逻辑分别与现象一和现象二是一致的, 有兴趣的, 可以在自己的电脑上面试一试。
字符串直接转切片
那你说了这么多, 现象三还是不能解释啊。请各位看官莫急, 接下来我们继续分析。
相信各位细心的小伙伴应该早就发现了我们在上面的cmd/compile/internal/gc/walk.go源码图中折叠了部分代码, 现在我们就将这块神秘的代码赤裸裸的展示出来
我们分析这块代码发现,go编译器在将字符串转字节切片生成AST时,总共分为三步。
先判断该变量是否是常量字符串,如果是常量字符串,则直接通过
types.NewArray创建一个和字符串等长的数组常量字符串生成的切片变量也要进行逃逸分析,并判断其大小是否大于函数栈允许分配给变量的最大长度, 从而判断节点是分配在栈上还是在堆上
最后,如果字符串长度是大于0, 将字符串内容复制到字节切片中, 然后返回。因此现象三中的切片容量是3也就完全清楚了
结论
字符串转字节切片步骤如下
判断是否是常量, 如果是常量则转换为等容量等长的字节切片
如果是变量, 先判断生成的切片是否发生变量逃逸
如果逃逸或者字符串长度>32, 则根据字符串长度可以计算出不同的容量
如果未逃逸且字符串长度<=32, 则字符切片容量为32
扩展
常见逃逸情况
函数返回局部指针
栈空间不足逃逸
动态类型逃逸, 很多函数参数为interface类型,比如fmt.Println(a ...interface{}),编译期间很难确定其参数的具体类型, 也会发生逃逸
闭包引用对象逃逸
以上是你能一口说出go中字符串转字节切片的容量嘛?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Go WebSocket 消息如何发送?
Jun 03, 2024 pm 04:53 PM
Go WebSocket 消息如何发送?
Jun 03, 2024 pm 04:53 PM
在Go中,可以使用gorilla/websocket包发送WebSocket消息。具体步骤:建立WebSocket连接。发送文本消息:调用WriteMessage(websocket.TextMessage,[]byte("消息"))。发送二进制消息:调用WriteMessage(websocket.BinaryMessage,[]byte{1,2,3})。
 如何在 Go 中使用正则表达式匹配时间戳?
Jun 02, 2024 am 09:00 AM
如何在 Go 中使用正则表达式匹配时间戳?
Jun 02, 2024 am 09:00 AM
在Go中,可以使用正则表达式匹配时间戳:编译正则表达式字符串,例如用于匹配ISO8601时间戳的表达式:^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}(\.\d+)?(Z|[+-][0-9]{2}:[0-9]{2})$。使用regexp.MatchString函数检查字符串是否与正则表达式匹配。
 深入理解 Golang 函数生命周期与变量作用域
Apr 19, 2024 am 11:42 AM
深入理解 Golang 函数生命周期与变量作用域
Apr 19, 2024 am 11:42 AM
在Go中,函数生命周期包括定义、加载、链接、初始化、调用和返回;变量作用域分为函数级和块级,函数内的变量在内部可见,而块内的变量仅在块内可见。
 Golang 与 Go 语言的区别
May 31, 2024 pm 08:10 PM
Golang 与 Go 语言的区别
May 31, 2024 pm 08:10 PM
Go和Go语言是不同的实体,具有不同的特性。Go(又称Golang)以其并发性、编译速度快、内存管理和跨平台优点而闻名。Go语言的缺点包括生态系统不如其他语言丰富、语法更严格以及缺乏动态类型。
 Golang 技术性能优化中如何避免内存泄漏?
Jun 04, 2024 pm 12:27 PM
Golang 技术性能优化中如何避免内存泄漏?
Jun 04, 2024 pm 12:27 PM
内存泄漏会导致Go程序内存不断增加,可通过:关闭不再使用的资源,如文件、网络连接和数据库连接。使用弱引用防止内存泄漏,当对象不再被强引用时将其作为垃圾回收目标。利用go协程,协程栈内存会在退出时自动释放,避免内存泄漏。
 如何在 IDE 中查看 Golang 函数文档?
Apr 18, 2024 pm 03:06 PM
如何在 IDE 中查看 Golang 函数文档?
Apr 18, 2024 pm 03:06 PM
使用IDE查看Go函数文档:将光标悬停在函数名称上。按下热键(GoLand:Ctrl+Q;VSCode:安装GoExtensionPack后,F1并选择"Go:ShowDocumentation")。
 如何使用 Golang 的错误包装器?
Jun 03, 2024 pm 04:08 PM
如何使用 Golang 的错误包装器?
Jun 03, 2024 pm 04:08 PM
在Golang中,错误包装器允许你在原始错误上追加上下文信息,从而创建新错误。这可用于统一不同库或组件抛出的错误类型,简化调试和错误处理。步骤如下:使用errors.Wrap函数将原有错误包装成新错误。新错误包含原始错误的上下文信息。使用fmt.Printf输出包装后的错误,提供更多上下文和可操作性。在处理不同类型的错误时,使用errors.Wrap函数统一错误类型。
 Go 并发函数的单元测试指南
May 03, 2024 am 10:54 AM
Go 并发函数的单元测试指南
May 03, 2024 am 10:54 AM
对并发函数进行单元测试至关重要,因为这有助于确保其在并发环境中的正确行为。测试并发函数时必须考虑互斥、同步和隔离等基本原理。可以通过模拟、测试竞争条件和验证结果等方法对并发函数进行单元测试。
