

深入探讨GET3D生成模型的五分钟技术趣谈

Part 01●
前言
近年来,随着以Midjourney和Stable Diffusion为代表的人工智能图像生成工具的兴起,2D人工智能图像生成技术已经成为许多设计师在实际项目中使用的辅助工具,在各种商业场景中得到应用,创造出越来越多的实际价值。同时,随着元宇宙的兴起,许多行业正朝着创建大规模3D虚拟世界的方向发展,多样化、高质量的3D内容对于游戏、机器人、建筑和社交平台等行业变得越来越重要。然而,手动创建3D资源非常耗时且需要特定的艺术素养和建模技能。其中一个主要挑战是规模问题——尽管可以在3D市场上找到大量的3D模型,但在游戏或电影中填充一群看起来都不一样的角色或建筑仍然需要艺术家投入大量时间。因此,对于能够在3D内容的数量、质量和多样性方面进行扩展的内容制作工具的需求也变得越来越明显
 图片
图片
请看图1,这是元宇宙空间的照片(来源:电影《无敌破坏王2》)
得益于2D生成模型在高分辨率图像合成中已经获得了逼真的质量,这一进展也启发了对3D内容生成的研究。早期的方法旨在将2D CNN生成器直接扩展到3D体素网格,但由于3D卷积的高内存占用和计算复杂性,阻碍了在高分辨率下的生成过程。作为一种替代方案,其他研究已经探索了点云、隐式或八叉树表示。然而,这些工作主要集中在生成几何体上,而忽略了外观。它们的输出表示还需要进行后处理,以使其与标准图形引擎兼容
为了能够实际应用到内容制作中,理想的3D生成模型应当满足以下要求:
具备生成具有几何细节和任意拓扑的形状的能力
重写内容:(b)输出的应该是纹理网格,这是Blender和Maya等标准图形软件所常用的表达方式
可以使用2D图像进行监督,因为它们比明确的3D形状更普遍
Part 02
3D生成模型简介
为了方便内容的创作过程并能够实际应用,生成性3D网络已经成为一个活跃的研究领域,能够产生高质量和多样化的3D资产。每年都有许多3D生成模型在ICCV、NeurlPS、ICML等大会上发表,其中包括以下几种前沿模型
Textured3DGAN是一种生成模型,它是卷积生成纹理3D网格方法的延伸。它能够在二维监督下学习使用GAN从实物图像中生成纹理网格。与以往的方法相比,Textured3DGAN放宽了姿态估计步骤中对关键点的要求,并将该方法推广到未标记的图像集合和新的类别/数据集,例如ImageNet
DIB-R:是一种基于插值的可微分渲染器,底层使用了PyTorch机器学习框架。这个渲染器已经被添加到了3D深度学习的PyTorch GitHub库中(Kaolin)。这种方法允许对图像中所有像素的梯度进行分析计算。其核心思想是将前景光栅化视为局部属性的加权插值,将背景光栅化视为基于距离的全局几何体的聚合。通过这种方式,它可以从单个图像预测出形状、纹理和光线等信息
PolyGen:PolyGen是一种基于Transformer架构的自回归生成模型,用于直接对网格进行建模。该模型依次预测网格的顶点和面。我们使用ShapeNet Core V2数据集对模型进行训练,得到的结果已经非常接近于人类构建的网格模型
SurfGen:具有显式表面鉴别器的对抗性3D形状合成。通过端到端训练的模型能够生成具有不同拓扑的高保真3D形状。
GET3D是一个生成模型,可以通过学习图像来生成高质量的3D纹理形状。它的核心是可微分表面建模、可微分渲染和2D生成对抗性网络。通过对2D图像集合进行训练,GET3D可以直接生成具有复杂拓扑、丰富几何细节和高保真纹理的显式纹理3D网格
 图片
图片
需要重写的内容是:图2 GET3D生成模型(来源:GET3D论文官网https://nv-tlabs.github.io/GET3D/)
GET3D是最近提出的一种3D生成模型,它通过使用ShapeNet、Turbosquid和Renderpeople等多个具有复杂几何图形的类别,例如椅子、摩托车、汽车、人物和建筑,展示了在无限制生成3D形状方面的最先进性能
Part 03
GET3D的架构和特性
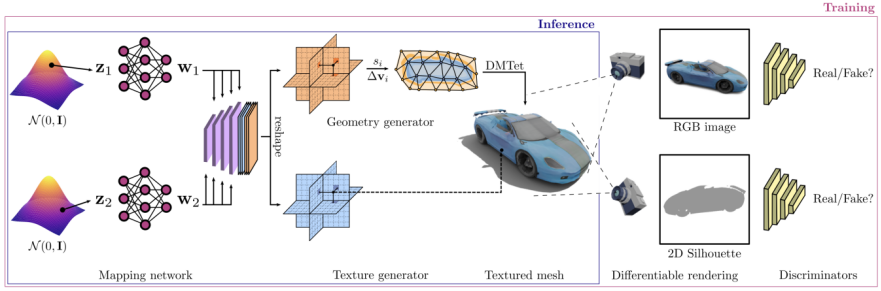 图片
图片
GET3D架构来源于GET3D论文官网,图3展示了该架构
通过两个潜在编码生成了一个3D SDF(有向距离场)和一个纹理场,再利用DMTet(Deep Marching Tetrahedra)从SDF中提取3D表面网格,并在表面点云查询纹理场以获取颜色。整个过程使用在2D图像上定义的对抗性损失来进行训练。特别是,RGB图像和轮廓是使用基于光栅化的可微分渲染器来获取的。最后使用两个2D鉴别器,每个鉴别器分别针对RGB图像和轮廓,来分辨输入是真实的还是伪造的。整个模型可以进行端到端的训练
GET3D在其他方面也非常灵活,除了将显式网格作为输出表达之外,还可以轻松适应其他任务,包括:
将几何体和纹理分离实现:模型的几何和纹理之间实现了良好的解耦,可以对几何潜在代码和纹理潜在代码进行有意义的插值
在生成不同类别形状之间的平滑过渡时,可以通过在潜在空间中进行随机行走,并生成相应的3D形状来实现
生成新的形状:可以通过向局部的潜在代码添加一些小的噪声来扰动,从而生成看起来相似但局部略有差异的形状
无监督材质生成:通过与DIBR++相结合,以完全无监督的方式生成材质,并产生具有意义的视图相关照明效果
以文本为导向的形状生成:通过结合StyleGAN NADA,利用计算渲染的2D图像和用户提供的文本上的定向CLIP损失来微调3D生成器,用户可以通过文本提示生成大量有意义的形状
 图片
图片
请参考图4,该图展示了基于文本生成形状的过程。该图的来源是GET3D论文官网,网址为https://nv-tlabs.github.io/GET3D/
Part 04
总结
虽然GET3D已经朝着实用的3D纹理形状的生成模型迈出了重要的一步,但是它仍然存在一些局限性。特别是在训练过程中,仍然依赖于2D剪影和相机分布的知识。因此,目前GET3D只能根据合成数据进行评估。一个有前景的扩展是利用实例分割和相机姿态估计方面的进步来缓解这个问题,并将GET3D扩展到真实世界的数据。GET3D目前还只按照类别进行训练,未来将扩展到多个类别,以更好地表示类别之间的多样性。希望这项研究能够让人们离使用人工智能进行3D内容的自由创作更近一步
以上是深入探讨GET3D生成模型的五分钟技术趣谈的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?
Jan 17, 2024 pm 02:57 PM
为何在自动驾驶方面Gaussian Splatting如此受欢迎,开始放弃NeRF?
Jan 17, 2024 pm 02:57 PM
写在前面&笔者的个人理解三维Gaussiansplatting(3DGS)是近年来在显式辐射场和计算机图形学领域出现的一种变革性技术。这种创新方法的特点是使用了数百万个3D高斯,这与神经辐射场(NeRF)方法有很大的不同,后者主要使用隐式的基于坐标的模型将空间坐标映射到像素值。3DGS凭借其明确的场景表示和可微分的渲染算法,不仅保证了实时渲染能力,而且引入了前所未有的控制和场景编辑水平。这将3DGS定位为下一代3D重建和表示的潜在游戏规则改变者。为此我们首次系统地概述了3DGS领域的最新发展和关
 了解 Microsoft Teams 中的 3D Fluent 表情符号
Apr 24, 2023 pm 10:28 PM
了解 Microsoft Teams 中的 3D Fluent 表情符号
Apr 24, 2023 pm 10:28 PM
您一定记得,尤其是如果您是Teams用户,Microsoft在其以工作为重点的视频会议应用程序中添加了一批新的3DFluent表情符号。在微软去年宣布为Teams和Windows提供3D表情符号之后,该过程实际上已经为该平台更新了1800多个现有表情符号。这个宏伟的想法和为Teams推出的3DFluent表情符号更新首先是通过官方博客文章进行宣传的。最新的Teams更新为应用程序带来了FluentEmojis微软表示,更新后的1800表情符号将为我们每天
 选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述
Jan 26, 2024 am 11:18 AM
选择相机还是激光雷达?实现鲁棒的三维目标检测的最新综述
Jan 26, 2024 am 11:18 AM
0.写在前面&&个人理解自动驾驶系统依赖于先进的感知、决策和控制技术,通过使用各种传感器(如相机、激光雷达、雷达等)来感知周围环境,并利用算法和模型进行实时分析和决策。这使得车辆能够识别道路标志、检测和跟踪其他车辆、预测行人行为等,从而安全地操作和适应复杂的交通环境.这项技术目前引起了广泛的关注,并认为是未来交通领域的重要发展领域之一。但是,让自动驾驶变得困难的是弄清楚如何让汽车了解周围发生的事情。这需要自动驾驶系统中的三维物体检测算法可以准确地感知和描述周围环境中的物体,包括它们的位置、
 CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer:显式监督BEVFormer结构,提升长尾检测性能
Mar 26, 2024 pm 12:41 PM
写在前面&笔者的个人理解目前,在整个自动驾驶系统当中,感知模块扮演了其中至关重要的角色,行驶在道路上的自动驾驶车辆只有通过感知模块获得到准确的感知结果后,才能让自动驾驶系统中的下游规控模块做出及时、正确的判断和行为决策。目前,具备自动驾驶功能的汽车中通常会配备包括环视相机传感器、激光雷达传感器以及毫米波雷达传感器在内的多种数据信息传感器来收集不同模态的信息,用于实现准确的感知任务。基于纯视觉的BEV感知算法因其较低的硬件成本和易于部署的特点,以及其输出结果能便捷地应用于各种下游任务,因此受到工业
 Windows 11中的Paint 3D:下载、安装和使用指南
Apr 26, 2023 am 11:28 AM
Windows 11中的Paint 3D:下载、安装和使用指南
Apr 26, 2023 am 11:28 AM
当八卦开始传播新的Windows11正在开发中时,每个微软用户都对新操作系统的外观以及它将带来什么感到好奇。经过猜测,Windows11就在这里。操作系统带有新的设计和功能更改。除了一些添加之外,它还带有功能弃用和删除。Windows11中不存在的功能之一是Paint3D。虽然它仍然提供经典的Paint,它对抽屉,涂鸦者和涂鸦者有好处,但它放弃了Paint3D,它提供了额外的功能,非常适合3D创作者。如果您正在寻找一些额外的功能,我们建议AutodeskMaya作为最好的3D设计软件。如
 单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具
May 23, 2023 pm 02:34 PM
单卡30秒跑出虚拟3D老婆!Text to 3D生成看清毛孔细节的高精度数字人,无缝衔接Maya、Unity等制作工具
May 23, 2023 pm 02:34 PM
ChatGPT给AI行业注入一剂鸡血,一切曾经的不敢想,都成为如今的基操。正持续进击的Text-to-3D,就被视为继Diffusion(图像)和GPT(文字)后,AIGC领域的下一个前沿热点,得到了前所未有的关注度。这不,一款名为ChatAvatar的产品低调公测,火速收揽超70万浏览与关注,并登上抱抱脸周热门(Spacesoftheweek)。△ChatAvatar也将支持从AI生成的单视角/多视角原画生成3D风格化角色的Imageto3D技术,受到了广泛关注现行beta版本生成的3D模型,
 牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
写在前面项目链接:https://nianticlabs.github.io/mickey/给定两张图片,可以通过建立图片之间的对应关系来估计它们之间的相机姿态。通常,这些对应关系是二维到二维的,而我们估计的姿态在尺度上是不确定的。一些应用,例如随时随地实现即时增强现实,需要尺度度量的姿态估计,因此它们依赖于外部的深度估计器来恢复尺度。本文提出了MicKey,这是一个关键点匹配流程,能够够预测三维相机空间中的度量对应关系。通过学习跨图像的三维坐标匹配,我们能够在没有深度测试的情况下推断出度量相对
 自动驾驶3D视觉感知算法深度解读
Jun 02, 2023 pm 03:42 PM
自动驾驶3D视觉感知算法深度解读
Jun 02, 2023 pm 03:42 PM
对于自动驾驶应用来说,最终还是需要对3D场景进行感知。道理很简单,车辆不能靠着一张图像上得到感知结果来行驶,就算是人类司机也不能对着一张图像来开车。因为物体的距离和场景的和深度信息在2D感知结果上是体现不出来的,而这些信息才是自动驾驶系统对周围环境作出正确判断的关键。一般来说,自动驾驶车辆的视觉传感器(比如摄像头)安装在车身上方或者车内后视镜上。无论哪个位置,摄像头所得到的都是真实世界在透视视图(PerspectiveView)下的投影(世界坐标系到图像坐标系)。这种视图与人类的视觉系统很类似,
