

爬虫|Python爬取B站小姐姐图片,学习的动力!

直接打开B站(bilibili)搜索 '小姐姐':
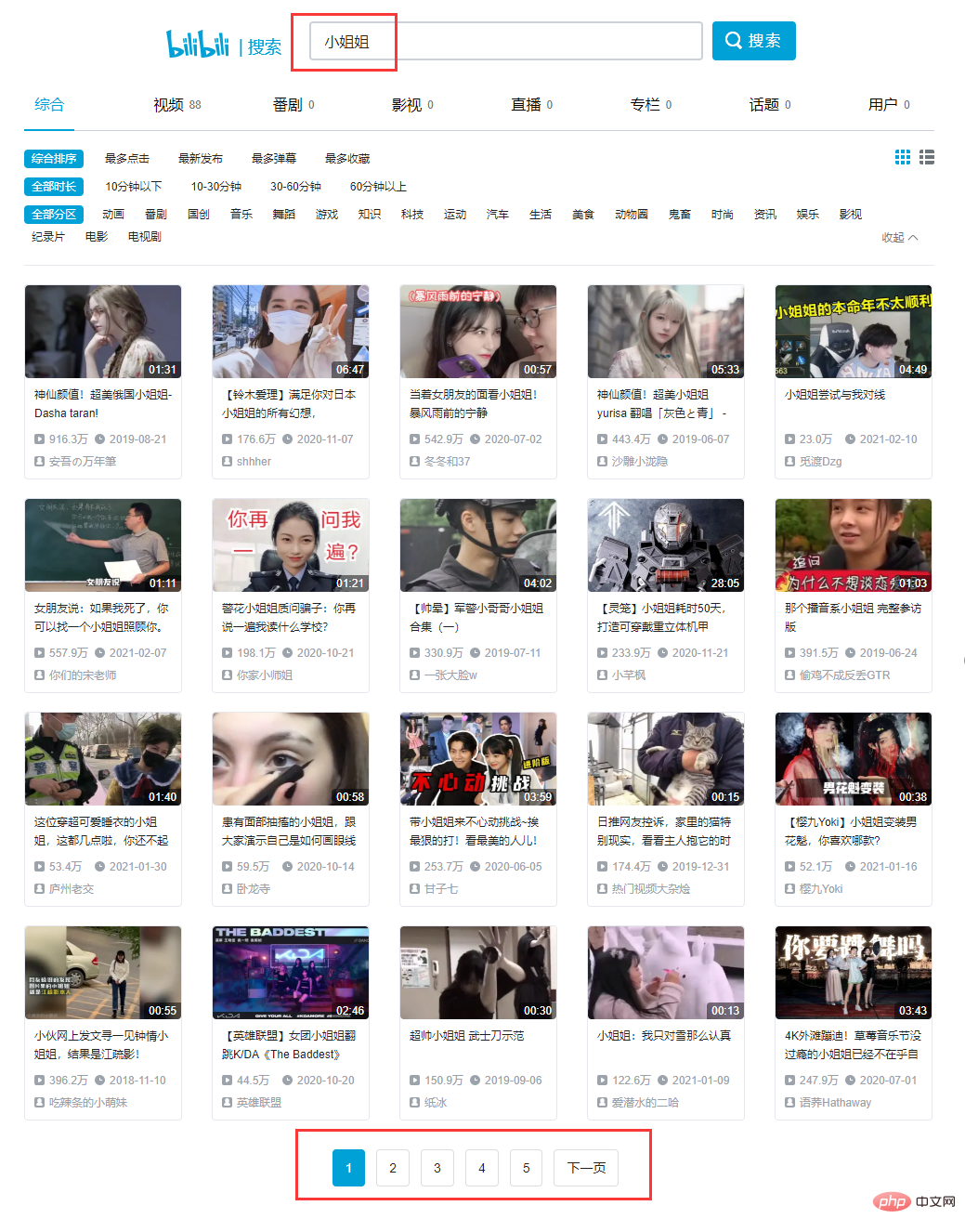
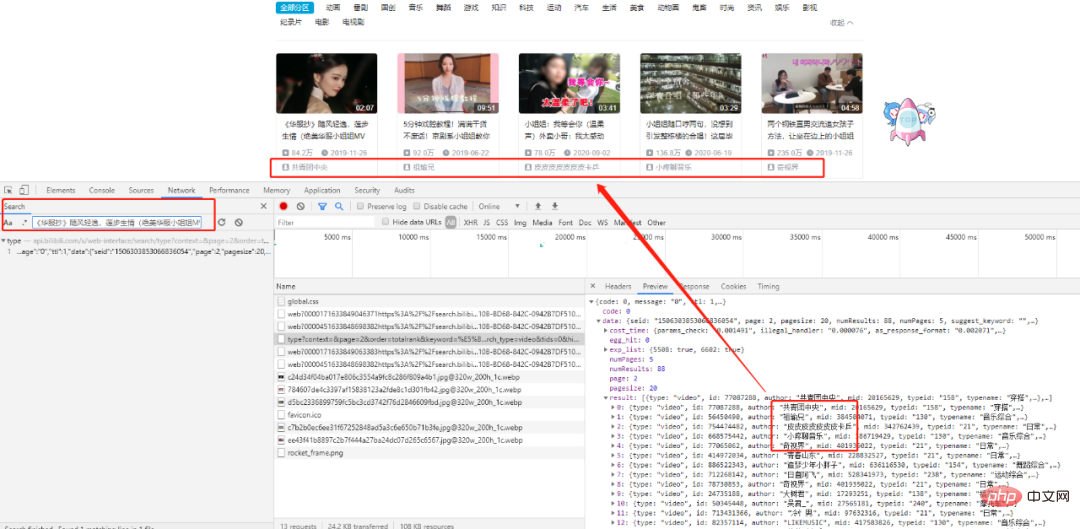
搜索第一个title,我们可以找到相应的XHR请求,仔细分析一下发现所有的数据都存在于一个json格式的数据集里,我们的目标就在result列表中。
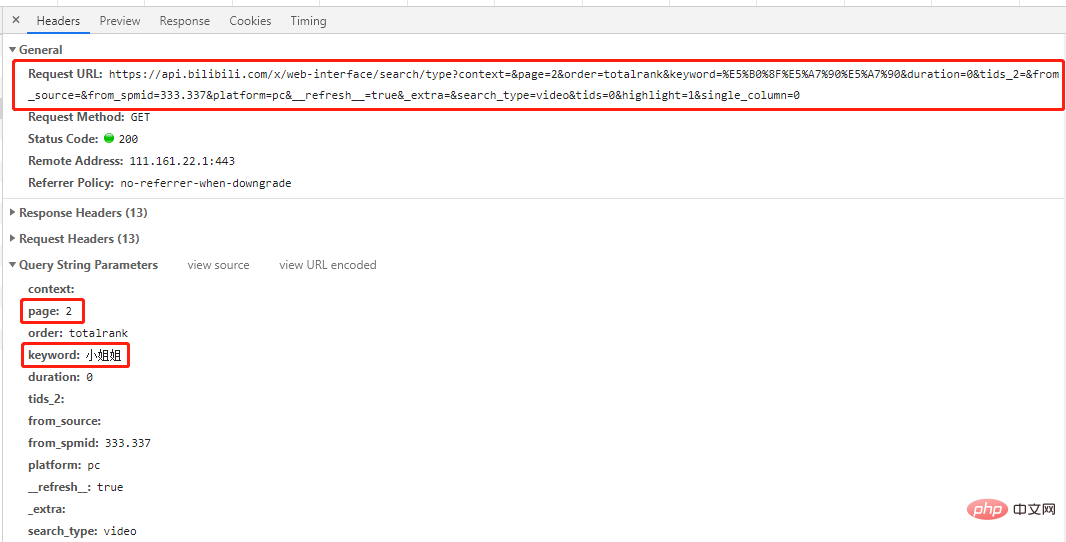
这是一个get请求,请求参赛数中有page和keyword两个参赛,分别对应请求的页码和关键字。
多查看几页找一下规律:
# 第一页 'https://api.bilibili.com/x/web-interface/search/all/v2?context=&page=1&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&tids=0&highlight=1&single_column=0' # 第二页 'https://api.bilibili.com/x/web-interface/search/type?context=&page=2&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0' # 第三页 'https://api.bilibili.com/x/web-interface/search/type?context=&page=3&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0'
可以看到除了第1页不一样外,其他几页url中只有page参数不一样,那么我们尝试一下第1页也用其他页的url请求一下,结果会发现同样可以出来想要的结果(自己试试)。
结论:所有页url只有page参数不一样,其他均一致。
# 导包 import re import time import json import random import requests from fake_useragent import UserAgent
2.2 获取页面信息
# 获取页面信息
def get_datas(url,headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = chardet.detect(r.content)['encoding']
datas = json.loads(r.text)
return datas# 获取图片链接信息
def get_hrefs(datas):
titles,hrefs = [],[]
for data in datas['data']['result']:
# 标题
title = data['title']
# 时长
duration = data['duration']
# 播放量
video_review =data['video_review']
# 发布时间
date_rls = data['pubdate']
pubdate = time.strftime('%Y-%m-%d %H:%M', time.localtime(date_rls))
# 作者
author = data['author']
# 图片链接
link_pic = data['pic']
href_pic = 'https:' + link_pic
titles.append(title)
hrefs.append(href_pic)
return titles, hrefs代码解析了视频标题,时长,播放量,发布时间,作者,图片链接等参数,这里我们只取标题和图片链接,其他参数可根据需要自行增,删。
# 保存图片
def download_jpg(titles, hrefs):
path = "D:/B站小姐姐/"
if not os.path.exists(path):
os.mkdir(path)
for i in range(len(hrefs)):
title_t = titles[i].replace('/','').replace(',','').replace('?','')
title_t = title_t.replace(' ','').replace('|','').replace('。','')
filename = '{}{}.jpg'.format(path,title_t)
with open(filename, 'wb') as f:
req = requests.get(url=hrefs[i], headers=headers)
f.write(req.content)
time.sleep(random.uniform(1.5,3.4))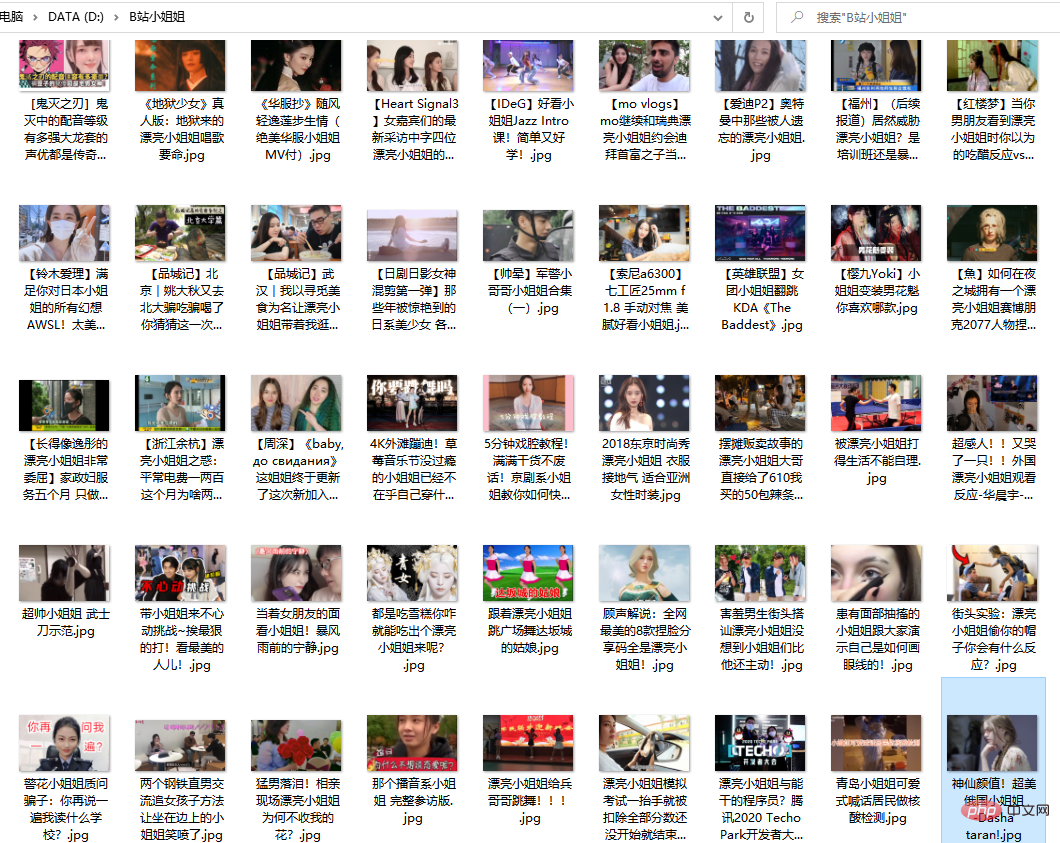
以上是爬虫|Python爬取B站小姐姐图片,学习的动力!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 XML如何修改注释内容
Apr 02, 2025 pm 06:15 PM
XML如何修改注释内容
Apr 02, 2025 pm 06:15 PM
对于小型XML文件,可直接用文本编辑器替换注释内容;对于大型文件,建议借助XML解析器进行修改,确保效率和准确性。删除XML注释时需谨慎,保留注释通常有助于代码理解和维护。进阶技巧中提供了使用XML解析器修改注释的Python示例代码,但具体实现需根据使用的XML库进行调整。修改XML文件时注意编码问题,建议使用UTF-8编码并指定编码格式。
 XML修改内容需要编程吗
Apr 02, 2025 pm 06:51 PM
XML修改内容需要编程吗
Apr 02, 2025 pm 06:51 PM
修改XML内容需要编程,因为它需要精准找到目标节点才能增删改查。编程语言有相应库来处理XML,提供API像操作数据库一样进行安全、高效、可控的操作。
 手机XML转PDF,转换速度快吗?
Apr 02, 2025 pm 10:09 PM
手机XML转PDF,转换速度快吗?
Apr 02, 2025 pm 10:09 PM
手机XML转PDF的速度取决于以下因素:XML结构的复杂性手机硬件配置转换方法(库、算法)代码质量优化手段(选择高效库、优化算法、缓存数据、利用多线程)总体而言,没有绝对的答案,需要根据具体情况进行优化。
 有什么手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 08:54 PM
有什么手机APP可以将XML转换成PDF?
Apr 02, 2025 pm 08:54 PM
无法找到一款将 XML 直接转换为 PDF 的应用程序,因为它们是两种根本不同的格式。XML 用于存储数据,而 PDF 用于显示文档。要完成转换,可以使用编程语言和库,例如 Python 和 ReportLab,来解析 XML 数据并生成 PDF 文档。
 xml格式怎么打开
Apr 02, 2025 pm 09:00 PM
xml格式怎么打开
Apr 02, 2025 pm 09:00 PM
用大多数文本编辑器即可打开XML文件;若需更直观的树状展示,可使用 XML 编辑器,如 Oxygen XML Editor 或 XMLSpy;在程序中处理 XML 数据则需使用编程语言(如 Python)与 XML 库(如 xml.etree.ElementTree)来解析。
 如何在protobuf中定义枚举类型并关联字符串常量?
Apr 02, 2025 pm 03:36 PM
如何在protobuf中定义枚举类型并关联字符串常量?
Apr 02, 2025 pm 03:36 PM
在protobuf中定义字符串常量枚举的问题在使用protobuf时,常常会遇到需要将枚举类型与字符串常量进行关联的情�...
 XML转换成图片的流程是什么?
Apr 02, 2025 pm 08:24 PM
XML转换成图片的流程是什么?
Apr 02, 2025 pm 08:24 PM
XML 转换图片需要先确定 XML 数据结构,再选择合适的图形化库(如 Python 的 matplotlib)和方法,根据数据结构选择可视化策略,考虑数据量和图片格式,进行分批处理或使用高效库,最终根据需求保存为 PNG、JPEG 或 SVG 等格式。
 如何在手机上高质量地将XML转换成PDF?
Apr 02, 2025 pm 09:48 PM
如何在手机上高质量地将XML转换成PDF?
Apr 02, 2025 pm 09:48 PM
在手机上高质量地将XML转换成PDF需要:使用无服务器计算平台在云端解析XML并生成PDF。选择高效的XML解析器和PDF生成库。正确处理错误。充分利用云端计算能力,避免在手机上进行繁重任务。根据需求调整复杂度,包括处理复杂的XML结构、生成多页PDF和添加图片。打印日志信息以帮助调试。优化性能,选择高效的解析器和PDF库,并可能使用异步编程或预处理XML数据。确保良好的代码质量和可维护性。
