站在未来的路口,回望历史的迷途,常常会很有意思,因为我们会不经意地兴起疯狂的念头,例如如果当年某事提前发生了,而另外一件事又没有发生会怎样?一如当年的奥匈帝国皇位继承人斐迪南大公夫妇如果没有被塞尔维亚族热血青年普林西普枪杀会怎样,又如若当年的丘老道没有经过牛家村会怎样?
2007年底,淘宝开启一个叫做“五彩石”的内部重构项目,这个项目后来成为了淘宝服务化、面向分布式走自研之路,走出了互联网中间件体系之始,而淘宝服务注册中心ConfigServer于同年诞生。
2008年前后,Yahoo 这个曾经的互联网巨头开始逐渐在公开场合宣讲自己的大数据分布式协调产品 ZooKeeper,这个产品参考了Google 发表的关于Chubby以及 Paxos 的论文。
2010年11月,ZooKeeper从 Apache Hadoop的子项目发展为 Apache的顶级项目,正式宣告 ZooKeeper成为一个工业级的成熟稳定的产品。
2011年,阿里巴巴开源Dubbo,为了更好开源,需要剥离与阿里内部系统的关系,Dubbo 支持了开源的 ZooKeeper 作为其注册中心,后来在国内,在业界诸君的努力实践下,Dubbo + ZooKeeper 的典型的服务化方案成就了 ZooKeeper 作为注册中心的声名。
2015年双11,ConfigServer 服务内部近8个年头过去了,阿里巴巴内部“服务规模”超几百万 ,以及推进“千里之外”的IDC容灾技术战略等,共同促使阿里巴巴内部开启了 ConfigServer 2.0 到 ConfigServer 3.0 的架构升级之路。
时间走向2018年,站在10年的时间路口上,有多少人愿意在追逐日新月异的新潮技术概念的时候,稍微慢一下脚步,仔细凝视一下服务发现这个领域,有多少人想到过或者思考过一个问题:
而回望历史,我们也偶有迷思,在服务发现这个场景下,如果当年 ZooKeeper 的诞生之日比我们 HSF 的注册中心 ConfigServer 早一点会怎样?
我们会不会走向先使用ZooKeeper然后疯狂改造与修补ZooKeeper以适应阿里巴巴的服务化场景与需求的弯路?
但是,站在今天和前人的肩膀上,我们从未如今天这样坚定的认知到,在服务发现领域,ZooKeeper 根本就不能算是最佳的选择,一如这些年一直与我们同行的Eureka以及这篇文章 Eureka! Why You Shouldn’t Use ZooKeeper for Service Discovery 那坚定的阐述一样,为什么你不应该用 ZooKeeper 做服务发现!
吾道不孤矣。
接下来,让我们回归对服务发现的需求分析,结合阿里巴巴在关键场景上的实践,来一一分析,一起探讨为何说 ZooKeeper 并不是最合适的注册中心解决方案。
CAP 和 BASE 理论相信读者都已经耳熟能详,也已成了指导分布式系统及互联网应用构建的关键原则之一,在此不再赘述其理论,我们直接进入对注册中心的数据一致性和可用性需求的分析:
注册中心最本质的功能可以看成是一个Query函数 Si = F(service-name),以 service-name 为查询参数,service-name 对应的服务的可用的 endpoints (ip:port) 列表为返回值.
注: 后文将 service 简写为 svc。
先来看看关键数据 endpoints (ip:port) 不一致性带来的影响,即 CAP 中的 C 不满足带来的后果 :
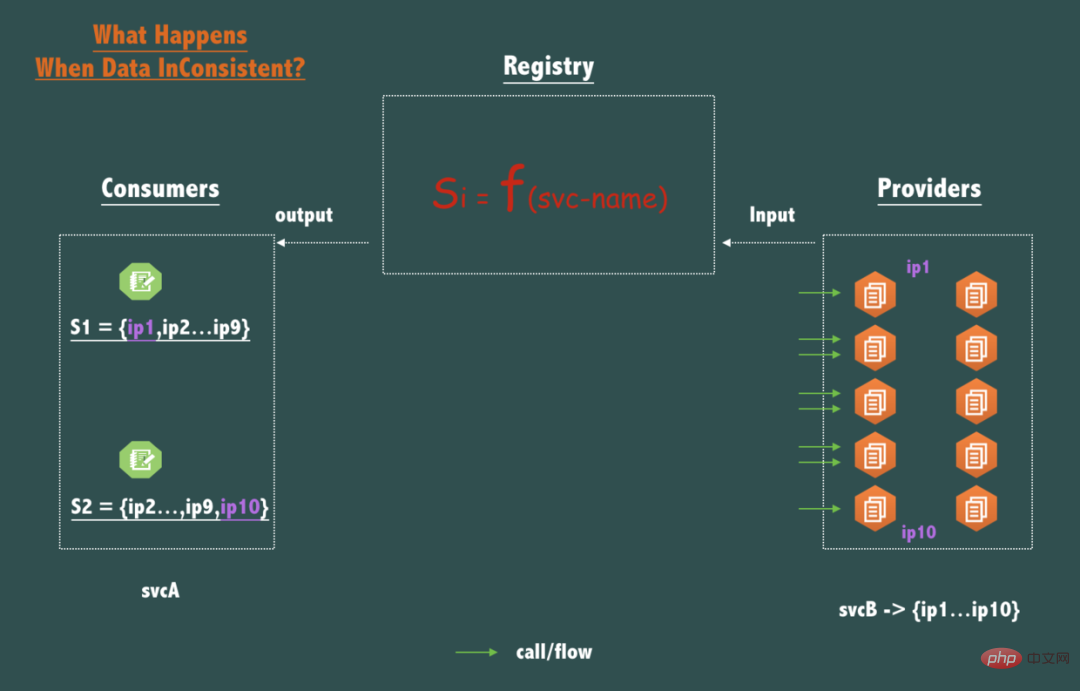
如上图所示,如果一个 svcB 部署了10个节点 (副本/Replica),如果对于同一个服务名 svcB, 调用者 svcA 的2个节点的2次查询返回了不一致的数据,例如: S1 = { ip1,ip2,ip3...,ip9 }, S2 = { ip2,ip3,....ip10 }, 那么这次不一致带来的影响是什么?
相信你一定已经看出来了,svcB 的各个节点流量会有一点不均衡。
ip1和ip10相对其它8个节点{ip2...ip9},请求流量小了一点,但很明显,在分布式系统中,即使是对等部署的服务,因为请求到达的时间,硬件的状态,操作系统的调度,虚拟机的 GC 等,任何一个时间点,这些对等部署的节点状态也不可能完全一致,而流量不一致的情况下,只要注册中心在SLA承诺的时间内(例如1s内)将数据收敛到一致状态(即满足最终一致),流量将很快趋于统计学意义上的一致,所以注册中心以最终一致的模型设计在生产实践中完全可以接受。
接下来我们看一下网络分区(Network Partition)情况下注册中心不可用对服务调用产生的影响,即 CAP 中的A不满足时带来的影响。
考虑一个典型的ZooKeeper三机房容灾5节点部署结构 (即2-2-1结构),如下图:
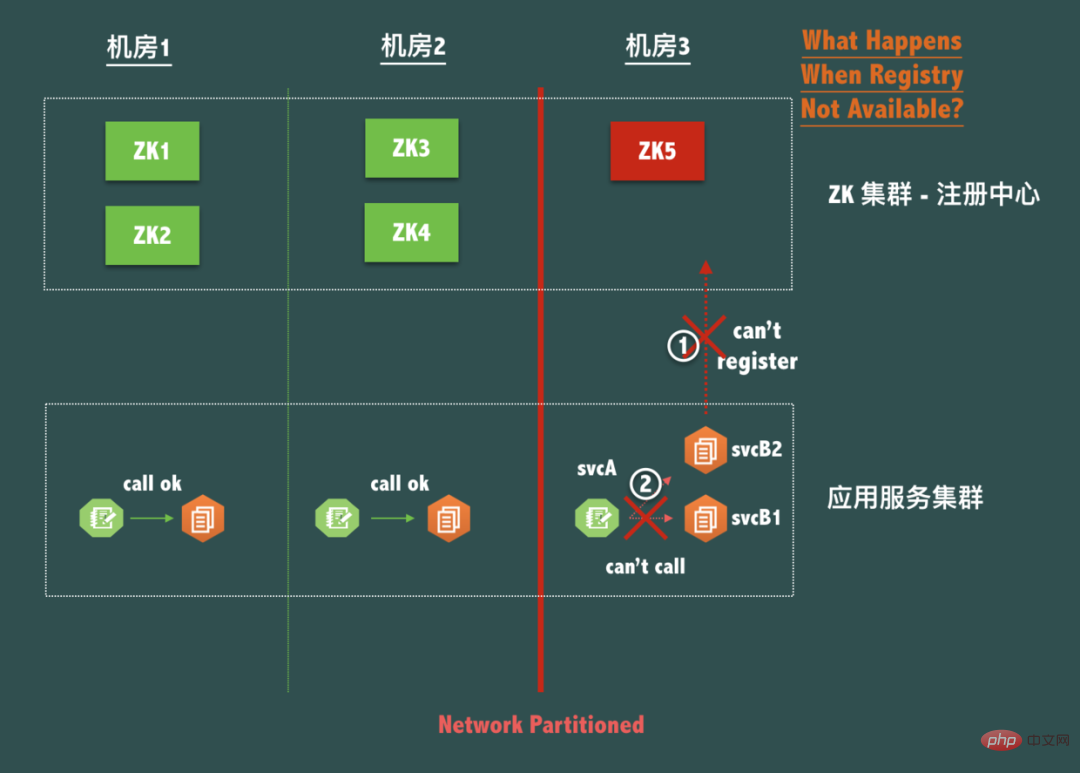
当机房3出现网络分区(Network Partitioned)的时候,即机房3在网络上成了孤岛,我们知道虽然整体 ZooKeeper 服务是可用的,但是节点ZK5是不可写的,因为联系不上 Leader。
也就是说,这时候机房3的应用服务 svcB 是不可以新部署,重新启动,扩容或者缩容的,但是站在网络和服务调用的角度看,机房3的 svcA 虽然无法调用机房1和机房2的 svcB,但是与机房3的svcB之间的网络明明是 OK 的啊,为什么不让我调用本机房的服务?
现在因为注册中心自身为了保脑裂(P)下的数据一致性(C)而放弃了可用性,导致了同机房的服务之间出现了无法调用,这是绝对不允许的!可以说在实践中,注册中心不能因为自身的任何原因破坏服务之间本身的可连通性,这是注册中心设计应该遵循的铁律! 后面在注册中心客户端灾容上我们还会继续讨论。
同时我们再考虑一下这种情况下的数据不一致性,如果机房1,2,3之间都成了孤岛,那么如果每个机房的svcA都只拿到本机房的 svcB 的ip列表,也即在各机房svcB 的ip列表数据完全不一致,影响是什么?
其实没啥大影响,只是这种情况下,全都变成了同机房调用,我们在设计注册中心的时候,有时候甚至会主动利用这种注册中心的数据可以不一致性,来帮助应用主动做到同机房调用,从而优化服务调用链路 RT 的效果!
通过以上我们的阐述可以看到,在 CAP 的权衡中,注册中心的可用性比数据强一致性更宝贵,所以整体设计更应该偏向 AP,而非 CP,数据不一致在可接受范围,而P下舍弃A却完全违反了注册中心不能因为自身的任何原因破坏服务本身的可连通性的原则。
你所在公司的“微服务”规模有多大?数百微服务?部署了上百个节点?那么3年后呢?互联网是产生奇迹的地方,也许你的“服务”一夜之间就家喻户晓,流量倍增,规模翻番!
当数据中心服务规模超过一定数量 (服务规模=F{服务pub数,服务sub数}),作为注册中心的 ZooKeeper 很快就会像下图的驴子一样不堪重负

其实当ZooKeeper用对地方时,即用在粗粒度分布式锁,分布式协调场景下,ZooKeeper 能支持的tps 和支撑的连接数是足够用的,因为这些场景对于 ZooKeeper 的扩展性和容量诉求不是很强烈。
但在服务发现和健康监测场景下,随着服务规模的增大,无论是应用频繁发布时的服务注册带来的写请求,还是刷毫秒级的服务健康状态带来的写请求,还是恨不能整个数据中心的机器或者容器皆与注册中心有长连接带来的连接压力上,ZooKeeper 很快就会力不从心,而 ZooKeeper 的写并不是可扩展的,不可以通过加节点解决水平扩展性问题。
要想在 ZooKeeper 基础上硬着头皮解决服务规模的增长问题,一个实践中可以考虑的方法是想办法梳理业务,垂直划分业务域,将其划分到多个 ZooKeeper 注册中心,但是作为提供通用服务的平台机构组,因自己提供的服务能力不足要业务按照技术的指挥棒配合划分治理业务,真的可行么?
而且这又违反了因为注册中心自身的原因(能力不足)破坏了服务的可连通性,举个简单的例子,1个搜索业务,1个地图业务,1个大文娱业务,1个游戏业务,他们之间的服务就应该老死不相往来么?也许今天是肯定的,那么明天呢,1年后呢,10年后呢?谁知道未来会要打通几个业务域去做什么奇葩的业务创新?注册中心作为基础服务,无法预料未来的时候当然不能妨碍业务服务对未来固有联通性的需求。
需要,也不需要。
我们知道 ZooKeeper 的 ZAB 协议对每一个写请求,会在每个ZooKeeper节点上保持写一个事务日志,同时再加上定期的将内存数据镜像(Snapshot)到磁盘来保证数据的一致性和持久性,以及宕机之后的数据可恢复,这是非常好的特性,但是我们要问,在服务发现场景中,其最核心的数据-实时的健康的服务的地址列表真的需要数据持久化么?
对于这份数据,答案是否定的。
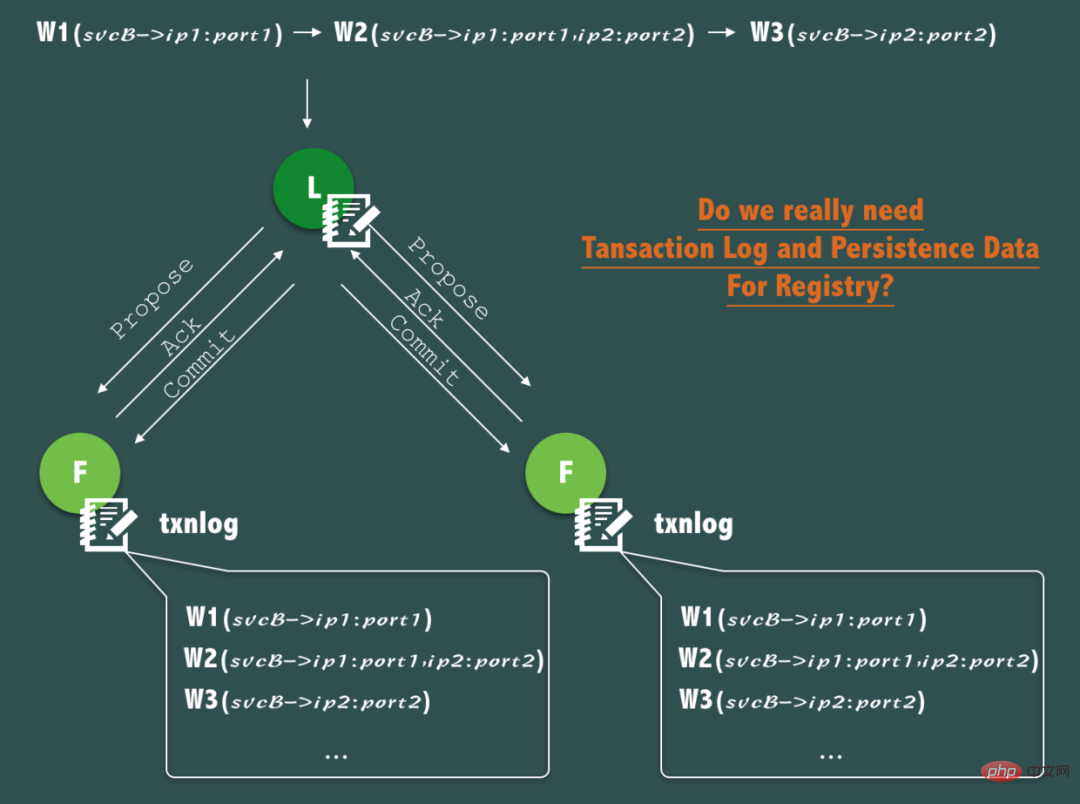
如上图所示,如果 svcB 经历了注册服务(ip1)到扩容到2个节点(ip1,ip2)到因宕机缩容 (ip1 宕机),这个过程中,产生了3次针对 ZooKeeper 的写操作。
但是仔细分析,通过事务日志,持久化连续记录这个变化过程其实意义不大,因为在服务发现中,服务调用发起方更关注的是其要调用的服务的实时的地址列表和实时健康状态,每次发起调用时,并不关心要调用的服务的历史服务地址列表、过去的健康状态。
但是为什么又说需要呢,因为一个完整的生产可用的注册中心,除了服务的实时地址列表以及实时的健康状态之外,还会存储一些服务的元数据信息,例如服务的版本,分组,所在的数据中心,权重,鉴权策略信息,service label等元信息,这些数据需要持久化存储,并且注册中心应该提供对这些元信息的检索的能力。
使用 ZooKeeper 作为服务注册中心时,服务的健康检测常利用 ZooKeeper 的 Session 活性 Track机制 以及结合 Ephemeral ZNode的机制,简单而言,就是将服务的健康监测绑定在了 ZooKeeper 对于 Session 的健康监测上,或者说绑定在TCP长链接活性探测上了。
这在很多时候也会造成致命的问题,ZK 与服务提供者机器之间的TCP长链接活性探测正常的时候,该服务就是健康的么?答案当然是否定的!注册中心应该提供更丰富的健康监测方案,服务的健康与否的逻辑应该开放给服务提供方自己定义,而不是一刀切搞成了 TCP 活性检测!
健康检测的一大基本设计原则就是尽可能真实的反馈服务本身的真实健康状态,否则一个不敢被服务调用者相信的健康状态判定结果还不如没有健康检测。
前文提过,在实践中,注册中心不能因为自身的任何原因破坏服务之间本身的可连通性,那么在可用性上,一个本质的问题,如果注册中心(Registry)本身完全宕机了,svcA 调用 svcB链路应该受到影响么?
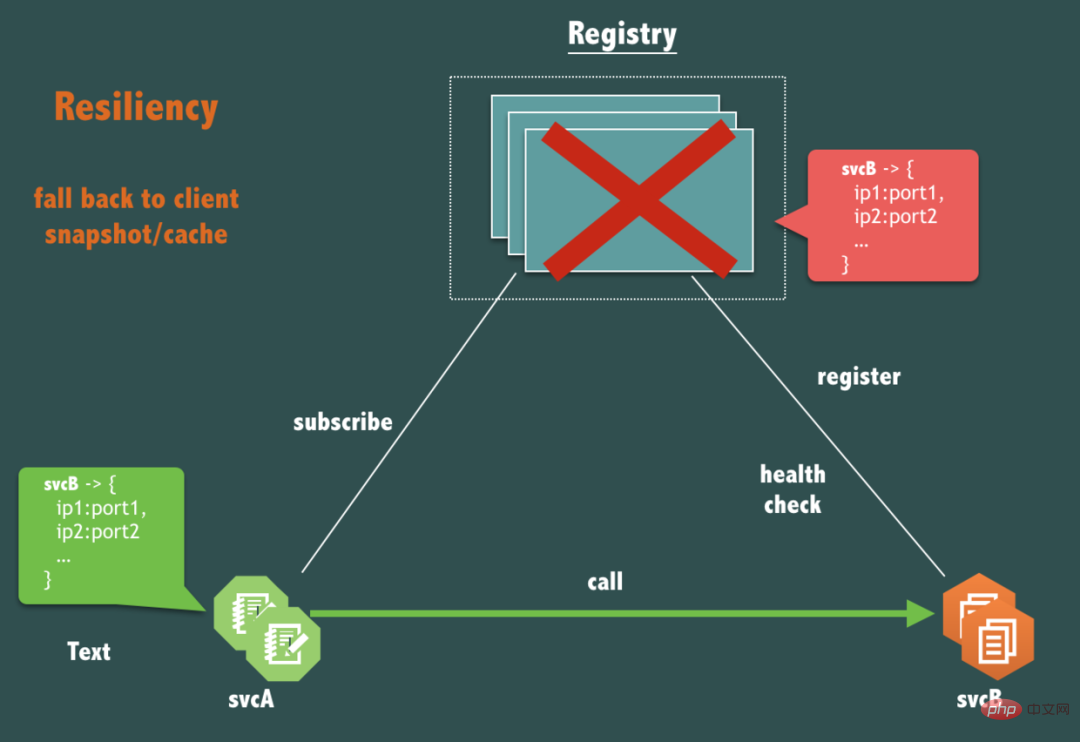
是的,不应该受到影响。
服务调用(请求响应流)链路应该是弱依赖注册中心,必须仅在服务发布,机器上下线,服务扩缩容等必要时才依赖注册中心。
这需要注册中心仔细的设计自己提供的客户端,客户端中应该有针对注册中心服务完全不可用时做容灾的手段,例如设计客户端缓存数据机制(我们称之为 client snapshot)就是行之有效的手段。另外,注册中心的 health check 机制也要仔细设计以便在这种情况不会出现诸如推空等情况的出现。
ZooKeeper的原生客户端并没有这种能力,所以利用 ZooKeeper 实现注册中心的时候我们一定要问自己,如果把 ZooKeeper 所有节点全干掉,你生产上的所有服务调用链路能不受任何影响么?而且应该定期就这一点做故障演练。
ZooKeeper 看似很简单的一个产品,但在生产上大规模使用并且用好,并不是那么理所当然的事情。如果你决定在生产中引入 ZooKeeper,你最好做好随时向 ZooKeeper 技术专家寻求帮助的心理预期,最典型的表现是在两个方面:
ZooKeeper 的原生客户端绝对称不上好用,Curator 会好一点,但其实也好的有限,要完全理解 ZooKeeper 客户端与 Server 之间的交互协议也并不简单,完全理解并掌握 ZooKeeper Client/Session 的状态机(下图)也并不是那么简单明了:
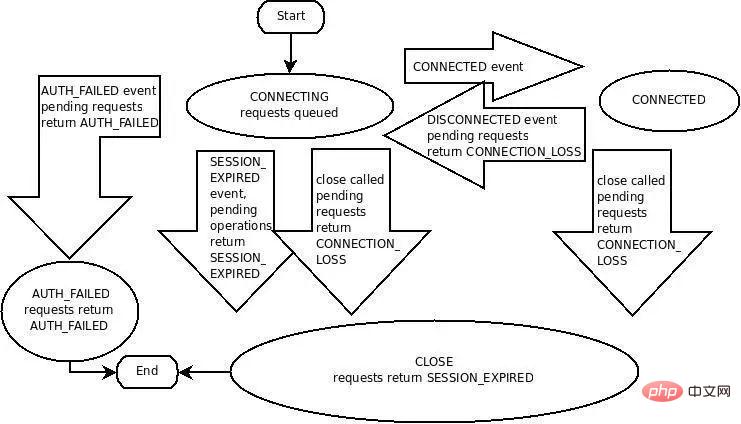
但基于 ZooKeeper 的服务发现方案却是依赖 ZooKeeper 提供的长连接/Session管理,Ephemeral ZNode,Event&Notification, ping 机制上,所以要用好ZooKeeper 做服务发现,恰恰要理解这些 ZooKeeper 核心的机制原理,这有时候会让你陷入暴躁,我只是想要个服务发现而已,怎么要知道这么多?而如果这些你都理解了并且不踩坑,恭喜你,你已经成为ZooKeeper的技术专家了。
我们在阿里巴巴内部应用接入 ZooKeeper 时,有一个《ZooKeeper 应用接入必知必会》的 WIKI,其中关于异常处理有过如下的论述:
如果说要选出应用开发者在使用ZooKeeper的过程中,最需要了解清楚的事情?那么根据我们之前的支持经验,一定是异常处理。
当所有一切(宿主机,磁盘,网络等等)都很幸运的正常工作的时候,应用与ZooKeeper可能也会运行的很好,但不幸的是,我们整天会面对各种意外,而且这遵循墨菲定律,意料之外的坏事情总是在你最担心的时候发生。
所以务必仔细了解 ZooKeeper 在一些场景下会出现的异常和错误,确保您正确的理解了这些异常和错误,以及知道您的应用如何正确的处理这些情况。
简单来说,这是个可以在同一个 ZooKeeper Session 恢复的异常(Recoverable), 但是应用开发者需要负责将应用恢复到正确的状态。
发生这个异常的原因有很多,例如应用机器与ZooKeeper节点之间网络闪断,ZooKeeper节点宕机,服务端Full GC时间超长,甚至你的应用进程Hang死,应用进程 Full GC 时间超长之后恢复都有可能。
要理解这个异常,需要了解分布式应用中的一个典型的问题,如下图: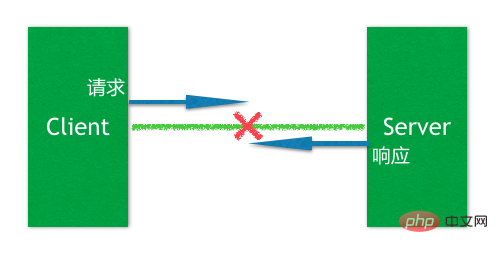
在一个典型的客户端请求、服务端响应中,当它们之间的长连接闪断的时候,客户端感知到这个闪断事件的时候,会处在一个比较尴尬的境地,那就是无法确定该事件发生时附近的那个请求到底处在什么状态,Server端到底收到这个请求了么?已经处理了么?因为无法确定这一点,所以当客户端重新连接上Server之后,这个请求是否应该重试(Retry)就也要打一个问号。
所以在处理连接断开事件中,应用开发者必须清楚处于闪断附近的那个请求是什么(这常常难以判断),该请求是否是幂等的,对于业务请求在Server端服务处理上对于"仅处理一次" "最多处理一次" "最少处理一次"语义要有选择和预期。
举个例子,如果应用在收到 ConnectionLossException 时,之前的请求是Create操作,那么应用的catch到这个异常,应用一个可能的恢复逻辑就是,判断之前请求创建的节点的是否已经存在了,如果存在就不要再创建了,否则就创建。
再比如,如果应用使用了exists Watch 去监听一个不存在的节点的创建的事件,那么在ConnectionLossException的期间,有可能遇到的情况是,在这个闪断期间,其它的客户端进程可能已经创建了节点,并且又已经删除了,那么对于当前应用来说,就miss了一次关心的节点的创建事件,这种miss对应用的影响是什么?是可以忍受的还是不可接受?需要应用开发者自己根据业务语义去评估和处理。
Session 超时是一个不可恢复的异常,这是指应用Catch到这个异常的时候,应用不可能在同一个Session中恢复应用状态,必须要重新建立新Session,老Session关联的临时节点也可能已经失效,拥有的锁可能已经失效。...
阿里巴巴的小伙伴在自行尝试使用 ZooKeeper 做服务发现的过程中,曾经在我们的内网技术论坛上总结过一篇自己踩坑的经验分享

在该文中中肯的提到:
... 在编码过程中发现很多可能存在的陷阱,毛估估,第一次使用zk来实现集群管理的人应该有80%以上会掉坑,有些坑比较隐蔽,在网络问题或者异常的场景时才会出现,可能很长一段时间才会暴露出来 ...
阿里巴巴是不是完全没有使用 ZooKeeper?并不是。
熟悉阿里巴巴技术体系的都知道,其实阿里巴巴维护了目前国内最大规模的ZooKeeper集群,整体规模有近千台的ZooKeeper服务节点。
同时阿里巴巴中间件内部也维护了一个面向大规模生产的、高可用、更易监控和运维的ZooKeeper的代码分支TaoKeeper,如果以我们近10年在各个业务线和生产上使用ZooKeeper的实践,给ZooKeeper 用一个短语评价的话,那么我们认为ZooKeeper应该是 “The King Of Coordination for Big Data”!
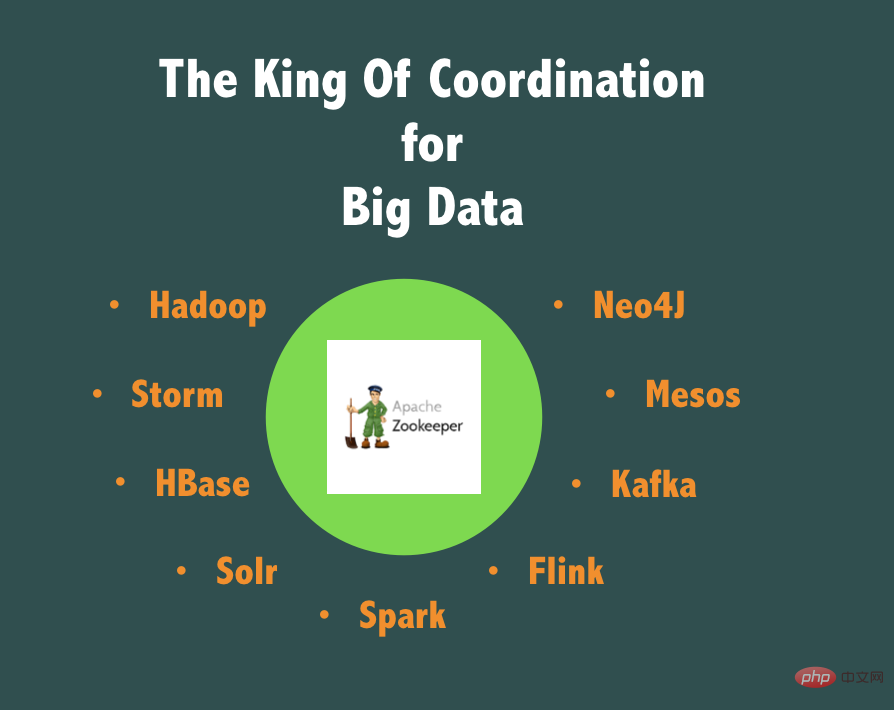
在粗粒度分布式锁,分布式选主,主备高可用切换等不需要高TPS 支持的场景下有不可替代的作用,而这些需求往往多集中在大数据、离线任务等相关的业务领域,因为大数据领域,讲究分割数据集,并且大部分时间分任务多进程/线程并行处理这些数据集,但是总是有一些点上需要将这些任务和进程统一协调,这时候就是 ZooKeeper 发挥巨大作用的用武之地。
但是在交易场景交易链路上,在主业务数据存取,大规模服务发现、大规模健康监测等方面有天然的短板,应该竭力避免在这些场景下引入 ZooKeeper,在阿里巴巴的生产实践中,应用对ZooKeeper申请使用的时候要进行严格的场景、容量、SLA需求的评估。
所以可以使用 ZooKeeper,但是大数据请向左,而交易则向右,分布式协调向左,服务发现向右。
感谢你耐心的阅读到这里,至此,我相信你已经理解,我们写这篇文章并不是全盘否定 ZooKeeper,而只是根据我们阿里巴巴在近10年来在大规模服务化上的生产实践,对我们在服务发现和注册中心设计及使用上的经验教训进行一个总结,希望对业界就如何更好的使用 ZooKeeper,如何更好的设计自己的服务注册中心有所启发和帮助。最后,条条大路通罗马,衷心祝愿你的注册中心直接就诞生在罗马。
以上是阿里为什么不用 ZooKeeper 做服务发现?的详细内容。更多信息请关注PHP中文网其他相关文章!























