不管是工作中,还是面试中,关于mysql的explain执行计划以及索引优化,都是非常值得关注的。
一,案例
二,explain 执行计划
三,索引遵循规则(失效问题)
四,不走索引常见类型
五,常见 sql 优化
六,字段数据类型讲解
七,总结
1,建表
CREATE TABLE `employees` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名', `age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄', `position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位', `hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间', PRIMARY KEY (`id`), KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE ) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
2,增加索引
#增加普通索引 ALTER TABLE `employees` ADD INDEX `idx_hire_time` (`hire_time`) USING BTREE #增加联合索引(这里只是写一下索引的增加和删除方式) alter table employees add index idx_n_a(name,age);
3,查看表中的全部索引信息,以下两种方式都可以
show index from employees; show KEYS from employees;
4,删除索引
drop index idx_n_a on employees
5,插入数据
INSERT INTO employees(name,age,position,hire_time) VALUES('LiLei',22,'manager',NOW()); INSERT INTO employees(name,age,position,hire_time) VALUES('HanMeimei', 23,'dev',NOW()); INSERT INTO employees(name,age,position,hire_time) VALUES('Lucy',23,'dev',NOW());
6,再插入 10w 条数据
drop procedure if exists insert_emp; delimiter ;; create procedure insert_emp() begin declare i int; set i=1; while(i<=100000)do insert into employees(name,age,position) values(CONCAT('zhenghuisheng',i),i,'dev'); set i=i+1; end while; end;; delimiter ; call insert_emp();
再次之前可以先去了解一下 b + 树的数据结构,再根据 b + 树来了解索引底层。
EXPLAIN select * from employees where date(hire_time) ='2022-05-03 11:01:17';
 使用 explain 关键字可以模拟优化器质性 sql 查询语句,从而知道 mysql 是如何处理 sql 语句的。explain + sql 语句,来查看执行计划的包含信息,接下来对这些参数进行初步讲解。
使用 explain 关键字可以模拟优化器质性 sql 查询语句,从而知道 mysql 是如何处理 sql 语句的。explain + sql 语句,来查看执行计划的包含信息,接下来对这些参数进行初步讲解。
id 的序列号表示 select 执行的顺序,如一个 sql 中有子查询这种,则通过 id 表示哪个 select 优先执行。当 id 相同时,顺序是由上到下,id 不同时,如果是子查询,id 的序号会递增,id 值越大,优先级越高,越先执行。看以下执行结果。
EXPLAIN select * from employees e inner join (select id from employees order by name limit 90000,5) ed on e.id = ed.id;

用于区分查询类型,是简单查询还是复杂查询 simple:简单查询,不包含子查询或者 union,如一条简单查询 primary:复杂查询的最外层标记,即最外层 select。如有子查询 subquery:包含在 select 中的子查询(不在 from 子句中) derived:临时表如上面那个 ed 表就是一个临时表 union:排重 union result:结果合并
这一列表示关联类型或者访问类型,即 MySQL 决定如何查找表中的行,查找数据行记录的大概范围 最好到最差:system > const > eq_ref > ref > range > index > all System:表中只有一行匹配的数据 (实际开发中不会出现),属于 const 里面的一种特例 const:表示通过索引一次找到,如主键索引和唯一索引 eq_ref:唯一索引扫描,表中只有一条记录与之匹配,如表连接查询时关联表的主键索引或者唯一索引,如上面图中的 id=2 的类型,即使用主键 id 进行 join 连接查询 ref:非唯一索引扫描,即使用的普通索引,可以找到多个符合条件的行 (实际开发中的最好达到这个要求)
#name字段加了索引 select * from employees where name = 'zhenghuisheng11'
range:范围。只检索给定范围的行,如 in(), between ,> ,<, >= 如果范围太大的话也会降低效率 (实际开发中的最低要求) index:全索引扫描,一般指的是二级索引扫描,直接走叶子节点遍历扫描,一般为覆盖索引,效率较慢,但是叶子结点数据较小,所以效率依旧比 all 快 all:全表遍历,一般指的是聚簇索引,如主键索引。一级索引在叶子结点里面存储的是对应的 value,而二级索引叶子结点里面存储的只是指向对应 value 的指针,即地址,所以一级索引的也结点相对较大,查询速率先对较慢。所以一般在主键索引和覆盖索引里面,会优先选择走覆盖索引。
这一列显示查询可能使用了哪些索引。explain 时可能出现 possible_keys 有列,而 key 显示 NULL 的情况,这种情况是因为表中数据不多,mysql 认为索引对此查询帮助不大,选择了全表查询。如果该列是 NULL,则没有相关的索引。在这种情况下,可以通过检查 where 子句看是否可以创造一个适当的索引来提高查询性能,然后用 explain 查看效果。
这一列显示该语句具体使用了那个索引,如果出现 null 不走索引,也可以使用 force index 强制走索引,但是效率不高
索引使用的字节数,越短越好
显示索引的哪一列被使用了,如果可能的话,是一个常数。那些列或常量被用于查找索引列上的值
根据表统计信息及索引选用情况,大致估算找到所需记录所需要读取的行数
常见的有 Using index 和 Using filesort「Using index」:使用覆盖索引,如果 select 后面查询的字段都可以从这个索引的树中获取,这种情况一般可以说是用到了覆盖索引,extra 里一般都有 using index,如果出现回表的情况,如在查询字段中有一个字段没有加索引或者出现索引失效的问题,导致 sql 回表走了全表扫描,就可以使用覆盖索引进行优化;覆盖索引一般针对的是辅助索引,整个查询结果只通过辅助索引就能拿到结果,不需要通过辅助索引树找到主键,再通过主键去主键索引树里获取其它字段值「Using filesort」:将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序
根据该表的联合索引,来考虑以下的事情
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age = 22 AND position ='manager';
 为简单查询,type 类型为 ref,key 为具体使用了哪个索引,即这个联合索引被使用了,长度 140,三个字段都使用到了索引,通过 ref 也可以发现三个字段都是使用 const,即为一个常量
为简单查询,type 类型为 ref,key 为具体使用了哪个索引,即这个联合索引被使用了,长度 140,三个字段都使用到了索引,通过 ref 也可以发现三个字段都是使用 const,即为一个常量
在联合索引中,需要从左往前依次使用索引,才能生效。即 a_b_c 这个索引,需要使用了 a,b 才能使用 c,即中间不能断,如果没有使用 b 的话那么 c 这个索引会失效。这个可以从 b + 树的底层了解。可以参考之前写的一篇博客
Mysql为何使用B+树?
如下图为一棵联合索引的索引树,每个节点相当于由三个字段组成,会根据字段顺序进行先后排序。以叶子节点为例,该叶子节点的排序会根据第一个字段进行比较,如果第一个字段一样,则开始比较第二个字段,以此类推;如果第一个字段不一样,则会根据 「ASCII」 码进行比较,如 a 在 b 前面,依次比较;如果所有字段都一样,那可以确定是一个二级索引,因为主键索引不可能一样,二级索引的话可以再根据主键 id 再进行比较。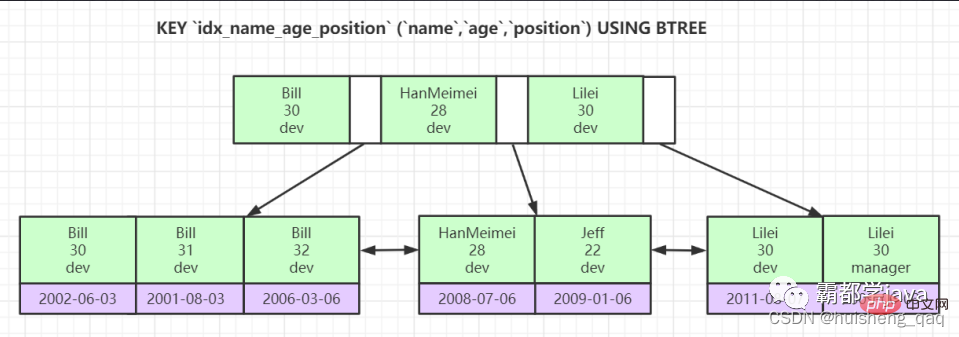 也就是说,b + 树底层已经帮我们排好序了,如果直接没有使用第一个字段 name,直接使用第二个字段 age 的话,那么可以发现叶子节点上的第二行 age 字段是并没有排序好的,就会导致重新走全表扫描,导致改索引失效。这就是最左前缀原则。当然如果中间索引没用的话,也会导致后面的索引失效,如直接使用 name 字段和 position 字段,没用用 age 字段,那么 position 字段也会失效。根据 key_len 和 ref 可知只使用了 name 一个索引字段,name 字段长度为 24,所以 24x3+2 = 74。
也就是说,b + 树底层已经帮我们排好序了,如果直接没有使用第一个字段 name,直接使用第二个字段 age 的话,那么可以发现叶子节点上的第二行 age 字段是并没有排序好的,就会导致重新走全表扫描,导致改索引失效。这就是最左前缀原则。当然如果中间索引没用的话,也会导致后面的索引失效,如直接使用 name 字段和 position 字段,没用用 age 字段,那么 position 字段也会失效。根据 key_len 和 ref 可知只使用了 name 一个索引字段,name 字段长度为 24,所以 24x3+2 = 74。
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND position ='manager';

如果在索引列上进行计算、函数、(自动 or 手动)类型转换,那么可能出现导致索引失效。1,如在 hire_time 字段使用日期函数,可能不走索引,但是使用范围查询,就可能会走索引
EXPLAIN select * from employees where date(hire_time) ='2022-05-03 12:58:17';

EXPLAIN select * from employees where hire_time BETWEEN '2022-05-01 18:26:05' and '2022‐05‐04 00:00:00';

EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND age > 22 AND position ='manager';

即减少使用 **select ** _的使用,将_改成具体的字段,防止有查到没有索引或者不在索引树的字段,导致为了查这个字段回表。回表就是说又需要通过 id 再次进行全表扫描,找出对应的那个字段的值。
EXPLAIN SELECT name,age,position FROM employees WHERE name= 'LiLei' AND age = 23 AND position ='manager';
EXPLAIN SELECT * FROM employees WHERE name != 'zhenghuisheng111'

mysql 底层会把那些为空的字段全部放在一个连续的空间,因此在查询 is null 的时候,会直接去拿那几个值,不需要通过走索引。
1,like 在使用通配符的情况下,% 在前面不走索引 即 liek %xx
EXPLAIN SELECT * FROM employees WHERE name like '%zhenghuisheng11'
 2,like 在有字符串作为前缀的时候会走索引 like xx%。这个依旧是想想 b + 树的底层就知道了,和最左前缀匹配原则一致
2,like 在有字符串作为前缀的时候会走索引 like xx%。这个依旧是想想 b + 树的底层就知道了,和最左前缀匹配原则一致
EXPLAIN SELECT * FROM employees WHERE name like 'zhenghuisheng11%'
 3,使用覆盖索引,查询字段必须是建立覆盖索引字段,来查询 %xx%
3,使用覆盖索引,查询字段必须是建立覆盖索引字段,来查询 %xx%
EXPLAIN SELECT name,age,position FROM employees WHERE name like '%zhenghuisheng%';

字符串不加单引号会造成作用失效,会走全表扫描。如果是一个 1000,那么 mysql 会自动将这个字符串转化为整型,和第三点一样,在索引列上进行了操作,导致索引失效,走了全表扫描
1,联合索引第一个字段使用范围,不走索引,因为 mysql 内部可能觉得第一个字段就用范围,结果集应该很大,回表效率不高,还不如就全表扫描。也可以添加 force index 来强制走索引,但是一般效率不高。
EXPLAIN SELECT * FROM employees WHERE name > 'zhenghuisheng01' AND age = 22 AND position ='manager'; #强制走索引 EXPLAIN SELECT * FROM employees force index(idx_name_age_position) WHERE name > 'zhenghuisheng01' AND age = 22 AND position ='manager';
2,一般在 select * 不走索引时,可以通过覆盖索引来实现走索引,即使用具体的字段来查询
EXPLAIN SELECT name,age,position FROM employees WHERE name > 'zhenghuisheng01' AND age = 22 AND position ='manager';
 3,in 和 or 在表数据量比较大的情况会走索引,在表记录不多的情况下会选择全表扫描
4,like KK% 一般情况都会走索引
3,in 和 or 在表数据量比较大的情况会走索引,在表记录不多的情况下会选择全表扫描
4,like KK% 一般情况都会走索引
根据最左前缀原则,中间字段不能断,所以只走了 name 索引字段。优化方式和常见的优化差不多
EXPLAIN SELECT * FROM employees WHERE name= 'LiLei' AND position ='dev'order by age;
select * from employees limit 10000,10;
实际这条 SQL 是先读取 10010 条记录,然后抛弃前 10000 条记录,然后读到后面 10 条想要的数据,因此越到后面效率越低,因此有以下几种优化方式「方式一」根据自增且连续的主键排序的分页查询
select * from employees where id > 90000 limit 5; #前提条件是数据id必须连续且自增,如果中间数据删除了几条,则不适应此优化方式 #该语句走了索引,并且扫描的行数大大降低
「方式二」
select * from employees ORDER BY name limit 90000,5; #根据非主键字段排序的分页查询,name为联合索引第一个,该方式用到了文件排序 #但是由于并没有走索引,并且扫描了全部的行,走了全表扫描,效率更低
「方式三 (推荐)」
select * from employees e inner join (select id from employees order by name limit 90000,5) ed on e.id = ed.id; #通过内连接查询,首先内连接查出全部id,会走name字段索引,再通过id进行联表查五个值即可

表关联主要有两种常见的算法 嵌套循环连接 Nested-Loop Join(NLJ) 算法 基于块的嵌套循环连接 Block Nested-Loop Join(BNL) 算法 接下来来一个示例,创建两张表,一张表插入 100 条数据,一张表插入 10000 条数据。如下
CREATE TABLE `t1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
#保证两表的结构一样
create table t2 like t1;
-- 插入一些示例数据
-- 往t1表插入1万行记录
drop procedure if exists insert_t1;
delimiter ;;
create procedure insert_t1()
begin
declare i int;
set i=1;
while(i<=10000)do
insert into t1(a,b) values(i,i);
set i=i+1;
end while;
end;;
delimiter ;
call insert_t1();
-- 往t2表插入100行记录
drop procedure if exists insert_t2;
delimiter ;;
create procedure insert_t2()
begin
declare i int;
set i=1;
while(i<=100)do
insert into t2(a,b) values(i,i);
set i=i+1;
end while;
end;;
delimiter ;
call insert_t2();「1、 嵌套循环连接 Nested-Loop Join(NLJ) 算法」这里主要针对建了索引的字段
EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;
 优化器一般会优先选择小表做驱动表,用 where 条件过滤完驱动表,然后再跟被驱动表做关联查询。而且小表走的是全表扫描,大表是 ref ,并且走了索引,因此效率比较高。在该算法中,使用 left join 时,左表是驱动表,右表是被驱动表,当使用 right join 时,右表时驱动表,左表是被驱动表,当使用 join 时,mysql 会选择数据量比较小的表作为驱动表,大表作为被驱动表,一般驱动表会选择数据较小的表作为驱动表。因此在上面的算法中,mysql 的流程如下:先选择 t2 表作为驱动表,然后先从表中取一条数据 a,在和 t1 表中的数据进行比对,由于 t1 表直接走了索引,索引 t2 表取一次,t1 表也可以通过索引一次找到,并且返回给客户端。所以只需要比对 100+100 次就可以将数据找出,即两百次。「2,基于块的嵌套循环连接 Block Nested-Loop Join(BNL) 算法」这里主要针对在关联查询时没有建立索引的字段
优化器一般会优先选择小表做驱动表,用 where 条件过滤完驱动表,然后再跟被驱动表做关联查询。而且小表走的是全表扫描,大表是 ref ,并且走了索引,因此效率比较高。在该算法中,使用 left join 时,左表是驱动表,右表是被驱动表,当使用 right join 时,右表时驱动表,左表是被驱动表,当使用 join 时,mysql 会选择数据量比较小的表作为驱动表,大表作为被驱动表,一般驱动表会选择数据较小的表作为驱动表。因此在上面的算法中,mysql 的流程如下:先选择 t2 表作为驱动表,然后先从表中取一条数据 a,在和 t1 表中的数据进行比对,由于 t1 表直接走了索引,索引 t2 表取一次,t1 表也可以通过索引一次找到,并且返回给客户端。所以只需要比对 100+100 次就可以将数据找出,即两百次。「2,基于块的嵌套循环连接 Block Nested-Loop Join(BNL) 算法」这里主要针对在关联查询时没有建立索引的字段
EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;
 在该算法中,mysql 的流程如下:也会选择表中数据较少的表作为驱动器,即把 t2 的所有数据放入到 join_buffer 中,再把表 t1 中每一行取出来,跟 join_buffer 中的数据做对比,由于该字段没有建索引,所以该字段在 sql 中是无序的,所以需要对表 t1 和 t2 都做一次全表扫描,因此扫描的总行数为 10000(表 t1 的数据总量) + 100(表 t2 的数据总量) = 10100。并且 join_buffer 里的数据是无序的,因此对表 t1 中的每一行,都要做 100 次判断,所以内存中的判断次数是 100 * 10000= 100 万次。
在该算法中,mysql 的流程如下:也会选择表中数据较少的表作为驱动器,即把 t2 的所有数据放入到 join_buffer 中,再把表 t1 中每一行取出来,跟 join_buffer 中的数据做对比,由于该字段没有建索引,所以该字段在 sql 中是无序的,所以需要对表 t1 和 t2 都做一次全表扫描,因此扫描的总行数为 10000(表 t1 的数据总量) + 100(表 t2 的数据总量) = 10100。并且 join_buffer 里的数据是无序的,因此对表 t1 中的每一行,都要做 100 次判断,所以内存中的判断次数是 100 * 10000= 100 万次。
针对上诉的 join 联表描述,作一下总结「1,关联字段加索引」「2,小表驱动大表」「3,最多关联不要超过三张表」
原则:小表驱动大表,即小的数据集驱动大的数据集
select * from A where id in (select id from B) #in:当B表的数据集小于A表的数据集时,in优于exists
select * from A where exists (select 1 from B where B.id = A.id) #exists:当A表的数据集小于B表的数据集时,exists优于in
mysql> EXPLAIN select count(1) from employees; 1 mysql> EXPLAIN select count(id) from employees; 2 mysql> EXPLAIN select count(name) from employees; 3 mysql> EXPLAIN select count(*) from employees; 4
在经过测试之后,可以发现四个 sql 的执行计划一样,说明这四个 sql 执行效率应该差不多 1 和 4 效率差不多 > count(字段) > count(主键 id),因为二级索引比主键索引小,数据比主键索引少,所以 count(字段) > count(主键 id)。如果 name 没有索引,则 id > 字段
这里主要讲解字段数据类型和 key_len 的关系,基本常用的如下 字符串
一个数字 或字母占1个字节,一个汉字占3个字节 char(n):如果存汉字长度就是 3n 字节 varchar(n):如果存汉字则长度是 3n + 2 字节,加的2字节用来存储字符串长度,因为 varchar是变长字符串
数值类型
tinyint:1字节 smallint:2字节 int:4字节 bigint:8字节
时间类型
date:3字节 timestamp:4字节 datetime:8字节
而索引列数据类型本身占用空间 + 额外空间,所以像上面的 name 字段走索引,他的 key_len 长度就为 24 x 3 + 2 = 74。所以在设计表的时候就不要直接写 255 长度了。最好根据实际大小填写。最后解释一下这个 int(n),这个 n 不是代表实际的长度,而是代表可见的长度。
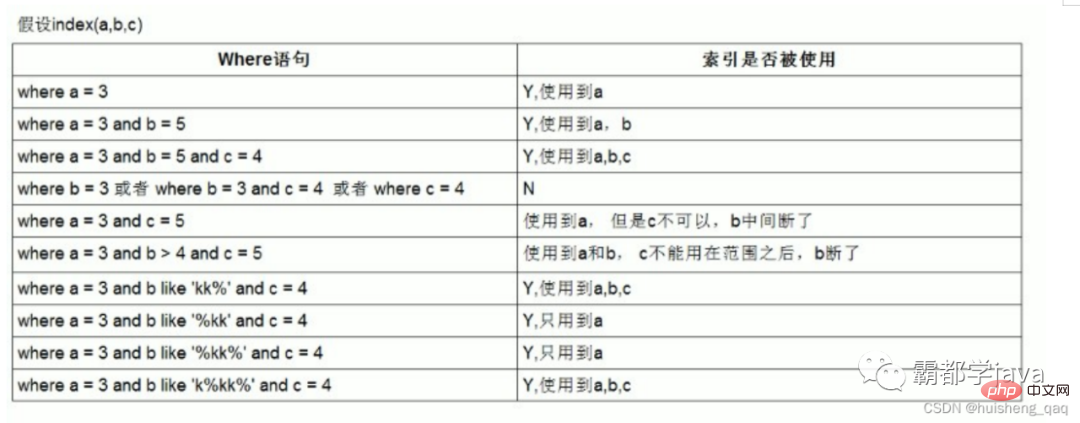
接下来以一个是否走索引的图表来总结
以上是最详细的 MySQL 执行计划和索引优化!的详细内容。更多信息请关注PHP中文网其他相关文章!





















