

Pandas+Pyecharts | 电子产品销售数据分析可视化+用户RFM画像

本期利用 python 分析一份 电子产品销售数据,看看:
每月订单数量订单额
每天订单数量分布
男女用户订单比例
女性/男性购买商品TOP20
各年龄段订单数量订单额
用户RFM等级画像
等等...
希望对大家有所帮助,如有疑问或者需要改进的地方可以联系小编。
涉及到的库:
Pandas — 数据处理
Pyecharts — 数据可视化
import pandas as pd from pyecharts.charts import Line from pyecharts.charts import Bar from pyecharts.charts import Pie from pyecharts.charts import Grid from pyecharts.charts import PictorialBar from pyecharts import options as opts from pyecharts.commons.utils import JsCode import warnings warnings.filterwarnings('ignore')
2.1 读取数据
df = pd.read_csv("电子产品销售分析.csv")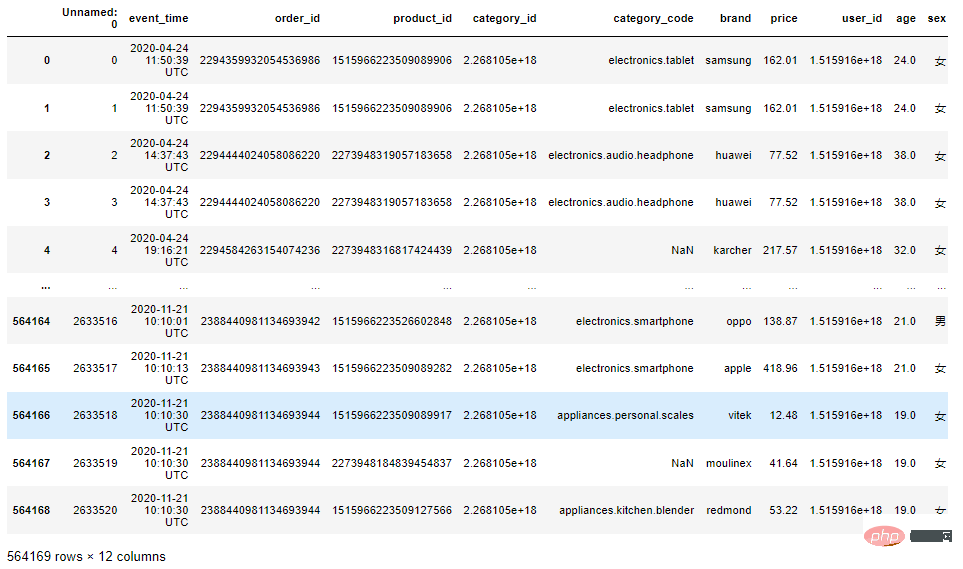
2.2 数据信息
df.info()
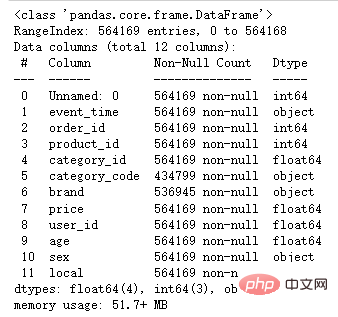
一共有564169条数据,其中category_code、brand两列有部分数据缺失。
2.3 去掉部分用不到的列
df1 = df[['event_time', 'order_id', 'category_code', 'brand', 'price', 'user_id', 'age', 'sex', 'local']] df1.shape
(564169, 9)
2.4 去除重复数据
df1 = df1.drop_duplicates() df1.shape
(556456, 9)
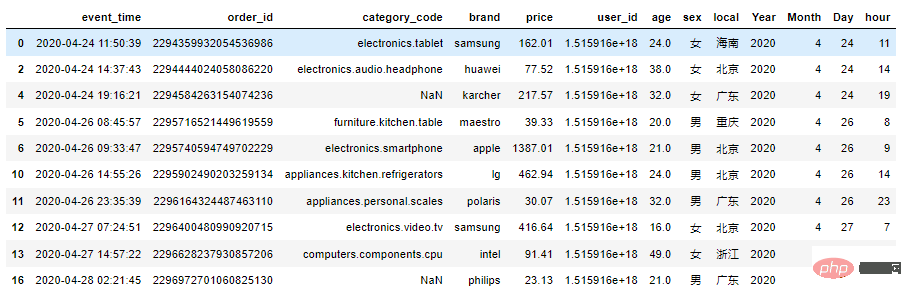
2.5 增加部分时间列
df1['event_time'] = pd.to_datetime(df1['event_time'].str[:19],format="%Y-%m-%d %H:%M:%S") df1['Year'] = df1['event_time'].dt.year df1['Month'] = df1['event_time'].dt.month df1['Day'] = df1['event_time'].dt.day df1['hour'] = df1['event_time'].dt.hour df1.head(10)
2.6 过滤数据,也可以选择均值填充
df1 = df1.dropna(subset=['category_code']) df1 = df1[(df1["Year"] == 2020)&(df1["price"] > 0)] df1.shape
(429261, 13)
2.7 对年龄分组
df1['age_group'] = pd.cut(df1['age'],[10,20,30,40,50],labels=['10-20','20-30','30-40','40-50'])
2.8 增加商品一、二级分类
df1["category_code_1"] = df1["category_code"].apply(lambda x: x.split(".")[0] if "." in x else x)
df1["category_code_2"] = df1["category_code"].apply(lambda x: x.split(".")[-1] if "." in x else x)
df1.head(10)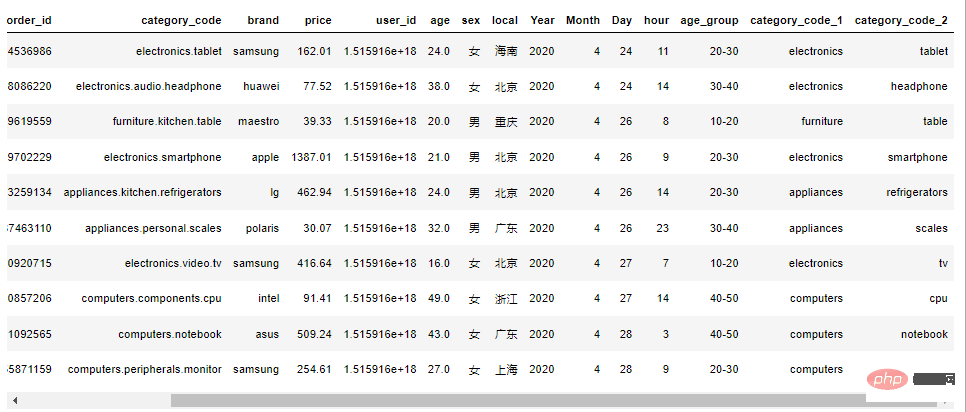
def get_bar1():
bar1 = (
Bar()
.add_xaxis(x_data)
.add_yaxis("订单数量", y_data1)
.extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts(formatter="{value}万")))
.set_global_opts(
legend_opts=opts.LegendOpts(pos_top='25%', pos_left='center'),
title_opts=opts.TitleOpts(
title='1-每月订单数量订单额',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='7%',
pos_left="center"
)
)
)
line = (
Line()
.add_xaxis(x_data)
.add_yaxis("订单额", y_data2, yaxis_index=1)
)
bar1.overlap(line)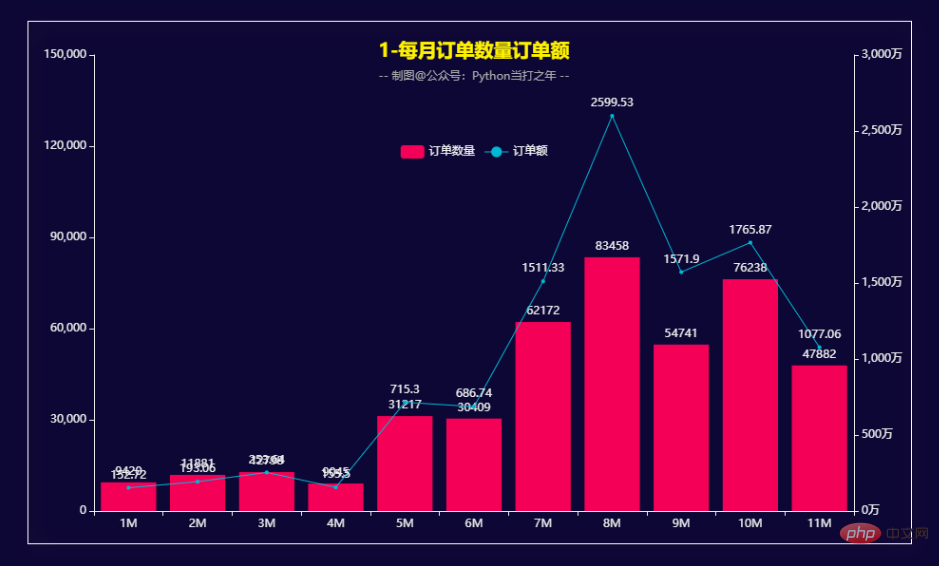
下半年的订单量和订单额相对于上半年明显增多。 8月份的订单量和订单额达到峰值。
def get_bar2():
pie1 = (
Pie()
.add(
"",
datas,
radius=["13%", "25%"],
label_opts=opts.LabelOpts(formatter="{b}: {d}%"),
)
)
bar1 = (
Bar(init_opts=opts.InitOpts(theme='dark', width='1000px', height='600px', bg_color='#0d0735'))
.add_xaxis(x_data)
.add_yaxis("", y_data, itemstyle_opts=opts.ItemStyleOpts(color=JsCode(color_function)))
.set_global_opts(
legend_opts=opts.LegendOpts(is_show=False),
title_opts=opts.TitleOpts(
title='2-一月各天订单数量分布',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='7%',
pos_left="center"
)
)
)
bar1.overlap(pie1)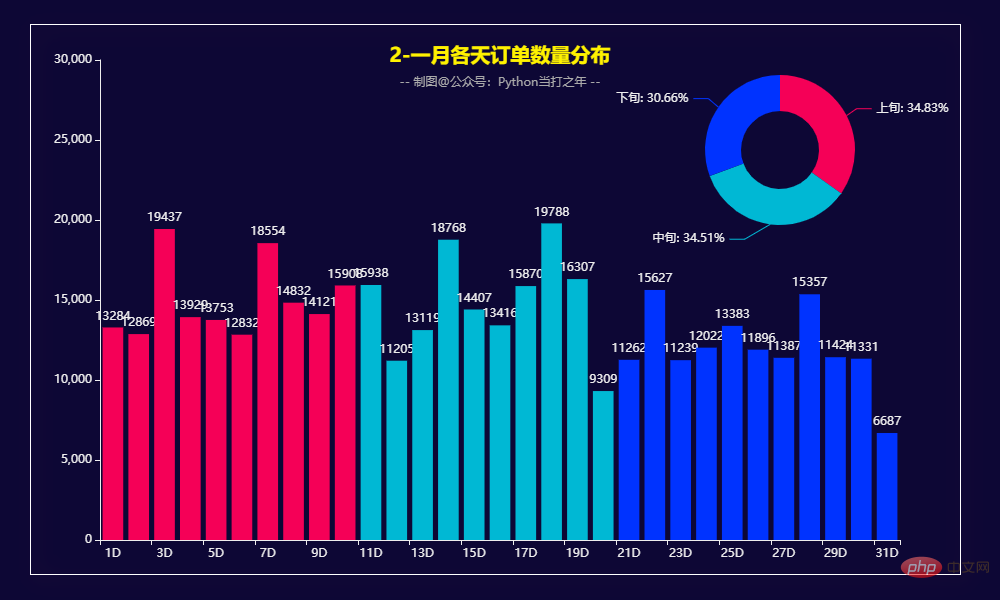
从每天的订单量上看,上中下旬订单量基本持平,占比都在30%以上,上旬和中旬要稍微高一点。
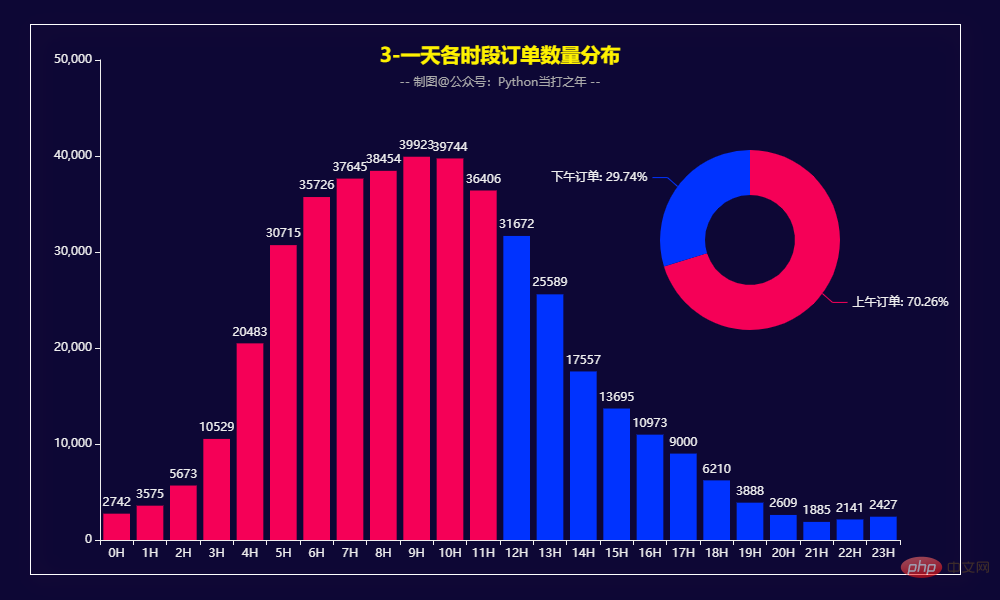
从订单时段上看,上午的订单要明显高于下午,占比达到了70.26%,尤其是在早上7:00-11:00之间。
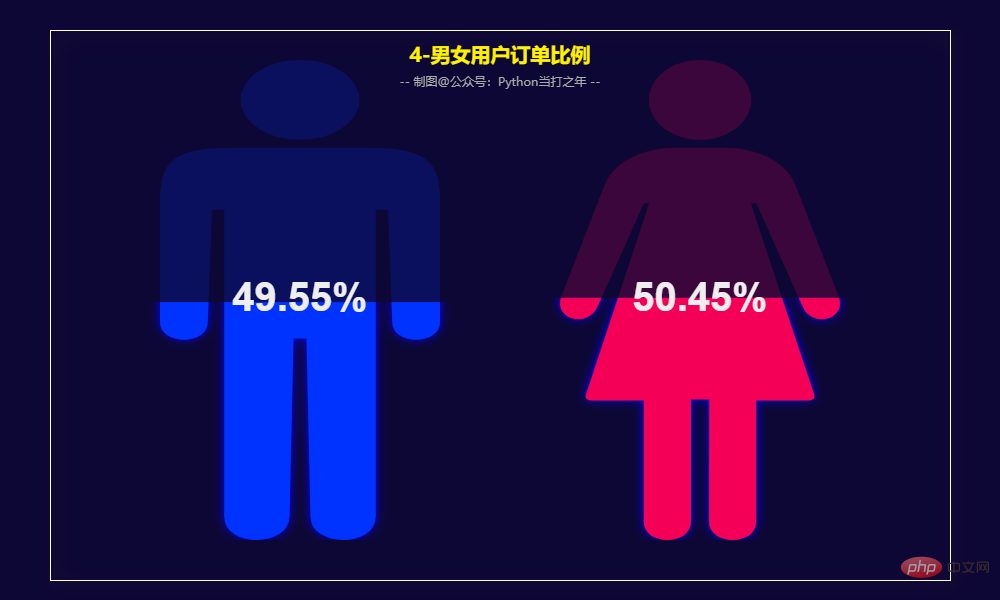
男性订单数量占比49.55%,女性订单数量占比50.45%,基本持平。
3.5 女性/男性购买商品TOP20
def get_bar3():
bar1 = (
Bar()
.add_xaxis(x_data1)
.add_yaxis('女性', y_data1,
label_opts=opts.LabelOpts(position='right')
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='5-女性/男性购买商品TOP20',
subtitle='-- 制图@公众号:Python当打之年 --',
pos_top='3%',
pos_left="center"),
legend_opts=opts.LegendOpts(pos_left='20%', pos_top='10%')
)
.reversal_axis()
)
bar2 = (
Bar()
.add_xaxis(x_data2)
.add_yaxis('男性', y_data2,
label_opts=opts.LabelOpts(position='right')
)
.set_global_opts(
legend_opts=opts.LegendOpts(pos_right='25%', pos_top='10%')
)
.reversal_axis()
)
grid1 = (
Grid()
.add(bar1, grid_opts=opts.GridOpts(pos_left='12%', pos_right='50%', pos_top='15%'))
.add(bar2, grid_opts=opts.GridOpts(pos_left='60%', pos_right='5%', pos_top='15%'))
)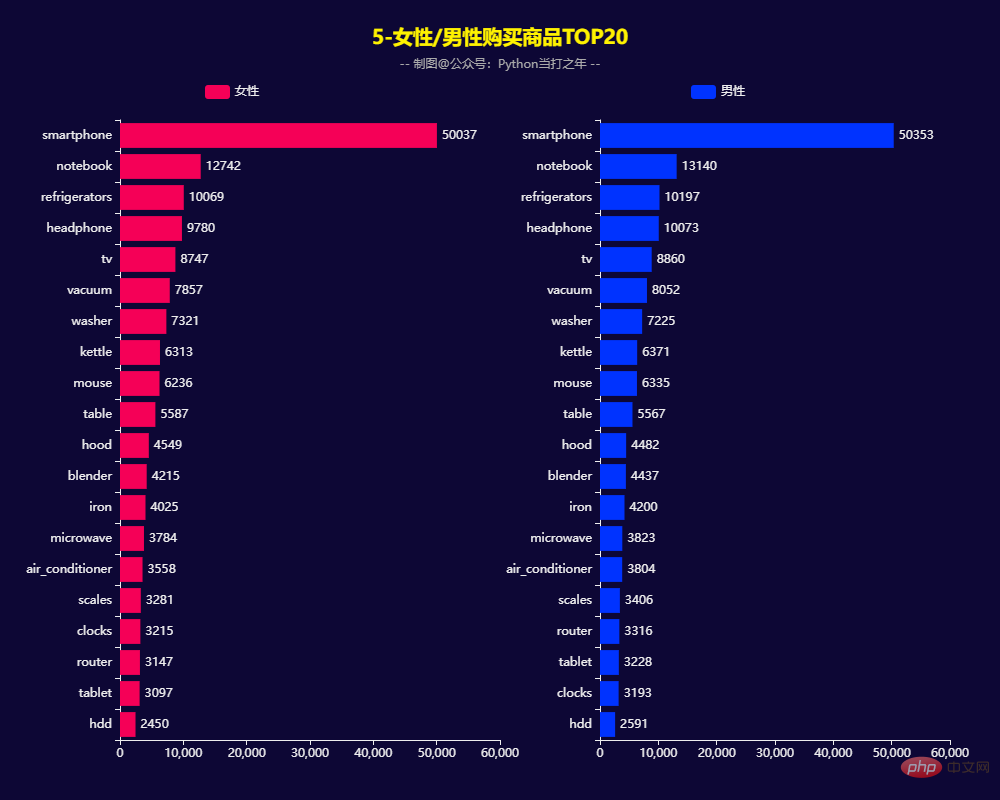
男性女性购买商品TOP20基本一致:smartphone、notebook、refrigerators、headphone等四类商品购买量比较大。
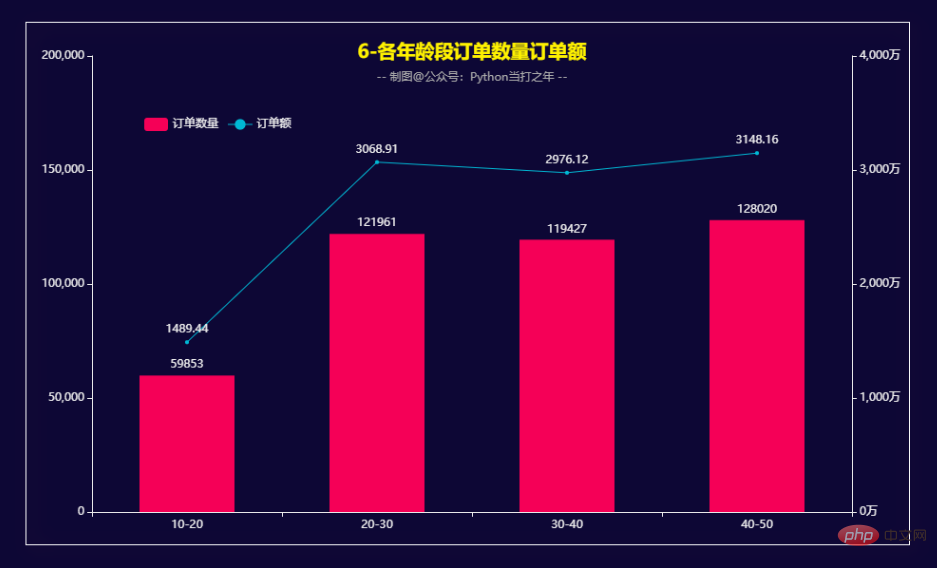
在10-50年龄段内,随着年龄段的增加,订单量和订单金额也在逐步增大。 细分的话,20-30和40-50这两个年龄段稍高一些。
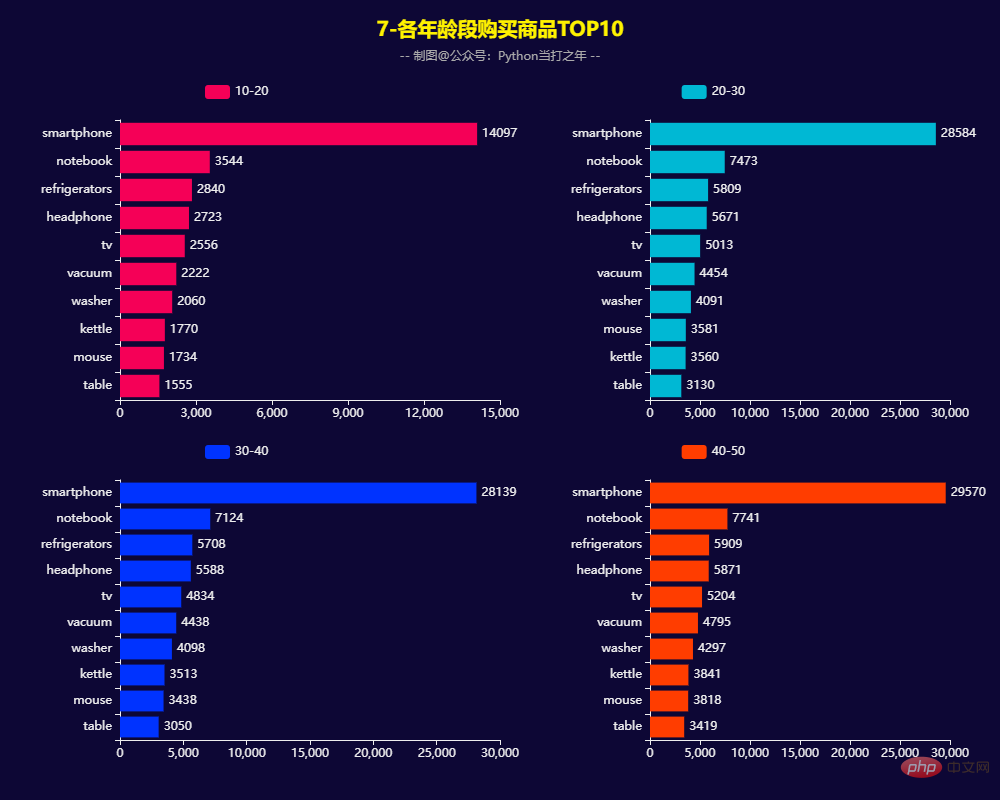
3.7 各年龄段购买商品TOP10
3.8 用户RFM等级画像
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。该模型通过一个客户的近期购买行为(R)、购买的总体频率(F)以及花了多少钱(M)三项指标来描述该客户的价值状况,从而能够更加准确地将成本和精力更精确的花在用户层次身上,实现针对性的营销。
用户分类:
def rfm_func(x):
level = x.apply(lambda x:"1" if x > 0 else '0')
RMF = level.R + level.F + level.M
dic_rfm ={
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要发展客户',
'001':'重要挽留客户',
'110':'一般价值客户',
'100':'一般发展客户',
'010':'一般保持客户',
'000':'一般挽留客户'
}
result = dic_rfm[RMF]
return result计算等级:
df_rfm = df1.copy()
df_rfm = df_rfm[['user_id','event_time','price']]
# 时间以当年年底为准
df_rfm['days'] = (pd.to_datetime("2020-12-31")-df_rfm["event_time"]).dt.days
# 计算等级
df_rfm = pd.pivot_table(df_rfm,index="user_id",
values=["user_id","days","price"],
aggfunc={"user_id":"count","days":"min","price":"sum"})
df_rfm = df_rfm[["days","user_id","price"]]
df_rfm.columns = ["R","F","M"]
df_rfm['RMF'] = df_rfm[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
df_rfm.head()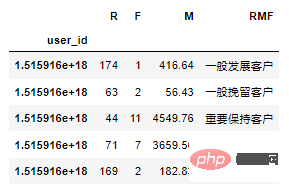
用户画像:
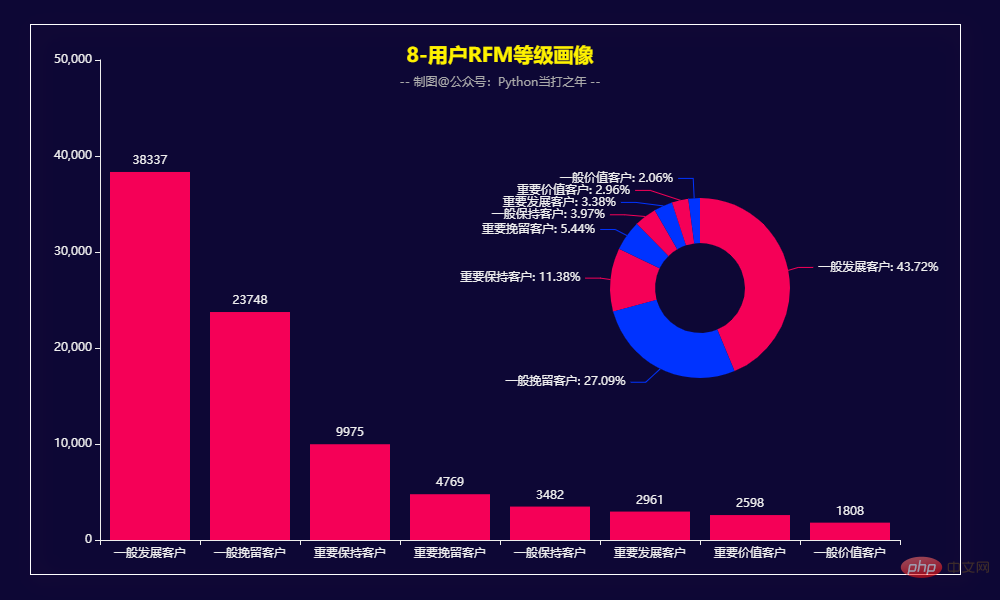
根据RFM模型可将用户分为以下8类:
重要价值客户:最近消费时间近、消费频次和消费金额都很高。 重要保持客户:最近消费时间较远,消费金额和频次都很高。
重要发展客户:最近消费时间较近、消费金额高,但频次不高、忠诚度不高,很有潜力的用户,必须重点发展。
重要挽留客户:最近消费时间较远、消费频次不高,但消费金额高的用户,可能是将要流失或者己经要流失的用户,应当给予挽留措施。
一般价值客户:最近消费时间近,频率高但消费金额低.需要提高其客单价。
一般发展客户:最近消费时间较近,消费金额、频次都不高。
一般保持客户:最近消费时间较远,消费频次高,消费金额不高。
一般挽留客户:各项指数都不高,可以适当放弃。
以上是Pandas+Pyecharts | 电子产品销售数据分析可视化+用户RFM画像的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 解决常见的pandas安装问题:安装错误的解读和解决方法
Feb 19, 2024 am 09:19 AM
解决常见的pandas安装问题:安装错误的解读和解决方法
Feb 19, 2024 am 09:19 AM
pandas安装教程:解析常见安装错误及其解决方法,需要具体代码示例引言:Pandas是一个强大的数据分析工具,广泛应用于数据清洗、数据处理和数据可视化等方面,因此在数据科学领域备受推崇。然而,由于环境配置和依赖问题,安装pandas可能会遇到一些困难和错误。本文将为大家提供一份pandas安装教程,并解析一些常见的安装错误及其解决方法。一、安装pandas
 如何使用pandas正确读取txt文件
Jan 19, 2024 am 08:39 AM
如何使用pandas正确读取txt文件
Jan 19, 2024 am 08:39 AM
如何使用pandas正确读取txt文件,需要具体代码示例Pandas是一个广泛使用的Python数据分析库,它可以用于处理各种各样的数据类型,包括CSV文件、Excel文件、SQL数据库等。同时,它也可以用于读取文本文件,例如txt文件。但是,在读取txt文件时,我们有时会遇到一些问题,例如编码问题、分隔符问题等。本文将介绍如何使用pandas正确读取txt
 使用pandas读取CSV文件并进行数据分析
Jan 09, 2024 am 09:26 AM
使用pandas读取CSV文件并进行数据分析
Jan 09, 2024 am 09:26 AM
Pandas是一个强大的数据分析工具,可以方便地读取和处理各种类型的数据文件。其中,CSV文件是最常见和常用的数据文件格式之一。本文将介绍如何使用Pandas读取CSV文件并进行数据分析,同时提供具体的代码示例。一、导入必要的库首先,我们需要导入Pandas库和其他可能需要的相关库,如下所示:importpandasaspd二、读取CSV文件使用Pan
 python pandas安装方法
Nov 22, 2023 pm 02:33 PM
python pandas安装方法
Nov 22, 2023 pm 02:33 PM
python可以通过使用pip、使用conda、从源代码、使用IDE集成的包管理工具来安装pandas。详细介绍:1、使用pip,在终端或命令提示符中运行pip install pandas命令即可安装pandas;2、使用conda,在终端或命令提示符中运行conda install pandas命令即可安装pandas;3、从源代码安装等等。
 Pandas轻松读取SQL数据库中的数据
Jan 09, 2024 pm 10:45 PM
Pandas轻松读取SQL数据库中的数据
Jan 09, 2024 pm 10:45 PM
数据处理利器:Pandas读取SQL数据库中的数据,需要具体代码示例随着数据量的不断增长和复杂性的提高,数据处理成为了现代社会中一个重要的环节。在数据处理过程中,Pandas成为了许多数据分析师和科学家们的首选工具之一。本文将介绍如何使用Pandas库来读取SQL数据库中的数据,并提供一些具体的代码示例。Pandas是基于Python的一个强大的数据处理和分
 python如何安装pandas
Dec 04, 2023 pm 02:48 PM
python如何安装pandas
Dec 04, 2023 pm 02:48 PM
python安装pandas的步骤:1、打开终端或命令提示符;2、输入“pip install pandas”命令安装pandas库;3、等待安装完成,可以在Python脚本中导入并使用pandas库了;4、使用的是特定的虚拟环境,确保在安装pandas之前激活相应的虚拟环境;5、使用的是集成开发环境,可以添加“import pandas as pd”代码来导入pandas库。
 使用pandas读取txt文件的实用技巧
Jan 19, 2024 am 09:49 AM
使用pandas读取txt文件的实用技巧
Jan 19, 2024 am 09:49 AM
使用pandas读取txt文件的实用技巧,需要具体代码示例在数据分析和数据处理中,txt文件是一种常见的数据格式。使用pandas读取txt文件可以快速、方便地进行数据处理。本文将介绍几种实用的技巧,以帮助你更好的使用pandas读取txt文件,并配以具体的代码示例。读取带有分隔符的txt文件使用pandas读取带有分隔符的txt文件时,可以使用read_c
 揭秘Pandas中高效的数据去重方法:快速去除重复数据的技巧
Jan 24, 2024 am 08:12 AM
揭秘Pandas中高效的数据去重方法:快速去除重复数据的技巧
Jan 24, 2024 am 08:12 AM
Pandas去重方法大揭秘:快速、高效的数据去重方式,需要具体代码示例在数据分析和处理过程中,经常会遇到数据中存在重复的情况。重复数据可能会对分析结果产生误导,因此去重是一个非常重要的工作环节。在Pandas这个强大的数据处理库中,提供了多种方法来实现数据去重,本文将介绍一些常用的去重方法,并附上具体的代码示例。基于单列去重最常见的情况是根据某一列的值是否重
